






目录
mysql
四个步骤:
- 安装:npm i mysql -S
- 导入:const mysql = require('mysql')
- 创建:const conn = mysql.createConection({host:xxx,user:xxx,password:xxx,database:xxx})
- 连接:conn.connect()
具体表操作看下面的例子:
// 1.安装 npm i mysql -S
// 2.导入模块
const mysql = require('mysql');
// 3.创建连接
const conn = mysql.createConnection({
host: '127.0.0.1',
user: 'root', //用户
password: '123456', //密码
database: 'dbTest' //请确保数据库存在
});
// 4.连接
conn.connect(err => {
if (err) throw err;
console.log('连接成功');
});
// 创建表
const CREATE_SQL = `CREATE TABLE IF NOT EXISTS test ( id INT NOT NULL PRIMARY KEY auto_increment, name VARCHAR ( 30 ) )`;
const INSERT_SQL = `INSERT INTO test(name) VALUES(?)`;
const SELECT_SQL = `SELECT * FROM test`;
//查询 conn.query()
conn.query(CREATE_SQL, (error)=> {
if (error) throw error;
conn.query(INSERT_SQL,'hello',(err, result) => {
if (err) throw err;
console.log(result);
conn.query(SELECT_SQL,(err,results)=>{
console.log(results);
// 关闭连接
conn.end(); //若query语句有嵌套,则end需在此执行
})
})
});
Sequelize
Sequelize是一个Node.js ORM(Object-Relational Mapping)框架,支持多种数据库,包括MySQL、PostgreSQL、SQLite和MariaDB等。它提供了一种在Node.js中操作关系型数据库的简单方式,使用JavaScript语言进行操作,可以方便地进行增删改查等操作。
Sequelize主要提供了以下功能:
-
定义模型:Sequelize提供了一种定义模型的方式,可以方便地将JavaScript对象映射到数据库中的表,并设置表之间的关系。
-
数据查询:Sequelize提供了一种查询构建器,可以方便地进行复杂的查询操作,并支持事务和锁机制。
-
数据验证:Sequelize提供了一种数据验证机制,可以在保存数据之前对数据进行验证。
-
数据迁移:Sequelize提供了一种数据迁移工具,可以方便地进行数据库结构的变更,支持回滚操作。
总的来说,Sequelize是一个功能丰富、易于使用的ORM框架,可以帮助我们更好地操作关系型数据库。它提供了一种简单的方式来定义模型、查询数据、验证数据和迁移数据等操作,使得我们可以更加高效地进行数据库开发。
const { Sequelize, DataTypes } = require('sequelize')
const Op = Sequelize.Op
// 建立连接
const sequelize = new Sequelize('dbTest', 'root', '', {
host: '127.0.0.1',
dialect: 'mysql',
})
;(async function () {
try {
await sequelize.authenticate()
console.log('Connection has been established successfully.')
} catch (error) {
console.error('Unable to connect to the database:', error)
}
})()
// 定义模型
const Books = sequelize.define(
'Books',
{
// 定义表中的字段,对象模型中的属性
id: {
type: DataTypes.INTEGER,
primaryKey: true, //设置主键
autoIncrement: true,
comment: '自增的id',
},
name: {
type: DataTypes.STRING,
allowNull: false, // 不允许为空,默认为true
},
price: {
type: DataTypes.FLOAT,
allowNull: false,
},
count: {
type: DataTypes.INTEGER,
defaultValue: 0,
},
},
{
tableName: 'books',
// 指定是否创建createAt和updateAt字段,默认true表示创建
timestamps: false,
freezeTableName: true,
}
)
// 模型同步到数据库
Books.sync({ force: true }).then(async () => {
// CRUD
// 插入数据 插入一条
// Books.create({})
// 插入多条数据
Books.bulkCreate([
{
name: '你不知道的JavaScript',
price: 2.9,
count: 10,
},
{
name: 'Vue实战开发',
price: 100.9,
count: 100,
},
{
name: 'React实战开发',
price: 122.9,
count: 88,
},
{
name: 'Nodejs实战',
price: 122.9,
count: 100,
},
])
// 查询所有的书籍
const books = await Books.findAll()
// const books = await Books.findAll({ attributes: ['id', 'name','price'] })
// 排除某些属性
// const books = await Books.findAll({
// attributes: { exclude: ['count'] },
// where: {
// price: {
// [Op.gt]: 10,
// },
// },
// order: [
// ['id', 'DESC'], //根据id倒序
// ],
// limit: 3,
// })
// 更新
// books = await Books.update(
// { name: '学习node mysql' },
// {
// where: {
// id: 2,
// },
// }
// )
// const maxPrice = await Books.max('count')
// console.log(maxPrice)
Books.max('price').then((maxPrice) => console.log(maxPrice))
await Books.destroy({
where: {
id: 1,
},
})
// console.log('All books', JSON.stringify(books, null, 2))
})
mongodb
MongoDB是一种开源的、面向文档的非关系型数据库管理系统,它使用JSON风格的文档代替了传统的行和列的存储方式。
安装地址:
Download MongoDB Community Server | MongoDB
配置过程(这个链接比较详细):
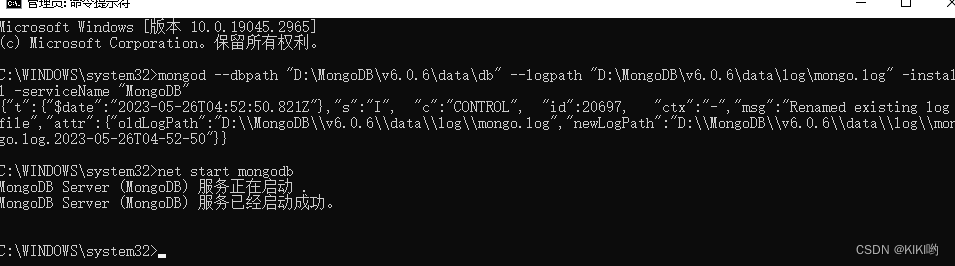
配置完成后将启动方式改为手动启动:
win+R输入cmd打开命令行然后输入services.msc,找到MongoDB改成手动
改成手动之后:
打开管理员命令行输入net start mongodb,启动成功
robo 3t 可视化工具
安装地址:
https://robomongo.org/download
详细链接:
以上准备完成之后:
打开vscode, 命令行输入安装mongodb
npm install mongodb
// 下载
// mongodb npm i mongodb -S
const MongoClient = require('mongodb').MongoClient
;(async function () {
const client = new MongoClient('mongodb://127.0.0.1:27017')
// 链接服务端
await client.connect()
console.log('链接成功')
// 获取数据库 // 获取集合
const db = client.db('school')
// 获取模型 grade1
const grade1 = db.collection('grade1')
// 先删除所有的数据
grade1.deleteMany()
// grade1.insertOne({
// name:"张三",age:20,hobby:['吃饭','睡觉','打豆豆'],score:90
// })
// grade1.insertMany([]);
// CRUD
// 查询操作
let r = await grade1.insertMany([
{ name: '张三', age: 20, hobby: ['吃饭', '睡觉', '打豆豆'], score: 90 },
{ name: '李四', age: 40, hobby: ['妹子', '篮球'], score: 93 },
{ name: '王五', age: 20, hobby: ['妹子', '睡觉'], score: 70 },
{ name: '赵六', age: 16, hobby: ['妹子'], score: 50 },
{ name: '张丽', age: 38, hobby: ['妹子'], score: 56 },
{ name: '小红', age: 40, hobby: ['妹子'], score: 87 },
{ name: '小马', age: 20, hobby: ['妹子'], score: 79 },
{ name: '小王', age: 59, hobby: ['妹子'], score: 102 },
{ name: '小黑', age: 16, hobby: ['妹子'], score: 60 },
{ name: 'kiki', age: 18, hobby: ['篮球'], score: 49 },
])
// // 查询文档的操作 获取一条数据
r = await grade1.findOne({ name: '张三' })
// //selert * from grade1
r = await grade1.find().toArray()
r = await grade1.find({ name: '张三' }).toArray()
// // 比较运算符
// r = await grade1
// .find({
// age: {
// // gt大于 lt小于 gte 大于等于 lte小于等于
// $gte: 20,
// },
// })
// .toArray()
// // 逻辑运算符 $and $or $ne $nor 不等于
// // 查询姓名叫王五并且年龄为20岁的人
// r = await grade1
// .find({
// name: '王五',
// age: 20,
// })
// .toArray()
// // 查询姓名叫张三或者年龄为20岁的人
// r = await grade1
// .find({
// $or: [
// {
// name: '张三',
// },
// {
// age: 20,
// },
// ],
// })
// .toArray()
// // // 查询年龄不大于20岁并且age不小于16的人员
// r = await grade1
// .find({
// $nor: [
// {
// age: {
// $gt: 20,
// },
// },
// {
// age: {
// $lt: 16,
// },
// },
// ],
// })
// .toArray()
// // 正则表达式
// r = await grade1
// .find({
// name: {
// $regex: /^张/,
// },
// })
// .toArray()
// // $all $in $size
// // 查找指定字段包含所有指定内容的数据
// r = await grade1
// .find({
// hobby: {
// $all: ['妹子'],
// },
// })
// .toArray()
// // 查找指定字段只有指定内容其一的数据
r = await grade1
.find({
hobby: {
$in: ['妹子', '睡觉'],
},
})
.toArray()
// // 查找指定字段的数据有三条的
// r = await grade1
// .find({
// hobby: {
// $size: 3,
// },
// })
// .toArray()
// // 分页查询 limit()
// // 查询前两条数据
// r = await grade1.find().limit(2).toArray()
// // 跳过前2条数据,获取后4条数据
// r = await grade1.find().skip(2).limit(4).toArray()
// // 根据age字段进行排序 1表示正序 -1 表示倒序
// r = await grade1
// .find()
// .sort({
// age: -1,
// })
// .toArray()
// // 分页
// const pageIndex = 1 //当前的索引
// const pageSize = 3 //当前一页显示的数据
// // 1 2 3 4
// r = await grade1
// .find()
// .skip((pageIndex - 1) * pageSize)
// .limit(pageSize)
// .toArray()
// // // 数组 forEach方法 map()方法
// // r.forEach(element => {
// // // console.log(element);
// // });
// // 所有的名字返回给前端 一个数组
// let names = r.map((ele) => ele.age)
// // console.log(names);
// // 聚合函数 $sum $min $max $avg
// // 相同年龄的人数
r = await grade1
.aggregate([
{
$group: {
_id: '$age',
count: {
$sum: 1,
},
},
},
])
.toArray()
// r = await grade1
// .aggregate([
// {
// $group: {
// _id: '$age',
// avgScore: {
// $avg: '$score',
// },
// },
// },
// ])
// .toArray()
// r = await grade1
// .aggregate([
// {
// $group: {
// _id: '$age',
// avgScore: {
// $max: '$score',
// },
// },
// },
// ])
// .toArray()
// // 更新文档
r = await grade1.updateOne(
{
name: "张三",
},
{
$set:{
name:"kiki"
}
}
)
console.log('更新成功',r )
// // 当你做删除的时候 一定要问一下自己 是否要删除
// r = await grade1.deleteOne({
// name:'张三'
// })
// console.log(r.result);
// 关闭客户端的链接
client.close()
})()
mongoose
Mongoose是基于MongoDB的Node.js ORM框架。
Mongoose提供了一些基于Schema的方法,使得我们可以在Node.js中更加方便地操作MongoDB数据库。
Mongoose提供了很多功能,包括数据验证、中间件、查询构建器等,可以帮助我们更方便地操作MongoDB数据库。
因此,我们可以说Mongoose是MongoDB的一个补充,可以更好地发挥MongoDB的优势。
const mongoose = require('mongoose')
mongoose.connect('mongodb://127.0.0.1/test')
const db = mongoose.connection
db.on('error', console.error.bind(console, 'connection error:'))
db.once('open', async () => {
// we're connected!
// 定义一个schema =>表
// 字段
const blogSchema = new mongoose.Schema({
title: String,
author: String,
body: String,
comments: [
{
body: String,
date: Date,
},
],
date: {
type: Date,
default: Date.now,
},
hidden: Boolean,
meta: {
votes: Number,
favs: Number,
},
})
// 定义实例方法 (schema对象上的方法)
blogSchema.methods.findAuthor = function () {
return this.model('Blog').find({ author: this.author }).exec()
}
// 定义静态方法 (模型上的方法)
blogSchema.statics.findTitle = function (title) {
return this.find({ title: title }).exec()
}
// 定义虚拟属性
blogSchema.virtual('getContent').get(function () {
return `${this.author}发布了一篇文章叫${this.title}`
})
// 定义一个模型
const Blog = mongoose.model('Blog', blogSchema)
try {
await Blog.deleteMany()
// 后添加
await Blog.insertMany([
{
title: 'Vue基础',
author: '小尤',
body: 'Vue是一个轻量级的高效的牛逼前端框架',
comments: [
{
body: '您说的对,非常认同',
date: new Date(),
},
],
hidden: true,
meta: {
votes: 10,
favs: 200,
},
},
{
title: 'React',
author: 'faceBook',
body: 'React是更牛逼前端框架',
comments: [
{
body: '您说的似对似不对,不是那么认同',
date: new Date(),
},
],
hidden: false,
meta: {
votes: 400,
favs: 2000,
},
},
]) //插入多条数据
console.log('插入数据成功')
// 查询操作
// find() findOne() findById()
// let r = await Blog.find({author:'小尤'})
let r = await Blog.find().and([
{
author: 'faceBook',
},
{
title: 'React',
},
])
// 在下面一定要多看文档,当你的需求是做不同的操作的时候结合文档 进行实现
let b = new Blog({ author: '小尤' })
r = await b.findAuthor()
r = await Blog.findTitle('Vue基础')
// console.log('更新结果', r)
// 5e66faf1d7886659dbf85b10
// 查询一条结果 根据_id获取
let sid = mongoose.Types.ObjectId('621f83a4cec82e5d1ddb469b')
r = await Blog.findOne({ _id: sid })
r = await Blog.findOne({ author: '小尤' })
console.log(r.getContent)
// 更新
// r = await Blog.where({ author: '小尤' }).updateOne({ title: '哈哈哈哈' })
// console.log('更新结果',r);
// // 更新并返回当前查询的结果
r = await Blog.findOneAndUpdate(
{ author: '小尤' },
{ author: 'kikiyo' },
{ new: true }
)
console.log('查询结果为', r)
// 删除操作
// r = await Blog.deleteOne({ author: '小尤' })
// console.log('删除成功',r); r.n 如果等于 表示 更新或删除成功
// 删除
} catch (error) {
console.log(error)
}
})















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









