






【问题描述】
编写程序统计一个英文文本文件中每个单词的出现次数(词频统计),并将统计结果按单词字典序输出到屏幕上。
注:在此单词为仅由字母组成的字符序列。包含大写字母的单词应将大写字母转换为小写字母后统计。
【输入形式】
打开当前目录下文件article.txt;,从中读取英文单词进行词频统计。
【输出形式】
程序将单词统计结果按单词字典序输出到屏幕上,每行输出一个单词及其出现次数,单词和其出现次数间由一个空格分隔,出现次数后无空格,直接为回车。
【样例输入】
当前目录下文件article.txt内容如下:
Do not take to heart every thing you hear.
Do not spend all that you have.
Do not sleep as long as you want;
【样例输出】
all 1
as 2
do 3
every 1
have 1
hear 1
heart 1
long 1
not 3
sleep 1
spend 1
take 1
that 1
thing 1
to 1
want 1
you 3
【样例说明】
输出单词及其出现次数。
数据集下载:wordcount数据集
提取码:k3v2
代码实现:
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/time.h>
#include <string>
#include <cstring>
#include <fstream>
#include <sstream>
#include <iterator>
#include <vector>
#include <map>
#include <unordered_map>
#include <dirent.h>
#include<algorithm>
#include <iostream>
#include <mpi.h>
using namespace std;
void getFiles(string path, vector<string>& filenames)
{
DIR *pDir;
struct dirent* ptr;
if(!(pDir = opendir(path.c_str()))){
return;
}
while((ptr = readdir(pDir))!=0) {
if (strcmp(ptr->d_name, ".") != 0 && strcmp(ptr->d_name, "..") != 0){
filenames.push_back(path + "/" + ptr->d_name);
}
}
closedir(pDir);
}
std::string readFile(std::string filename) {
std::ifstream in(filename);
in.seekg(0, std::ios::end);
size_t len = in.tellg();
in.seekg(0);
std::string contents(len + 1, '\0');
in.read(&contents[0], len);
return contents;
}
std::vector<std::string> split(std::string const &input) {
vector<string> ret;
int i=0,j=0,n=input.length();
string temp;
while(j<n){
if ((input[j] >= 'a' && input[j] <= 'z') || (input[j] >= 'A' && input[j] <= 'Z')) {
j++;
}
else {
if (i < j) {
temp = input.substr(i, j - i);
ret.emplace_back(temp);
}
j++;
i = j;
}
}
return ret;
}
std::vector<std::string> getWords(
std::string &content, int rank, int worldsize) {
std::vector<std::string> wordList = split(content);
std::vector<std::string> re;
std::string tmp;
for (int i = 0 ; i < wordList.size(); i++) {
if (i % worldsize == rank) {
//re.push_back(wordList[i]);
tmp += " " + wordList[i];
}
}
re.push_back(tmp);
return re;
}
std::vector<pair<std::string, int>> countWords(
std::vector<std::string> &contentList) {
// split words
std::vector<std::string> wordList;
std::string concat_content;
for (auto it = contentList.begin(); it != contentList.end(); it++) {
std::string content = (*it);
concat_content += " " + content;
}
wordList = split(concat_content);
// do the word count
std::map<std::string, int> counts;
for (auto it = wordList.begin(); it != wordList.end(); it++) {
if (counts.find(*it) != counts.end()) {
counts[*it] += 1;
} else {
counts[*it] = 1;
}
}
std::vector<pair<std::string, int>> res;
for (auto it = counts.begin(); it != counts.end(); it++) {
res.push_back(std::make_pair(it->first, it->second));
}
return res;
}
std::vector<pair<std::string, int>> mergeCounts(
std::vector<pair<std::string, int>> &countListA,
std::vector<pair<std::string, int>> &countListB) {
std::map<std::string, int> counts;
for (auto it = countListA.begin(); it != countListA.end(); it++) {
counts[it->first] = it->second;
}
for (auto it = countListB.begin(); it != countListB.end(); it++) {
if (counts.find(it->first) == counts.end())
counts[it->first] = it->second;
else
counts[it->first] += it->second;
}
std::vector<pair<std::string, int>> res;
for (auto it = counts.begin(); it != counts.end(); it++) {
res.push_back(std::make_pair(it->first, it->second));
}
return res;
}
void sendLocalCounts(int from, int to,
std::vector<pair<std::string, int>> &counts) {
int num = counts.size();
MPI_Send(&num, 1, MPI_INT, to, from, MPI_COMM_WORLD);
if (num) {
int *counts_array = new int[num];
int i = 0;
for (auto it = counts.begin(); it != counts.end(); it++, i++) {
counts_array[i] = it->second;
}
MPI_Send(counts_array, num, MPI_INT, to, from, MPI_COMM_WORLD);
delete counts_array;
}
std::string words = " ";
for (auto it = counts.begin(); it != counts.end(); it++) {
words += it->first;
words += " ";
}
num = words.length();
MPI_Send(&num, 1, MPI_INT, to, from, MPI_COMM_WORLD);
if (num) {
char *_words = new char[num];
words.copy(_words, num);
MPI_Send(_words, num, MPI_CHAR, to, from, MPI_COMM_WORLD);
delete _words;
}
}
void recvCounts(int from, int to, std::vector<pair<std::string, int>> &counts) {
MPI_Status status;
int _num = 0, num = 0;
int *counts_array;
char *_words;
std::string words;
MPI_Recv(&_num, 1, MPI_INT, from, from, MPI_COMM_WORLD, &status);
if (_num) {
counts_array = new int[_num];
MPI_Recv(counts_array, _num, MPI_INT, from, from, MPI_COMM_WORLD, &status);
}
MPI_Recv(&num, 1, MPI_INT, from, from, MPI_COMM_WORLD, &status);
if (num) {
_words = new char[num];
MPI_Recv(_words, num, MPI_CHAR, from, from, MPI_COMM_WORLD, &status);
for (int _i = 0; _i < num; _i++) words+=_words[_i];
delete _words;
}
if (_num) {
std::vector<std::string> word_vec = split(words);
for (int i = 0; i < _num; i++) {
counts.push_back(std::make_pair(word_vec[i], counts_array[i]));
}
delete counts_array;
}
}
void treeMerge(int id, int worldSize,
std::vector<pair<std::string, int>> &counts) {
int participants = worldSize;
while (participants > 1) {
MPI_Barrier(MPI_COMM_WORLD);
int _participants = participants / 2 + (participants % 2 ? 1 : 0);
if (id < _participants) {
if (id + _participants < participants) {
std::vector<pair<std::string, int>> _counts;
std::vector<pair<std::string, int>> temp;
recvCounts(id + _participants, id, _counts);
temp = mergeCounts(_counts, counts);
counts = temp;
}
}
if (id >= _participants && id < participants) {
sendLocalCounts(id, id - _participants, counts);
}
participants = _participants;
}
}
int main(int argc, char *argv[]) {
int rank;
int worldSize;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &worldSize);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
/*
* Word Count for big file
*/
{
struct timeval start, stop;
gettimeofday(&start, NULL);
std::string big_file = "input.txt";
auto content = readFile(big_file);
transform(content.begin(),content.end(),content.begin(), ::tolower);
auto partContent = getWords(content, rank, worldSize);
auto counts = countWords(partContent);
treeMerge(rank, worldSize, counts);
gettimeofday(&stop, NULL);
if (rank == 0) {
fstream dataFile;
std::string out_file = "./output.txt";
dataFile.open("./output.txt", ios::out);
int num = 0;
for (auto it = counts.begin(); it != counts.end(); it++) {
//num = it->second/worldSize;
num = it->second;
dataFile << it->first << " : " << num << endl;
cout<< it->first << " : " << num << endl;
}
}
if (rank == 0) {
cout << "times: "
<< (stop.tv_sec - start.tv_sec) * 1000.0 +
(stop.tv_usec - start.tv_usec) / 1000.0
<< " ms"<< endl;
}
}
MPI_Finalize();
return 0;
}
编译:mpicxx ./filename.cpp -o ./filename
运行:mpirun -n 2 ./filename
运行结果:
Mpi:一个线程时:
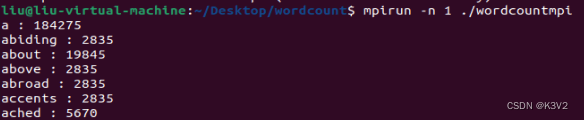
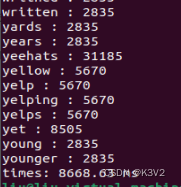
四个线程时:
![]()
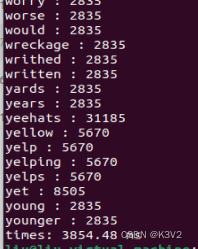
加速比:8668.63/3854.48=2.254163985803533
加速效果明显。
Mpi基本原理:
1.什么是MPI
Massage Passing Interface:是消息传递函数库的标准规范,由MPI论坛开发。
一种新的库描述,不是一种语言。共有上百个函数调用接口,提供与C和Fortran语言的绑定
MPI是一种标准或规范的代表,而不是特指某一个对它的具体实现
MPI是一种消息传递编程模型,并成为这种编程模型的代表和事实上的标准
2.MPI的特点
MPI有以下的特点:
消息传递式并行程序设计
指用户必须通过显式地发送和接收消息来实现处理机间的数据交换。
在这种并行编程中,每个并行进程均有自己独立的地址空间,相互之间访问不能直接进行,必须通过显式的消息传递来实现。
这种编程方式是大规模并行处理机(MPP)和机群(Cluster)采用的主要编程方式。
并行计算粒度大,特别适合于大规模可扩展并行算法
用户决定问题分解策略、进程间的数据交换策略,在挖掘潜在并行性方面更主动,并行计算粒度大,特别适合于大规模可扩展并行算法
消息传递是当前并行计算领域的一个非常重要的并行程序设计方式
二、MPI的基本函数
MPI调用借口的总数虽然庞大,但根据实际编写MPI的经验,常用的MPI函数是以下6个:
MPI_Init(…);
MPI_Comm_size(…);
MPI_Comm_rank(…);
MPI_Send(…);
MPI_Recv(…);
MPI_Finalize();
三、MPI的通信机制
MPI是一种基于消息传递的编程模型,不同进程间通过消息交换数据。
1.MPI点对点通信类型
所谓点对点的通信就是一个进程跟另一个进程的通信,而下面的聚合通信就是一个进程和多个进程的通信。
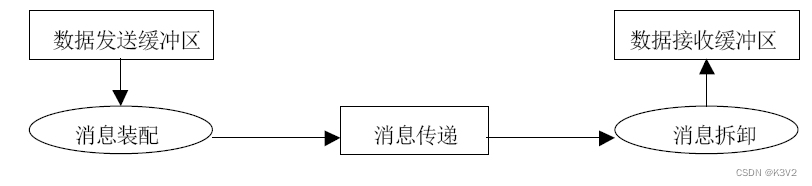
- 标准模式:
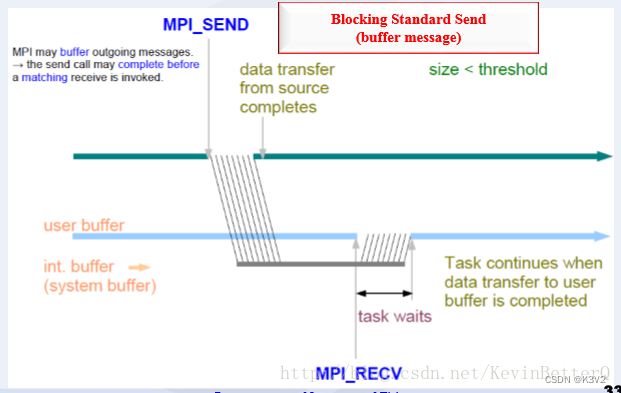
该模式下MPI有可能先缓冲该消息,也可能直接发送,可理解为直接送信或通过邮局送信。是最常用的发送方式。
由MPI决定是否缓冲消息
没有足够的系统缓冲区时或出于性能的考虑,MPI可能进行直接拷贝:仅当相应的接收完成后,发送语句才能返回。
这里的系统缓冲区是指由MPI系统管理的缓冲区。而非进程管理的缓冲区。
MPI环境定义有三种缓冲区:应用缓冲区、系统缓冲区、用户向系统注册的通信用缓冲区
MPI缓冲消息:发送语句在相应的接收语句完成前返回。
这时后发送的结束或称发送的完成== 消息已从发送方发出,而不是滞留在发送方的系统缓冲区中。
该模式发送操作的成功与否依赖于接收操作,我们称之为非本地的,即发送操作的成功与否跟本地没关系。















 1370
1370











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









