







了解
Huggingface官网: link。Huggingface是一个开源社区,它提供给了先进的NLP模型,数据集以及其他的工具:数据集,数据集的下载地址;各种预训练模型。
Hugging Face Transformer是Hugging Face的最核心的项目,使用它可以做以下的事情:
1.直接使用预训练模型进行推理
2.提供了大量预训练模型使用
3.使用预训练模型进行迁移学习
几个简单的API:
1.AutoTokenizer:用于分词
2.AutoFeatureExtractor:用于特征提取
3.AutoProcessor:用于数据处理
4.AutoModel:用于加载模型
很多情况下不能满足需求,使用HuggingFace模型做迁移学习
1.选择一个和你的任务类似的任务的预训练模型,或者直接选择一个与任务无关的基础模型
2.从原有模型中拿出主干部分
3.开始自己的下游任务,构建成新的模型
4.开始训练
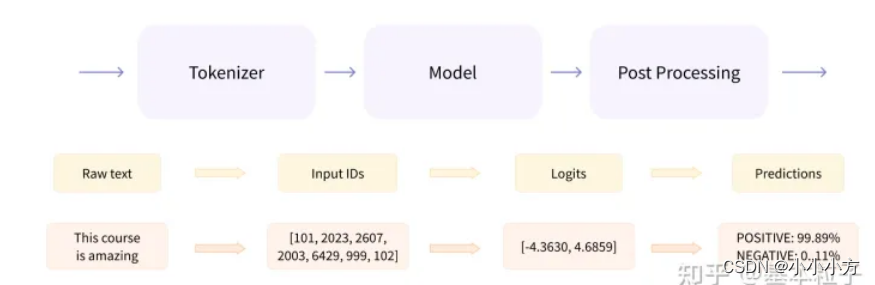
transformer模型一般有三个部分组成:1.tokennizer 2.model 3.post processing
tokenizer把输入的文本做切分,然后变成向量
Model负责根据输入的变量提取语言信息,输出logits;encoder模型、decoder模型、sequence2sequence模型
post processing根据模型输出的语义信息,执行nlp任务
主要的模型:
自回归:GPT2、transformer-XL、XLNet
自编码:bert、albert、roberta、electra等
案列
基础
# 导入模型
import torch
from transformers import BertModel,BertTokenizer,BertConfig
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
config = BertConfig.from_pretrained('bert-base-chinese')
config.update({'output_hidden_states':True}) #直接更改模型配置
model = BertModel.from_pretrained('bert-base-chinese',config=config)
# 测试MLM和NSP任务的效果
# 对单个句子编码
print(tokenizer.encode("生活的真谛是美和爱"))
# 对一组句子编码
print(tokenizer.encode_plus("生活的真谛是美和爱","说的太好了"))
# 使用英文的base模型示例一个MLM任务
from transformers import pipeline
unmasker = pipeline("fill-mask",model = "bert-base-uncased")
print(unmasker("The goal of life is [MASK].", top_k=5))
运行结果:
[{'sequence': 'the goal of life is life.', 'score': 0.1093331053853035, 'token': 2166, 'token_str': 'life'}, {'sequence': 'the goal of life is survival.', 'score': 0.039418816566467285, 'token': 7691, 'token_str': 'survival'}, {'sequence': 'the goal of life is love.', 'score': 0.03293060138821602, 'token': 2293, 'token_str': 'love'}, {'sequence': 'the goal of life is freedom.', 'score': 0.03009609691798687, 'token': 4071, 'token_str': 'freedom'}, {'sequence': 'the goal of life is simplicity.', 'score': 0.024967176839709282, 'token': 17839, 'token_str': 'simplicity'}]
from transformers import BertTokenizer
# 加载预训练字典和分词方法
tokenizer=BertTokenizer.from_pretrained(
pretrained_model_name_or_path='bert-base-chinese',
cache_dir=None,
force_download=False
)
sents = [
'选择珠江花园的原因是方便',
'笔记本的键盘确实爽',
'房间太小,其他的一般',
'今天才知道这本书还有第6卷,真的有点郁闷',
'机器背面四户被撕破了张什么标签,残胶还在'
]
print(tokenizer,sents)
运行结果:
PreTrainedTokenizer(name_or_path='bert-base-chinese', vocab_size=21128, model_max_len=512, is_fast=False, padding_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}) ['选择珠江花园的原因是方便', '笔记本的键盘确实爽', '房间太小,其他的一般', '今天才知道这本书还有第6卷,真的有点郁闷', '机器背面四户被撕破了张什么标签,残胶还在']
#编码两个句子
out = tokenizer.encode(
text=sents[0],
text_pair=sents[1],
# 当句子长度大于max_length,截断
truncation=True,
# padding补齐
padding='max_length',
add_special_tokens=True,
max_length=30,
return_tensors=None
)
print("2.",out)
print("3.",tokenizer.decode(out))
运行结果:
[101, 6848, 2885, 4403, 3736, 5709, 1736, 4638, 1333, 1728, 3221, 3175, 912, 102, 5011, 6381, 3315, 4638, 7241, 4669, 4802, 2141, 4272, 102, 0, 0, 0, 0, 0, 0]
[CLS] 选 择 珠 江 花 园 的 原 因 是 方 便 [SEP] 笔 记 本 的 键 盘 确 实 爽 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
#input_ids 编码后的向量
# token_type_ids 第一个句子和特殊位置编码为0,其余的为1
# special_token_mask 特殊位置是1,其余位置是0
# attention_mask padding的位置是0,其余的是1
# length:返回句子的长度
input_ids : [101, 6848, 2885, 4403, 3736, 5709, 1736, 4638, 1333, 1728, 3221, 3175, 912, 102, 5011, 6381, 3315, 4638, 7241, 4669, 4802, 2141, 4272, 102, 0, 0, 0, 0, 0, 0]
token_type_ids : [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0]
special_tokens_mask : [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1]
attention_mask : [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0]
length : 30
# 增强的编码函数
out = tokenizer.encode_plus(
text = sents[0],
text_pair=sents[1],
# 当句子长度大于max_length 截断
truncation=True,
padding='max_length',
max_length=30,
add_special_tokens=True,
# 可取值tf,pt,np 默认list
return_tensors=None,
return_special_tokens_mask=True,
return_token_type_ids=True,
return_attention_mask=True,
# 返回标识符的长度
return_length=True
)
for k,v in out.items():
print(k,':',v)
print("4.",tokenizer.decode(out['input_ids']))
运行的结果:
4. [CLS] 选 择 珠 江 花 园 的 原 因 是 方 便 [SEP] 笔 记 本 的 键 盘 确 实 爽 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD]
input_ids : [[101, 6848, 2885, 4403, 3736, 5709, 1736, 4638, 1333, 1728, 3221, 3175, 912, 102, 5011, 6381, 3315, 4638, 7241, 4669, 4802, 2141, 4272, 102, 0, 0, 0, 0, 0, 0], [101, 2791, 7313, 1922, 2207, 8024, 1071, 800, 4638, 671, 5663, 102, 791, 1921, 2798, 4761, 6887, 6821, 3315, 741, 6820, 3300, 5018, 127, 1318, 8024, 4696, 4638, 3300, 102]]
token_type_ids : [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
special_tokens_mask : [[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1], [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1]]
length : [24, 30]
attention_mask : [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
#批量编码句子
out = tokenizer.batch_encode_plus(
# 批量编码
# batch_text_or_text_pairs=[sents[0],sents[1]],
# 批量成对的编码
batch_text_or_text_pairs=[(sents[0],sents[1]),(sents[2],sents[3])],
add_special_tokens=True,
# 当句子长度大于max_length 截断
truncation=True,
padding='max_length',
max_length=30,
# 可取值tf,pt,np 默认list
return_tensors=None,
return_special_tokens_mask=True,
return_token_type_ids=True,
return_attention_mask=True,
# 返回标识符的长度
return_length=True
)
for k,v in out.items():
print(k,':',v)
print("5.",tokenizer.decode(out['input_ids'][0]),tokenizer.decode(out['input_ids'][1]))
运行结果:
CLS] 选 择 珠 江 花 园 的 原 因 是 方 便 [SEP] 笔 记 本 的 键 盘 确 实 爽 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD] [PAD] [CLS] 房 间 太 小 , 其 他 的 一 般 [SEP] 今 天 才 知 道 这 本 书 还 有 第 6 卷 , 真 的 有 [SEP]
# 添加新词
tokenizer.add_tokens(new_tokens=['月光','希望'])
# 添加新符号
tokenizer.add_special_tokens({'eos_token':'[EOS]'})
zidian = tokenizer.get_vocab()
# 编码新添加的词
out = tokenizer.encode(
text='月光的新希望[EOS]',
text_pair=None,
truncation=True,
padding='max_length',
add_special_tokens=True,
max_length=8,
return_tensors=None,
)
print("8.",out)
print("9.",tokenizer.decode(out))
运行结果:
[101, 21128, 4638, 3173, 21129, 21130, 102, 0]
[CLS] 月光 的 新 希望 [EOS] [SEP] [PAD]
# 情感分类任务 pipeline提供了一些不需要预训练模型就可以执行的NLP任务
from transformers import pipeline
classifier = pipeline("sentiment-analysis")
result = classifier('I hate you ')[0]
print(result)
result = classifier('I love you')[0]
print(result)
运行结果:
{'label': 'NEGATIVE', 'score': 0.9991129040718079}
{'label': 'POSITIVE', 'score': 0.9998656511306763}
中文文本分类任务
# 定义数据集
import torch.utils.data
from datasets import load_from_disk
class Dataset(torch.utils.data.Dataset):
def __init__(self,split):
self.dataset=load_from_disk('C:/Users/LIUMIAO/.cache/huggingface/datasets/ChnSentiCorp')['train']
def __len__(self):
return len(self.dataset)
def __getitem__(self, i):
text = self.dataset[i]['text']
label = self.dataset[i]['label']
return text,label
dataset = Dataset('train')
print(len(dataset),dataset[0])
运行结果
9600 ('选择珠江花园的原因就是方便,有电动扶梯直接到达海边,周围餐馆、食廊、商场、超市、摊位一应俱全。酒店装修一般,但还算整洁。 泳池在大堂的屋顶,因此很小,不过女儿倒是喜欢。 包的早餐是西式的,还算丰富。 服务吗,一般', 1)
# 加载tokenizer
from transformers import BertTokenizer
token = BertTokenizer.from_pretrained('bert-base-chinese')
print(token)
PreTrainedTokenizer(name_or_path='bert-base-chinese', vocab_size=21128, model_max_len=512, is_fast=False, padding_side='right', special_tokens={'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'})
# 定义批处理函数
def collate_fn(data):
sents =[i[0] for i in data]
labels = [i[1] for i in data]
#编码
data = token.batch_encode_plus(batch_text_or_text_pairs=sents,
truncation=True,
padding='max_length',
return_tensors='pt',
max_length=500,
return_length=True)
# input_ids:编码之后的数字
# attention_mask 补零的位置是0,其他位置是1
input_ids = data['input_ids']
attention_mask = data['attention_mask']
token_type_ids = data['token_type_ids']
labels = torch.LongTensor(labels)
return input_ids,attention_mask,token_type_ids,labels
# 定义数据加载器
loader = torch.utils.data.DataLoader(
dataset =dataset,
batch_size=16,
collate_fn=collate_fn,
shuffle=True,
drop_last=True
)
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader):
break
print(len(loader))
print(input_ids.shape,attention_mask.shape,token_type_ids.shape,labels)
运行结果:
600
torch.Size([16, 500]) torch.Size([16, 500]) torch.Size([16, 500]) tensor([0, 1, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 1, 1])
from transformers import BertModel
#加载预训练模型
pretrained = BertModel.from_pretrained('bert-base-chinese')
# 不训练,不需要计算梯度
for param in pretrained.parameters():
param.requires_grad_(False)
# 模型计算
out = pretrained(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
print(out.last_hidden_state.shape)
运行结果:
torch.Size([16, 500, 768])
# 定义下游任务模型
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
# 定义全连接层进行分本分类
self.fc = torch.nn.Linear(768,2)
def forward(self, input_ids, attention_mask, token_type_ids):
with torch.no_grad():
out = pretrained(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)
# 放入全连接层 只取第0个词的特征 与bert模型的特点有关
out = self.fc(out.last_hidden_state[:,0])
out = out.softmax(dim=1)
return out
model = Model()
# 训练
from transformers import AdamW
optimizer = AdamW(model.parameters(),lr=5e-4)
criterion = torch.nn.CrossEntropyLoss()
model.train()
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader):
out = model(input_ids= input_ids,
attention_mask = attention_mask,
token_type_ids=token_type_ids)
loss = criterion(out,labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
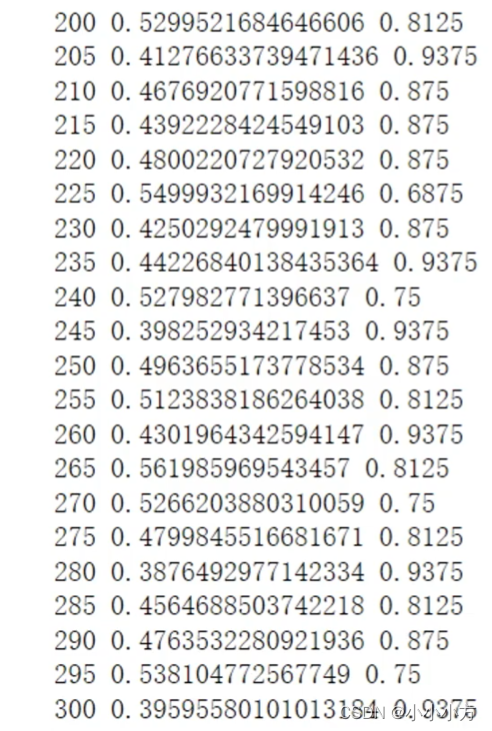
if i%5 == 0:
out = out.argmax(dim=1)
accuracy = (out == labels).sum().item() / len(labels)
print(i,loss.item(),accuracy)
if i == 300:
break
# 测试
def test():
model.eval()
correct = 0
total = 0
loader_test = torch.utils.data.DataLoader(
dataset=Dataset('validation'),
batch_size=32,
collate_fn=collate_fn,
shuffle=True,
drop_last=True
)
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader_test):
if i == 5:
break
print(i)
with torch.no_grad():
out = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids = token_type_ids)
out = out.argmax(dim =1)
correct += (out == labels).sum().items()
total += len(labels)
print(correct / total)
test()
中文文本填空
# 定义数据集
import torch.utils.data
from datasets import load_from_disk
class Dataset(torch.utils.data.Dataset):
def __init__(self,split):
dataset=load_from_disk('C:/Users/LIUMIAO/.cache/huggingface/datasets/ChnSentiCorp')['train']
# 过滤 只需要文本长度大于30
def f(data):
return len(data['text'])>30
self.dataset = dataset.filter(f)
def __len__(self):
return len(self.dataset)
def __getitem__(self, i):
text = self.dataset[i]['text']
return text
dataset = Dataset('train')
# print(len(dataset),dataset[0])
# 加载tokenizer
from transformers import BertTokenizer
# 加载字典和分词工具
token = BertTokenizer.from_pretrained('bert-base-chinese')
# 定义批处理函数
def collate_fn(data):
# 编码
data = token.batch_encode_plus(
batch_text_or_text_pairs=data,
truncation=True,
padding='max_length',
max_length=30,
return_tensors='pt',
return_length=True
)
input_ids =data['input_ids']
attention_mask = data['attention_mask']
token_type_ids = data['token_type_ids']
# 把第15个词固定的替换称mask
labels = input_ids[:,15].reshape(-1).clone()
input_ids[:,15] = token.get_vocab()[token.mask_token]
return input_ids,attention_mask,token_type_ids,labels
# 定义数据加载器
loader = torch.utils.data.DataLoader(
dataset = dataset,
batch_size=16,
collate_fn=collate_fn,
shuffle=True,
drop_last=True
)
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader):
break
print(len(loader))
print(token.decode(input_ids[0]))
print(token.decode(labels[0]))
print(input_ids,attention_mask.shape,token_type_ids.shape,labels.shape)
# 加载预训练模型
from transformers import BertModel
pretrained = BertModel.from_pretrained('bert-base-chinese')
# 不训练 不需要计算梯度
for param in pretrained.parameters():
param.requires_grad_(False)
# 模型测试
out = pretrained(input_ids = input_ids,
attention_mask= attention_mask,
token_type_ids= token_type_ids)
print(out.last_hidden_state.shape)
# 定义下游任务模型
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.decoder = torch.nn.Linear(768,token.vocab_size,bias=False)
self.bias = torch.nn.Parameter(torch.zeros(token.vocab_size))
self.decoder.bias = self.bias
def forward(self,input_ids,attention_mask,token_type_ids):
with torch.no_grad():
out = pretrained(input_ids=input_ids,
attention_mask= attention_mask,
token_type_ids=token_type_ids)
out = self.decoder(out.last_hidden_state[:,15])
return out
model = Model()
print(model(input_ids=input_ids,
attention_mask = attention_mask,
token_type_ids = token_type_ids).shape)
# 训练
from transformers import AdamW
optimizer = AdamW(model.parameters(),lr=5e-4)
criterion = torch.nn.CrossEntropyLoss()
model.train()
for epoch in range(5):
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader):
out = model(input_ids = input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)
loss = criterion(out,labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if i%50 == 0:
out = out.argmax(dim=1)
accuracy =(out == labels).sum().item() / len(labels)
print(epoch,i,loss.item(),accuracy)

#测试
def test():
model.eval()
correct=0
total=0
loader_test = torch.utils.data.DataLoader(
dataset=Dataset('test'),
batch_size = 32,
collate_fn=collate_fn,
shuffle=True,
drop_last=True
)
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader_test):
if i == 15:
break
print(i)
with torch.no_grad():
out = model(input_ids=input_ids,
attention_mask= attention_mask,
token_type_ids=token_type_ids)
out = out.argmax(dim=1)
correct += (out==labels).sum().item()
total += len(labels)
print(token.decode(input_ids[0]))
print(token.decode(labels[0]),token.decode(labels[0]))
print(correct/total)
test()

中文关系推断
# 定义数据集
import random
import torch
from datasets import load_from_disk
class Dataset(torch.utils.data.Dataset):
def __init__(self,split):
dataset=load_from_disk('C:/Users/LIUMIAO/.cache/huggingface/datasets/ChnSentiCorp')['train']
# 过滤 只需要文本长度大于40
def f(data):
return len(data['text'])>40
self.dataset = dataset.filter(f)
def __len__(self):
return len(self.dataset)
def __getitem__(self, i):
text = self.dataset[i]['text']
# 切分一句话为前半段和后半段
sentence1 = text[:20]
sentence2 = text[20:40]
label = 0
# 有一半的概率把后半句替换为一句无关的话
if random.randint(0,1) == 0:
j = random.randint(0,len(self.dataset)-1)
sentence2 = self.dataset[j]['text'][20:40]
label =1
return sentence1,sentence2,label
dataset = Dataset('train')
sentence1,sentence2,label = dataset[0]
print(len(dataset),sentence1,sentence2,label)
运行结果:
8001 选择珠江花园的原因就是方便,有电动扶梯直 接到达海边,周围餐馆、食廊、商场、超市、 0
from transformers import BertTokenizer
token = BertTokenizer.from_pretrained('bert-base-chinese')
def collate_fn(data):
sents = [i[:2] for i in data]
labels = [i[2] for i in data]
data = token.batch_encode_plus(batch_text_or_text_pairs=sents,
truncation=True,
padding='max_length',
max_length=45,
return_length=True,
return_tensors='pt',
add_special_tokens=True)
input_ids = data['input_ids']
attention_mask = data['attention_mask']
token_type_ids = data['token_type_ids']
labels = torch.LongTensor(labels)
return input_ids,attention_mask,token_type_ids,labels
# 定义数据加载器
loader = torch.utils.data.DataLoader(dataset=dataset,
batch_size = 8,
collate_fn= collate_fn,
shuffle = True,
drop_last = True)
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader):
break
print(len(loader))
print(token.decode(input_ids[0]))
print(input_ids,attention_mask,token_type_ids,labels)
运行结果:
1000
[CLS] 当 当 的 送 货 真 是 太 慢 了 , 从 下 单 到 收 到 用 了 [SEP] 8 天 , 还 是 快 递 , 而 且 我 打 了 起 码 10 个 电 话 [SEP] [PAD] [PAD] [PAD] [PAD]
from transformers import BertModel
pretrained = BertModel.from_pretrained('bert-base-chinese')
for param in pretrained.parameters():
param.requires_grad_(False)
out = pretrained(
input_ids = input_ids,
attention_mask = attention_mask,
token_type_ids = token_type_ids
)
print(out.last_hidden_state.shape)
运行结果:torch.Size([8, 45, 768])
# 下游任务模型
class Model(torch.nn.Module):
def __init__(self):
super().__init__()
self.fc = torch.nn.Linear(768,2)
def forward(self,input_ids,attention_mask,token_type_ids):
with torch.no_grad():
out = pretrained(input_ids= input_ids,
attention_mask=attention_mask,
token_type_ids = token_type_ids)
out = self.fc(out.last_hidden_state[:,0])
out = out.softmax(dim=1)
return out
model=Model()
print(model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids = token_type_ids).shape)
运行结果:
torch.Size([8, 2])
# 训练
from transformers import AdamW
optimizer = AdamW(model.parameters(),lr=5e-4)
criterion = torch.nn.CrossEntropyLoss()
model.train()
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader):
out = model(input_ids = input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids)
loss = criterion(out,labels)
loss.backward()
optimizer.step()
optimizer.zero_grad()
if i%5 == 0:
out = out.argmax(dim=1)
accuracy =(out == labels).sum().item() / len(labels)
print(i,loss.item(),accuracy)
if i == 30:
break
运行结果:
0 0.6576839685440063 0.625
5 0.5604016184806824 0.875
10 0.5890108346939087 0.75
15 0.523377001285553 0.75
20 0.48699864745140076 0.875
25 0.5254334211349487 0.875
30 0.4540831744670868 0.75
#测试
def test():
model.eval()
correct=0
total=0
loader_test = torch.utils.data.DataLoader(
dataset=Dataset('test'),
batch_size = 32,
collate_fn=collate_fn,
shuffle=True,
drop_last=True
)
for i,(input_ids,attention_mask,token_type_ids,labels) in enumerate(loader_test):
if i == 15:
break
print(i)
with torch.no_grad():
out = model(input_ids=input_ids,
attention_mask= attention_mask,
token_type_ids=token_type_ids)
out = out.argmax(dim=1)
correct += (out==labels).sum().item()
total += len(labels)
print(token.decode(input_ids[0]))
print(token.decode(labels[0]),token.decode(labels[0]))
print(correct/total)
test()
运行结果:
[CLS] 酒 店 很 干 净 , 服 务 不 错 , 所 以 决 定 今 晚 再 次 来 [SEP] 里 散 发 出 的 霉 味 ; 设 施 极 其 一 般 , 淋 浴 龙 头 拧 [SEP] [PAD] [PAD]
1
[CLS] 这 本 书 从 我 买 来 到 现 在 我 已 经 看 了 3 / 4 , 觉 [SEP] 得 还 是 很 好 的 , 发 现 原 来 只 是 自 我 感 觉 良 好 。 [SEP] [PAD] [PAD]
2
[CLS] 优 点 就 是 [UNK] 屏 , 做 工 还 可 以 , 功 能 键 挺 多 [SEP] 为 市 长 大 厦 是 比 较 新 的 酒 店 , 可 一 进 门 就 感 觉 [SEP] [PAD] [PAD] [PAD] [PAD]
3
[CLS] 从 地 段, 星 级, 价 格, 环 境 和 设 施 考 虑, 此 酒 [SEP] 店 相 当 不 错. 如 果 没 有 其 他 因 素, 下 次 还 会 再 [SEP] [PAD] [PAD]
4
[CLS] 是 我 在 北 戴 河 附 近 住 过 的 的 比 较 舒 适 的 饭 店 , [SEP] 果 还 可 以 , 开 了 一 天 , 电 池 这 里 有 一 点 点 偏 高 [SEP] [PAD] [PAD]
5
[CLS] 网 购 就 是 很 方 便 , 开 始 的 时 候 对 于 此 种 贵 重 物 [SEP] 56 独 显 , 做 [UNK] 都 错 错 有 余 。 好 本 子 , 在 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD]
6
[CLS] 性 价 比 非 常 高, 2999. 00 元, 能 够 配 置 [SEP] 象 生 活 吧 , 但 我 喜 欢 简 单 一 点 的 。 做 一 个 菜 也 [SEP] [PAD] [PAD] [PAD] [PAD] [PAD]
7
[CLS] 外 观 漂 亮, 各 功 能 指 示 灯 也 很 好 看, 价 格 较 中 [SEP] 其 实 离 晋 祠 还 很 远 。 服 务 态 度 不 大 好 。 根 本 就 [SEP] [PAD] [PAD]
8
[CLS] 第 一 次 买 烤 漆 的 本 , 比 想 象 中 好 看 , 朋 友 也 说 [SEP] 一 个 巴 掌 拍 不 响 [UNK] , 孙 寅 贵 在 替 自 己 辩 解 洗 冤 [SEP] [PAD] [PAD]
9
[CLS] 没 货 了 为 什 么 在 页 面 上 不 显 示 告 诉 啊 , 还 让 人 [SEP] 买 什 么 啊 ? 这 不 骗 人 吗 ! 对 客 户 尊 重 最 起 码 应 [SEP] [PAD] [PAD]
10
[CLS] 这 本 书 不 厚 , 但 全 部 读 下 来 , 也 需 要 些 心 力 。 [SEP] 序 又 汤 用 彤 先 生 的 儿 子 , 汤 一 介 所 述 , 父 子 同 [SEP] [PAD] [PAD]
11
[CLS] 非 常 不 错 的 营 养 食 谱 , 把 宝 宝 每 月 需 要 的 营 养 [SEP] 指 标 都 给 出 来 , 让 我 参 考 给 孩 子 搭 配 。 而 且 书 [SEP] [PAD] [PAD]
12
[CLS] 公 平 定 律 好 像 就 是 说 什 么 时 候 都 要 做 到 公 平 , [SEP] : 00 , 一 少 妇 在 里 面 捉 丈 夫 奸 在 房 , 大 喊 大 [SEP] [PAD] [PAD] [PAD]
13
[CLS] 个 人 觉 得 不 值 得 一 买 。 不 喜 欢 这 种 乱 糟 糟 的 画 [SEP] 法 。 喜 欢 这 本 书 的 , 大 多 是 单 身 生 活 的 女 子 , [SEP] [PAD] [PAD]
14
[CLS] 酒 店 很 不 错 , 大 床 房 床 挺 大 的 , 房 间 也 挺 大 , [SEP] 各 方 面 的 设 施 都 不 错 , 卫 生 间 里 有 浴 缸 和 淋 浴 [SEP] [PAD] [PAD]
0.8625














 175
175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









