






第一种结构:
标签名为大类名
-train
-class1
-1.jpg
-2.jpg
-class2
-1.jpg
-2.jpg
-class3
-1.jpg
-2.jpg
-val
-1.jpg
-2.jpg
可根据我们的代码提取出相关的label(通过数字的方式去定义),存放于csv或者txt文件中
# -*-coding:utf-8-*-
import os
import os.path
import pandas as pd
def write_train_txt(content, filename, mode='w'):
"""保存txt数据
:param content:需要保存的数据,type->list
:param filename:文件名
"""
with open(filename, mode) as f:
for line in content:
str_line = ""
for col, data in enumerate(line):
if not col == len(line) - 1:
# 以空格作为分隔符
str_line = str_line + str(data) + " "
else:
# 每行最后一个数据用换行符“\n”
str_line = str_line + str(data) + "\n"
f.write(str_line)
def write_val_txt(content, filename, mode='w'):
"""保存txt数据
:param content:需要保存的数据,type->list
:param filename:文件名
"""
str_line = ''
with open(filename, mode) as f:
for line in content:
str_line = str_line + str(line) + "\n"
f.write(str_line)
def get_train_files_list(dir):
'''
实现遍历dir目录下,所有文件(包含子文件夹的文件)
:param dir:指定文件夹目录
:return:包含所有文件的列表->list
'''
# parent:父目录, filenames:该目录下所有文件夹,filenames:该目录下的文件名
files_list = [] #写入文件的数据
class_floder = os.listdir(dir)
class_path = [os.path.join(dir,i) for i in class_floder]
# print(class_floder) # ['clothes', 'pants', 'shoes']
# print(class_path) # ['./mydata/train/clothes', './mydata/train/pants', './mydata/train/shoes']
for i in range(len(class_floder)):
curr_file = class_floder[i]
# print(curr_file)
if curr_file == "shoes":
labels = 0
elif curr_file == "pants":
labels = 1
elif curr_file == "clothes":
labels = 2
curr_file = os.path.join(dir, curr_file)
file_list = os.listdir(curr_file)
# print(file_list) # ['679005d71e2b58620cbc99de3297318c.jpeg', 'cfc38e8c6dbac6e455cb591c0c6865a4.jpeg', '019d3044ebf4e44d2fa2cd16df60252d.jpeg']
for file_name in file_list:
files_list.append([os.path.join(class_path[i], file_name), labels])
# print(files_list) # [['./mydata/train/clothes/679005d71e2b58620cbc99de3297318c.jpeg', 2], ['./mydata/train/clothes/cfc38e8c6dbac6e455cb591c0c6865a4.jpeg', 2], ['./mydata/train/clothes/019d3044ebf4e44d2fa2cd16df60252d.jpeg', 2]]
#写入csv文件
path = "%s" % os.path.join(class_path[i], file_name)
label = "%d" % labels
list = [path, label]
data = pd.DataFrame([list])
data.to_csv("./mydata/train.csv", mode='a', header=False, index=False)
return files_list
def get_val_files_list(dir):
files_list = [] # 写入文件的数据
class_path = os.listdir(dir)
for file_name in class_path:
files_list.append(os.path.join(dir, file_name))
#写入csv文件
path = "%s" % os.path.join(dir, file_name)
list = [path]
data = pd.DataFrame([list])
data.to_csv("./mydata/val.csv", mode='a', header=False, index=False)
return files_list
if __name__ == '__main__':
# 训练集trian(带标签)
# 提前创建csv文件
df = pd.DataFrame(columns=['path', 'label'])
df.to_csv("./mydata/train.csv", index=False)
train_dir = './mydata/train'
train_txt = './mydata/train.txt'
train_data = get_train_files_list(train_dir) # 顺便写入csv文件
# 写入并保存txt文件
write_train_txt(train_data, train_txt, mode='w')
# 验证集val(不带标签)
df = pd.DataFrame(columns=['path'])
df.to_csv("./mydata/val.csv", index=False)
val_dir = './mydata/val'
val_txt = './mydata/val.txt'
val_data = get_val_files_list(val_dir) # 顺便写入csv文件
write_val_txt(val_data, val_txt, mode='w')
文件存放路径为:
-train
-class1
-1.jpg
-2.jpg
-class2
-1.jpg
-2.jpg
-class3
-1.jpg
-2.jpg
-val
-1.jpg
-2.jpg
-train.txt
-val.txt
-train.csv
-val.csv
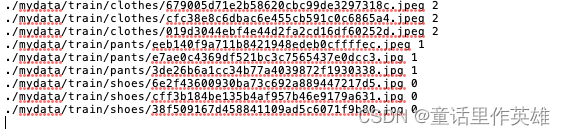
train.txt文件
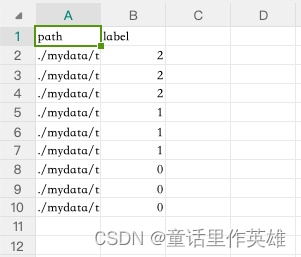
train.csv文件
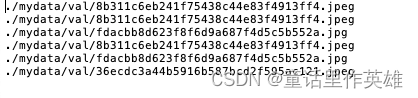
val.txt文件
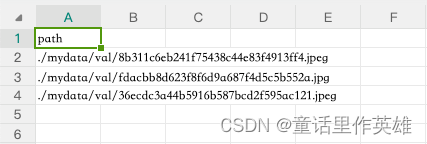
val.csv文件
第二种结构
标签名为大类下的小类名
-train
-class1
-class1_1
-1.jpg
-2.jpg
-class1_2
-1.jpg
-2.jpg
-class2
-class2_1
-1.jpg
-2.jpg
-class3
-class3_1
-1.jpg
-2.jpg
# -*-coding:utf-8-*-
import os
import os.path
import pandas as pd
def check_DS_Store(list):
li = list
for i in list:
if '.DS_Store' in i:
li.remove(i)
return li
def write_train_txt(content, filename, mode='w'):
"""保存txt数据
:param content:需要保存的数据,type->list
:param filename:文件名
"""
with open(filename, mode) as f:
for line in content:
str_line = ""
for col, data in enumerate(line):
if not col == len(line) - 1:
# 以空格作为分隔符
str_line = str_line + str(data) + " "
else:
str_line = str_line + str(data) + "\n"
f.write(str_line)
def get_train_files_list(dir):
'''
实现遍历dir目录下,所有文件(包含子文件夹的文件)
:param dir:指定文件夹目录
:return:包含所有文件的列表->list
'''
# parent:父目录, filenames:该目录下所有文件夹,filenames:该目录下的文件名
files_list = [] #写入文件的数据
class_floder = os.listdir(dir)
class_floder = check_DS_Store(class_floder)
# print(class_floder)
class_path = [os.path.join(dir,i) for i in class_floder]
class_path = check_DS_Store(class_path)
# print(class_path)
label = 0
for i in range(len(class_path)):
temp = os.listdir(class_path[i])
temp = check_DS_Store(temp)
# print(temp)
for j in range(len(temp)):
curr_file_folder = os.path.join(class_path[i], temp[j])
curr_file_folder = check_DS_Store(curr_file_folder)
# print(curr_file_folder)
for k in os.listdir(curr_file_folder):
curr_filename = os.path.join(curr_file_folder, k)
# curr_filename = check_DS_Store(curr_filename)
# print(curr_filename)
files_list.append([curr_filename,label])
label += 1
# print(files_list)
return files_list
if __name__ == '__main__':
train_dir = './mydata/Lacoste4大类AI标签训练样本'
train_txt = './mydata/all_image.txt'
train_data = get_train_files_list(train_dir)
# print(train_data)
# 写入并保存txt文件
write_train_txt(train_data, train_txt, mode='w')















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









