







 本文介绍了如何使用Python爬虫批量从NCBI获取不同物种参考基因组的assembly信息,包括发布信息、组装详情和下载链接。通过分析网页URL规律、定位所需内容,并编写正则表达式进行匹配,最终实现自动化收集和处理数据。
本文介绍了如何使用Python爬虫批量从NCBI获取不同物种参考基因组的assembly信息,包括发布信息、组装详情和下载链接。通过分析网页URL规律、定位所需内容,并编写正则表达式进行匹配,最终实现自动化收集和处理数据。
1.问题导向
最近在做某个课题的时候,按老师的要求需要从NCBI中批量下载不同物种的参考基因组,同时收集相应参考基因组的一些组装信息,基因组非常多,导致工作量巨大,一个一个手动收集的话,既费时又费力,这时就想到了用python爬虫来完成这项任务。
2.爬虫思路
2.1找到所需爬取的网页并观察网址urls的异同点
以猪、马、牛、羊参考基因组为例:
# Sus scrofa (pig)
https://www.ncbi.nlm.nih.gov/assembly/GCA_000003025.6
# Equus caballus (horse)
https://www.ncbi.nlm.nih.gov/assembly/GCF_002863925.1
# Bos taurus (cattle)
https://www.ncbi.nlm.nih.gov/assembly/GCF_002263795.1
# Ovis aries (sheep)
https://www.ncbi.nlm.nih.gov/assembly/GCF_016772045.1
......
#汇总:
urls = "https://www.ncbi.nlm.nih.gov/assembly/{assembly_ID}"NCBI中的参考基因组大部分是按照GenBank assembly accession号来存放位置的,因此我们只需要得到所需要收集物种的登录号,即可找到对应参考基因组的组装信息的页面。
2.2确认所需爬取的信息并确认是否需要二次爬取
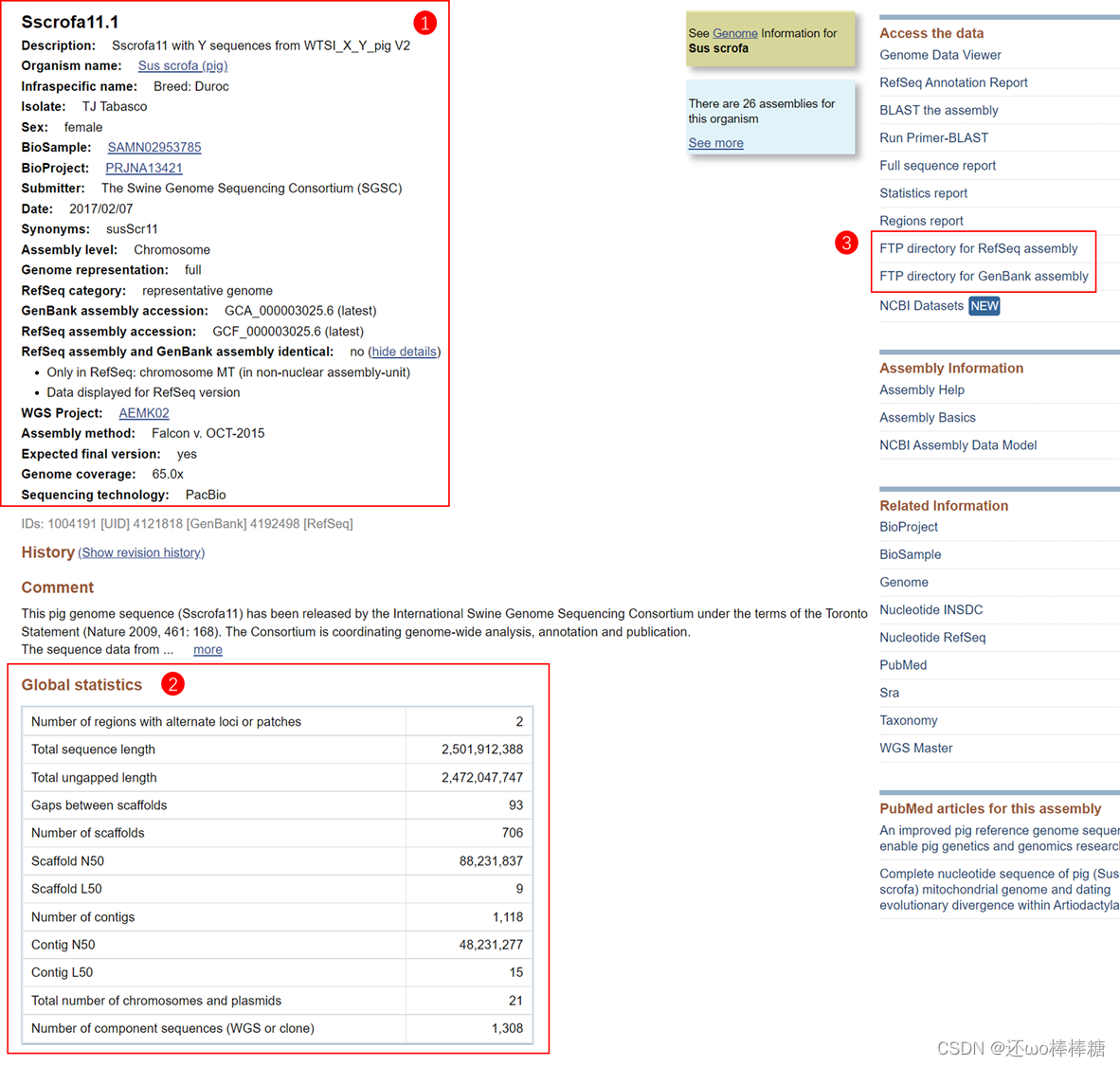
此处,需要爬取的信息共分为三部分,分别为上图红框中部分:
- 第一部分为每个assembly的基本信息,按照自己的需要选择内容,如assembly name、Organism name、Genome coverage等。
- 第二部分为每个assembly的组装信息,主要反映assembly的组装质量,建议全都收集。
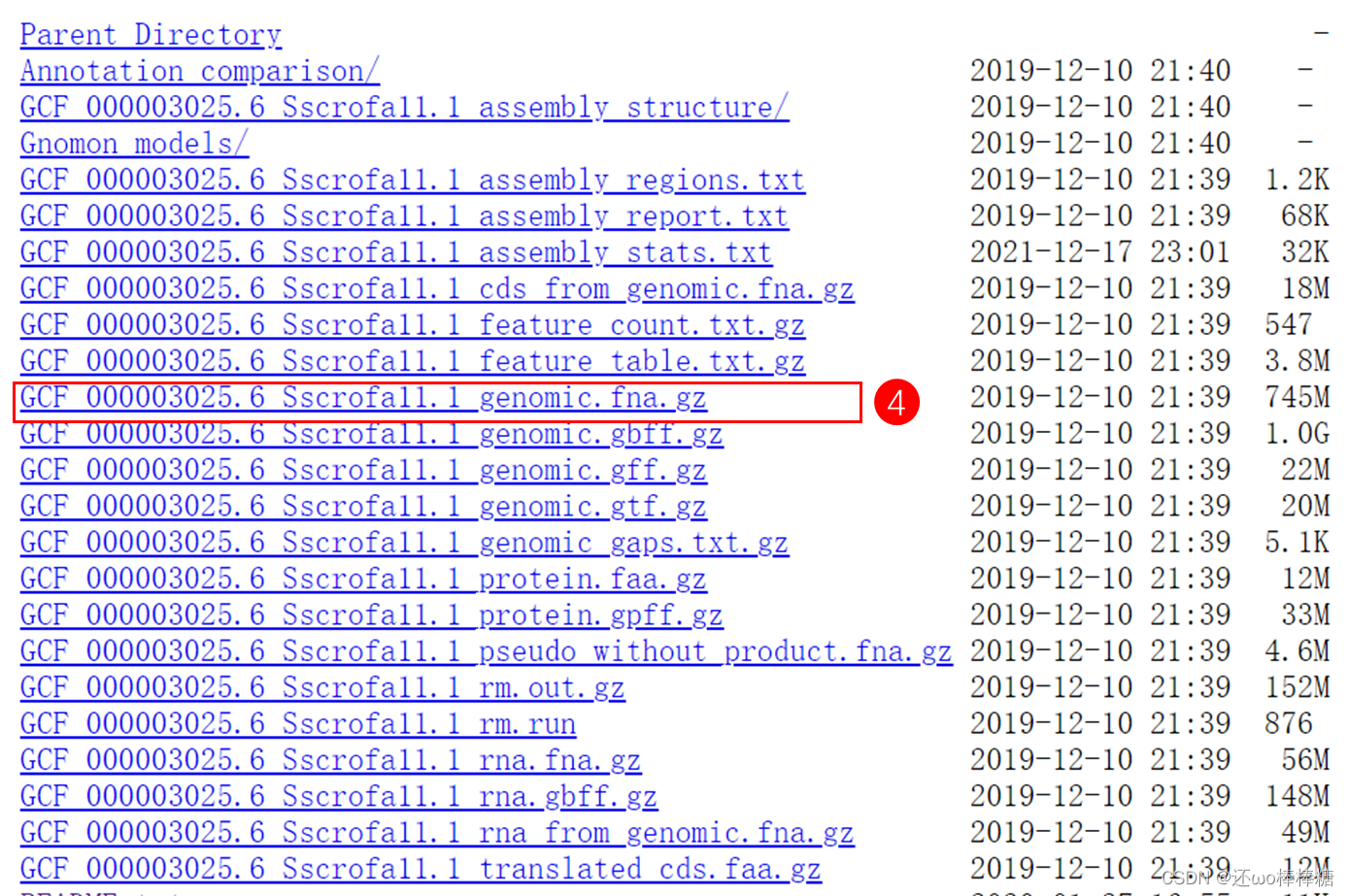
- 第三部分为常规下载的FTP地址,用来存放供下载的参考基因组、CDS序列、或注释文件GFF、GTF等文件,因为其拥有独立的网址url,需要二次爬取。新页面如下图所示:
- 如下图。本文主要下载参考基因组,即.fna文件,可按需要下载蛋白.faa、注释文件.gff或.gtf文件等。
2.3 在网页源代码中搜索定位所需要的信息
通过鼠标右键或快捷键"CTRL+U"来调出网页源代码,并利用"CTRL+F"来快速定位自己所需要爬取的内容的位置,如下:
- 第一部分:assembly基本信息
<div><div><div id="summary_cont"><div class="col margin_r0 nine_col"><div id="summary"><h1 xmlns:math="http://exslt.org/math" class="marginb0 margin_t0">Sscrofa11.1</h1><input type="hidden" value="true" id="ftp-genbank-refseq-exist" /><dl xmlns:math="http://exslt.org/math" class="assembly_summary_new margin_t0"><dt>Description: </dt><dd>Sscrofa11 with Y sequences from WTSI_X_Y_pig V2</dd><dt>Organism name: </dt><dd><a href="/Taxonomy/Browser/wwwtax.cgi?mode=Info&id=9823&lvl=3&lin=f&keep=1&srchmode=1&unlock"><span class="highlight" style="background-color:">Sus scrofa</span> (pig)</a></dd><dt>Infraspecific name: </dt><dd>Breed: Duroc</dd><dt>Isolate: </dt><dd>TJ Tabasco</dd><dt>Sex: </dt><dd>female</dd><dt>BioSample: </dt><dd><a href="/biosample/SAMN02953785/">SAMN02953785</a></dd><dt>BioProject: </dt><dd><a href="/bioproject/PRJNA13421/">PRJNA13421</a></dd><dt>Submitter: </dt><dd>The Swine Genome Sequencing Consortium (SGSC)</dd><dt>Date: </dt><dd>2017/02/07</dd><dt>Synonyms: </dt><dd>susScr11</dd><dt>Assembly level: </dt><dd>Chromosome</dd><dt>Genome representation: </dt><dd>full</dd><dt>RefSeq category: </dt><dd>representative genome</dd><dt>GenBank assembly accession: </dt><dd>GCA_000003025.6 (<span class="highlight" style="background-color:">latest</span>)</dd><dt>RefSeq assembly accession: </dt><dd>GCF_000003025.6 (<span class="highlight" style="background-color:">latest</span>)</dd><dt>RefSeq assembly and GenBank assembly identical: </dt><dd>no (<a href="#assembly-diff" id="assembly-diff-trigger">hide details</a>)</dd><dd id="assembly-diff"><ul><li>Only in RefSeq: chromosome MT (in non-nuclear assembly-unit)</li></ul></dd><dd class="displayed-from-refseq"><ul style="margin-left:0;"><li>Data displayed for RefSeq version</li></ul></dd><dt>WGS Project: </dt><dd><a href="/nuccore/AEMK00000000.2/">AEMK02</a></dd><dt>Assembly method: </dt><dd>Falcon v. OCT-2015</dd><dt>Expected final version: </dt><dd>yes</dd><dt>Genome coverage: </dt><dd>65.0x</dd><dt>Sequencing technology: </dt><dd>PacBio</dd></dl><div xmlns:math="http://exslt.org/math" style="clear:both"></div><p style="color:grey;"><span>IDs: </span><span>1004191 [UID] </span><span>4121818 [GenBank] </span><span>4192498 [RefSeq] </span></p></div></div><div class="more_genome_data-cont"><div class="more_genome_data shadow margin_r1"><h3>See <a href="/genome/?term=txid9823[orgn]">Genome</a> Information  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









