






在上一篇文章当中,我们也提到了什么是HTTP。
每一个HTTP请求,都会对应一个HTTP响应。
下面这一篇文章,将聊一下HTTP请求的一些内容
目录
在当下的场景当中,get和post没有本质的区别,是可以相互替换的。
区别2:通常情况下get没有body部分,而post有body部分
四、HTTP请求头(request)数据包的一些常见的"键值对"
②Content-Length&Content-Type;这两个键值对
取值1:application/x-www-form-urlencoded:form
六、session
一、URL
URL的含义就是"网络上唯一资源的地址符"。
通过浏览器,打开网页的时候,地址栏里面填写这个网址,就是URL。

通过这个URL。既可以明确主机是谁,又可以明确访问的是主机上面的什么资源。
下面,说明一下一个URL被分为了哪几个部分。
第一部分:协议名称
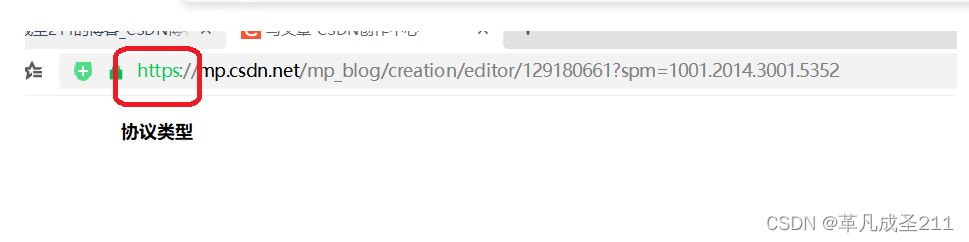
https/http:这一部分,描述了当前的这一个网络地址,是给http用的,还是给https用的。
如果显示的是http,那么就是给http这一个协议使用的。如果显示的是https,那就是给https这一个协议使用的。
第二部分:认证信息(新的版本已经没有了)
显示的是当前用户登录的登录信息(可能是用户名/密码)
第三部分:服务器地址+(端口号)
当前需要访问的主机是哪一个。可能是一串字符,也有可能是1.2.3.4这样的ip地址。
如下图,显示的就是一个域名地址。
 如果显示了端口号,那这一个端口就是http请求需要访问的端口。
如果显示了端口号,那这一个端口就是http请求需要访问的端口。
但是,可以看到:一般情况下,都没有显示端口号,这是怎么回事呢?
没有显示端口号,并不代表没有端口号。
对于没有在URL地址当中显示端口号的情况:
如果使用的是http协议,那么默认是80端口。
如果使用的是https协议,那么默认值就会是443端口。
第四部分:带层次的文件路径
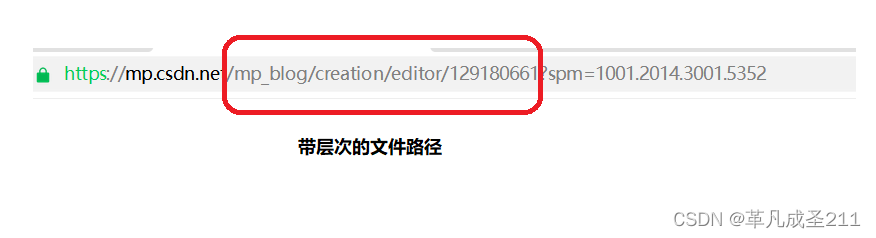
描述了当前服务器需要访问的资源是什么。
对于这一个带有层次的文件路径,有可能是一个真实的文件的路径。
也有可能是虚拟的,由服务器代码,构造出的一个动态的数据。
单凭:ip地址/域名地址+文件路径已经可以锁定网络上面的某一个地址了,但是,还有一部分,那就是查询字符串。
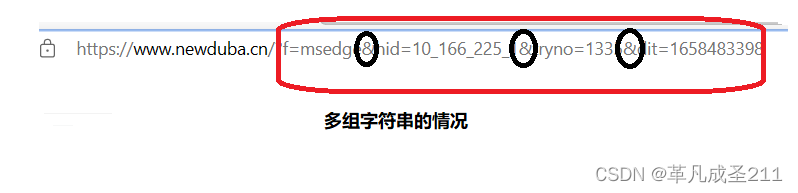
第五部分:查询字符串
 查询字符串,可以有一组,也可以有多组。
查询字符串,可以有一组,也可以有多组。
每一组都是使用键值对来表示的,键和值之间用"="来连接。
但是组与组之间,使用的是"&"来连接的。
但是,这些字符串的具体含义,那就是由web开发的程序员来决定的了。
第六部分:片段标识符
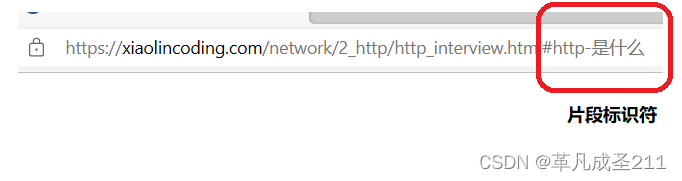
本质上是希望访问的具体的html页面的哪一个子部分。可以理解为:跳转到某一个章节的部分。(此部分可能有,也可能没有)
总览一下http的URL的结构:

其中:文件资源(文件目录)和查询字符串部分,是后续web开发常用的
URL和URI的区别
URL是(uniform resource locator)的缩写:在网页上面输入的那个地址就是URL,任意一个网络资源都有它对应的URL。URL是具体的
URI是Web上可以用的每一种资源(例如图片、文档、视频等)。
URI是抽象的,需要URL来定义到它具体的网络上面的位置。
例如:访问一个网络地址为:http://localhost:8080/ServletLearning_war_exploded/hello
那么,如果调用getRequestURI()和getRequestURL()
区别就在于:
前者:返回的是一个相对的路径:/ServletLearning_war_exploded/hello。
后者:返回的是一个绝对的路径:http://localhost:8080/ServletLearning_war_exploded/hello
那么,也就意味着:URL是URI的一个子集。
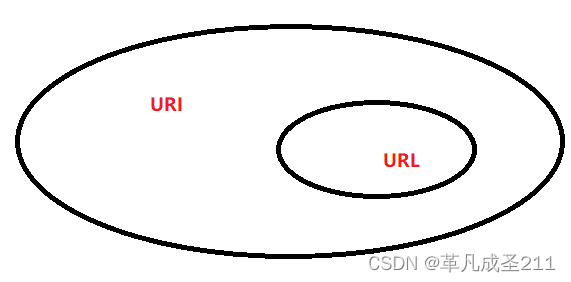
二、URL encode/decode
为什么要使用url encode
当输入的查询字符串当中,如果出现了特殊的符号,例如?或者/或者++等等的符号的时候,为了避免歧义。于是就需要对于这些特殊的字符进行转义。
观察如下的一个URL:
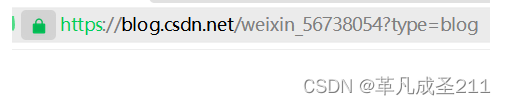
此时,可以看到type是blog。如果一个客户在type的等号后面输入了:b&o=log,也就是变成了这样:
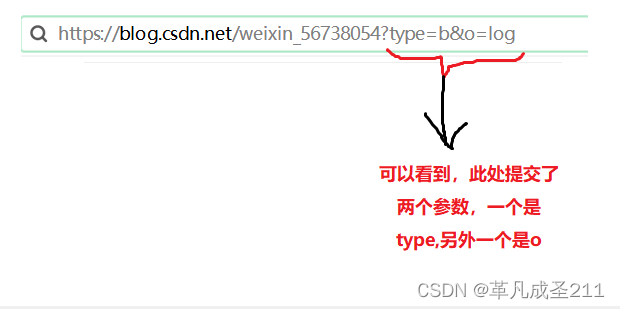
这样,也就产生了歧义。究竟是type这个参数的值是"=b&o=log",还是两个参数,一个参数是type,另外一个参数是o呢?
于是,就涉及到了http encode,它会把用户输入的存在歧义的字符串给转义掉。
一个转义的例子:
下面,举一个转义的例子:
如果在百度搜索引擎当中输入了"C++",可以查看一下搜索栏的内容:
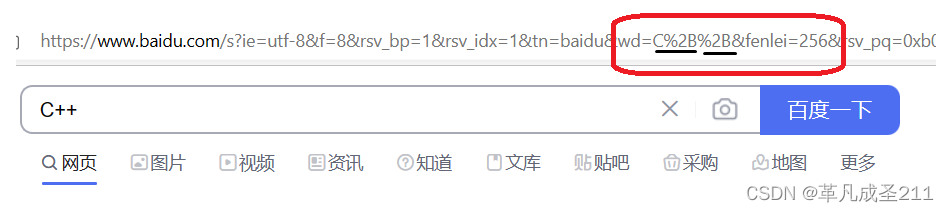
可以看到,搜索的两个加号,被替换为了"%2B"。
转义的规则:
查一下"+"对应的ascii码值:2B
因此,转义的规则就是让对应的字符转化为16进制,也就是ascii码,然后再加上"%"。这样就完成了转义了。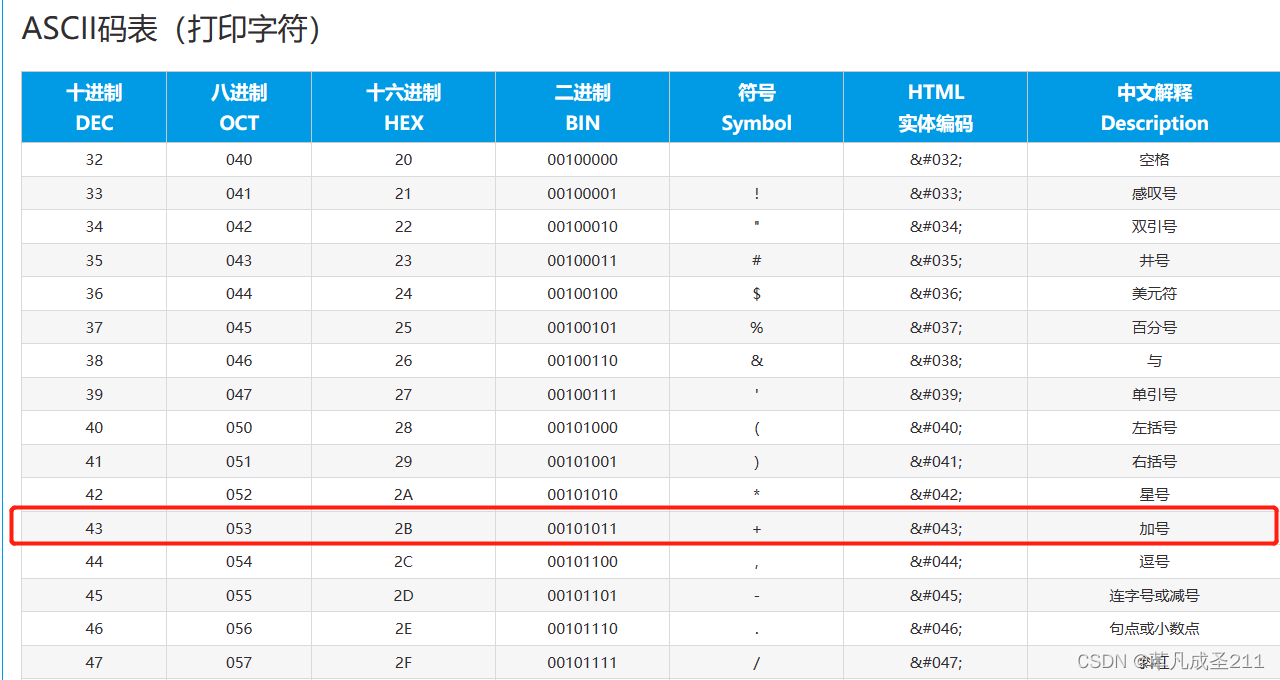
URL的decode,就是上述过程的逆向。当遇到了%+字符串的时候,就把它们转化为对应的字符。
三、HTTP的请求方法
在http请求头当中,包含了一个属性,那就是http方法:
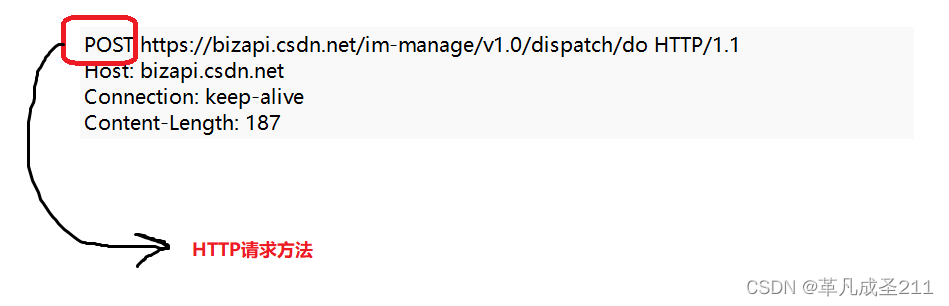
这一个方法有许多,但是最常用的,还是两个:一个是get,另外一个是post。
| 方法 | 用处 | 支持的版本 |
| post | 传输实体 | 1.0&1.1 |
| get | 获取资源 | 1.0&1.1 |
HTTP当中引入了的这一些方法的初衷,也是为了表示不同的"语义"。
但是,实际开发的场景当中,这些方法的用处也没有区分地这么明确。很多时候,GET方法也可以传输实体,POST方法也可以获取资源...
但是,二者的区别究竟在哪里呢?
get和post的区别
在当下的场景当中,get和post没有本质的区别,是可以相互替换的。
但是,仍然在细节上面,存在一些区别:对照一下get和post不同的抓包方式,比较一下它们的区别。
区别1: 语义上面的区别
| 方法 | 用处 | 支持的版本 |
| post | 传输实体 | 1.0&1.1 |
| get | 获取资源 | 1.0&1.1 |
get方法一般用于获取资源,而post方法一般用于传输实体。 但是现在这个区别已经不那么清晰了。
例如,用户登录这个功能,一般使用的就是post请求。向服务器提交userName和password两个字段,登录成功之后跳转页面。
查询商品列表这个功能,一般使用的就是get请求。
来获取商品列表这一系列的资源。
区别2:通常情况下get没有body部分,而post有body部分
对比一下使用Fiddler抓包的情况 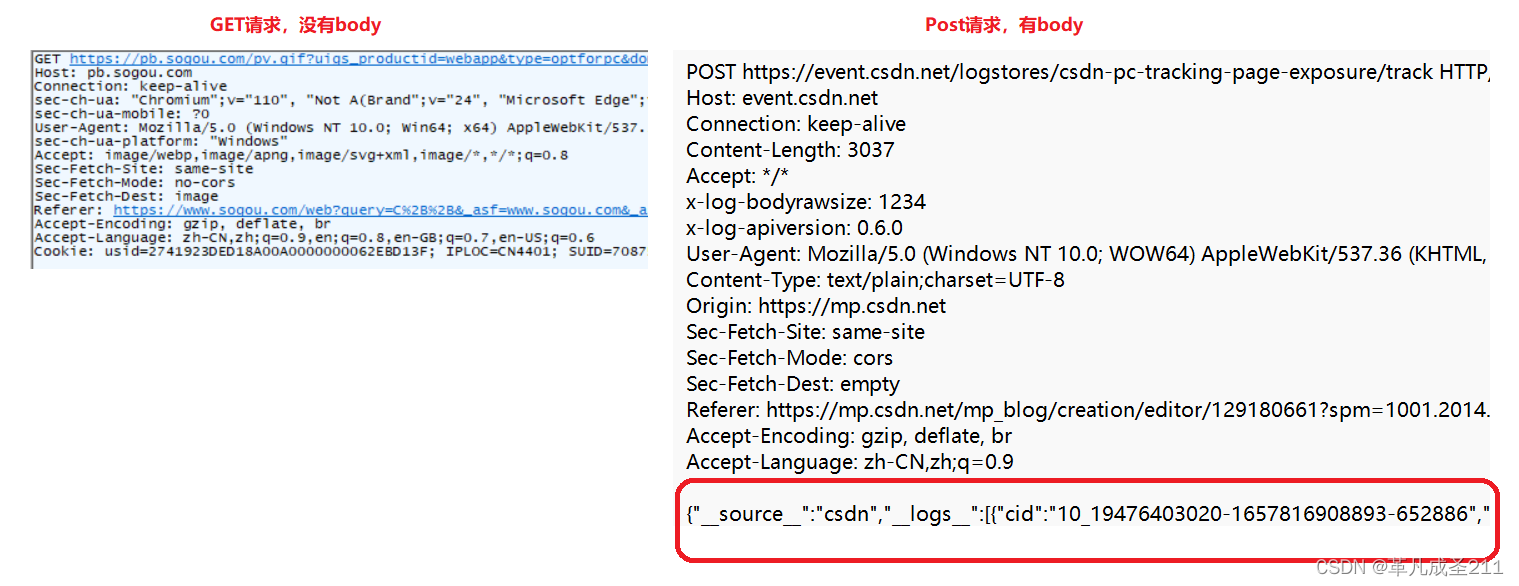
通常情况下:
get是没有body的,它一般通过query string(查询字符串)来服务器传递数据。
post是有body的,post通过body向服务器传递数据
上述情况,一般情况下都是成立的。但是,偶尔也会出现post没有body,但是get有body的情况。或者post有查询字符串,但是get没有查询字符串的情况。
其次:一部分公司在实际开发当中,有时候会硬性规定一定要使用post请求来处理。那这样肯定post也会有不带body的情况。
区别3:Get请求一般是幂等的,POST请求一般不是幂等的
这个区别也不是强制性的。
幂等&不幂等:
每次相同的输入,得到的输出结果是确定的,那么就说这个请求是幂等的。
每次相同的输入,得到的输出结果是不确定的,那么就说这个请求是不幂等的。
区别4:GET可以被缓存,POST不可以被缓存
能否缓存,其实和能否幂等是有密切关系的。
如果请求类型是幂等的,那么请求就是可以缓存的。
如果请求类型是不幂等的,那么请求就是不可以缓存的。
案例1:例如像查询百度热搜榜这样的请求,由于百度热搜榜实时更新比较快速的,那么就不是幂等的,也就不需要缓存。
案例2:还有,类似于广告搜索这样的请求,虽然是get请求(获取数据的),但是,它的要求一定是不可以缓存的。因为如果缓存的话,用户多次搜索同一个关键字,看到的仍然是一组/一个广告,这样是没有意义的。
区别5:浏览器提交方式的不同
如果一个请求是get请求,那么一般都是以下的5种情况:
情况1:用户直接在URL地址栏输入内容。
情况2:通过前端的a标签转发到服务器的内容。
情况3:通过img/link/script标签指定的路径。
情况4:通过form表单,并且method指定为GET
情况5:通过ajax发送的请求指定为get
如果一个请求是post请求,那么可以通过form表单,指定方法为post的形式来提交。
或者通过ajax发送的请求为post
总结一下:GET与POST的区别
| 方法 | GET | POST |
| 语义 | 通过查询字符串获取内容 | 向服务器提交实体 |
| 有无body | 通常无 | 通常有 |
| 是否幂等 | 通常是 | 通常否 |
| 是否可以被缓存 | 通常可以 | 通常不可以 |
| 提价方式不同 | 上述的5种情况 | 上述的2种情况 |
四、HTTP请求头(request)数据包的一些常见的"键值对"
在这一篇文章当中,我们提到了HTTP请求是由HTTP请求行+HTTP请求头+body构成的。
【网络原理7】认识HTTP_革凡成圣211的博客-CSDN博客HTTP抓包,Fiddler的使用https://blog.csdn.net/weixin_56738054/article/details/129148515?spm=1001.2014.3001.5502
HTTP请求头是由多个键值对构成的,下面,将聊一下HTTP请求头当中有哪些常见的键值对。
①host:描述了请求资源的主机地址&端口号
这是一个使用Fidller抓包后看到的数据。关于怎样使用Fidller抓包,也已经在上一篇文章当中提到了
如上图,看到的域名是bizapi.csdn.net。
但是,这一个地址可以被DNS解析为一个确定的ip地址,也就是类似于1.2.3.4这样的IP地址。
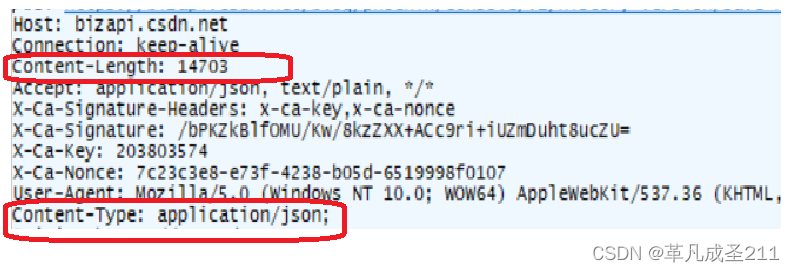
②Content-Length&Content-Type;这两个键值对
这两个属性是在描述请求头当中body部分的属性。如果一个HTTP请求有body,那么这两个键值对才会在HTTP请求头当中出现。
下面,来聊一下一个登陆的案例:
当用户提交了userName(用户名)和password(密码)之后,就可以正常登录了。
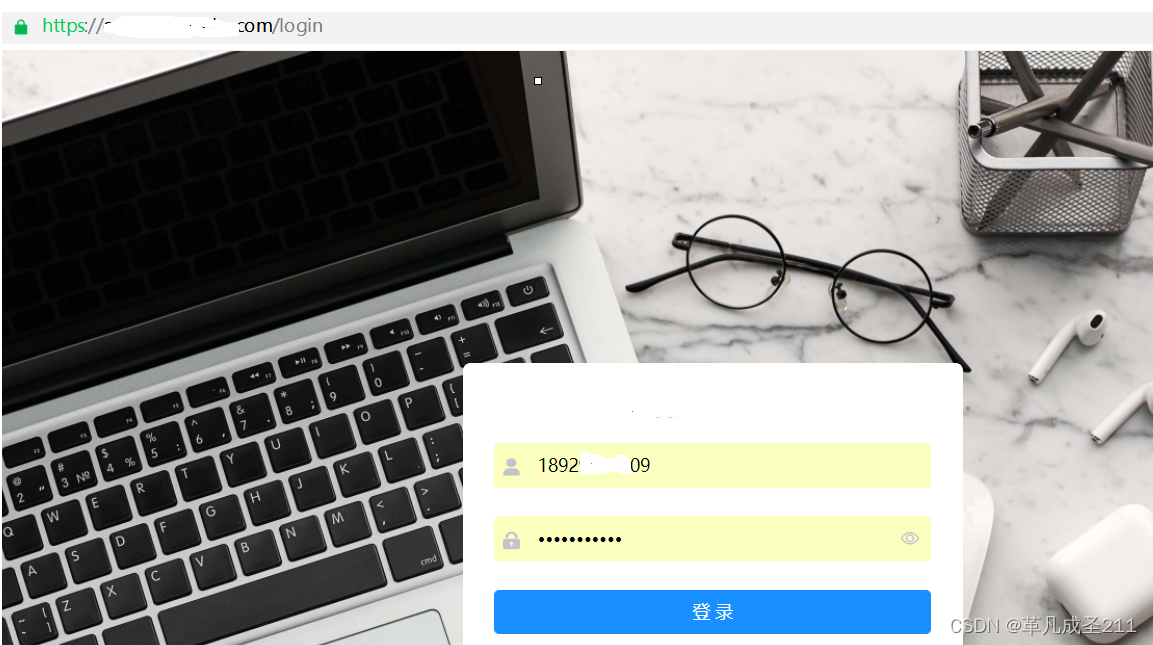
但是,可以看到,提交并且跳转页面的时候,并没有在url地址栏显示userName和password
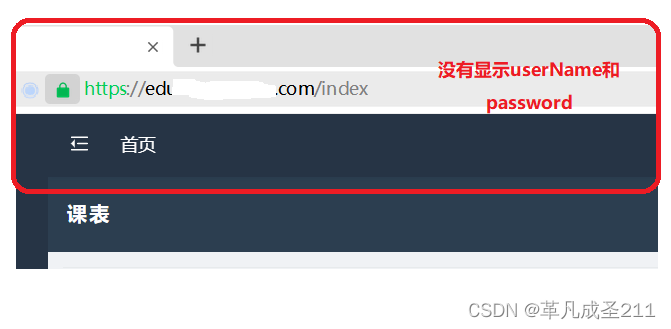 这也就说明,这个网站很有可能是使用post请求提交的,把用户名和密码封装到一个实体当中。
这也就说明,这个网站很有可能是使用post请求提交的,把用户名和密码封装到一个实体当中。
也就是post请求的body部分。
但是,在早期的网站当中,很多时候是使用get请求提交的,那么就意味着提交的内容(userName,password)都是可以显示在url地址栏当中的,这样给人感觉就很不安全。
Content-Type的各种取值
Content-Type所表示的含义,其实就是body当中数据的表示格式。
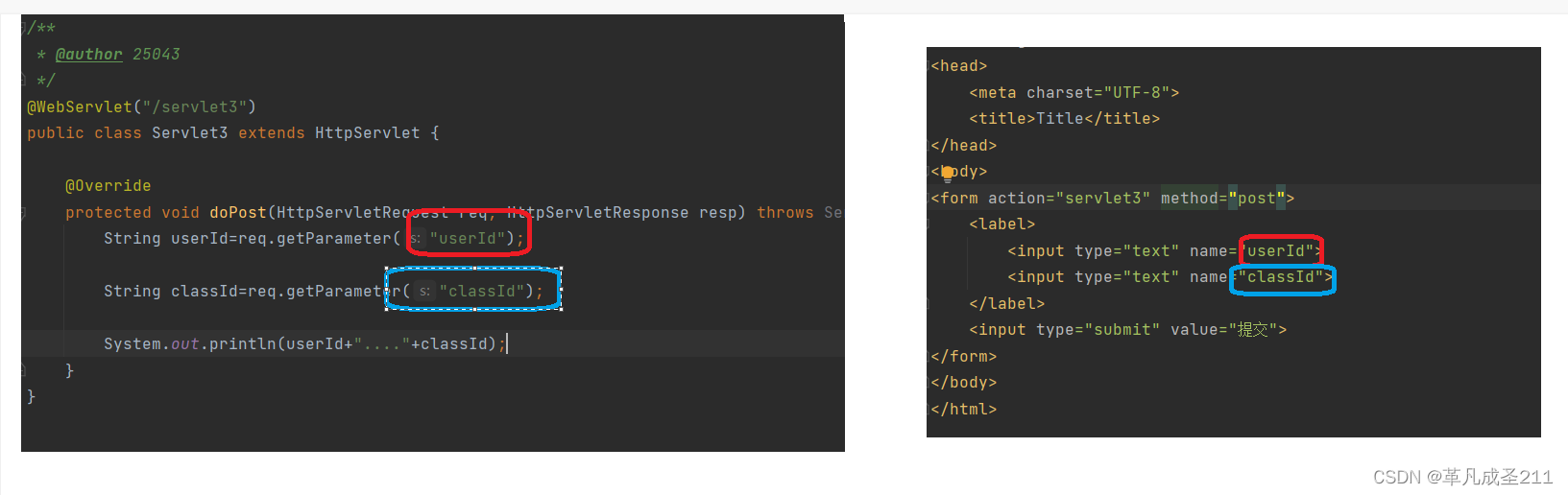
取值1:application/x-www-form-urlencoded:form

这一种取值,说明是通过表单form来进行提交。
我们常见的:url当中经常使用param1=aaa¶m2=bbb这种使用queryString的方
式,body的取值就是这样的。
在服务器当中,是以req.getParameter(name)的方式来接收参数的
取值2:multipart/form-data:form

当使用这种格式的时候,需要在form表单后面新增一个属性:enctype="multipart/form-data"。
这一种格式通常用来提交图片/文件的内容。
取值3:application/json
关于这一个取值,其实就是向服务器提交json格式的字符串。
json格式的字符串,就是类似于{"key1":"value1",
"key2":"value2"}这样的 格式的。
但是作为服务端,需要引入解析json的jar包,下面是引入了jackson来进行解析:
在pom.xml当中引入jackson的依赖:
<!-- https://mvnrepository.com/artifact/com.fasterxml.jackson.core/jackson-databind -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.14.2</version>
</dependency>
然后在前端页面当中构造ajax请求:(需要导入jqury的代码)
<input type="text" id="userId">
<input type="text" id="classId">
<input type="button" value="提交" id="submit">
<script src="JQ.js"></script>
<script>
let userIdInput=document.querySelector('#userId');
let classIdInput=document.querySelector('#classId');
let bottom=document.querySelector('#submit');
bottom.onclick=function (){
$.ajax({
//发送post请求
type:'post',
//指定servlet的路径
url:'servlet3',
contentType:'application/json',
//构造json的字符串
data: JSON.stringify({
userId:userIdInput.value,
classId:classIdInput.value
}),
success:function (body){
console.log(body);
}
});
}
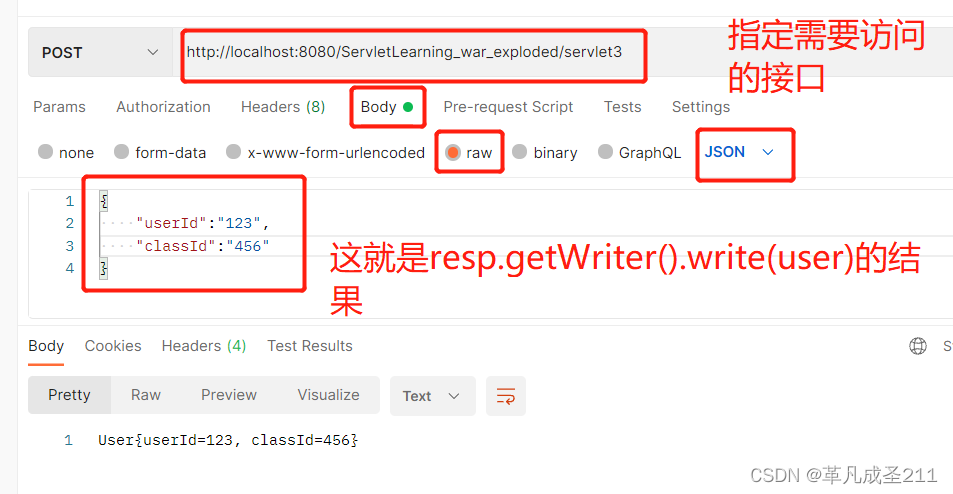
</script>如果使用postman构造,方式大致是这样:
服务端如何接收json格式的字符串(重点)
第一步:创建ObjectMapper对象(mapper);
第二步:调用(mapper)的readValue方法;这个方法内部有两个参数:
参数1:对于哪一个字符串进行转化,可以是一个输入流(req.getInputStream()),也可以是一个"name"。
参数2:需要转化的实体的字节码文件(例如User.class)
然后,在readValue方法内部读取inputStream的内容,并且转化,映射到对应的类当中.
需要注意的是,jackson需要属性名称和ajax提交的key的名称一致。
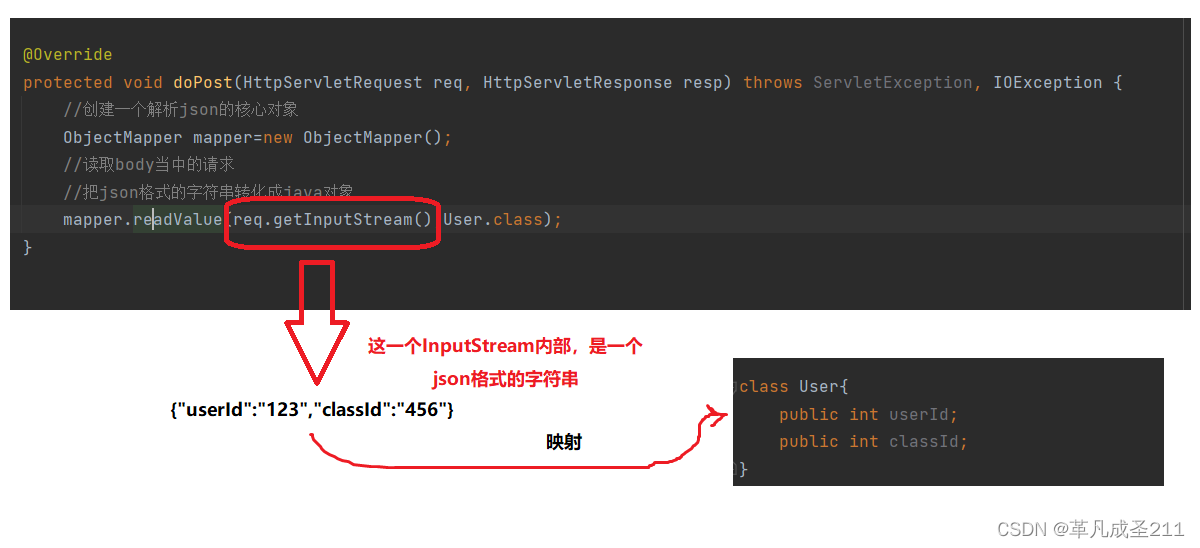
在readValue方法内部,是怎样转化的呢?
大致是这样的一个过程:
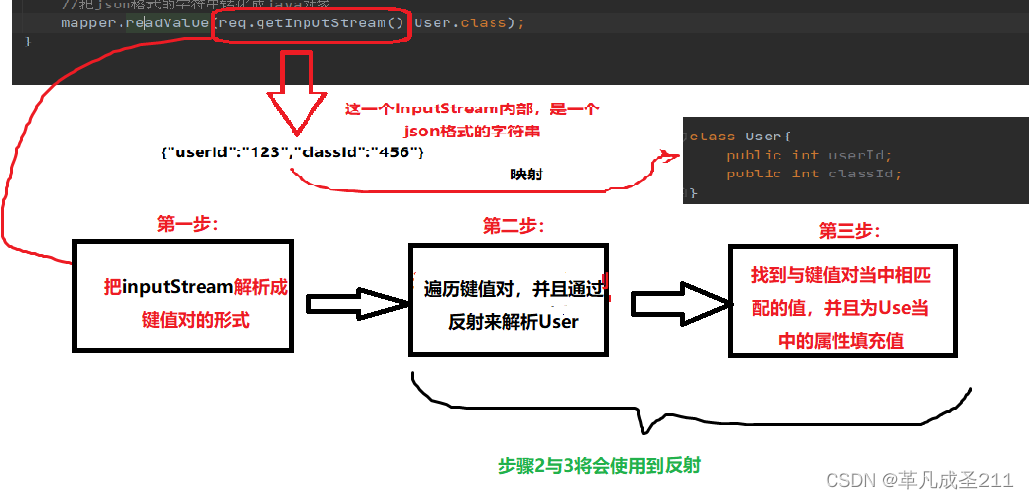
整体代码实现:
/**
* @author 25043
*/
@WebServlet("/servlet3")
public class Servlet3 extends HttpServlet {
@Override
protected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {
//创建一个解析json的核心对象
ObjectMapper mapper=new ObjectMapper();
//读取body当中的请求
//把json格式的字符串转化成java对象
User user= mapper.readValue(req.getInputStream(),User.class);
//把user返回给前端
System.out.println(user);
resp.getWriter().write(user.toString());
}
} 运行结果:
关于Content-length
其实,Content-length的值,是对于有body的HTTP请求当中,约定读取多少个字节的body来设定的。
也就是在空行之后的body部分,读取多少内容。
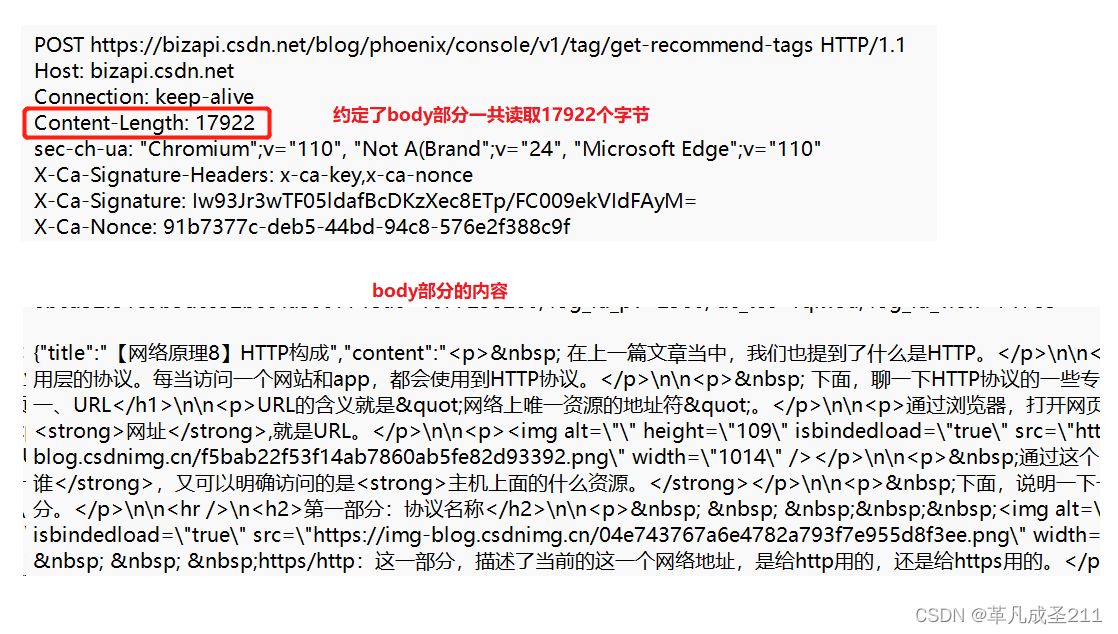
③User-Agent
表示当前用户使用的是一个什么样的设备来上网。
主要就是两部分内容:操作系统信息+浏览器信息
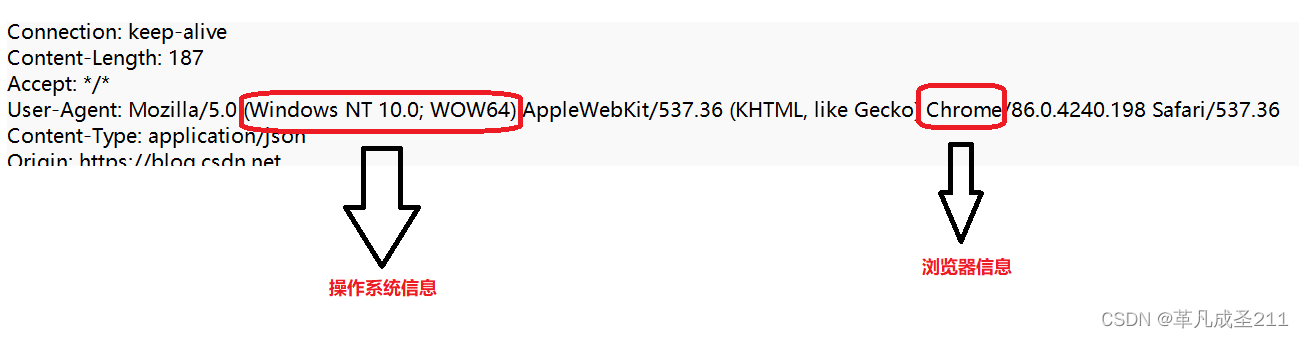
操作系统信息:括号里面的内容(Windows NT 10.0; WOW64)
代表了两个含义:
当前的windows版本为10,电脑是64位的系统。
浏览器信息:
上图显示的是Chrome浏览器。
但是,当前的互联网时代,可能User-Agent可能更大的作用就是区分PC端(电脑打开的
浏览器页面)还是手机端。为了返回一个合适的页面
④Referer:描述了当前的页面,是从哪里跳转过来的
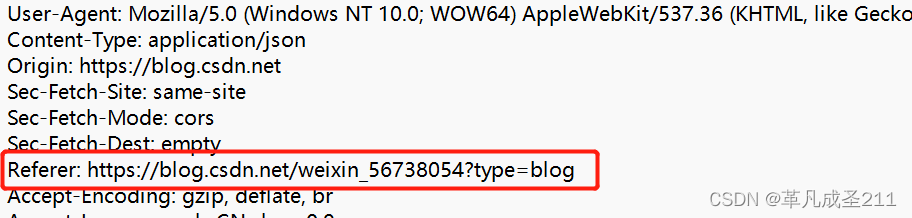
如果当前这个页面,是由其他页面的超链接等等跳转过来的,那么就会有这一个字段,显示跳转之前的页面。
下面,通过一个例子,来讲解一下这个字段的重要性:
我们都知道,互联网很大一部分的收入都来自于广告的收益。下面,打开360浏览器,然后输入"旅游":
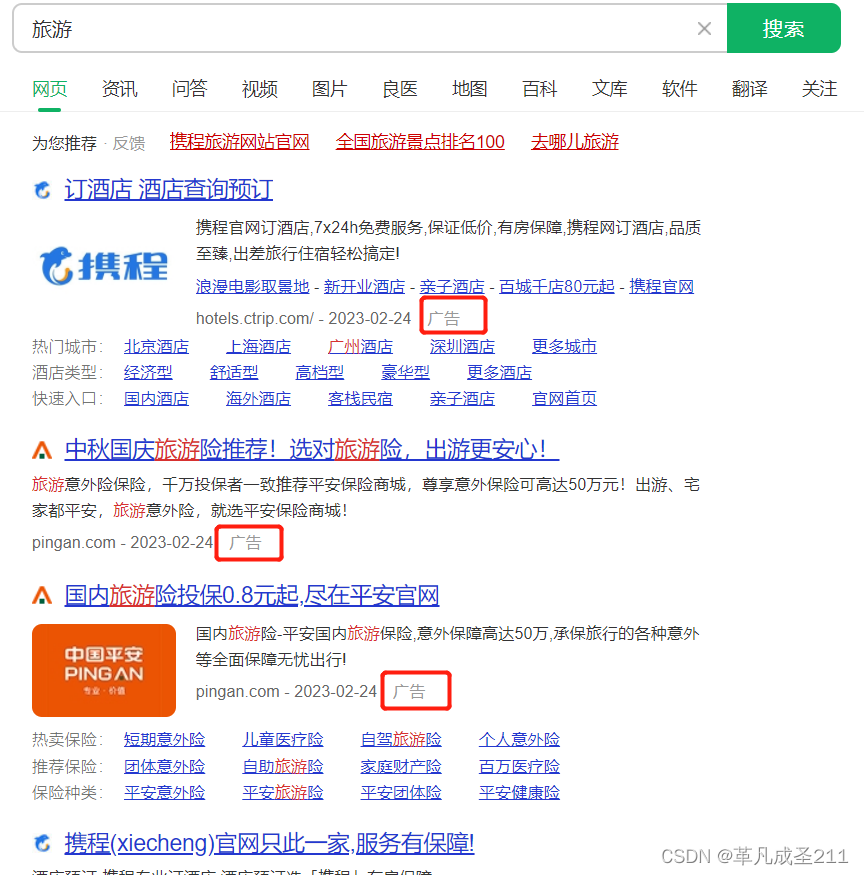
可以看到,这一个页面上面,呈现了大量的url地址。如果细心一点,可以发现这些地址的下面都有不太明显的"广告"二字。这些广告商,在浏览器上面刊登自己的页面,是需要给浏览器费用的。
怎么个收费法呢?
那就是按照点击的次数来计费。只要有用户点击其中一个url,那么就会记录点击的次数。最后,广告商根据这个点击次数来付给浏览器钱。用户点击一次,浏览器可能收几块钱,也有可能几十/几百元。
但是,这些广告商,不一定仅仅只在一个平台上面发布自己的广告信息。它有可能在多个平台上面发布信息。
这个时候,Refere字段就发挥了作用了,它可以让广告商知道是哪一个平台跳转过来的。从而付给对应的平台钱。
但是,仍然有一个存在问题,那就是,如果运营商把Refere字段给改动了,这样,岂不是会造成刊登广告的平台的经济损失?(ps:只有运营商,也就是卖路由器的那些公司,才有这个能力改动)
以上这种情况,在过去非常地猖獗,并且牵扯了很多法律问题。那么,如何避免黑心的运营商进行篡改HTTP的内容呢?下一篇文章,将会讲一下HTTPS。
⑤Connection:KeepAlive
在早期的HTTP1.1的时代,其特点是传输完成数据之后,立刻释放TCP连接,也就是短连接的。
但是,由于互联网的迅速发展,一个网站很有可能需要同一时间处理大量的请求。如果反复创建连接、销毁连接,那么就是比较耗时间的,于是引入了keep-Alive。
keep-Alive的含义:
Keep-Alive功能使客户端到服务器端的连接持续有效,也就是让这个连接保存一段时间。
后续,再次发送同一个请求的时候,如果Connection保持keepAlive,那么将会复用之前的连接。不会创建新的连接。
如果想要关闭这一个连接,需要把keep-Alive设置为close。(HTTP1.1版本默认是开启的)
五、cookie
引入cookie
为了安全,浏览器在一般情况下面,不允许让页面上面的js访问用户电脑上面的文件系统的。
但是这样的安全机制,也带来了一定的麻烦。有时候,如果确实需要在页面上面存储一些数据,方便后续的访问呢?
例如:用户登录之后,登录状态需要保存到一个特定的地方。后续,当前用户如果需要访问这个网站的其他页面的时候,服务器就可以识别了。
虽然有上面的安全机制保证。但是,其实可以让页面的js访问一个磁盘的指定空间。
这个指定的空间有很多种,但是最常见的一种就是cookie.
cookie:浏览器提供给页面的一种持久化数据的机制。这个数据不会因为程序的重启/主机重启而丢失。
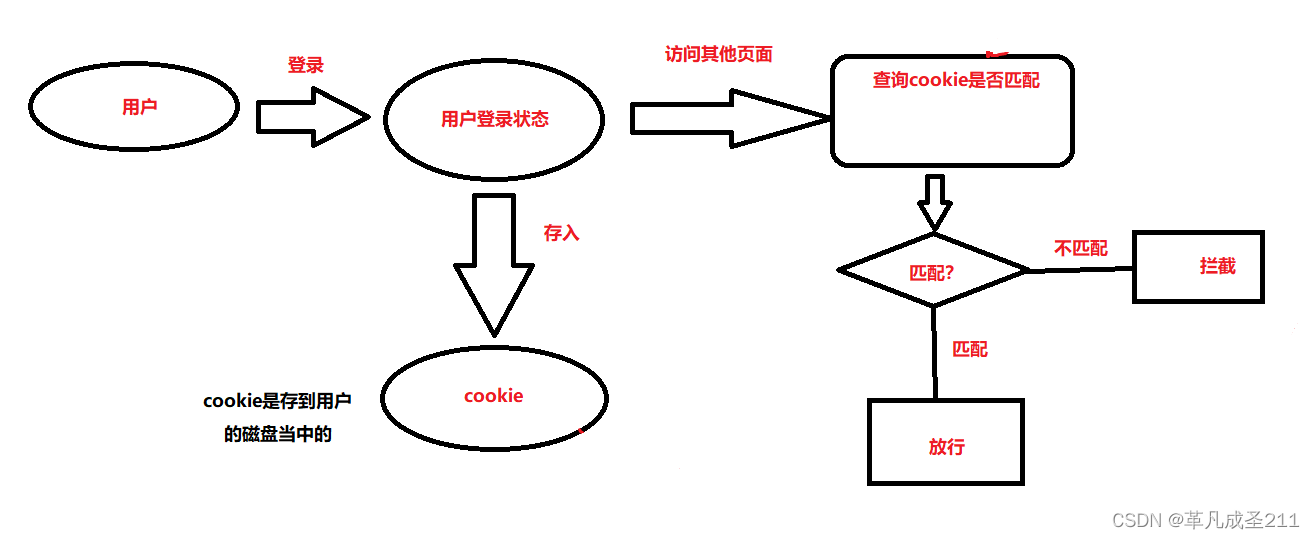
其中,cookie的数据是存储到用户的磁盘当中的一个特定的位置。也就是谁访问这个网站,那么cookie就会存在谁的磁盘当中。
cookie具体的组织形式
步骤1:按照访问网站的域名来组织。
针对每一个域名,浏览器都会分配一组cookie。
例如访问www.baidu.com的时候,就会给www.baidu.com分配一组cookie。
当访问www.sogou.com的时候,就会给www.sogou.com分配一组cookie。
步骤2:每一个域名对应的一组cookie当中,又会按照键值对来组织数据
可以这样查看当前浏览器下面的cookie:
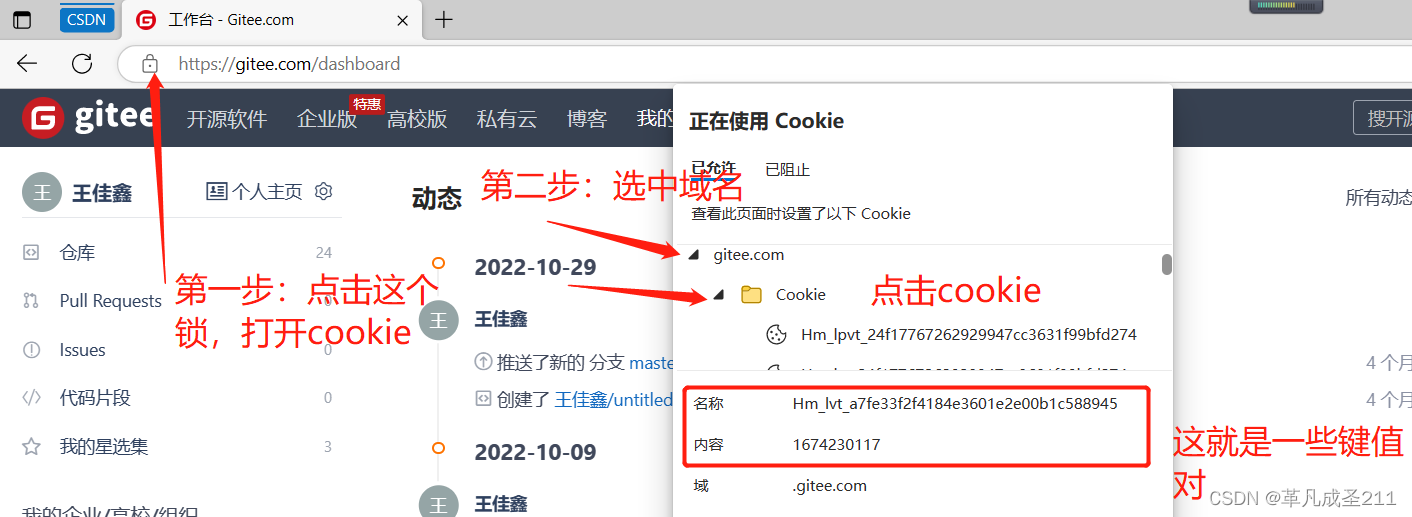
这一些键值对,就是cookie来组织的。
六、session
对于cookie,它们大部分都是把信息存放到用户的服务器上面的。因此,也就非常容易丢失。甚至用户可以点开cookie手动进行删除。并且数据量一旦大起来,那么非常不好管理
因此,引入了第二种方式来存储一些用户的信息,那就是session。
把真实的用户信息,存储到浏览器所在的服务器当中。
然后对于用户一方,仅仅存储身份标识。当需要查询用户信息的时候,直接根据用户的身份标识,然后去浏览器查询就可以了。
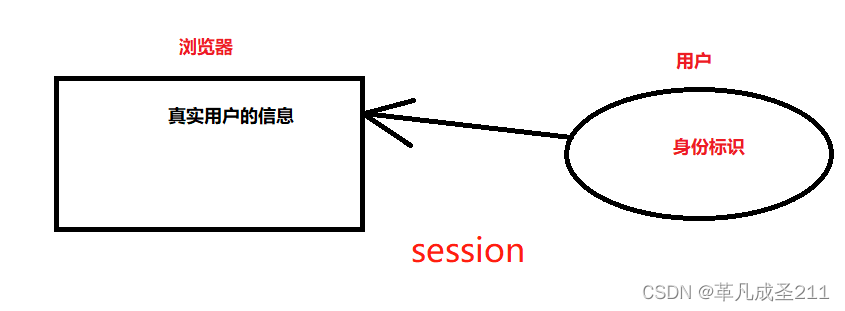
但是,实际开发当中,cookie和session很多时候都是一起配合使用的。
下面,我们使用Fidler抓包,看一下cookie当中的数据(HTTP请求)
 可以看到,在这一个cookie信息当中,有一个gitee-session-n 这样的字段
可以看到,在这一个cookie信息当中,有一个gitee-session-n 这样的字段
这一个字段,就很可能是用户的sessionID。(但是不一定绝对是)
cookie把用户的sessionID存储到用户的磁盘当中。当用户访问的时候,就根据这个sessionId查询浏览器的session的具体内容(例如用户的登录状态)。
关于cookie和session的内容,会在后面的servlet部分详细讲一下在代码当中是如何实现的。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









