







目录
概述
爬取豆瓣的高评分的电影。
准备
所需模块
- re模块
- requests模块
涉及知识点
- python基础
- requests模块基础
- re模块基础
运行效果
控制台打印:

完成爬虫
1. 分析网页
打开豆瓣,查看评分最高的影视排名
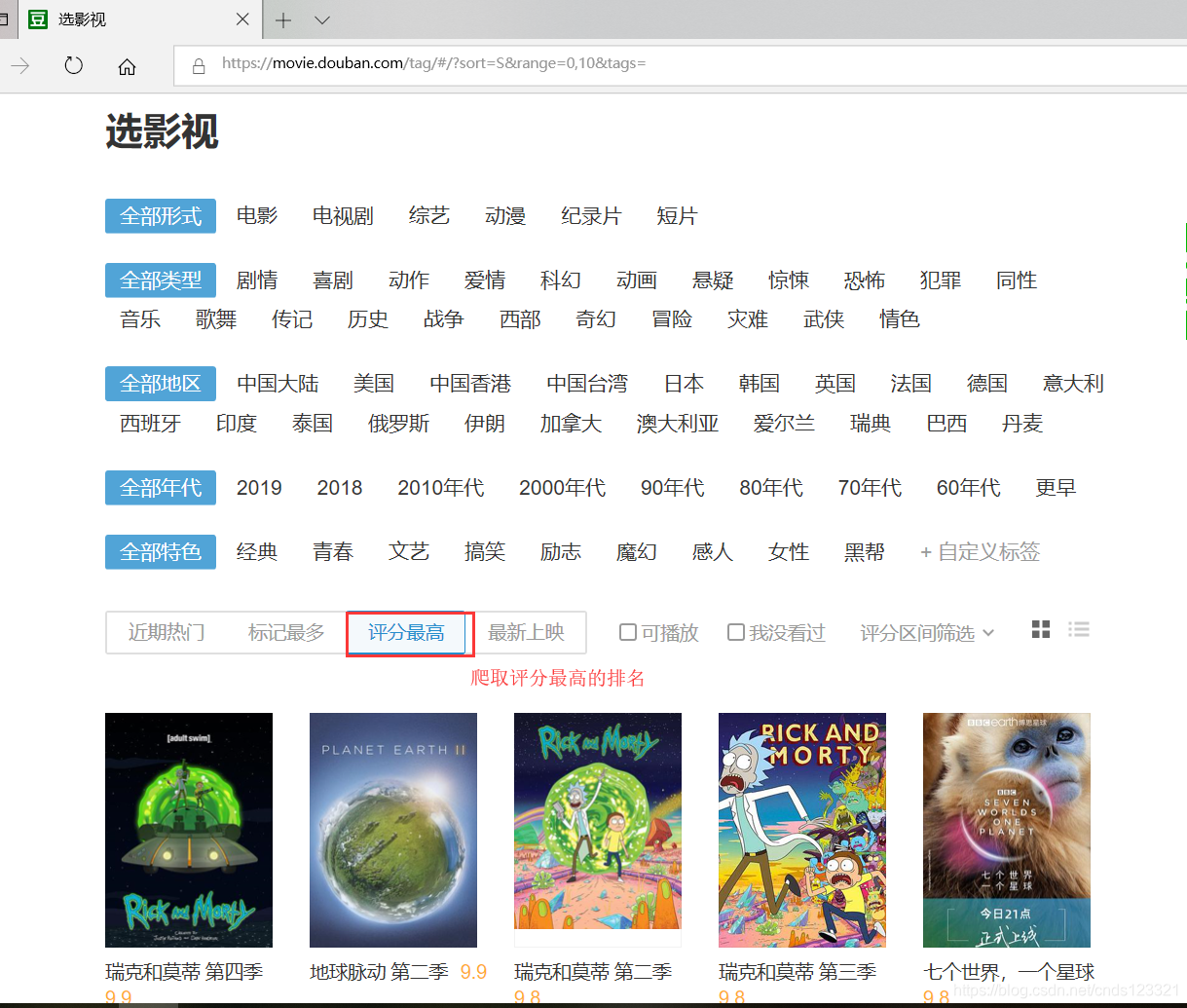
按F12,分析网页:
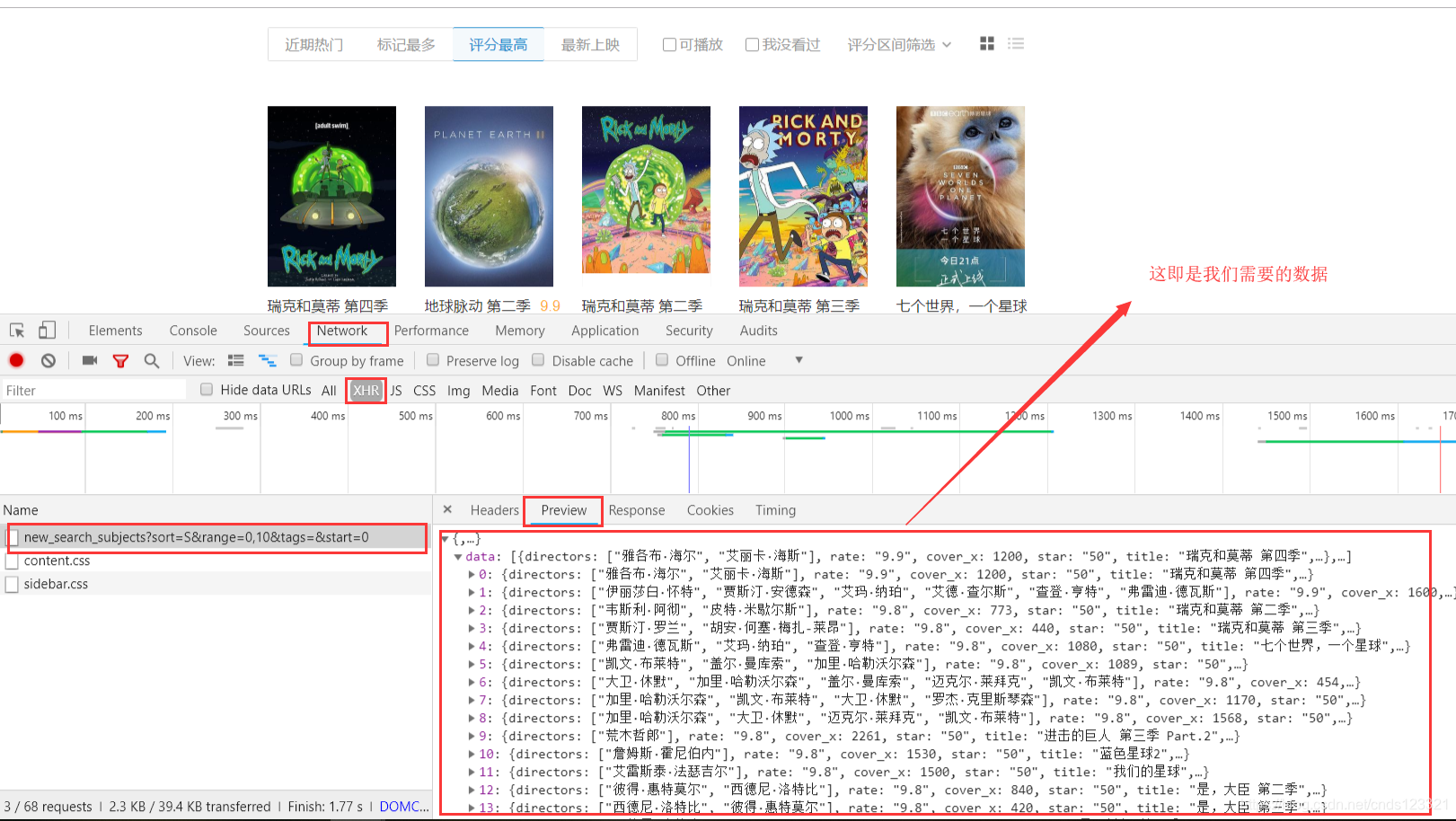
前20条的URL为:https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start=0
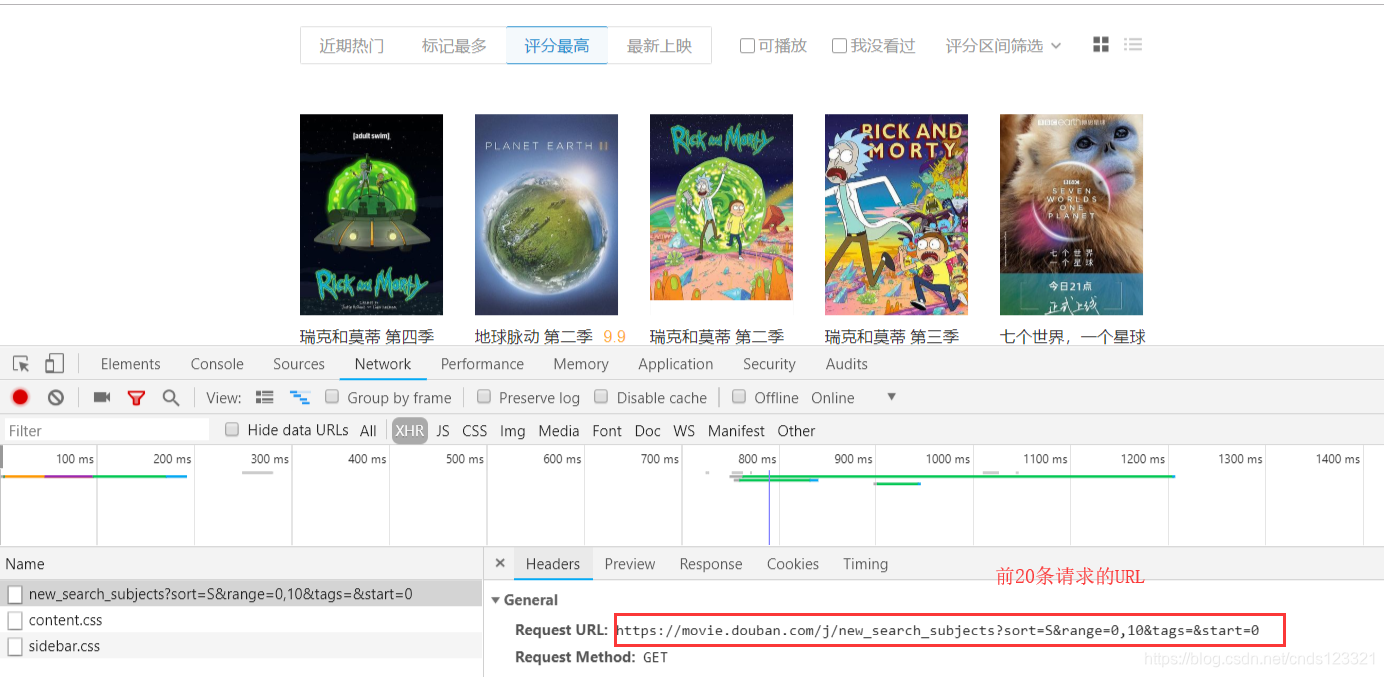
点击【加载更多】,第20-40条记录的URL为:https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start=20


第40-60条的记录URL为:https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start=40

比较三者的URL:
# 第1页:https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start=0
# 第2页:https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start=20
# 第3页:https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start=40
# 第4页:https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start=60
# 故可以得到URL公式:url="https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start="+(page_index-1)*20
直接使用requests请求即可获取JSON格式的数据。
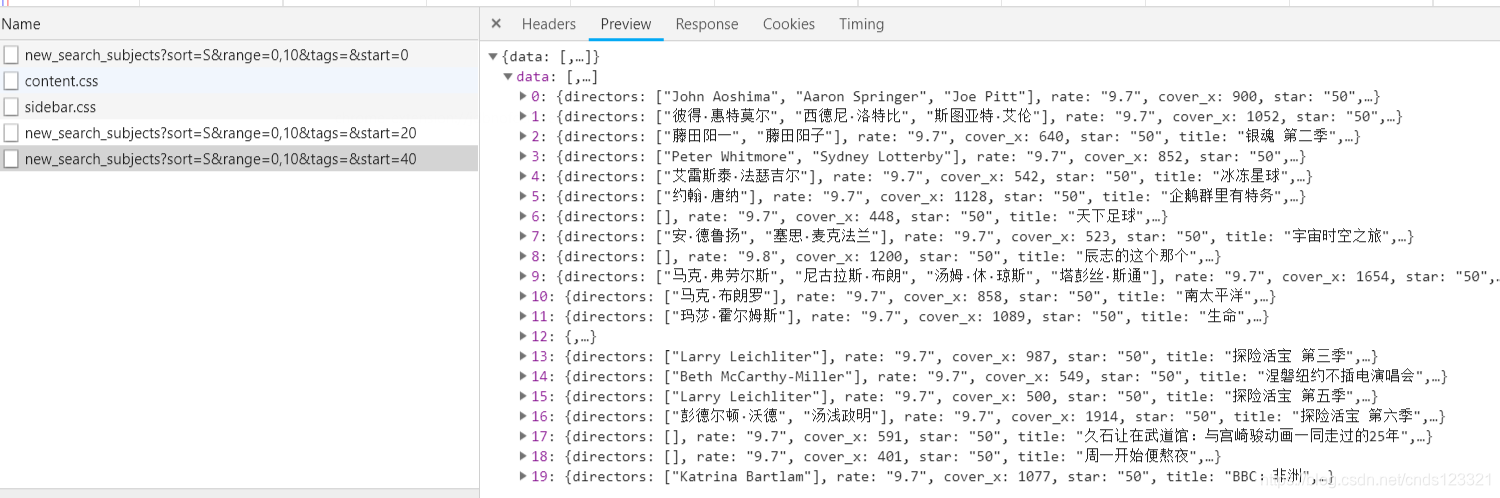
我们所需要的数据:
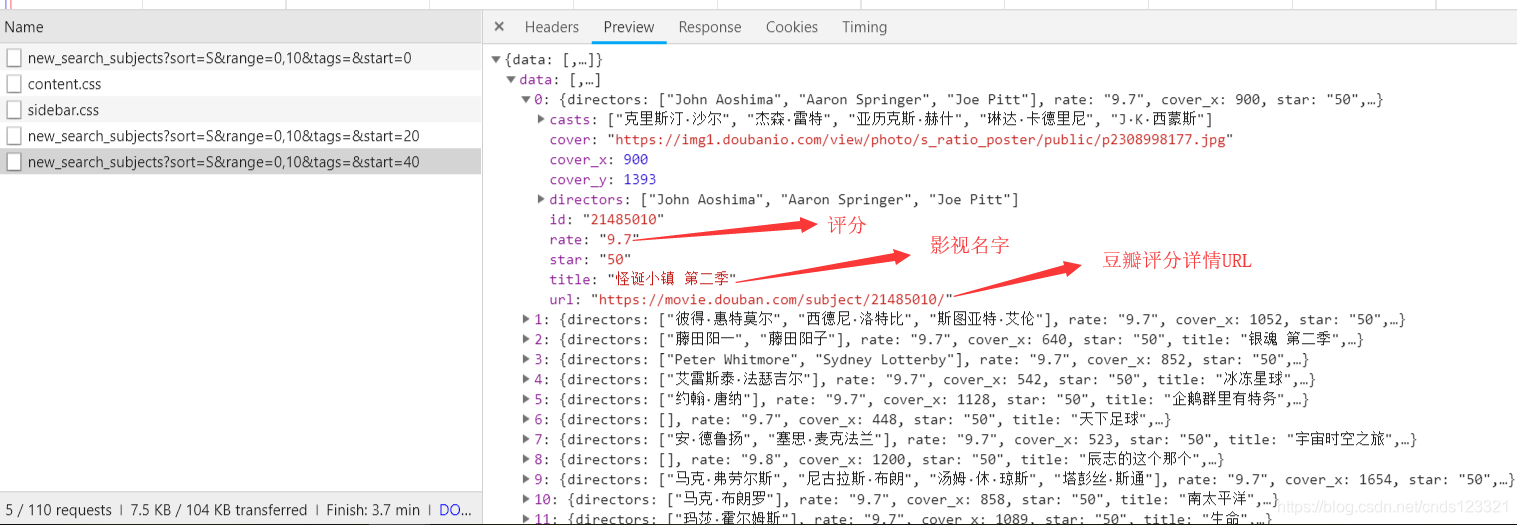
2. 爬虫代码
只处理前20条,代码如下:
import re
import requests
# 爬取豆瓣高评分影视
# 第1页:https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start=0
# 第2页:https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start=20
# 第3页:https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start=40
# 第4页:https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start=60
# 故可以得到URL公式:url="https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start="+(page_index-1)*20
# 请求头
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
page_index = 1 # 获取前20条
url = r"https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start=" + str(
(page_index - 1) * 20) # 拼接URL
response = requests.get(url, headers=header).text # 发送请求,获取响应
response = re.sub(r"\\", "", response) # 对网址进行处理
pat_title = r'"title":"(.*?)",' # 匹配影视名
pat_rate = r'"rate":"(.*?)",' # 匹配影视评分
pat_url = r'"url":"(.*?)",' # 匹配具体豆瓣影评的URL
data_title_list = re.compile(pat_title).findall(response) # 获取影视名列表
data_rate_list = re.compile(pat_rate).findall(response) # 获取影视评分列表
data_url_list = re.compile(pat_url).findall(response) # 获取具体豆瓣影评的URL
for i in range(0, len(data_title_list)): # 循环遍历打印
print(data_title_list[i], "\t\t\t\t\t\t\t\t", data_rate_list[i], "\t\t\t\t\t\t\t\t", data_url_list[i])
打印结果如下:

3. 整理总结
import re
import requests
# 爬取豆瓣高评分影视
# 第1页:https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start=0
# 第2页:https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start=20
# 第3页:https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start=40
# 第4页:https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start=60
# 故可以得到URL公式:url="https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start="+(page_index-1)*20
# 请求头
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36"
}
page_num = int(input("请输入您想知道的记录条数(记录条数是20的倍数):")) # 获取记录总条数
page_index = int(page_num / 20) # 获取页数
for i in range(1, page_index + 1): # 循环遍历页数
url = r"https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=&start=" + str(
(i - 1) * 20) # 拼接URL
response = requests.get(url, headers=header).text # 发送请求,获取响应
response = re.sub(r"\\", "", response) # 对网址进行处理
pat_title = r'"title":"(.*?)",' # 匹配影视名
pat_rate = r'"rate":"(.*?)",' # 匹配影视评分
pat_url = r'"url":"(.*?)",' # 匹配具体豆瓣影评的URL
data_title_list = re.compile(pat_title).findall(response) # 获取影视名列表
data_rate_list = re.compile(pat_rate).findall(response) # 获取影视评分列表
data_url_list = re.compile(pat_url).findall(response) # 获取具体豆瓣影评的URL
for i in range(0, len(data_title_list)): # 循环遍历打印
print(data_title_list[i], "\t\t\t\t\t\t\t\t", data_rate_list[i], "\t\t\t\t\t\t\t\t", data_url_list[i])
打印结果:


















 1600
1600

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









