






官方学习网址
https://parsel.readthedocs.io/en/latest/usage.html
提取文本数据

a = response.xpath('//title/text()')

返回的是一个selector对象
你也可以用CSS来问同样的事情
a = response.css('title::text')
若要实际提取文本数据 .get().getall()
a = response.xpath('//title/text()').get()

返回的是字符串
.get()始终返回单个结果;如果有多个匹配项, 返回第一个匹配项的内容;如果没有匹配项,则无 被返回。 返回包含所有结果的列表。.getall()
快速选择嵌套数据 .xpath().css()
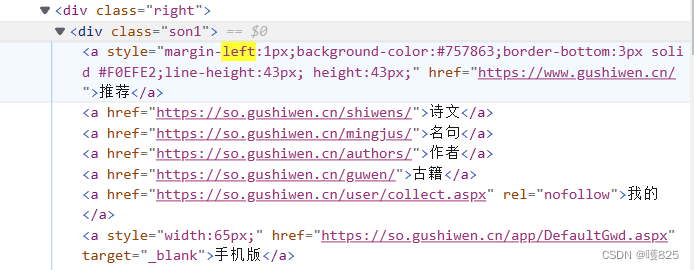
实例
a3 = response.css('.son1').xpath('./a/text()').getall()

如果只想提取第一个匹配的元素,可以调用 选择器 .get().extract_first()
a3 = response.css('.son1').xpath('./a/text()').get()
a3 = response.css('.son1').xpath('./a/text()').extract_first()
返回未找到元素,则返回:None 使用 .get() is None
作为快捷方式,也可直接在选择器列表中使用; 它返回第一个匹配元素的属性:.attrib
基本URL和一些图像链接
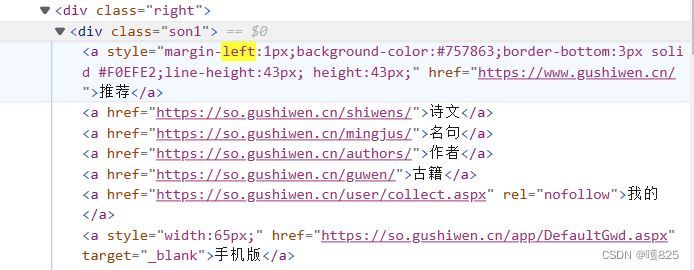
a4 = response.xpath('//div[@class="son1"]/a/@href').getall()
a4 = response.xpath('//div[@class="son1"]').css('a::attr(href)').getall()

对于css 要选择文本节点,请使用::text
要选择属性值,请使用 其中名称为 要为其输入值的属性的名称::attr(name)
这些伪元素是特定于 Scrapy/Parsell 的。 它们很可能不适用于其他库,如 lxml 或 PyQuery。
*::text 选择当前选择器上下文的所有后代文本节点:
a::attr(href)选择后代链接的 HREF 属性值
将选择器与正则表达式结合使用
节点:
a::attr(href)选择后代链接的 HREF 属性值
将选择器与正则表达式结合使用
当 XPath 或不够时,该函数可能非常有用。test() starts-with() contains()















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











