







计数排序
前面我们使用的都是对比排序,也就是排序是通过数值的对比进行排序的,现在我们来学习一下通过计数方法进行排序。所谓计数排序也就是通过计数的方式来进行排序输出。思路:通过创建一个计数器(列表实现),然后统计出对应的数值出现的次数,以此得到一个完整的计数器,然后从小到大进行输出。
通过下图我们可以直观理解:
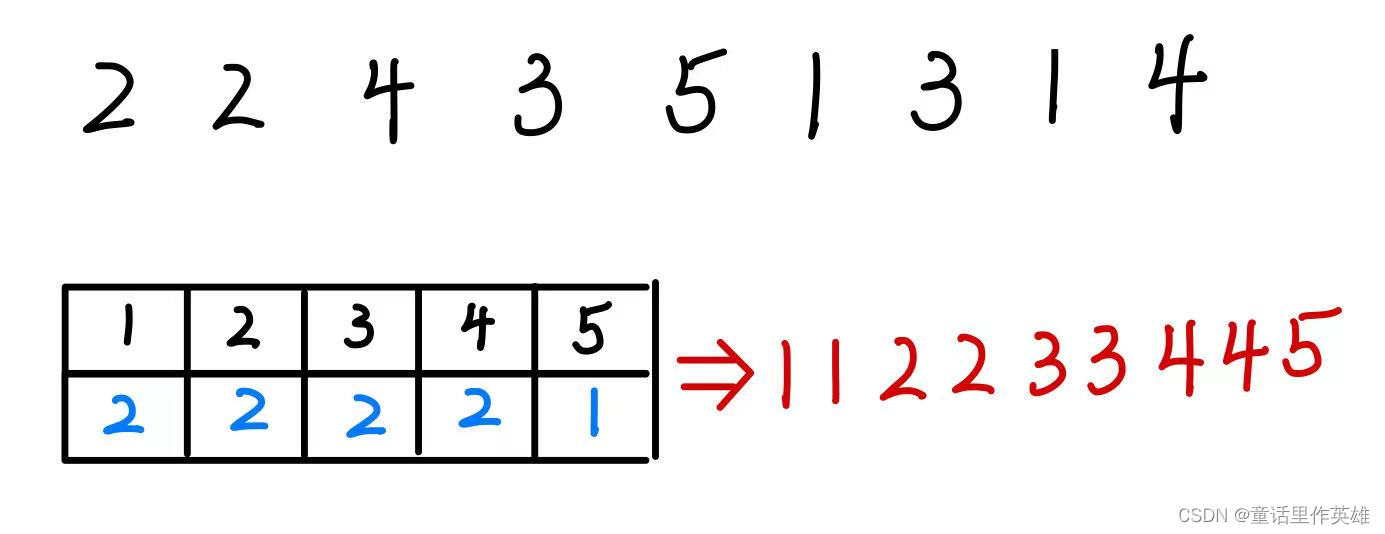
代码实现如下:
# 时间复杂度为:O(n)
def count_sort(li,max_count): # 我们输入列表和最大值
count = [0 for _ in range(max_count+1)]
for val in li:
count[val] += 1
li.clear()
for ind,val in enumerate(count):
for i in range(val):
li.append(ind)
return li
# 主函数调用
import random
a= [random.randint(0,101) for i in range(100)] # randint只左不右
print(a)
b = count_sort(a,100)
print(b)
为什么时间复杂度是n,而不是n2,因为n是列表长度,第一个for循环是n,但是第二个for循环虽然嵌套了,但是其实总体遍历也是整个列表,也就是时间复杂度也是n,所以总体的时间复杂度就是n。
不足:1、计数排序存在一些限制,会额外占用一些空间来存储计数器(新列表);2、集合的空间比较有限,如果多了小数点,那么整个统计的过程将会更加占用内存,并且对于一些分布不均匀的情况,也会浪费大量内存。
桶排序
桶排序是基于计数排序的改进,将元素先分在不同的桶中,再对每个桶中的元素排序。个人理解为:计数排序是将具体的值进行计数,而桶排序则是不仅限于具体的值,而是变成一个区间,然后再对这个区间里面的数值进行排序。
我们可以通过下图进行理解:
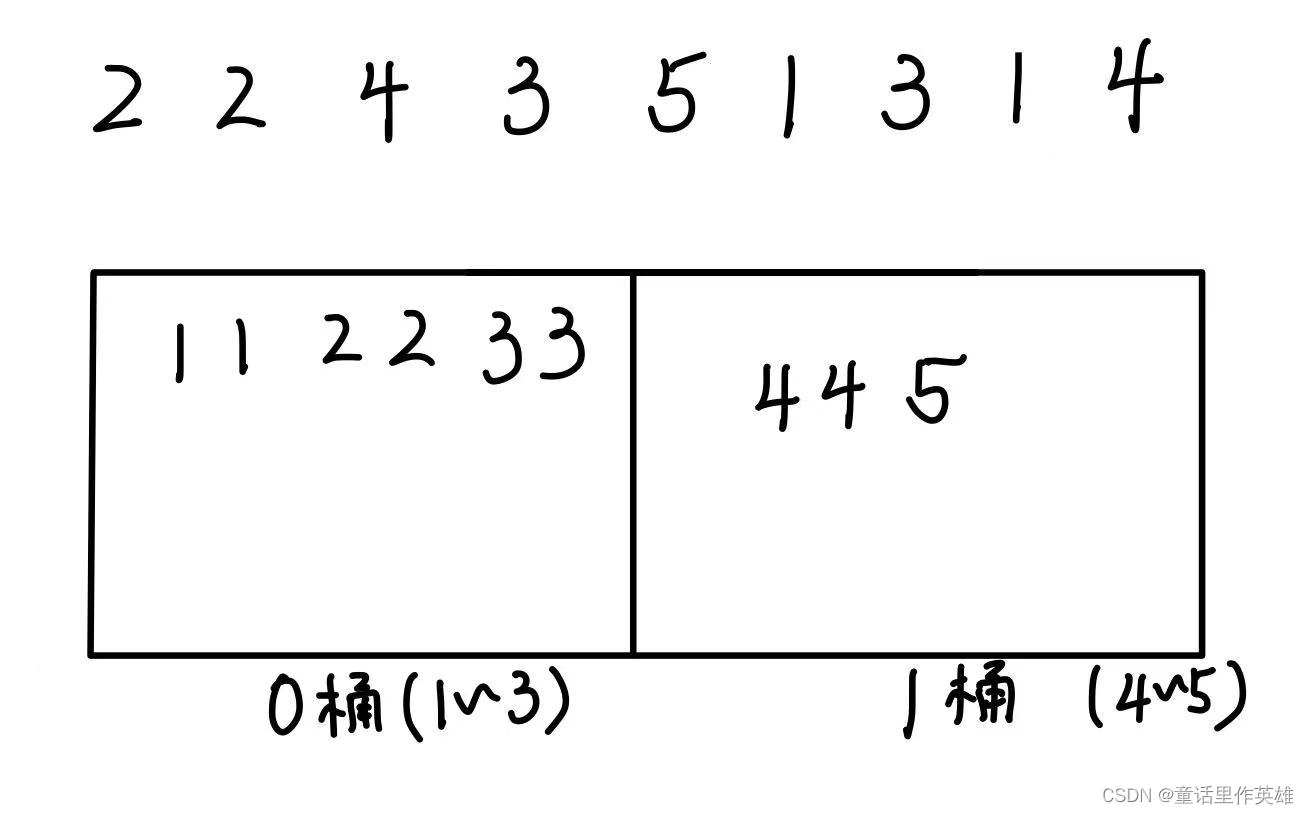
代码实现如下:
# 平均时间复杂度为:O(n+k),最坏时间复杂度为:O(n^2),空间复杂度为:O(nk)
def bucket_sort(li,n,max_num): # n表示为分多少桶,max_num为最大的数
buckets = [[] for _ in range(n)] # 使用二维矩阵来表示n个空桶
for val in li :
i = min(val//(max_num//n),n-1) # 表示放在第几号桶,min是为了防止在最极限情况下分组错误
# 例如:将10000分为100个组,在分组后10000会在第100号桶,但是最大的桶是99号桶(从0开始排序)
buckets[i].append(val)
for j in range(len(buckets[i])-1,0,-1):
if buckets[i][j] < buckets[i][j-1]:
buckets[i][j],buckets[i][j-1] = buckets[i][j-1],buckets[i][j] # python支持同一时刻两个变量进行互换
else:
break
sorted_li = []
for buc in buckets :
sorted_li.extend(buc) # 或者可以使用sorted_li += buc
return sorted_li
# 主函数
import random
li = [random.randint(0,10001) for i in range(10000)]
print(li[:100])
li_sorted = bucket_sort(li,100,10000)
print(li_sorted[:100])
相对于计数排序,桶排序可以使用的范围更加广,因为不需要确切的去获取一个一个的数值,只要判断是否在区间内即可。
不足:但是还是有着自己的局限,只有在数据分布均衡的这种特殊情况下使用比较合适,当数据分布不均衡的时候,效果会比较差,就可能变成了普通的排序方法。
基数排序
基数排序是一种多关键字排序,即先以个位数进行分桶,再以十位数进行分桶,以此类推。
我们可以通过下图进行理解:根据箭头从左往右的顺序进行遍历,绿色框是列表,蓝色框是分类标准,黄色的是对应数值被分类的位置。
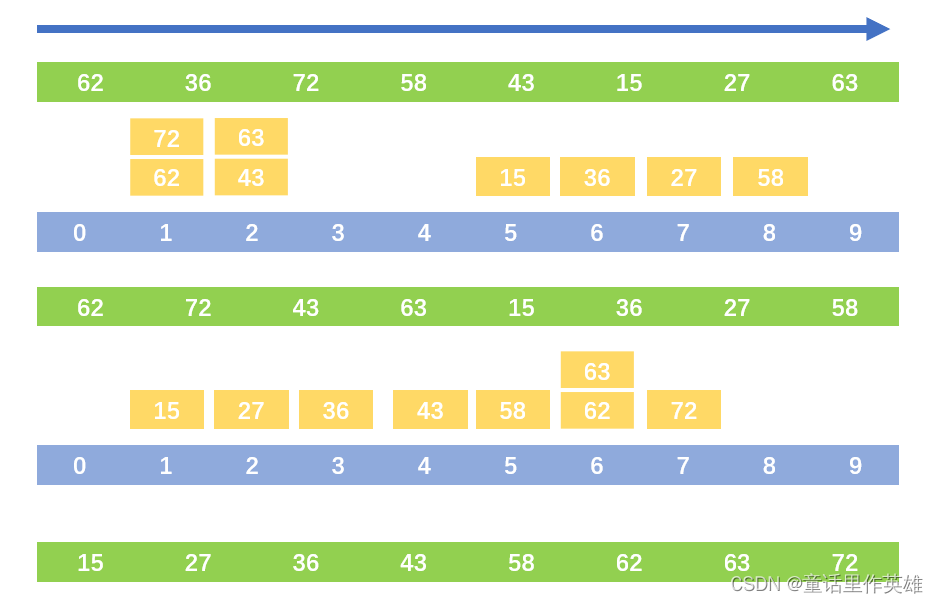
那么要是我们的数据的位数不同怎么办,不用担心,我们可以通过低位数前面自动补零完成,但是在代码中我们不需要考虑这个问题,因为我们可以通过取余的方式去得到对应的位数大小。
代码如下:
# 时间复杂度:O(kn),空间复杂度:O(k+n),k是循环次数(位数)
def radix_sort(li):
max_num = max(li) # 找最大值,有几位数就有几次循环
it = 0
while 10**it <= max_num:
buckets = [[] for _ in range(10)]
for val in li:
digit = (val // 10**it) % 10
buckets[digit].append(val)
li.clear()
for buc in buckets:
li.extend(buc)
it += 1
return li
# 主函数
import random
li = [random.randint(0,10001) for i in range(10000)]
print(li[:100])
li_sorted = radix_sort(li)
print(li_sorted[:100])















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









