







目录
什么是Producer、Consumer、Broker、Topic、Partition?
Kafka 是什么?主要应用场景有哪些?
Kafka 是一个分布式流式处理平台。这到底是什么意思呢?
流平台具有三个关键功能:
- 消息队列:发布和订阅消息流,这个功能类似于消息队列,这也是 Kafka 也被归类为消息队列的原因。
- 容错的持久方式存储记录消息流: Kafka 会把消息持久化到磁盘,有效避免了消息丢失的风险·。
- 流式处理平台: 在消息发布的时候进行处理,Kafka 提供了一个完整的流式处理类库。
Kafka 主要有两大应用场景:
- 消息队列 :建立实时流数据管道,以可靠地在系统或应用程序之间获取数据。
- 数据处理: 构建实时的流数据处理程序来转换或处理数据流。
和其他消息队列相比,Kafka的优势在哪里?
我们现在经常提到 Kafka 的时候就已经默认它是一个非常优秀的消息队列了,我们也会经常拿它给 RocketMQ、RabbitMQ 对比。我觉得 Kafka 相比其他消息队列主要的优势如下:
- 极致的性能 :基于 Scala 和 Java 语言开发,设计中大量使用了批量处理和异步的思想,最高可以每秒处理千万级别的消息。
- 生态系统兼容性无可匹敌 :Kafka 与周边生态系统的兼容性是最好的没有之一,尤其在大数据和流计算领域。
发布-订阅模型:Kafka 消息模型
发布-订阅模型主要是为了解决队列模型存在的问题。

发布订阅模型(Pub-Sub) 使用主题(Topic) 作为消息通信载体,类似于广播模式;发布者发布一条消息,该消息通过主题传递给所有的订阅者,在一条消息广播之后才订阅的用户则是收不到该条消息的。
在发布 - 订阅模型中,如果只有一个订阅者,那它和队列模型就基本是一样的了。所以说,发布 - 订阅模型在功能层面上是可以兼容队列模型的。
Kafka 采用的就是发布 - 订阅模型。
RocketMQ 的消息模型和 Kafka 基本是完全一样的。唯一的区别是 Kafka 中没有队列这个概念,与之对应的是 Partition(分区)。
什么是Producer、Consumer、Broker、Topic、Partition?
Kafka 将生产者发布的消息发送到 Topic(主题) 中,需要这些消息的消费者可以订阅这些 Topic(主题),如下图所示:
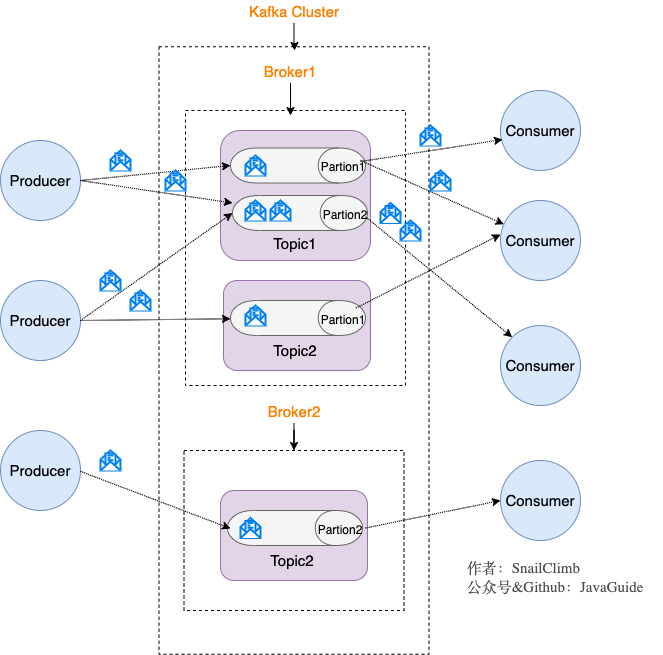
上面这张图也为我们引出了,Kafka 比较重要的几个概念:
- Producer(生产者) : 产生消息的一方。
- Consumer(消费者) : 消费消息的一方。
- Broker(代理) : 可以看作是一个独立的 Kafka 实例。多个 Kafka Broker 组成一个 Kafka Cluster。
同时,你一定也注意到每个 Broker 中又包含了 Topic 以及 Partition 这两个重要的概念:
- Topic(主题) : Producer 将消息发送到特定的主题,Consumer 通过订阅特定的 Topic(主题) 来消费消息。
- Partition(分区) : Partition 属于 Topic 的一部分。一个 Topic 可以有多个 Partition ,并且同一 Topic 下的 Partition 可以分布在不同的 Broker 上,这也就表明一个 Topic 可以横跨多个 Broker 。这正如我上面所画的图一样。
划重点:Kafka 中的 Partition(分区) 实际上可以对应成为消息队列中的队列。这样是不是更好理解一点?
Kafka 的多副本机制了解吗?带来了什么好处?
还有一点我觉得比较重要的是 Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader 的家伙,其他副本称为 follower。我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。
生产者和消费者只与 leader 副本交互。你可以理解为其他副本只是 leader 副本的拷贝,它们的存在只是为了保证消息存储的安全性。当 leader 副本发生故障时会从 follower 中选举出一个 leader,但是 follower 中如果有和 leader 同步程度达不到要求的参加不了 leader 的竞选。
Kafka 的多分区(Partition)以及多副本(Replica)机制有什么好处呢?
- Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力(负载均衡)。
- Partition 可以指定对应的 Replica 数, 这也极大地提高了消息存储的安全性, 提高了容灾能力,不过也相应的增加了所需要的存储空间。
Zookeeper 在 Kafka 中的作用知道吗?
ZooKeeper 主要为 Kafka 提供元数据的管理的功能。
从图中我们可以看出,Zookeeper 主要为 Kafka 做了下面这些事情:
- Broker 注册 :在 Zookeeper 上会有一个专门用来进行 Broker 服务器列表记录的节点。每个 Broker 在启动时,都会到 Zookeeper 上进行注册,即到/brokers/ids 下创建属于自己的节点。每个 Broker 就会将自己的 IP 地址和端口等信息记录到该节点中去
- Topic 注册 : 在 Kafka 中,同一个Topic 的消息会被分成多个分区并将其分布在多个 Broker 上,这些分区信息及与 Broker 的对应关系也都是由 Zookeeper 在维护。比如我创建了一个名字为 my-topic 的主题并且它有两个分区,对应到 zookeeper 中会创建这些文件夹:
/brokers/topics/my-topic/Partitions/0、/brokers/topics/my-topic/Partitions/1 - 负载均衡 :上面也说过了 Kafka 通过给特定 Topic 指定多个 Partition, 而各个 Partition 可以分布在不同的 Broker 上, 这样便能提供比较好的并发能力。 对于同一个 Topic 的不同 Partition,Kafka 会尽力将这些 Partition 分布到不同的 Broker 服务器上。当生产者产生消息后也会尽量投递到不同 Broker 的 Partition 里面。当 Consumer 消费的时候,Zookeeper 可以根据当前的 Partition 数量以及 Consumer 数量来实现动态负载均衡。
Kafka 如何保证消息的消费顺序?
Kafka 中发送 1 条消息的时候,可以指定 topic, partition, key,data(数据) 4 个参数。如果你发送消息的时候指定了 Partition 的话,所有消息都会被发送到指定的 Partition。并且,同一个 key 的消息可以保证只发送到同一个 partition,这个我们可以采用表/对象的 id 来作为 key 。
对于如何保证 Kafka 中消息消费的顺序,有了下面两种方法:
- 1 个 Topic 只对应一个 Partition。
- (推荐)发送消息的时候指定 key/Partition。
Kafka 如何保证消息不丢失
生产者丢失消息的情况
生产者(Producer) 调用send方法发送消息之后,消息可能因为网络问题并没有发送过去。
所以,我们不能默认在调用send方法发送消息之后消息消息发送成功了。为了确定消息是发送成功,我们要判断消息发送的结果。但是要注意的是 Kafka 生产者(Producer) 使用 send 方法发送消息实际上是异步的操作,我们可以通过 get()方法获取调用结果,但是这样也让它变为了同步操作。
SendResult<String, Object> sendResult = kafkaTemplate.send(topic, o).get();
if (sendResult.getRecordMetadata() != null) {
logger.info("生产者成功发送消息到" + sendResult.getProducerRecord().topic() + "-> " + sendRe
sult.getProducerRecord().value().toString());
}但是一般不推荐这么做! 可以采用为其添加回调函数的形式,
示例代码如下:
ListenableFuture<SendResult<String, Object>> future = kafkaTemplate.send(topic, o);
future.addCallback(result -> logger.info("生产者成功发送消息到topic:{} partition:{}的消息", result.getRecordMetadata().topic(), result.getRecordMetadata().partition()),
ex -> logger.error("生产者发送消失败,原因:{}", ex.getMessage()));如果消息发送失败的话,我们检查失败的原因之后重新发送即可!
另外这里推荐为 Producer 的retries (重试次数)设置一个比较合理的值,一般是 3 ,但是为了保证消息不丢失的话一般会设置比较大一点。设置完成之后,当出现网络问题之后能够自动重试消息发送,避免消息丢失。另外,建议还要设置重试间隔,因为间隔太小的话重试的效果就不明显了,网络波动一次你3次一下子就重试完了。
消费者丢失消息的情况
我们知道消息在被追加到 Partition(分区)的时候都会分配一个特定的偏移量(offset)。偏移量(offset)表示 Consumer 当前消费到的 Partition(分区)的所在的位置。Kafka 通过偏移量(offset)可以保证消息在分区内的顺序性。
当消费者拉取到了分区的某个消息之后,消费者会自动提交了 offset。自动提交的话会有一个问题,试想一下,当消费者刚拿到这个消息准备进行真正消费的时候,突然挂掉了,消息实际上并没有被消费,但是 offset 却被自动提交了。
解决办法也比较粗暴,我们手动关闭闭自动提交 offset,每次在真正消费完消息之后之后再自己手动提交 offset 。 但是,细心的朋友一定会发现,这样会带来消息被重新消费的问题。比如你刚刚消费完消息之后,还没提交 offset,结果自己挂掉了,那么这个消息理论上就会被消费两次。
Kafka 弄丢了消息
我们知道 Kafka 为分区(Partition)引入了多副本(Replica)机制。分区(Partition)中的多个副本之间会有一个叫做 leader 的家伙,其他副本称为 follower。我们发送的消息会被发送到 leader 副本,然后 follower 副本才能从 leader 副本中拉取消息进行同步。生产者和消费者只与 leader 副本交互。你可以理解为其他副本只是 leader 副本的拷贝,它们的存在只是为了保证消息存储的安全性。
试想一种情况:假如 leader 副本所在的 broker 突然挂掉,那么就要从 follower 副本重新选出一个 leader ,但是 leader 的数据还有一些没有被 follower 副本的同步的话,就会造成消息丢失。
设置 acks = all
acks 的默认值即为1,代表我们的消息被leader副本接收之后就算被成功发送。当我们配置 acks = all 代表则所有副本都要接收到该消息之后该消息才算真正成功被发送。
Kafka 如何保证消息不重复消费
数据重复消费的情况,如果处理
(1)去重:将消息的唯一标识保存到外部介质中,每次消费处理时判断是否处理过;
(2)不管:大数据场景中,报表系统或者日志信息丢失几条都无所谓,不会影响最终的统计分析结果。
消息队列应用的场景:
大致分为三类:解耦、异步、削峰。
解耦:
发布-订阅模式(Pub-Sub)。生产者生成和发送消息到消息队列,消费者从消息队列中取走消息进行处理,称为消费,使用消息队列将“生产者”和“消费者”之间的操作关联解耦,易于扩展。
引入 MQ,A 系统产生一条数据,发送到 MQ 里面去,每个子系统加上对消息队列中消息进行订阅,持续监听就可以了,哪个系统需要数据自己去 MQ 里面消费。如果新系统需要数据,直接从 MQ 里消费即可;如果某个系统不需要这条数据了,就取消对 MQ 消息的消费即可。
A系统不需要去考虑要给谁发送数据,不需要维护这个代码,也不需要考虑消费端是否调用成功、失败超时等情况,我只负责把信息放到MQ里即可。
异步:
削峰:
比如:系统有售票业务,平时每天QPS也就50左右,系统风平浪静。结果每次一到春运抢票,每秒并发请求数量突然会暴增。如果系统是直接基于 MySQL 的,大量的请求直接打到 MySQL,比如一般MySQL能抗2000条请求,现在每秒10000 条 SQL,可能就直接把 MySQL 给打死了,导致系统崩溃。但是高峰期一过就又没人了,QPS回到50,对整个系统几乎没有任何的压力。
使用消息队列,A 系统可以根据自己的承载能力,从 MQ 中慢慢拉取请求。
RocketMQ实现原理:
RocketMQ由NameServer注册中心集群、Producer生产者集群、Consumer消费者集群和若干Broker(RocketMQ进程)组成,它的架构原理是这样的:
Broker在启动的时候去向所有的NameServer注册,并保持长连接,每30s发送一次心跳。
Producer在发送消息的时候从NameServer获取Broker服务器地址,根据负载均衡算法选择一台服务器来发送消息。
Conusmer消费消息的时候同样从NameServer获取Broker地址,然后主动拉取消息来消费。















 339
339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









