







最近在刷python二级的题库,发现在简单应用题和综合应用题中jieba库出现频率最高的就是分词和词频统计
1.分词,在jieba库中,分词有三种模式:精确模式,全模式与搜索引擎模式
(1)cut()全模式
把句子中所有可以成词的词语都扫描出来,速度非常快,但是不可以解决歧义,也就是会有重复的字,例如
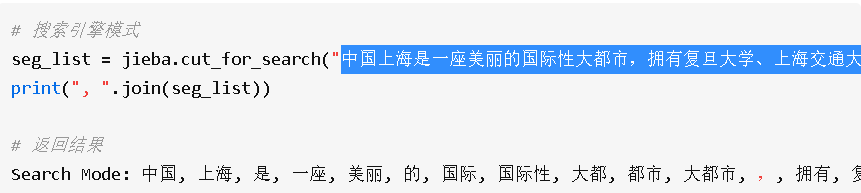
(2)lcut()精确模式、
将句子最精确地分开,适合文本分析,返回结果是列表类型

把句子中所有可以成词的词语都扫描出来,速度非常快,但是不可以解决歧义,也就是会有重复的字,例如
将句子最精确地分开,适合文本分析,返回结果是列表类型
 1万+
219
1万+
219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章





















