






目录
一、 引言
为了回馈tushare平台免费对高校学生开放使用,本人(tushare ID : 421217)与大家分享一下基于tushare数据的量化交易。
本文主要分为数据搜集与算法实现两个部分,在数据搜集部分本文主要利用tushare平台搜集了沪市A股在2013-1~2021-9的行情类、每股类、情绪类、动量类、统计类与常见的技术指标及部分特征滞后项共87个特征(具体指标可见代码),总计88163条数据;而后进行数据预处理与基于XGBoost算法的选股。具体流程见下文。
二、 数据搜集
本文把时间序列分为3个时间段,以2013-1~2020-11的数据作为训练集数据,2020-12的数据作为验证集,2021-1的数据作为测试集,并不断滚动训练直至2021-8。本文的87个特征均以真实月度数据或利用talib库结合23日日度数据计算得出,2021-1数据搜集代码示例如下:
import pandas as pd
import numpy as np
import tushare as ts
import talib as ta
import matplotlib.pyplot as plt
pro = ts.pro_api('your token')
ts.set_token('your token')#设置token
api = ts.pro_api()
import warnings
warnings.filterwarnings('ignore')
pd.options.display.max_columns=None
def Changestr(datetime1): #用于统一时间格式
str1 = datetime1.strftime('%Y-%m-%d')
return str1
def Changemonth(datetime1):#用于统一时间格式
str1 = datetime1.strftime('%Y%m%d')
return str1
data=pd.read_excel(r'D:\xxx.xlsx')#待搜集的股票池
stock=pd.DataFrame()
for pp,qq in data.iterrows():
if data.iloc[pp,0]<=pd.to_datetime('2020-07-15'):
stock_y=pd.DataFrame()
######
stock_y=ts.pro_bar(ts_code=qq['ts_code'], start_date='2020-08-01', end_date='20210131',freq='M',adj='qfq') #获取月度数据
######
if pd.DataFrame(stock_y).empty:
continue
stock_y.sort_values('trade_date',inplace=True)
stock_y.reset_index(inplace=True)
stock_y.drop('index',inplace=True,axis=1)
stock_y['cum_returns']=(stock_y['pct_chg']/100+1).cumprod()-1
stock_y.drop('change',axis=1,inplace=True)
lsttt=[]
for i in stock_y['trade_date']:
lsttt.append(i[0:6])
stock_y['tt']=lsttt
######
ss=pro.query('daily_basic', ts_code=qq['ts_code'],start_date='2020-08-01', end_date='20210131',fields='ts_code,trade_date,turnover_rate,volume_ratio,pe,pb,ps,dv_ratio,total_share,float_share,total_mv,circ_mv')
######
if pd.DataFrame(ss).empty:
continue
ss.sort_values('trade_date',inplace=True)
ss.reset_index(inplace=True)
ss.drop('index',inplace=True,axis=1)
ss.set_index('trade_date',inplace=True)
ss.index=pd.to_datetime(ss.index)
kk=ss.resample('m').mean()
kk.reset_index(inplace=True)
lsttt0=[]
for i in kk['trade_date']:
lsttt0.append(Changemonth(i)[0:6])
kk['tt']=lsttt0
stock_y=pd.merge(stock_y,kk,on='tt')
stock_y.drop(['tt','trade_date_y'],axis=1,inplace=True)
stock_y.set_index('trade_date_x',inplace=True)
stock_y.index=pd.to_datetime(stock_y.index)
######
stock1=ts.pro_bar(ts_code=qq['ts_code'],start_date='2020-08-01', end_date='20210131',freq='D',adj='qfq') #获取日度数据
######
if pd.DataFrame(stock1).empty:
continue
stock1.sort_values('trade_date',inplace=True)
stock1.reset_index(inplace=True)
stock1.drop('index',inplace=True,axis=1)
stock1.set_index('trade_date',inplace=True)
stock1.index=pd.to_datetime(stock1.index)
#行情指标
'''high,open,low,close,pct_chg,vol,amount,pre_close'''
#每股类指标
'''turnover_rate,volumn_ratio,dv_ratio,float_share,circ_mv,pe,pb,ps'''
#情绪类指标
stock1['PSY']=pd.DataFrame((stock1['pct_chg']>0).rolling(23).mean()*100).values
stock1["rsi"] = ta.RSI(stock1['close'],timeperiod=23)
stock1['willr'] = ta.WILLR(stock1['high'], stock1['low'], stock1['close'], timeperiod=23)
stock1['turnover_rate_std']=ss.turnover_rate.rolling(23).std()
stock1['ATR'] = ta.ATR(stock1.high, stock1.low, stock1.close, timeperiod=23)
stock_y['obv'] = ta.OBV(stock_y['close'],stock_y['vol'])
stock1['AR_high']=(stock1['open']/stock1['high']).rolling(23).mean()
stock1['AR_low']=(stock1['open']/stock1['low']).rolling(23).mean()
stock1['BR_high']=(stock1['pre_close']/stock1['high']).rolling(23).mean()
stock1['BR_low']=(stock1['pre_close']/stock1['low']).rolling(23).mean()
# #动量指标
'''cum_returns'''
stock1['BIAS']=(stock1['close']-stock1['close'].rolling(23).mean())/stock1['close']
stock1['cci'] = ta.CCI(stock1['high'], stock1['low'], stock1['close'], timeperiod=23)
stock1['MINUS_DI'] = ta.MINUS_DI(stock1.high, stock1.low, stock1.close, timeperiod=23)
stock1['MINUS_DM']= ta.MINUS_DM(stock1.high, stock1.low, timeperiod=23)
stock1['MOM']= ta.MOM(stock1.close, timeperiod=23)
stock_y['AD'] = ta.AD(stock_y.high, stock_y.low, stock_y.close, stock_y.vol)
stock_y['HT_TRENDMODE'] = ta.HT_TRENDMODE(stock_y.close)
#统计类指标
stock1['pct_chg_std']=stock1.pct_chg.rolling(23).std()
stock1['close_std'] = np.sqrt(ta.VAR(stock1.close,timeperiod=23))
stock1['vol_std']=stock1['vol'].rolling(23).std()
stock1['amount_std']=stock1['amount'].rolling(23).std()
stock_y['typeprice'] = ta.TYPPRICE(stock_y.high,stock_y.low, stock_y.close)
stock_y['AVGPRICE'] = ta.AVGPRICE(stock_y.open,stock_y.high, stock_y.low, stock_y.close)
stock_y['WCLPRICE'] = ta.WCLPRICE(stock_y.high, stock_y.low, stock_y.close)
stock1['midprice'] = ta.MIDPRICE(stock1.high,stock1.low,timeperiod=23)
# 技术指标
stock1['midpoint'] = ta.MIDPOINT(stock1.close, timeperiod=23)
stock1['EMA'] = ta.EMA(stock1.close, timeperiod=23)
stock1['MFI'] = ta.MFI(stock1.high, stock1.low, stock1.close, stock1.vol, timeperiod=23)
stock1['macd'], stock1['macdsignal'], stock1['macdhist'] = ta.MACD(stock1['close'], fastperiod=12, slowperiod=23, signalperiod=9)
stock1['upperband'], stock1['middleband'], stock1['lowerband'] = ta.BBANDS(stock1['close'], timeperiod=23, nbdevup=2, nbdevdn=2, matype=0)
stock1['TEMA'] = ta.TEMA(stock1.close, timeperiod=23)
stock_y['RVI']=(stock_y['close']-stock_y['open'])/(stock_y['high']-stock_y['low'])
stock1['trix']=ta.TRIX(stock1.close,23)
stock_y.reset_index(inplace=True)
lsttt0=[]
for i in stock_y['trade_date_x']:
lsttt0.append(Changemonth(i)[0:6])
stock_y['tt']=lsttt0
kk=stock1.resample('m').last().iloc[:,10:]
kk.reset_index(inplace=True)
lsttt0=[]
for i in kk['trade_date']:
lsttt0.append(Changemonth(i)[0:6])
kk['tt']=lsttt0
stock_y=pd.merge(stock_y,kk,on='tt')
stock_y.drop(['tt','trade_date_x'],axis=1,inplace=True)
stock_y.set_index('trade_date',inplace=True)
stock_y.index=pd.to_datetime(stock_y.index)
lst=['PSY','rsi','willr','turnover_rate_std','ATR','obv','AR_high','AR_low','BR_high','BR_low','cum_returns','BIAS','cci','MINUS_DI','MINUS_DM','MOM','AD','HT_TRENDMODE']
for m in lst:
for i in [1,2]:
stock_y[m+'_L%d'%i]=stock_y[m].shift(i)
stock_y.drop(['total_share','total_mv'],axis=1,inplace=True)
######
stock=stock.append(stock_y.loc['2021-01-01':])三、数据预处理
在数据搜集完成后,本文仅发现dv_ratio特征存在缺失值,以0填补;对所有特征进行z-score标准化处理,运用LOF算法去除异常值,把VIF系数大于10的特征剔除后,仍剩余28个特征。
考虑到特征众多,后续解释较为困难,继续运用因子分析的方式对28个特征降维,在保留80.1614%的方差下,选出了12个重要特征,其因子载荷矩阵如下图所示:
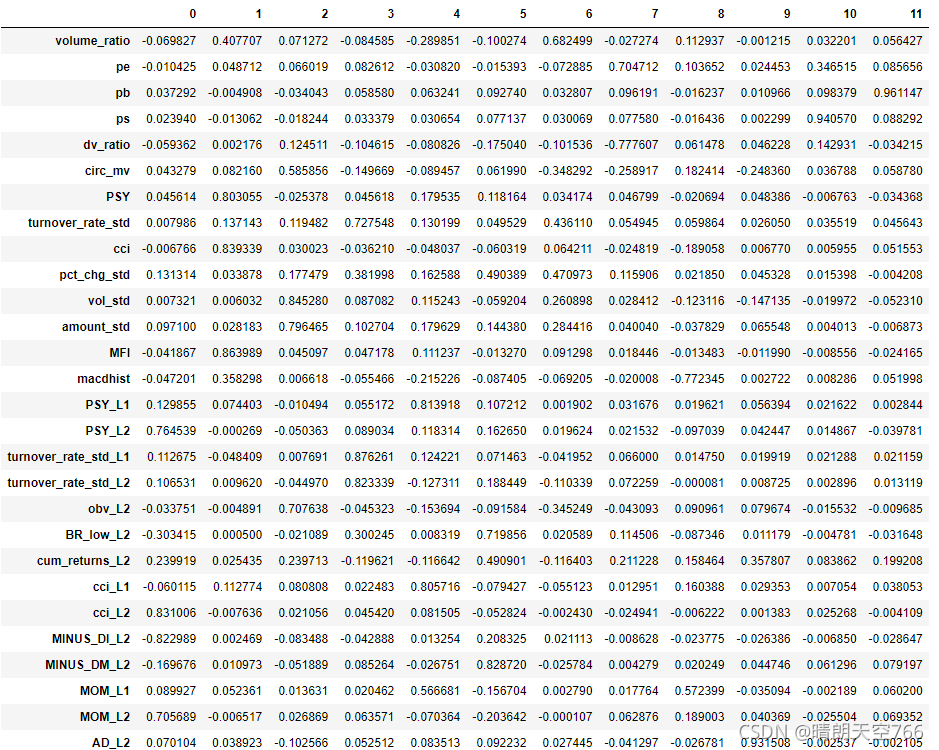
后续本文将用这12个特征与XGBoost算法建模选股。
四、 XGBoost算法实现
本文交易策略为:经参数调优后,在验证集上预测准确率大于50%,且做多上涨概率最大的前5只股票收益率为正,那么在测试集将开仓,否则本月什么也不做,并每月重新估计模型参数,不断滚动预测下去,XGBoost示例代码如下:
import xgboost as xgb
lst=[]
a=np.random.randint(100000000)
for i in range(1):#查看每月收益情况:
dt=xgb.DMatrix(xt.values,zzyt)
dc=xgb.DMatrix(xc.values,yc)
params ={
'objective' : 'binary:logistic', #目标函数,逻辑回归(二分类问题)
'booster' : 'gbtree', #基学习器
'eta' : 0.1, #学习率
'gamma' : 0, #惩罚力度
'max_depth' :4 ,
'eval_metric' : ['error'], #评估指标
'min_child_weight':1,
'subsample':1,
'scale_pos_weight':1,
'colsample_bytree':1,
'seed':a
}
watch_list=[(dt,'train')]
model = xgb.train(params,dt,1000,evals = watch_list,early_stopping_rounds =10,verbose_eval=False)
print((model.predict(dc).round()==yc).mean())#计算准确率回测结果如下:
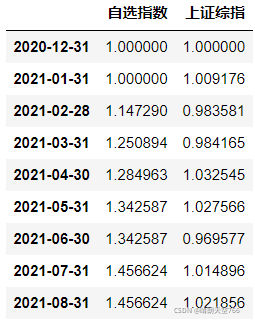
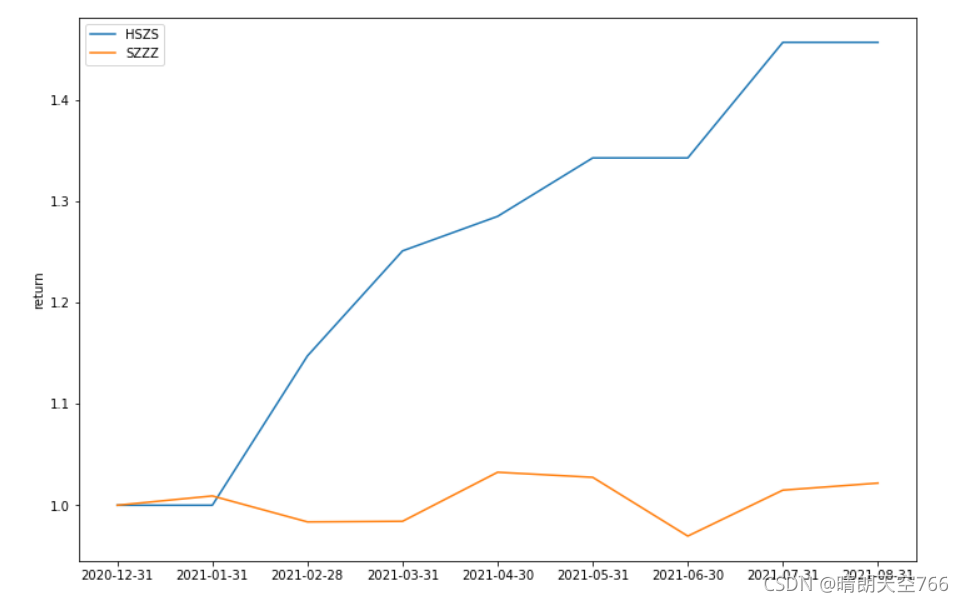
可以看到,本文最终获取了45.66%的收益,并实现了0回撤,远远超越了上证综指的表现。 这8个月的选股列表如下表所示:
| 2021-1 | 2021-2 | 2021-3 | 2021-4 | 2021-5 | 2021-6 | 2021-7 | 2021-8 |
| 未开仓 | 600543.SH | 600549.SH | 600521.SH | 688208.SH | 未开仓 | 601038.SH | 未开仓 |
|---|---|---|---|---|---|---|---|
| 600707.SH | 600511.SH | 603733.SH | 600892.SH | 601865.SH | |||
| 601127.SH | 600847.SH | 603960.SH | 600328.SH | 603208.SH | |||
| 603919.SH | 603225.SH | 600699.SH | 603966.SH | 600526.SH | |||
| 601579.SH | 600569.SH | 600884.SH | 603530.SH | 603008.SH |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









