







文章目录
前言
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。

论文题目:学习层次感知的知识图嵌入以进行链接预测
论文链接:https://arxiv.org/abs/1911.09419
arXiv:1911.09419v3 [cs.LG] 6 Apr 2022
摘要
知识图谱嵌入,旨在将实体和关系表示为低维度的向量(或矩阵、张量等),已被证明是预测知识图中缺失链接的强大技术。现有的知识图谱嵌入模型主要关注建模关系模式,如对称性/反对称性、反转和组合。然而,许多现有的方法未能对语义层次结构进行建模,而这种层次结构在现实世界应用中非常常见。为了解决这一挑战,我们提出了一种新颖的知识图谱嵌入模型——即层次感知知识图谱嵌入(HAKE)——它将实体映射到极坐标系统。HAKE的灵感来源于极坐标系统中的同心圆可以自然地反映层次结构这一事实。具体来说,径向坐标旨在模拟不同层次的实体,而半径较小的实体被期望处于更高层次;角度坐标旨在区分处于同一层次的实体,这些实体被期望具有大致相同的半径但不同的角度。实验表明,HAKE能够有效地在知识图谱中建立语义层次结构,并在链接预测任务的基准数据集上显著优于现有的最先进方法。
1 介绍
知识图谱通常是事实三元组的集合,包括头部实体、关系和尾部实体,以结构化方式表示人类知识。在过去的几年里,我们见证了知识图谱在许多领域的巨大成就,如自然语言处理(Zhang et al. 2019)、问答系统(Huang et al. 2019)和推荐系统(Wang et al. 2018)。
尽管常用的知识图谱包含数十亿的三元组,但它们仍然受到不完整性问题的困扰,即缺失很多有效的三元组,因为手动找到所有有效的三元组是不现实的。因此,知识图谱补全,也称为知识图谱中的链接预测,最近受到了广泛关注。链接预测旨在根据已知的链接自动预测实体之间的缺失链接。这是一项具有挑战性的任务,因为我们不仅需要预测两个实体之间是否存在关系,还需要确定它们之间的具体关系是什么。
受单词嵌入(Mikolov 等,2013)的启发,研究人员开始转向知识图谱的分布式表示(即知识图谱嵌入),以解决链接预测问题。知识图谱嵌入将实体和关系视为低维度的向量(或矩阵、张量),这些向量可以高效地存储和计算。此外,与词嵌入类似,知识图谱嵌入可以保留实体和关系的语义和内在结构。因此,除了链接预测任务外,知识图谱嵌入还可以用于各种下游任务,如三元组分类(林等人,2015年),关系推断(郭,孙和胡,2019年)和搜索个性化(Nguyen等人,2019年)。
现有知识图谱嵌入模型的成功在很大程度上依赖于它们对关系连接模式的建模能力,如对称性/反对称性、反转和组合(Sun等,2019)。例如,TransE(Bordes等,2013)将关系表示为翻译,可以模拟反转和组合模式。现有知识图谱嵌入模型的成功在很大程度上依赖于它们对关系连接模式的建模能力,如对称性/反对称性、反转和组合(Sun等,2019)。例如,TransE(Bordes等,2013)将关系表示为翻译,可以模拟反转和组合模式。
语义层次是知识图谱中普遍存在的属性。例如,WordNet(Miller 1995)包含了一个三元组[arbor/cassia/palm,hypernym,tree],在这个层次结构中,“tree”比“arbor/cassia/palm”处于更高的层次。Freebase(Bollacker等人2008)包含了一个三元组[England,/location/location/contains,Ponte-frac t/Lancaster],在这个层次结构中,“Ponte-frac t/Lancaster”比“England”处于更低的层次。尽管已经有一些工作考虑到了层次结构(Xie, Liu, and Sun 2016; Zhang et al. 2018),但它们通常需要额外的数据或过程来获取层次信息。因此,找到一种能够自动且有效地建模语义层次结构的方法仍然具有挑战性。
在这篇论文中,我们提出了一种新颖的知识图谱嵌入模型——即层次感知知识图谱嵌入(HAKE)。为了模拟语义层次结构,HAKE旨在区分两类实体:(a)处于不同层次的实体;(b)处于同一层次的实体。受到具有层次属性的实体可以被视为树这一事实的启发,我们可以使用节点(实体)的深度来模拟层次结构的不同层次。因此,我们使用模数信息来模拟类别(a)中的实体,因为模数的大小可以反映深度。在上述设置下,类别(b)中的实体将具有大致相同的模数,这很难区分。受到同一圆上的点可以具有不同相位的事实的启发,我们使用相位信息来模拟类别(b)中的实体。结合模数和相位信息,HAKE将实体映射到极坐标系统中,其中径向坐标对应模数信息,角度坐标对应相位信息。实验表明,我们提出的HAKE模型不仅能清晰地区分实体的语义层次结构,还能在基准数据集上显著且一致地优于几种最先进的方法。
符号 在这篇论文中,我们使用小写字母h,r和t分别表示头部实体、关系和尾部实体。三元组(h,r,t)表示知识图中的一个事实。相应的粗体小写字母h,r和t表示头部实体、关系和尾部实体的嵌入(向量)。向量h的第i个条目表示为[h]i。让k表示嵌入维度。
让◦表示Rn × Rn到Rn的Hadamard乘积,即 [a ◦ b]i = [a]i · [b]i, 并且∥ · ∥1, ∥ · ∥2分别表示ℓ1和ℓ2范数。
注:markdown语法中上下标的表示方法:
下标 :θ1 :θ ~ 1 ~
上标 :θ2:θ ^ 2 ^
2 相关工作
在这一部分,我们将描述相关工作以及它们与我们的工作在两个方面的关键区别——模型类别和知识图谱中层次结构的建模方式。
模型类别
大致来说,我们可以将知识图谱嵌入模型分为三类:翻译距离模型、双线性模型和基于神经网络的模型。表1展示了一些流行的模型。

表1:几种知识图谱嵌入模型的详细信息,其中◦表示Hadamard积,f表示激活函数,∗表示2D卷积,ω表示卷积层中的滤波器。¯·表示ComplEx模型中复数向量的共轭和ConvE模型中实数向量的2D重塑。
翻译距离模型 将关系描述为从源实体到目标实体的转换。TransE(Bordes等人,2013)假设实体和关系满足h + r ≈ t,其中h, r, t ∈ Rn,并定义相应的得分函数为fr(h, t) = −∥h+r−t∥1/2。然而,TransE在1-N,N-1和N-N关系上表现不佳(Wang等人,2014)。TransH(王等人,2014年)通过允许实体在不同的关系下具有不同的表示,克服了多对多关系问题。得分函数定义为fr(h, t) = −∥h⊥+r−t⊥∥2,其中h⊥和t⊥是实体在关系特定超平面上的投影。ManifoldE(Xiao, Huang, and Zhu 2016)通过将假设h + r ≈ t放松为∥h + r − t∥22 ≈ θr2 来处理多对多问题,对于每个有效的三元组。这样,候选实体可以位于一个流形上,而不是精确的点。相应得分函数的定义为fr(h, t) = −(∥h + r − t∥22 −θr2)2。最近,为了更好地模拟对称和反对称关系,旋转E(Sun等人,2019)在复向量空间中将每个关系定义为从源实体到目标实体的旋转。得分函数定义为fr(h, t) = −∥h ◦ r − t∥1,其中h, r, t ∈ Ck且|[r]i| = 1。
双线性模型 基于产品评分函数来匹配实体和关系的潜在语义,这些实体和关系都体现在它们的向量空间表示中。RESCAL(Nickel, Tresp, 和 Kriegel 2011)将每个关系表示为一个满秩矩阵,并将评分函数定义为 fr(h, t) = h⊤Mrt,这也可以看作是一个双线性函数。由于全秩矩阵容易过拟合,近期的研究开始对Mr做出额外的假设。例如,DistMult(杨等,2015)假设Mr是一个对角矩阵,而ANAL- OGY(刘,吴,和杨,2017)假设Mr是正态的。然而,这些简化模型通常表达能力较弱,对于通用知识图谱来说不够强大。不同的是,ComplEx(Trouillon等人,2016)通过引入复数嵌入来扩展DistMult,以便更好地模拟不对称和逆向关系。HolE(Nickel,Rosasco和Poggio,2016)通过使用循环相关操作,结合了RESCAL的表现力和DistMult的效率与简单性。
基于神经网络的模型近年来受到了更多的关注。例如,MLP(Dong等人,2014年)和NTN(Socher等人,2013年)使用全连接神经网络来确定给定三元组的得分。ConvE(Dettmers等人,2018年)和ConvKB(Nguyen等人,2018年)采用卷积神经网络来定义得分函数。最近,图卷积网络也被引入,因为知识图谱明显具有图结构(Schlichtkrull等人,2018)。
我们提出的模型HAKE属于平移距离模型。更具体地说,HAKE与RotatE(Sun等人,2019)有相似之处,其中作者声称他们使用了模数和相位信息。然而,RotatE和HAKE之间存在两个主要区别。详细区别如下。
(a)目标是不同的。RotatE旨在模拟关系模式,包括对称/反对称、反转和组合。HAKE旨在模拟语义层次结构,同时也可以模拟上述所有提到的关系模式。
(b) 使用模数信息的方法不同。旋转模型将关系视为复数空间中的旋转,这鼓励两个相关实体具有相同的模数,无论关系如何。RotatE中不同的模数来自于训练中的不准确。相反,HAKE明确地建模了模数信息,这在区分层次结构中不同级别的实体方面显著优于RotatE。
层次结构建模的方法
另一个相关的问题是如何在知识图谱中建模层次结构。一些近期的工作从不同的角度考虑了这个问题。李等(2016)将实体和类别联合嵌入到一个语义空间中,并设计了用于概念分类和无数据层次分类任务的模型。张等人(2018)使用聚类算法来建模层次关系结构。谢、刘和孙(2016)提出了TKRL,它将类型信息嵌入到知识图谱嵌入中。也就是说,TKRL需要实体的额外层次类型信息。
与以前的工作不同,我们的工作…
(a) 考虑了知识图谱嵌入中更为常见的链接预测任务;
(b) 可以在无需使用聚类算法的情况下自动学习知识图谱中的语义层次结构;
© 除了知识图谱中的三元组外,不需要任何其他额外信息。
3 提出的HAKE方法
在这部分,我们介绍了我们提出的HAKE模型。首先,我们介绍了反映知识图谱中语义层次结构的两类实体。之后,我们介绍了我们提出的HAKE模型,它可以对两类实体进行建模。
两类实体
为了模拟知识图谱的语义层次结构,知识图谱嵌入模型必须能够区分以下两类实体。
(a) 属于不同层次的实体。例如,“哺乳动物”和“狗”,“奔跑”和“移动”。
(b) 属于同一层次的实体。例如,“玫瑰”和“牡丹”,“卡车”和“货车”。
为了建立知识图谱的语义层次结构模型,我们需要一个能够区分不同层次和同一层次的实体的知识图谱嵌入模型。例如,它应该能够区分“哺乳动物”和“狗”,“奔跑”和“移动”这些不同层次的实体,以及“玫瑰”和“牡丹”,“卡车”和“货车”这些同一层次的实体。
层次感知知识图谱嵌入
为了模拟以上两类,我们提出了一个层次感知的知识图谱嵌入模型——HAKE。HAKE由两部分组成——模数部分和相位部分,分别旨在模拟两类不同的实体。图1给出了所提出模型的示例。
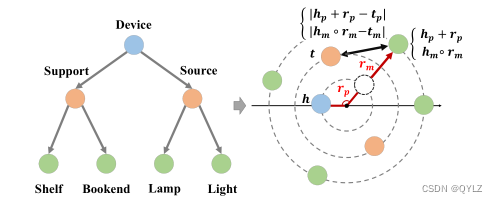
图1:HAKE的简单示意图。在极坐标系统中,径向坐标旨在模拟层次结构中不同级别的实体,而角度坐标旨在区分同一层次结构中的实体。
为了区分不同部分的嵌入,我们使用em(e可以是h或t)和rm来表示模数部分中的实体嵌入和关系嵌入,使用ep(e可以是h或t)和rp来表示相位部分中的实体嵌入和关系嵌入。
模数部分的目的是在不同层次的层次结构中建模实体。受到这样一个事实的启发,即具有层次属性的实体可以被视为一棵树,我们可以使用节点(实体)的深度来建模层次结构的不同级别。因此,我们使用模数信息来建模类别(a)中的实体,因为模数可以反映树中的深度。具体来说,我们将hm和tm的每个元素,即[hm]i和[tm]i,视为模数,将rm的每个元素,即[r]i,视为两个模数之间的缩放变换。我们可以将模数部分表示如下: hm ◦ rm = tm,其中hm,tm ∈ Rk,rm ∈ R+k。 相应的距离函数为: dr,m(hm, tm) = ∥hm ◦ rm − tm∥2。
请注意,我们允许实体嵌入的条目包含负数,但限制关系嵌入的条目必须是正数。这是因为实体嵌入的符号可以帮助我们预测两个实体之间是否存在关系。例如,如果存在一个关系r在h和t1之间,而h和t2之间没有关系,那么(h, r, t1)是一个正样本,(h, r, t2)是一个负样本。我们的目标是使dr(hm,t1,m)(hm和t1,m之间的距离)最小化,使dr(hm,t2,m)(hm和t2,m之间的距离)最大化,以便在正样本和负样本之间做出明确的区分。对于正样本,[h]i 和 [t1]i 倾向于拥有相同的符号,因为 [rm]i > 0。对于负样本,如果我们将 [hm]i 和 [t2,m]i 的符号随机初始化,那么它们的符号可能不同。这样,dr(hm, t2,m) 就更有可能大于 dr(hm, t1,m),这正是我们所期望的。我们将在补充材料的第4节通过实验验证这个观点。
此外,我们可以预期,在层次结构中更高层次的实体将具有较小的模数,因为这些实体更接近树的根部。
如果我们只使用模数部分来嵌入知识图谱,那么类别(b)中的实体将具有相同的模数。此外,假设r是一个反映相同语义层次的关系,那么[r]i将趋于1,因为对于所有h,h ◦ r ◦ r = h成立。因此,类别(b)中实体的嵌入往往会变得相同,这使得难以区分这些实体。因此,需要一个新的模块来建模类别(b)中的实体。
阶段部分的目的是在语义层次结构的同一级别上建模实体。受到这样一个事实的启发,即相同圆上的点(即具有相同模数)可以具有不同的相位,我们使用相位信息来区分类别(b)中的实体。具体来说,我们将hp和tp的每个条目,即[hp]i和[tp]i视为一个相位,并将rp的每个条目,即[rp]i视为一个相位变换。我们可以将相位部分表述如下:(hp + rp)mod 2π = tp,其中hp,rp,tp ∈ [0, 2π)k。 对应的距离函数为: dr,p(hp, tp) = ∥sin((hp + rp - tp)/2)∥1, 其中sin(·)是一个将正弦函数应用于输入的每个元素的操作。请注意,我们使用正弦函数来测量相位之间的距离,而不是使用∥hp +rp -tp∥1,因为相位具有周期性特征。这个距离函数与pRotatE(Sun等人,2019)的距离函数具有相同的公式。
将模数部分和相位部分结合起来,HAKE将实体映射到极坐标系统中,其中径向坐标和角度坐标分别对应于模数部分和相位部分。这就是说,HAKE将实体h映射到[hm; hp],其中hm和hp分别由模数部分和相位部分生成,[ · ; · ]表示两个向量的连接。显然,([hm]i, [hp]i)是极坐标系中的一个二维点。具体而言,我们如下定义HAKE:

HAKE这个距离函数是:

其中λ属于实数,是模型学习到的一个参数。相应的评分函数是:
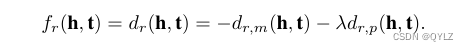
当两个实体具有相同的模数时,模数部分dr,m(hm, tm) = 0。然而,相位部分dr,p(hp, tp)可以非常不同。通过结合模数部分和相位部分,HAKE可以模拟类别(a)和类别(b)中的实体。因此,HAKE可以模拟知识图谱的语义层次结构。
在评估模型时,我们发现向 dr,m(h, t) 添加混合偏差有助于提高 HAKE 的性能。修改后的 dr,m(h, t) 如下所示:
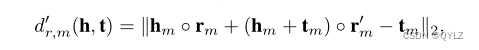
其中-rm < r’ m < 1是一个与rm具有相同维度的向量。实际上,上述距离函数等同于:
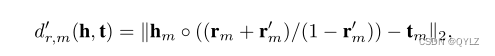
其中/表示元素级除法操作。如果我们让rm ← (rm + r’m)/(1 - r’m),那么修改后的距离函数在比较不同实体对的距离时与原始函数完全相同。为了便于表示,我们仍然使用dr,m(h, t) = ∥hm ◦ rm - tm∥2来表示模长部分。我们将在实验部分对偏差进行消融研究。
损失函数
为了训练模型,我们使用了带有自对抗训练的负采样损失函数(Sun等,2019):
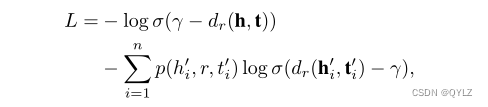
在这里,γ表示一个固定的边际,σ表示sigmoid函数,而(h’i,r,t’i)表示第i个负三元组。此外,
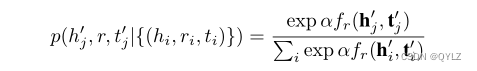
这段内容是关于负采样的概率分布,其中α表示采样温度。
4 实验与分析
本节内容如下组织。首先,我们详细介绍了实验设置。然后,我们展示了在三个基准数据集上我们提出的模型的有效性。最后,我们分析了由HAKE生成的嵌入向量,并展示了消融研究的结果。HAKE的代码可以在GitHub上找到,地址是https://github.com/MIRALab-USTC/KGE-HAKE。 这一部分的组织如下。
实验设置
我们使用三个常用的知识图谱数据集——WN18RR(Toutanova和Chen 2015),FB15k-237(Dettmers等人2018),以及YAGO3-10(Mahdisoltani,Biega和Suchanek 2013)来评估我们提出的方法。这些数据集的详细信息总结在表2中。
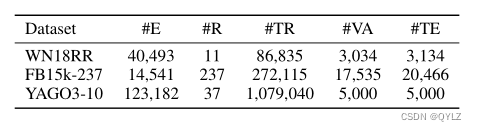
表格2:数据集的统计信息。符号#E和#R分别表示实体数量和关系数量。#TR、#VA和#TE分别表示训练集大小、验证集大小和测试集大小。
WN18RR、FB15k-237和YAGO3-10分别是WN18(Bordes等人,2013)、FB15k(Bordes等人,2013)和YAGO3(Mahdisoltani,Biega和Suchanek,2013)的子集。正如Toutanova和Chen(2015)以及Dettmers等人(2018)所指出的,WN18和FB15k存在测试集泄漏问题。即使使用简单的基于规则的模型,也可以获得最先进的结果。因此,我们将WN18RR和FB15k-237作为基准数据集。
评估协议遵循Bordes等人(2013)的方法,对于测试数据集中的每个三元组(h,r,t),我们用每个候选实体替换头部实体h或尾部实体t,以创建一组候选三元组。然后,我们将候选三元组按照其得分从高到低排序。值得注意的是,我们采用了Bordes等人(2013)中的“Filtered”设置,即在排名时不考虑任何已存在的有效三元组。我们选择平均互反排名(MRR)和命中率@N(H@N)作为评估指标。更高的MRR或H@N表示更好的性能。
训练协议 我们使用Adam(Kingma和Ba 2015)作为优化器,并使用网格搜索来寻找最佳超参数,基于验证数据集的性能。为了使模型更容易训练,我们在距离函数中添加了一个额外的系数,即dr(h, t) = λ1dr,m(hm, tm) + λ2dr,p(hp, tp),其中λ1, λ2 ∈ R。
基准模型 有人可能会认为相位部分是不必要的,因为我们可以通过允许[r]i为负数来区分类别(b)中的实体。我们提出了一种模型——ModE——它只使用模数部分,但允许[r]i小于0。具体来说,ModE的距离函数是

主要结果
在此部分,我们展示了我们提出的HAKE和ModE模型与现有最先进的方法(包括TransE(Bordes等人,2013年),DistMult(Yang等人,2015年),ComplEx(Trouillon等人,2016年),ConvE(Dettmers等人,2018年)和RotatE(Sun等人,2019年))的性能对比。
表3显示了HAKE、ModE和几个之前模型的性能。我们的基准模型ModE与TransE具有相似的简单性,但在所有数据集上都显著优于它。令人惊讶的是,ModE甚至在所有数据集上超越了更复杂的模型,如DistMult、ConvE和Complex,并在FB15k-237和YAGO3-10数据集上击败了最先进的模型RotatE,这证明了模长信息的巨大威力。表3还显示,我们的HAKE在所有数据集上显著优于现有的最先进的方法。
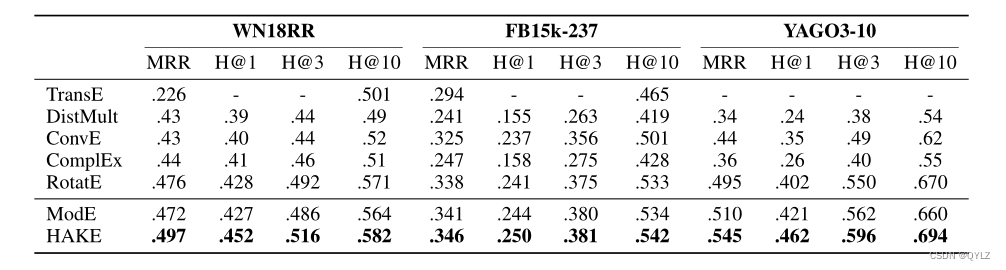
表3:在WN18RR、FB15k-237和YAGO3-10数据集上的评估结果。TransE和RotatE的结果分别来自Nguyen等人(2018)和Sun等人(2019)。其他结果来自Dettmers等人(2018)。
WN18RR数据集包含两种关系:对称关系,如similar to,将实体链接在类别(b)中;其他关系,如hypernym和member meronym,将实体链接在类别(a)中。实际上,RotatE可以很好地模拟类别(b)中的实体(Sun等人,2019)。然而,与RotatE相比,HAKE的MRR高0.021,H@1高2.4%,H@3高2.4%。与RotatE相比,HAKE的优越性能表明我们提出的模型可以更好地模拟层次结构中的不同级别。
FB15k-237数据集具有更复杂的的关系类型和较少的实体,与WN18RR和YAGO3-10相比。尽管在FB15k-237中存在反映层次结构的关系,但还有很多关系,如“/location/location/time zones”和“/film/film/prequel”,这些关系并不导致层次结构。这段数据集的特点解释了为什么我们的提议模型在表现上没有像WN18RR和YAGO3-10数据集那样超越之前的最先进水平。然而,结果也显示,只要知识图谱中存在语义层次结构,我们的模型就能获得更好的性能。由于几乎所有知识图谱都具有这样的层次结构,我们的模型具有广泛的应用性。
YAGO3-10数据集包含具有高关系入度的实体(Dettmers等人,2018年)。例如,预测链接任务(?,hasGender,male)有超过1000个正确答案,这使得任务具有挑战性。幸运的是,我们可以将“male”视为更高层次的实体,将预测的头实体视为更低层次的实体。通过这种方式,YAGO3-10是一个具有明显语义层次属性的数据集,我们可以期待我们的模型在这个数据集上能够表现良好。表3验证了我们的期望。ModE和HAKE都显著优于以前的最先进水平。值得注意的是,与RotatE相比,HAKE的MRR高0.050,H@1高6.0%,H@3高4.6%。
关系嵌入分析
在这部分,我们首先通过分析关系嵌入的模数,展示HAKE能够有效地模拟层次结构。然后,我们通过分析关系嵌入的相位部分,展示HAKE可以帮助我们区分处于同一层次的实体。
在图2中,我们绘制了六个关系的模数分布直方图。这些关系来自WN18RR、FB15k-237和YAGO3-10。具体来说,图2a、2c、2e和2f中的关系来自WN18RR。图2d中的关系来自FB15k-237。图2b中的关系来自YAGO3-10。我们将图2中的关系分为三组。

图2:一些关系的模分布直方图。这些关系来自WN18RR、FB15k-237和YAGO3-10数据集。图(d)中的关系是/celebrities/celebrity/celebrity friends/celebrities/friendship/friend,为了简化,我们称其为“朋友”关系。
(A)图2c和2d中的关系连接了语义层次结构中同一级别的实体;
(B) 图2a和2b中的关系表示尾实体在层次结构中处于比头实体更高的位置;
© 图2e和2f中的关系表示尾实体在层次结构中处于比头实体更低的位置。
如模型描述部分所述,我们期望在层次结构中处于较高层次的实体具有较小的模数。实验验证了我们的预期。对于ModE和HAKE,组(A)中大多数关系的条目取值接近1,导致头部实体和尾部实体具有近似的模数。在组(B)中,关系的大多数条目取值小于1,这导致头部实体的模长小于尾部实体。组(C)的情况与组(B)相反。这些结果表明,我们的模型可以捕捉知识图中的语义层次结构。此外,与ModE相比,HAKE的关系嵌入模长的方差更低,这表明HAKE可以更清晰地建模层次结构。
如上所述,组(A)中的关系反映了相同的语义层次结构,并且期望具有约1的模数。显然,仅使用模数部分很难区分由这些关系连接的实体。在图3中,我们绘制了组(A)中关系的相位。结果表明,处于层次结构同一级别的实体可以通过它们的相位进行区分,因为许多相位具有π的值。

图3:两个反映相同层次关系的分布直方图。图(a)和(b)中的关系分别来自WN18RR和FB15k-237。
实体嵌入分析
在这部分,为了进一步证明HAKE能够捕捉实体之间的语义层次关系,我们对一些实体对的嵌入进行了可视化。
我们绘制了两个模型的实体嵌入:之前的最先进的RotatE和我们提出的HAKE。RotatE将每个实体视为一组复数。由于复数可以被视为2D平面上的一个点,我们可以在2D平面上绘制实体嵌入。至于HAKE,我们已经提到它将实体映射到极坐标系统。因此,我们还可以将由HAKE生成的实体嵌入基于它们的极坐标在2D平面上进行绘制。为了公平比较,我们设置k=500。也就是说,每个图形包含500个点,实体嵌入的实际维度为1000。请注意,我们使用对数刻度来更好地显示实体嵌入之间的差异。由于所有模数的值都小于1,所以在应用对数运算后,图中较大的半径实际上将代表较小的模数。
图4展示了来自WN18RR数据集的三个三元组的可视化结果。与尾部实体相比,图4a、4b和4c中的头部实体分别处于较低层次、相似层次和较高层次的语义层次结构中。我们可以看到,在HAKE的可视化结果中存在明显的同心圆,这表明HAKE可以有效地模拟语义层次结构。然而,在RotatE中,三个子图中的实体嵌入都是混合的,使得很难区分层次结构中不同级别的实体。

图4:可视化WN18RR数据集中多个实体对的嵌入。
Ablation Studies
注解:(中文:去除研究或部分消除研究):这是一种科学研究方法,通过移除或部分移除某个组件、过程或因素,以研究该组件、过程或因素对整个系统的影响。
在这部分,我们对HAKE的模部和相位部分以及混合偏差项进行了消融研究。表4显示了在三个基准数据集上的结果。

表格4:在WN18RR、FB15k-237和YAGO3-10数据集上的消融实验结果。符号m、p和b分别表示模部、相位部分和混合偏差项。
我们可以看到,偏差可以提高HAKE在几乎所有指标上的性能。特别是,偏差在YAGO3-10数据集上提高了4.7%的H@1得分,这说明了偏差的有效性。
我们还发现,HAKE的模部在所有数据集上表现不佳,原因是它无法区分同级层次结构中的实体。当只使用相位部分时,HAKE退化为pRotatE模型(Sun等人,2019)。它比模部表现更好,因为它可以很好地模拟同级层次结构中的实体。然而,我们的HAKE模型在所有数据集上都显著优于模数部分和相位部分,这表明对于知识图谱中的语义层次建模,结合这两部分的重要性。
与其它相关工作进行比较
我们将我们的模型与TKRL模型(Xie, Liu, and Sun 2016)进行比较,这些模型也旨在建模层次结构。关于HAKE和TKRL之间的区别,请参阅相关工作部分。表5显示了HAKE和TKRL在FB15k数据集上的H@10得分。最佳表现TKRL的最高分为.734,由WHE+STC版本获得,而我们的HAKE模型的H@10得分为.884。结果显示,尽管HAKE不需要额外的信息,但它显著优于TKRL。

表5:与TKRL模型(Xie, Liu和Sun 2016)在FB15k数据集上的比较结果。RHE、WHE、RHE+STC和WHE+STC是TKRL模型的四个版本,其结果取自原始论文。
5 结论
为了在知识图中模拟语义层次结构,我们提出了一种新颖的层次感知知识图嵌入模型——HAKE,它将实体映射到极坐标系统中。实验表明,我们提出的HAKE在链接预测任务的基准数据集上显著优于几个现有的最先进的方法。进一步的研究表明,HAKE能够对语义层次结构中不同层次和同一层次的实体进行建模。
附录
在这篇附录中,我们将对关系模式、负实体嵌入和实体嵌入的模数进行分析。然后,我们将提供更多关于语义层次结构的可视化结果。
A. 关系模式分析
在这个部分,我们证明我们的HAKE模型可以推断出(对称)、反转和组合关系模式。详细的命题和证明如下。
命题1 HAKE可以推断出(对称)模式。
证明:如果r(x, y)和r(y, x)成立,我们有

然后,我们有

否则,如果r(x, y) 和¬r(y, x) 成立,我们有

命题2 HAKE可以推断出反转模式。
证明:如果r1(x, y)和r2(y, x)成立,我们有
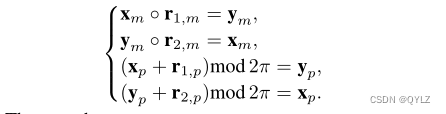
然后,我们有
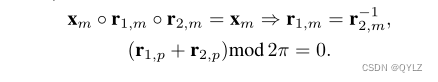
命题3 HAKE可以推断出组合模式。
证明:如果r1(x, z)、r2(x, y)和r3(y, z)成立,我们有

然后,我们有

B. 对负实体嵌入的分析
我们把相关联的实体对表示为由某种关系关联的实体对集合,把未关联的实体对表示为在训练/验证/测试数据集中不包含在任何三元组中的实体对集合。值得注意的是,未链接的巴黎可能包含有效的三元组,因为知识图是不完整的。对于已链接和未链接的实体对,我们计算两个实体的嵌入条目,这些条目具有不同的符号。图5显示了结果。
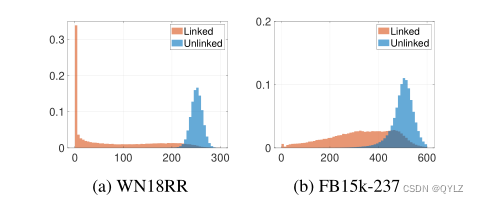
图5:链接和未链接实体对的负模量示例。对于每个实体对h和t,如果h和t之间有链接,我们将其标记为“已链接”。否则,我们将其标记为“未链接”。x轴表示i的数量,即[hm]i和[tm]i的符号不同的次数,y轴表示频率。
对于链接的实体对,正如我们所料,大多数条目具有相同的符号。由于未链接的实体对数量庞大,我们随机抽取其中一部分进行绘制。对于未链接的实体对,大约一半的条目具有不同的符号,这与随机初始化相一致。结果支持我们的假设,即实体嵌入的负符号可以帮助我们的模型区分正负三元组。
C. 实体嵌入模数的分析
图6展示了实体嵌入的模数。我们可以观察到,RotatE鼓励实体嵌入的模数相同,因为关系是在复数空间中以旋转的形式进行建模的。与RotatE相比,HAKE中实体嵌入的模数更加分散,使其在建模语义层次结构方面具有更大的潜力。

图6:实体嵌入模的直方图。与RotatE相比,HAKE中实体嵌入模的分布更加分散,使其具有更多的潜力来建模语义层次结构。
D. 更多语义层次的结果
在这一部分,我们可视化了WN18RR中的更多三元组。我们使用与正文相同的方法将头实体和尾实体绘制在2D平面上。可视化结果如图7所示,其中子标题展示了相应的三元组。从图中可以看出,与RotatE模型相比,我们的HAKE模型在不同层次和同一层次的实体建模方面表现更好。
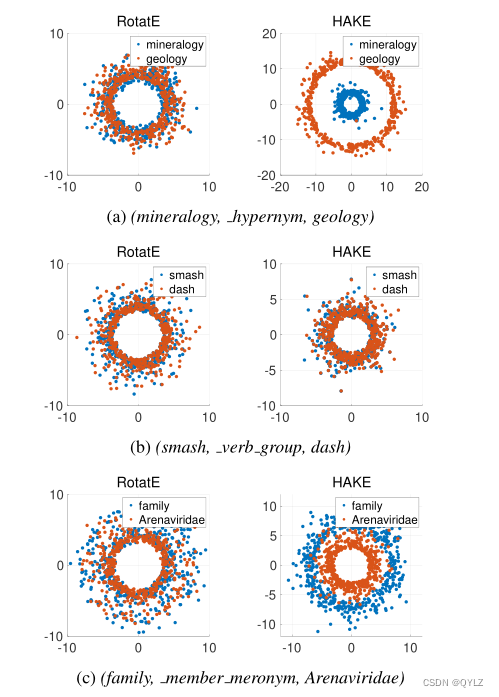
图7:WN18RR数据集中的几个实体嵌入的可视化。














 916
916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









