







先上代码,后面细说
import urllib.request
url = "https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=0";
Agent = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
# 1.请求对象的定制
request = urllib.request.Request(url=url, headers=Agent)
# 2.获取响应的数据
response = urllib.request.urlopen(request);
content = response.read().decode('utf-8')
# 下载数据到本地
with open('douban.json','w',encoding='utf-8') as fp:
fp.write(content)

准备工作
我们先打开豆瓣电影,摁下F12,找到Network这一栏,摁下F5刷新
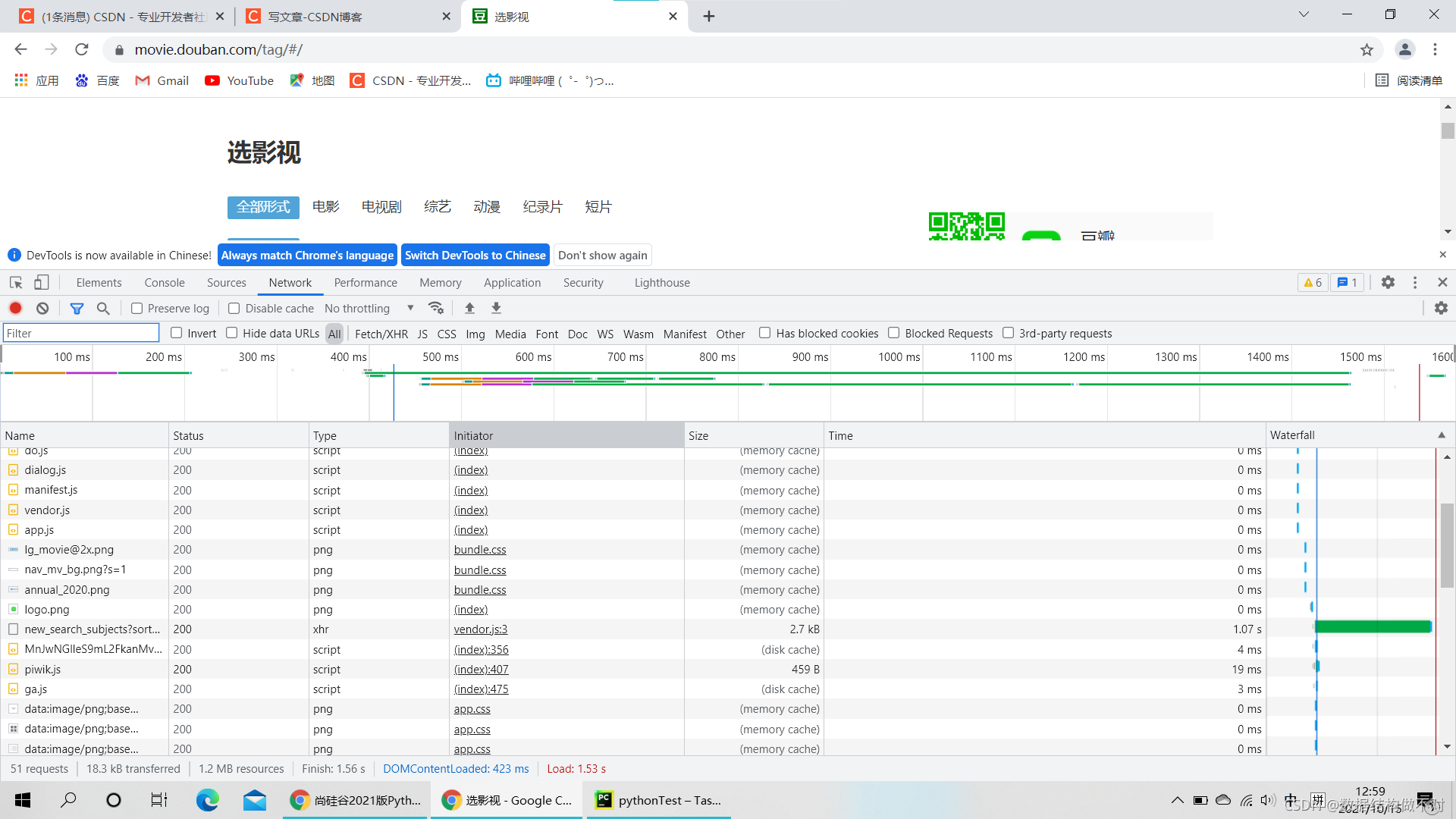
可以看到出现了很多的请求,但我们要找到我们需要的。
我们先想一个问题, 因为电影网站的数据量是十分庞大的, 渲染如此庞大的数据只有一种可能,就是通过JS发送ajax请求, 来从后端获取数据再渲染到页面上,。那么我们的数据源就明确了, 接下来就需要打开F12控制台中的Network, 选中XHR, 然后刷新页面就找到了数据源, 下面Preview显示的就是我们需要的电影数据
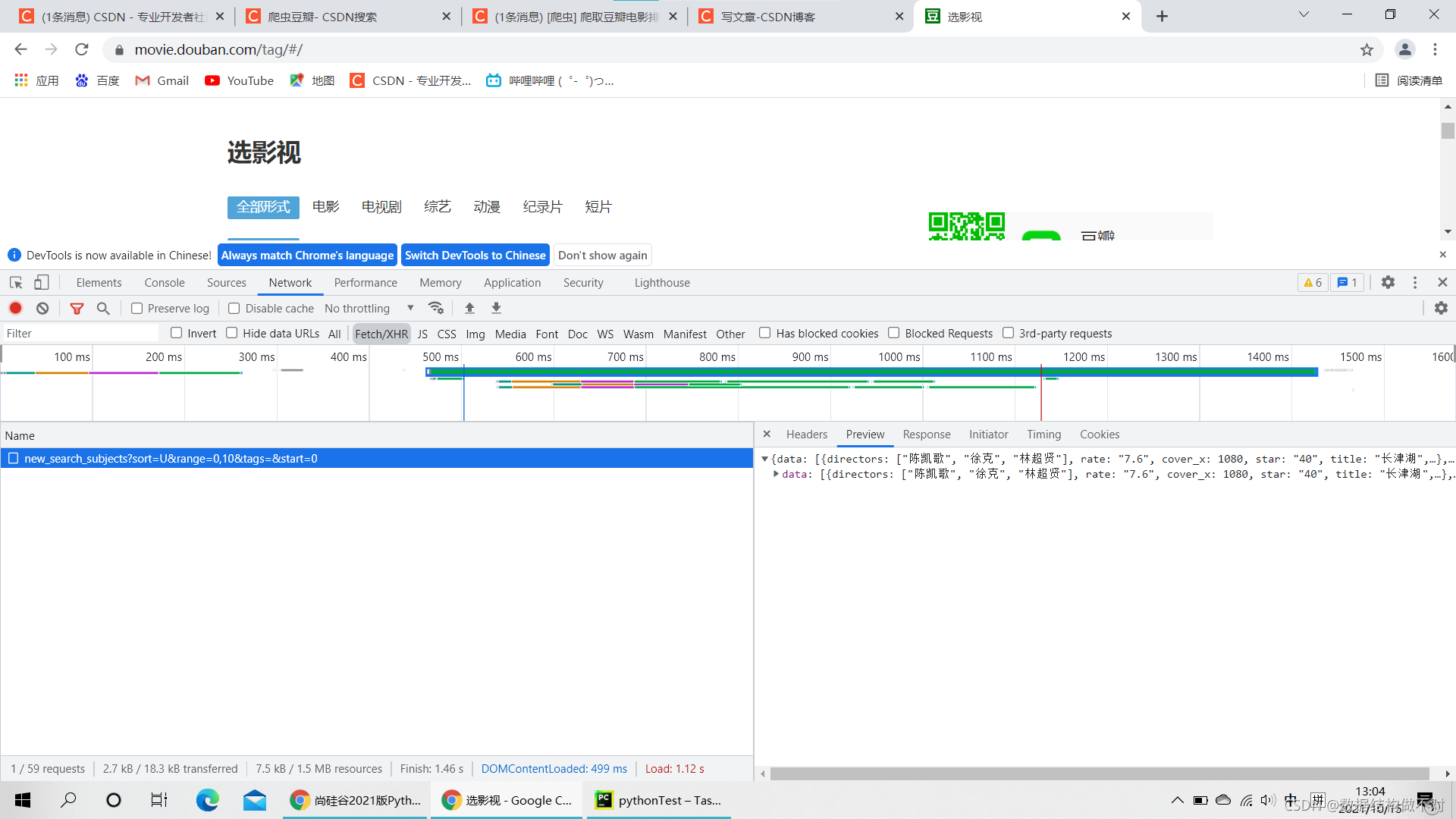
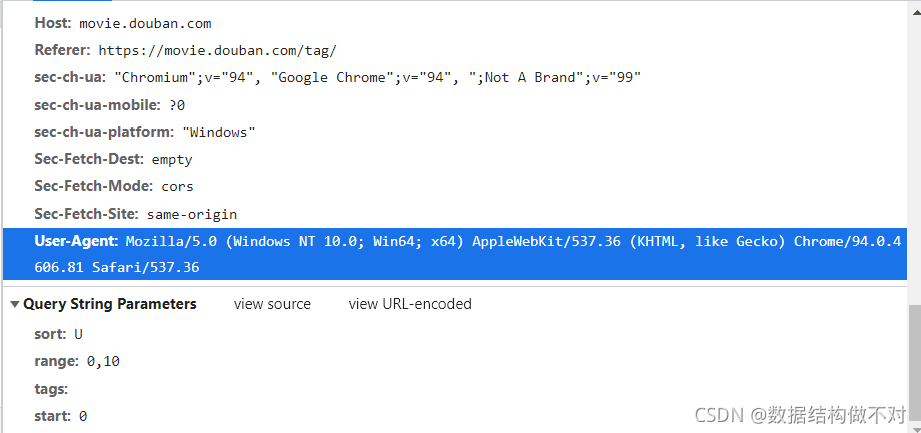
我们先把url和Agent复制下来,准备工作就完成了

import urllib.request
url = "https://movie.douban.com/j/new_search_subjects?sort=U&range=0,10&tags=&start=0";
Agent = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}

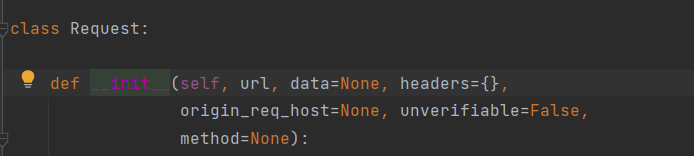
请求对象的定制
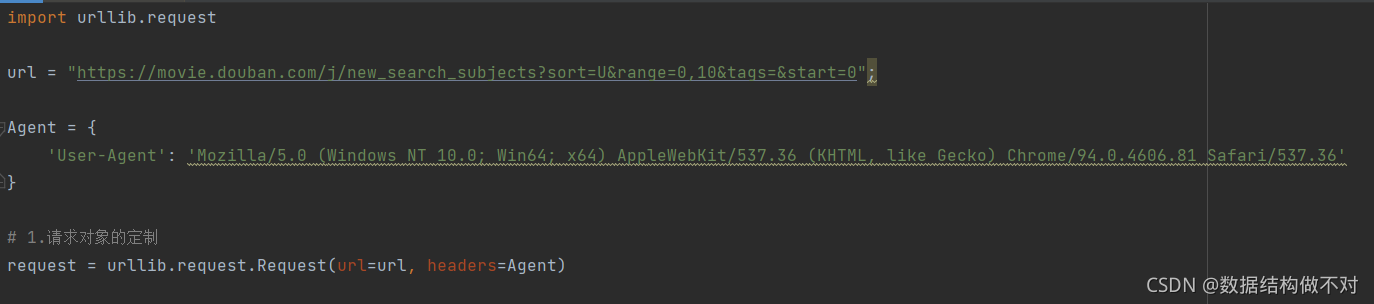
# 1.请求对象的定制
request = urllib.request.Request(url=url, headers=Agent)
因为我们传参数的位置跟在Request方法中的参数位置不一样,所有我们要url=url, headers=Agent
获取响应的数据
# 2.获取响应的数据
response = urllib.request.urlopen(request);
centent = response.read().decode('utf-8');
打印出来看看有没有问题
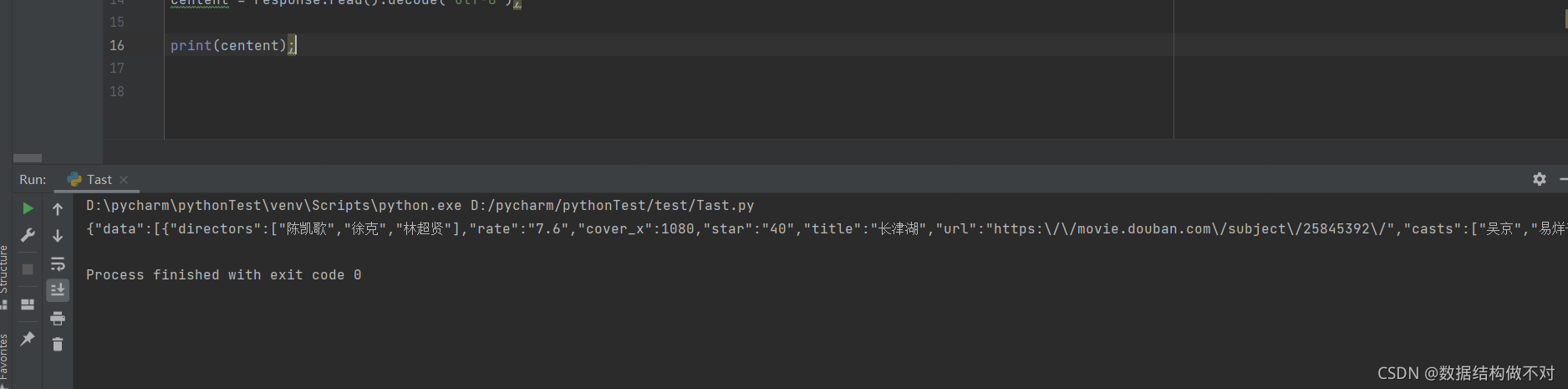
是这个,我们现在就保存我们的数据
数据下载到本地

可以看到它是json的数据,所以我们也用json数据保存下来
# 下载数据到本地
with open('douban.json','w',encoding='utf-8') as fp:
fp.write(content)
open方法默认使用gdk编码,如果数据里面有汉字,我们需要在open方法指定编码格式为’utf-8,也就是encoding='utf-8'
保存下来了,去看看成果
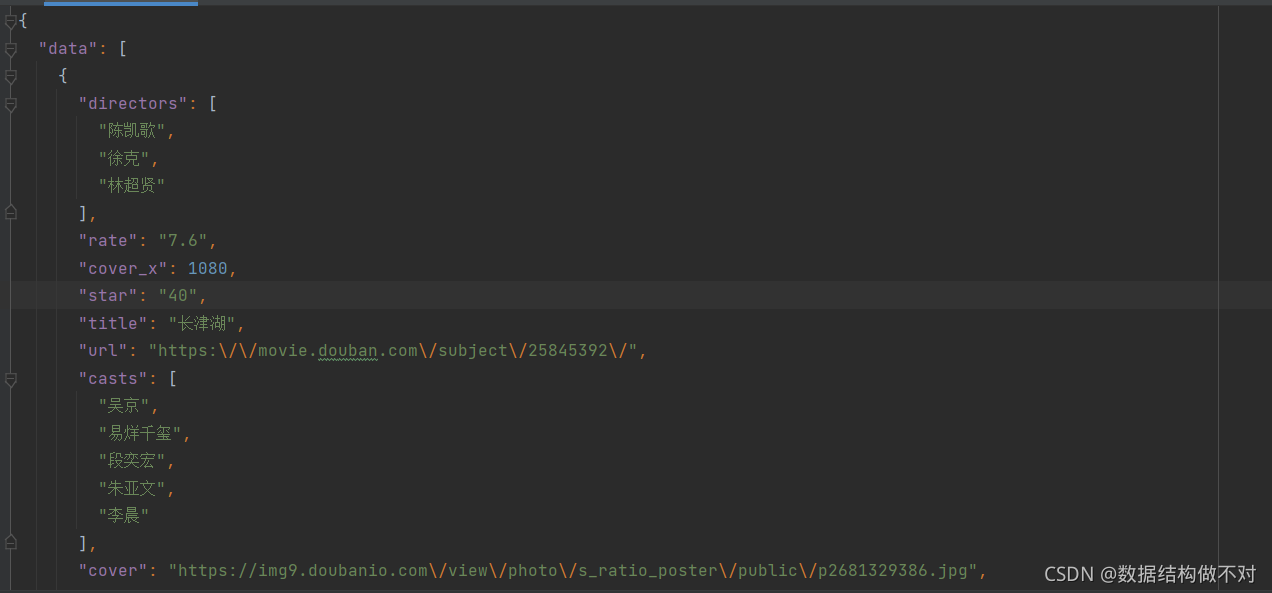
最开始下载下来的是一条长串,如果是pycharm就全部选中,然后crtl+alt+L就能自动整理成现在更直观的样子














 8589
8589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









