






一。创建爬虫
创建包 进入包 创建项目 cd项目 创建爬虫 修改设置
二。初体验
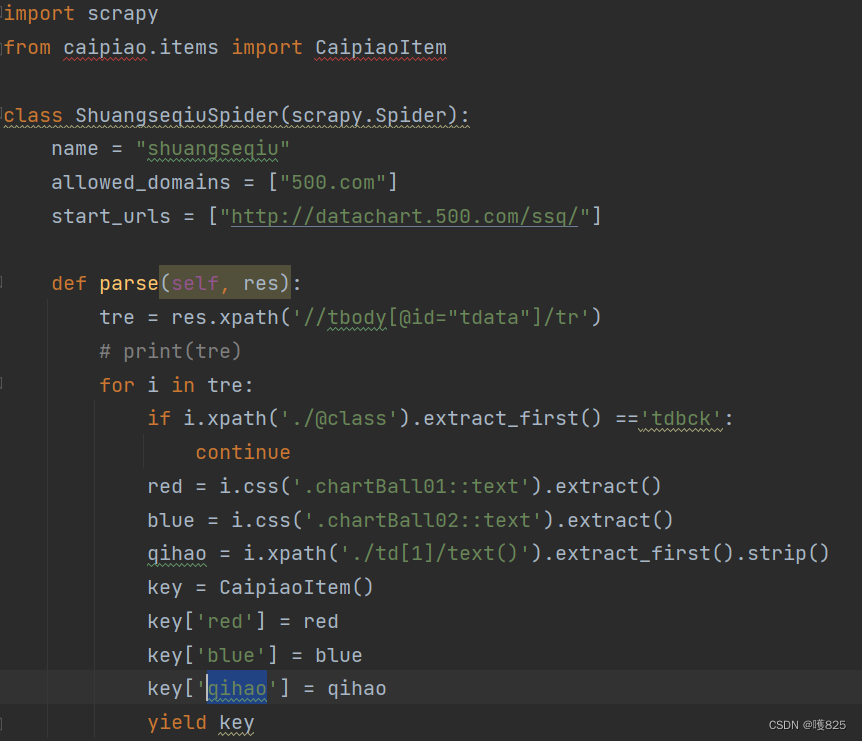

三。学习笔记
2.yield request item none
记得去setting打开通道!
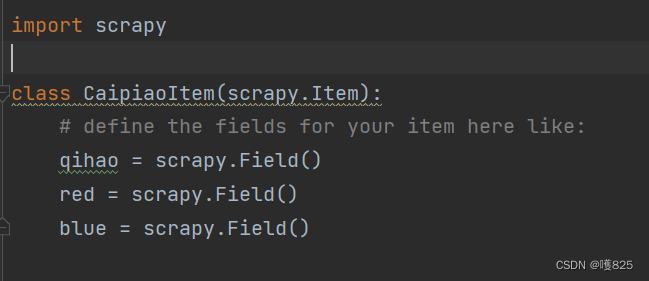
3.items
name = scrapy.Field() 相当于设置字典的key
key = caipiaoItem()
key['key'] = 值
yield name
4.存储数据的方案:
1.数据存储到csv中 数据分析
2.数据存储到mysql数据库中 业务逻辑
3.数据存储到mangodb数据库中 大批量的数据存储
4.文件存储 图片,视频
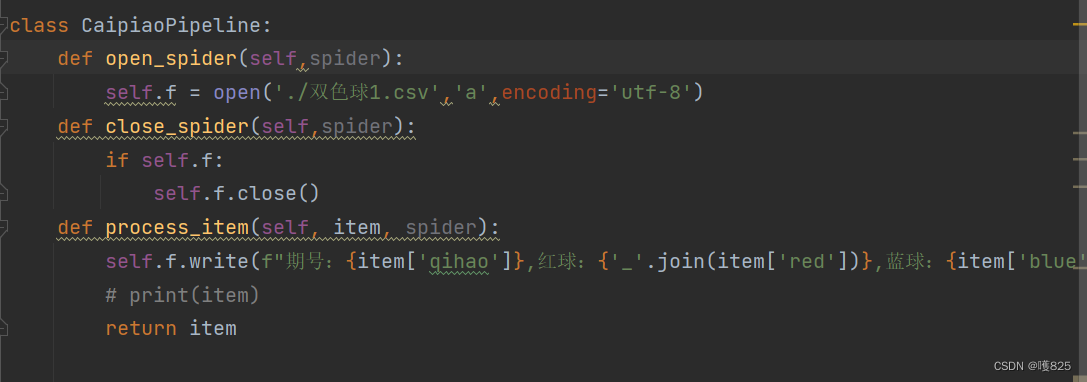
1.1创建一个后缀名.csv文件,
with open ("./11.csv","a",encoding = "utf-8") as f:
只能用a,数据是一条一条从通道进来的,如果用w每一次写入都会清楚之前写入的数据
1.2"在爬虫开始的时候就已经打开了文件,数据一条条从通道过来,直接写入文件,而不是来一条打开一次文件"
def open_spider(self,spider):
self.f = open('./双色球1.csv','a',encoding='utf-8')
def close_spider(self,spider):
if self.f:
self.f.close()
避免了这个问题















 197
197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











