






 文章讲述了作者在百度实习期间作为测试开发工程师负责的服务端测试,包括需求评审、接口测试流程、bug分级处理、印象深刻业务场景(AI智能生成数字人)及bug发现和修复的经历。
文章讲述了作者在百度实习期间作为测试开发工程师负责的服务端测试,包括需求评审、接口测试流程、bug分级处理、印象深刻业务场景(AI智能生成数字人)及bug发现和修复的经历。
目录
自动化测试的时候,怎样保证服务端运行的稳定性/测试环境的稳定性
线上巡检的好处与不足是什么?面对这些不足,有没有什么好的解决办法?
在上线新的需求适合,如果某个接口正在被大量的用户请求,如何保证新需求上线的时候这个接口还是稳定的?
在灰度发布当中,如何衡量/减少更新之前和更新之后不同用户之间因为请求这个接口得到不同结果的差异带来的损失?
Q2:介绍一下你实习过程当中比较印象深刻的业务场景(或者印象深刻的bug)
本次改动的背景(新增了modify接口:入参为gender和uid,dpuid)
Q3:如果回调机制失败,数字人的状态可能长时间停留在3,导致用户认为变更失败
Q4:对于同一个数字人,变更性别之后,尝试再次变更性别,提示错误
考虑HTTP建立连接/断开连接是否会产生额外的消耗?实际上用户切换不同数字人是否会断开连接?(选)
上述代码有没有内存溢出的风险,如果有,请问原因是什么,怎样解决?
java.lang.OutOfMemoryError: unable to create new native thread。是因为堆内存当中放不下这么多线程对象吗?
在上述代码当中,如果想模拟Jmeter一样,在规定时间内启动所有线程,可以怎样设置
如果需要构造的数据量比较大,例如要测试1万个或者更多的数字人,那么可以怎样操作?
在做压力测试的时候,如何考虑压测脚本/jmeter运行的稳定性
经典面试题:如果想要jmeter进行压测,每秒20个HTTP请求,持续30秒,应该怎样配置
一个接口的case数量比较大的时候,新的case和老的case的兼容性
批量接口执行自动化测试(未完待续)
Q1:谈一谈你实习过程当中负责了什么?
我在百度的实习当中,担任的职务是测试开发工程师(实习生)。在工作当中,主要负责百度网盘的一刻相册的服务端测试。
首先,我想讲一下服务端测试的流程:
服务端测试流程
步骤1:参与需求评审
当产品经理提出需要实现某一个需求的时候,我们一般会组织开一个短会,在会议上面,产品经理会给出这个需求的描述。产出一个交互设计文档,然后技术细节会rd在后面补充进去。写到需求文档当中。
我们这边是两周一个迭代周期,在需求评审会议上面,会划分出来若干个需求,以及各自的开发/测试负责人。由于每一个开发人员在开发需求的时候都会拉一个分支出来,我们在需求评审会议上面就需要尽可能地避免不同的开发人员之间的代码冲突。比如本次A同学对A接口的功能进行改动,那么B同学开发的时候就要避开对A接口的改动,避免产生代码冲突。
步骤2:介入测试(详细)
在这个步骤当中,rd同学一般都已经把接口开发完成,然后就等待我们进行一些接口测试了。
他们在一般情况下面在提测单当中会写好本次改动或者新增的代码是哪些,以及改动的代码属于哪个模块。同时,在提测单当中也会附有需求文档和接口文档等等。
1⃣️接下来,我们QA同学就去icode上面找到对应的代码模块,拉取对应的代码到自己的服务器当中,启动服务。
2⃣️在数据库当中构造测试可能用到的数据,然后在接口自动化平台上面编写接口的入参以及断言等等情况,来验证接口返回值是否符合预期,功能是否正常等等。
3⃣️在请求接口的过程当中,如果遇到了功能不符合预期的情况,或者接口报错的情况,我们首先会通过日志来分析问题的原因,根据错误日志,来锁定问题,给rd提出解决的方案等等。
步骤二第一步:进行code review
借助辅助工具Comcat看来完成:
也就是大致看一看代码,查看一下是否有比较明显的语法错误等等。
例如:数组越界、是否存在空指针异常等等。
同时,也需要了解清楚大致的代码逻辑,进行测试。
步骤二第二步:部署测试环境
在测试环境当中,我们需要安装一些必要的软件等等,例如mysql和redis。只有有了这些软件,我们才可以让运行的代码正常运行。
1⃣️接下来,我们QA同学就去icode上面找到对应的代码模块,拉取本次研发提测的代码分支,部署到自己的开发机上面,启动服务,让它在本地可以正常与逆行。
步骤二第三步:设计测试用例
在了解了大致的测试流程之后,我们需要设计测试用例,包括每一个接口参数是什么?结合需求文档以及代码的具体业务逻辑来完成接口测试用例的编写。
步骤二第四步:接口测试&白盒测试
一般情况下,研发同学会提供一个接口文档和,包含入参是什么、出参是什么。然后我们需要看一下返回是否符合预期。然后在公司自己研发的工具平台上面编写接口测试的case。
白盒测试:
我们需要根据接口传入参数的不同,进行白盒测试。
行覆盖(语句覆盖):该代码是否被覆盖到;
判定覆盖:每个判定的分支被测试到。(例如if,else分支等等)
条件覆盖:每个条件的取值至少满足一次。(if语句的各个条件)
此外的话,还需要进行一个步骤就是:进行存储有关系的校验,就是当我请求了接口之后,看一看数据库当中的数据有无写入进去,不应当只是看接口的断言是什么。(跟存储有关系的校验)
步骤二第五步:接口参数的参数化
比如在做接口测试case的时候,如果A接口是create person,B接口是list person。那么B接口的查询参数列表就会使用到A接口的create之后的personId。那么这个时候,A接口的personId以及B接口查询的personId就需要做参数化。把A接口返回的personId提取为一个全局变量,B接口传入的personId就引用这个全局变量。
步骤二第六步:接口断言的兼容性
对于一些接口,如果返回的字段值不确定的时候,就需要考虑兼容性的问题。
例如listPerson接口,如果输入参数userId=123,那么list接口返回的就是关于这个user下面的所有Pseron的集合。如果输入参数userId=123和输出的参数list写死,那么userId变成其他的值的时候,这个断言就会写失败。
所以这个时候,就需要考虑Person的来源:当制作一个Person的时候,把这个Person的属性的值,保存到全局变量当中,采用json表达式来提取这个Person的属性值。例如提取全局变量为:gender=$.Person.gender。
然后为list接口断言的时候,就断言返回的list接口当中的Person[0]或者Person[1]的各个字段的值。
步骤3:关于bug(如果有)
bug的等级
当出现了bug之后,我们首先会去找rd同学确认这个bug是否真的与功能存在较大的差异。然后根据bug的影响,确定bug的等级。
最高一级为p0,这这个等级的bug一般就是出现了程序的崩溃,例如代码当中存在死循环、死锁或者锁未释放等等较为严重的情况。
但是一般情况下面,如果出现了逻辑错误,但是不会导致程序崩溃或者停滞不前的,我们一般顶级为P1级别的bug。
其余的P2往下的bug,一般就是一些虽然接口返回错误,但是不影响大体功能,或者就是一些可以优化的逻辑。
bug的处理过程
提出bug:open
开发认为是bug:fix
不认为是bug:not——a——bug==》close
认为是bug但是不是特别严重,选择等一下处理==〉delay
立刻处理,处理结束之后==》resolved:等待验证。
验证通过==〉close
验证不通过==》open
步骤4:测试环境服务端接口自动化
需要做自动化测试的场景(按照重要程度)
情况1:这个业务场景比较重要,用户可能频繁访问
类似于用户登录,退出登录,或者支付等等这种比较重要的业务场景,就需要做自动化测试。确保每次需求上线之后这些功能都可以正常执行。
情况2:业务场景比较复杂
当接口涉及复杂的业务逻辑或多个数据表交互时,手动测试效率较低且容易出错。自动化测试可以通过编写脚本模拟复杂场景,确保业务逻辑正确性
情况3:接口开发出来之后,主要的功能很少再次变动。
对于某一个接口,如果第一次开发出来之后,后面的迭代周期很少再次改动了,那么就可以不用自动化测试。
如果需要,那么怎样做:
在做接口自动化测试的时候,我们需要完成两样工作:
第一步是明确接口上下文的执行顺序:
哪些步骤先执行,哪些步骤后面执行,找到接口相互依赖顺序。
第二步是添加到正式集合当中执行测试:
然和把这些接口测试的case添加到一个正式的集合里面,点击批量执行的按钮。获取接口执行的测试报告。
第三步是确定是否联调:(选)
在这一步当中,需要确定我们即将部署上线的这个服务模块是否需要跟其他模块进行联调?
如果不用联调,那么就运行完我们这个模块的接口测试case并且获取测试报告。
如果需要联调的话,那么就要首先明确我们调用的接口或者有没有其他的服务调用我们的接口。
如果存在这样的情况,就需要部署其他的服务一起执行一次这些自动化的case。
第四步是风险点评估:
如果确定有些代码一般情况下测试用例很难覆盖到,那么这个时候就需要提一个风险点。例如try-catch-finally语句块里面的异常情况catch,需要提一个风险点,并且把异常信息输入到指定的文件/数据库表当中,添加日志的告警。当告警的时候及时处理。
第五步:集成的测试环境以及master分支测试环境的接口自动化测试:
在编写好接口测试用例运行的时候,需要在自己的开发机上面运行一次接口自动化测试的case。如果没有问题了,研发就把分支合并到master分支当中,部署到一个集成的测试环境当中。
等待本期迭代周期的其他需求完成测试环境测试之后,部署到这个集成测试环境当中,统一再运行一次所有的自动化测试的case,查看测试报告,分析上线之前的风险点。
如果需要集成其他模块进行集成测试,也会在这个集成测试环境进行测试。
如果需要进行压力测试,也是在这个集成测试环境当中进行测试。
不需要做自动化测试的场景(按照重要程度排名)
情况1:需求变更太过于频繁
对于某一个接口,如果经常需要改动主要的功能,这样的接口就不适合做接口自动化。因为维护用例的成本比较高。
情况2:接口不太稳定
如果本身这个接口不太稳定,或者在这个接口调用了其他的第三方的服务,且第三方服务不稳定或不可控(如请求超时、错误码不一致),则自动化测试难以有效执行。此时需要开发人员手动添加适配代码来配合测试
情况3:重要程度比较低的需求
对于一些用户很少访问的接口,或者这个接口功能比较简单,或者只是临时的一个接口,并且不会影响主流程。那么这个接口就一般不用做接口自动化测试。
如果不需要:
研发把代码合入master分支,在统一的测试环境运行一次全部的接口自动化case,当上线之后,在线上再次运行一次接口自动化的case。
延期自动化测试
对于一些需求,如果需要实现自动化的成本和时间比较高,但是本期迭代需求比较块,那么我们就会选择延期自动化测试,也就是本次需求不做接口自动化测试,但是后面会补回来相关的自动化用例。
自动化测试当中,提升自动化测试case的可维护性和运行性
方案一,把脚本以代码模块分区运行:(已经实现)
不同的代码模块有不同的自动化case负责。例如:百度网盘有很多业务线,例如主端业务线,网盘B端业务线,网盘海外版业务线,一刻相册业务线等等,每一个业务线都有自己的代码模块,这些代码模块执行自动化测试的时候分开独立运行。
如果需要大规模联调的时候再统一添加到正式集合里面运行。
方案二,参数化设计:(已经实现)
对于接口的参数,可以采用${userId}等方式来参数化,实际的参数来自于上游其他接口的传入数据或者在csv文件当中导入的数据,避免硬编码。
方案三,加入异常处理机制:(已经实现)
例如在执行接口测试的时候,添加超时处理机制:如超过规定时间没有建立连接/没有收到响应就抛出异常,超时重新请求等等,但是最好的还是超时抛出异常。
方案四,脚本定期维护/集成到测试流水线:(已经实现)
在每次研发合并好代码准备上线之前,都会在单机测试环境,集成测试环境运行一次当前代码模块的自动化测试case,查看运行报告,获取运行日志,上线之后再在线上环境运行。
方案五,隔离环境运行:(已经实现)
例如在线下测试的时候,请求的ip+port是线下的。在线上运行的时候,请求的ip是线上的。做到请求除了url以外没有其他的区别。
方案六:定期运行/冒烟测试:(可以实现但是没有实现)
把集成环境的自动化case定期运行一下,例如每天定时运行,获取自动化测试报告等等。
自动化测试的时候,怎样保证服务端运行的稳定性/测试环境的稳定性
方案一,集成测试环境的监控与报警(未实现):
给服务端添加响应的监控告警机制,当出现cpu飙升以及内存泄露情况的时候及时告警相关人员。
方案二,分布式部署(未实现):
资源分配:合理分配服务器资源,避免资源争用或不足。
负载均衡:使用负载均衡技术,分散请求压力,避免单点过载。
方案三,数据库采用水平分表的方式:
在测试化境,线上环境,都做到了水平分表,例如digitalPerson表就是根据dpUid%表的数量得出的数据决定分配到哪个数据库上面。
方案四,合理设计数据库索引:
在研发的时候,合理根据查询的条件建立数据库索引,提高查询效率。
方案五,定期清理不必要的测试数据:
例如在测试环境数据库/redis产生了大量的脏数据,这些数据需要定期清理。
自动化测试的业务场景
回归测试:对原有测试用例的回归;
冒烟测试:在测试环境定期执行接口自动化case;
线上巡检:在线上环境运行接口自动化case。
在做接口自动化测试的时候,如何处理返回数据量特别大的接口
方案一,使用流是处理:采用I/O流把接口的数据存储到指定的文件当中,避免一次读取到内存。
方案二,提取主要字段:对于一个接口返回数据,只提取其中需要的部分,不为每一个字段都做断言。
方案三,分页处理:跟后端同学协商这个接口是否可以做成分页?接口新增page参数指定页码,约定一页多少行数据。
步骤5:上线内网,联调
在这个环节,服务端就需要跟客户端进行联调。使用到一个常见的环节就是抓包:手机跟电脑连接在一个wifi下面,手机安装Charles代理证书,电脑上面安装charles代理,确保电脑和手机在一个ip地址上面。最后通过手机点击按钮,就可以查看到接口请求和返回的情况了。
在这个环节,就可以通过接口的传入参数,传出参数定位bug出现在客户端还是服务端。
步骤6:上线外网,以及线上服务端接口自动化测试(线上巡检)
在这个环节,客户端跟服务端都上线到外网了,我们服务端需要再次运行一次接口自动化的case。
把请求接口的ip和端口号改为线上的服务器。本次需求就测试完成了。
线上巡检时候,有可能发现哪些类型的bug?
回归性质的bug:原来的版本没有问题,但是新上线了需求之后,出现了bug。
性能缺陷:由于线上的访问量比实际测试环境的大,因此线上巡检时候有可能出现504/503错误。
第三方服务:当这个接口依赖于第三方的服务,但是第三方的服务出现临时的宕机。(可以搭建mockserver来完成第三方服务的模拟)
线上巡检的好处与不足是什么?面对这些不足,有没有什么好的解决办法?
线上巡检的好处:
主动发现问题:可以更加真实地反馈用户操作导致的真实问题,减少故障影响的范围
降低运维成本:
自动化巡检减少人工干预,提高运维效率。
例如:通过脚本定期检查服务状态,减少人工巡检工作量
线上巡检的不足
资源消耗:
频繁巡检可能占用系统资源,影响正常业务运行。
例如:巡检脚本占用大量CPU或带宽。
复杂性高:
随着系统规模扩大,巡检脚本和规则可能变得复杂,难以维护。
例如:分布式系统中,巡检脚本需要适配多种环境。
依赖于人工分析:
巡检结果需要人工分析,可能存在主观判断错误或响应延迟。
例如:巡检报告需要运维人员手动排查,耗时较长
会产生比较多的脏数据:
可能导致线上的数据库当中产生大量的冗余数据,影响线上真实用户查询的性能
针对线上巡检的不足的解决办法
优化巡检范围:在巡检的时候,只覆盖主流程或者重要的流程。
简化巡检的复杂度:例如把巡检脚本模块化执行,针对不同的代码模块执行各自的巡检脚本
定期清理数据:尽可能与巡检时间错开。比如巡检是每天都有,但是数据清理是每隔两周到三周一次。通过脚本来清理数据确保线上的真实数据不会被误删。
在上线新的需求适合,如果某个接口正在被大量的用户请求,如何保证新需求上线的时候这个接口还是稳定的?
在上线新需求时,确保高流量接口的稳定性至关重要。以下是一些关键措施:
1. 灰度发布
逐步发布:先让新版本在小部分用户中运行,观察稳定性和性能,再逐步扩大范围。
流量控制:通过负载均衡或网关工具,控制新版本的流量比例。
2. 蓝绿部署
双环境切换:保持两个独立环境(蓝绿),新版本部署在绿色环境,测试通过后切换流量。
快速回滚:如果新版本有问题,可以迅速切回蓝色环境。
3. 金丝雀发布
小范围测试:先让少量用户使用新版本,逐步增加流量,确保稳定后再全面上线。
在灰度发布当中,如何衡量/减少更新之前和更新之后不同用户之间因为请求这个接口得到不同结果的差异带来的损失?
用户分桶与流量控制
-
分桶策略:将用户流量按固定比例划分(如5%灰度组、95%对照组),确保两组用户特征分布一致。
-
逐步放量:从低风险用户(如内部员工、测试用户)开始,逐步扩大到普通用户。
-
动态调整流量:根据监控指标动态调整灰度流量比例,确保问题影响范围可控。
自动化测试与对比
-
自动化回归测试:在灰度发布前,运行全面的回归测试,确保新版本不会破坏现有功能。
-
响应对比工具:编写脚本对比新旧版本的响应结果,标记不一致的字段或行为。
-
实时监控差异:通过日志系统(如ELK、Splunk)实时监控灰度组和对照组的差异。
数据格式的兼容
-
数据格式兼容:确保新旧版本的数据格式(如JSON字段)兼容,避免客户端解析失败。
功能开关(Feature Flags)
-
动态控制:通过功能开关动态启用或禁用新功能,无需重新部署代码。
-
细粒度控制:可以根据用户ID、地域、设备等条件逐步开放新功能。
-
快速回退:如果发现问题,可以立即关闭功能开关,恢复到旧版本逻辑。
监控与告警
-
核心指标监控:
-
技术指标:错误率、响应时间、吞吐量。
-
业务指标:订单转化率、支付成功率、用户留存率。
-
-
实时告警:设定阈值(如错误率>1%或响应时间>500ms),触发告警并通知相关人员。
-
日志追踪:通过Trace ID追踪单个用户的请求链路,快速定位问题。
Q2:介绍一下你实习过程当中比较印象深刻的业务场景(或者印象深刻的bug)
在实习过程当中,我遇到了一个比较印象深刻的业务场景是关于一刻相册当中一个根据用户照片,AI智能生成数字人、写真的场景。
原始背景
原有的场景是:用户根据自己的百度账号,登录了一刻相册之后,可以看到一个AI印象馆的标识。
点击进去之后:用户需要上传20张照片,然后会根据这20张照片,请求智能化的接口,生成一一个数字人。这里的用户(user)和数字人的实体关系是(一对多):一个user可以对应多个digital_person_info。也就是一个用户可以制作多个数字人。
数字人有以下几个比较特殊的属性:
属性1:数字人的性别:0女1男;
属性2:数字人的文件缩略图id:fsid;
属性3:数字人的图片属性模板描述(一个json数组,里面包含了动作id,模板的代码描述id:数字人的性别+年龄的id,一共4个组合:例如成年男性是30100,未成年女性是31100......)
属性4:数字人的status,1为制作成功,3为制作中,4为制作失败
本次改动的背景(新增了modify接口:入参为gender和uid,dpuid)
上下游接口的主要任务
上游接口传入uid,dp_uid,以及gender三这个主要的字段。
上游的主要任务就是完成这个几个参数的校验,校验他们之间的正确性。
以及变更性别的正确性:例如男的不可以再变成男的;女的不可以再变成女的。以及uid下面的dp_uid都属于这个用户。
下游联调的时候,主要传入了这几个参数:
uid,dp_uid,taskId。
taskId=uid+dp_uid+时间戳(原本是uid+dp_uid的)但是后面发现了一个bug,就改成taskId=uid+dp_uid+时间戳。
其中taskId作为本次请求的requestId以及logId,需要在客户端请求之后立刻生成,每一次变更性别的taskId都不一样 。
联调时候发生的事情
第一步:采用http.newRequest请求下游的接口(同步)
往下游的接口传入三个参数:uid,dp_uid,taskId:其中taskId为uid+dp_uid+时间戳。
下游在接收到这个taskId之后,就会正式启动变更数字人性别的任务。
第二步:修改数字人status并且往任务表插入数据
在请求下游的接口之后,就把数字人的status修改为3:正在制作当中。
并且往任务表task(taskID,uid,dp_uid,status,lastChangeTime)当中插入一条数据,
这条数据的status=3,代表任务正在执行当中。
以上两个步骤需需要绑定成为一个事务。
请求的时候如果下游的接口报错,那么就可以直接返回了,不用修改数字人的性别。
下游的大模型服务会根据我们提供的taskId来变更数字人的性别
变更成功:调用我们这边服务的回调接口,修改数字人状态为1
制作成功之后,下游的接口就会进行回调操作:
调用我们这边的回调接口:入参:uid,dp_uid,gender,status,taskId。
uid:用户Id
dp_uid:数字人的Id
gender:目标变更的性别
status:变更成功为1
taskId:上游传入的参数taskId。
回调接口的主要逻辑
步骤一:查询task表以及dp表,任务是否处于变更中:status=3
如果这次的任务task的status仍然处于3这个状态以及dp表的status仍然处于3这个状态,那么执行下面的任务:
回调接口会把数字人的status修改为1,并且把gender修改为目标性别,
同时我们在log文件当中可以看到回写的taskId(logId),
并且把任务表task(taskID,uid,dp_uid,status,lastChangeTime)当中uid和dp_uid对应的status改回1.把lastChangeTime改为回调成功的时间。
本次任务完成。
步骤二:查询发现任务的status为4,以及数字人的status=4,变更失败的情况
那么就不会进行步骤一的修改,直接返回,提示“变更失败”。
回调失败情况
下游请求回调的时候响应时间超时。
下游回调时候我方接口出现请求异常。
数字人需求测试用例设计
P0级别的用例:
①对于参数的校验:uid,dp_uid正确;传入的dp_uid一定是当前用户uid下面的。如果不一样的报错
②男性数字人变女性
③女性数字人变男性
④男性再次传入男性
⑤女性再次传入女性
⑥男性变为女性之后,再变回男性
⑦女性变成男性之后,再次变回女性
P1级别的用例:
⑧:针对同一个数字人,变更的时候再次传入变更的参数--提示正在变更当中
⑨:同一个用户,同时制作了多个数字人,一起变更,用户变更了一个之后继续接着变更两个,三个...所有数字人变更。
(这里为了防止用户制作大量的数字人,一起变更,造成下游大模型响应迟钝,我们做了限制。在尝试变更当前数字人性别的时候,先查询一下当前用户下面有多少个数字人正在变更性别。如果正在变更的超过10个,那么就返回消息提示:数量已经超出限额,需要等待制作完成)
(还有变更效果的评估,见Q8)
⑩:不同的用户,各自同时变更自己制作的数字人
P2级别的用例:
十一:请求下游ip正确,也就是向下游提交了制作的任务,提交成功,返回200状态码(只允许特定的服务器ip地址访问大模型)
十二:下游ip错误/下游环境报错/下游接口500:也就是请求下游状态码不是200的情况,可能是500的时候等等。下游ip错误的时候,数字人的status会不会变为3?
十三:通过和下游的联调:(发送HTTP请求是同步的http.NewRequest,但是制作成功之后会回调)
制作失败/超时(调用list接口查询时候,会看到制作失败的提示,并且还是原来的数字人)
这种情况是提交任务成功,返回状态码200。但是数字人一直处于制作中,看不到制作成功的结果。
P3级别的用例:
十四(选):请求超时的情况?根据taskId终止任务,并且给客户端提示请求超时。
(请求超时分为两种,上游请求下游超时,以及下游回调时候超时。)
上游请求下游超时的情况表现为用户点击了变更性别的按钮之后一直停在页面上面卡顿。
下游回调时候超时可以通过脚本来修改)
十五:下游制作成功之后,调用回调接口,回调接口的参数:uid,dp_uid,status,fsid(制作成功之后就是新的fsid)。
回调接口的安全性设计:对于这个接口只允许特定的ip地址访问。
十六:回调接口请求我们这边的服务失败:接口报错500等:终止任务并且把数字人状态修改为4.数字人fsid仍然是原来的值。
十七(选):回调接口回请求调超时:终止任务并且修改数字人status为4,数字人fsid仍然是原来的值。
对于这个需求,有做接口自动化吗?为什么?
我们选择了做延期自动化测试:原因:
第一个:考虑到这个接口的重要程度,这个接口预计在上线之后会有大量的用户访问,是一个比较重要的接口,因此要做接口自动化测试。
第二个:为了自动化测试的稳定性,下游的接口需要用mock代替大模型接口,需要搭建额外的mock环境,但是本期迭代比较紧,就暂时没有做接口自动化,等待后期完善。
本次测试遇到的困难
在联调下游智能化接口的时候,这个过程比较复杂。
第一步:需要明确下游服务启动的ip和port,http请求需要打到他们的服务器上面。
第二步:联调时候,需要在他们的服务器看到我们上游传入的logid。需要不断与他们进行沟通,观察日志的情况。并且需要考虑下游服务可能出现的问题
联调应该发生在测试的什么阶段?
首先,我方需要明确我们向下游的接口传入的参数是什么?明确我们传入的参数之后,启动服务之前,就需要开始准备联调了。因为我们请求下游的时候,需要做到:我们这边的问题及时被他们发现,或者他们的问题及时被我们发现,这个就是需要通过taskId:uid+dp_uid+时间戳来传递消息,定位问题。
Q3:如果回调机制失败,数字人的状态可能长时间停留在3,导致用户认为变更失败
在这个业务场景当中,如果下游的服务在制作的时候产生了崩溃,那么这个数字人的状态就永远停留在status=3这个下面。用户查询这个数字人的时候(调用list接口),就只能看到这个数字人一直处于变更当中的状态,即使下游的服务恢复了,也无法重启制作。
研发做了哪些改动
改动1:下游的服务自行配置了检测失败的机制,如果对于一个数字人制作失败了,回调的时候传入status=4:制作失败;fsId还是原来的fsId,不改动。并且根据taskId终止这次变更任务。
改动2:新增检测脚本,每隔15分钟运行一次。
查询任务表(taskID,uid,dp_uid,status,lastChangeTime)。
查看有没有status=3并且最后修改的时间和现在差距>=15分钟的,如果有,就把status改为4,制作失败。
并且给对应的数字人的status修改为4。
并且根据taskId终止这次变更的任务。
数字人的fsid不变。
代码配置文件设计
config-test.properties(测试环境)
db.url=jdbc:mysql://test-db-host:3306/test_database
db.user=test_user
db.password=test_passwordconfig-dev.properties(开发环境)
db.url=jdbc:mysql://dev-db-host:3306/dev_database
db.user=dev_user
db.password=dev_password研发代码:
package TestFile;
import java.io.FileInputStream;
import java.io.IOException;
import java.sql.*;
import java.time.LocalDateTime;
import java.time.temporal.ChronoUnit;
import java.util.Properties;
public class TaskMonitor {
private static String dbUrl;
private static String dbUser;
private static String dbPassword;
public static void main(String[] args) {
// 加载配置文件
String environment = System.getProperty("env"); // 通过命令行参数指定环境
if (environment == null || !(environment.equals("test") || environment.equals("dev"))) {
System.err.println("请指定运行环境:-Denv=test 或 -Denv=dev");
System.exit(1);
}
loadConfig(environment); // 加载对应环境的配置文件
checkAndUpdateTasks(environment); // 执行任务
}
/**
* 加载配置文件
*/
private static void loadConfig(String environment) {
Properties props = new Properties();
String configFile = "config-" + environment + ".properties";
try (FileInputStream input = new FileInputStream(configFile)) {
props.load(input);
dbUrl = props.getProperty("db.url");
dbUser = props.getProperty("db.user");
dbPassword = props.getProperty("db.password");
} catch (IOException e) {
System.err.println("无法加载配置文件: " + configFile);
e.printStackTrace();
System.exit(1);
}
}
/**
* 检查任务表并更新状态
*/
private static void checkAndUpdateTasks(String environment) {
try (Connection conn = DriverManager.getConnection(dbUrl, dbUser, dbPassword)) {
// 查询符合条件的任务
String query = "SELECT taskID, uid, dp_uid, lastChangeTime FROM tasks WHERE status = 3";
try (PreparedStatement pstmt = conn.prepareStatement(query)) {
ResultSet rs = pstmt.executeQuery();
while (rs.next()) {
int taskID = rs.getInt("taskID");
int uid = rs.getInt("uid");
int dpUid = rs.getInt("dp_uid");
Timestamp lastChangeTime = rs.getTimestamp("lastChangeTime");
// 计算时间差
LocalDateTime now = LocalDateTime.now();
LocalDateTime lastChange = lastChangeTime.toLocalDateTime();
long minutesDiff = ChronoUnit.MINUTES.between(lastChange, now);
// 如果时间差 >= 15分钟,更新状态
if (minutesDiff >= 15) {
//终止变更任务
stopTheTask(taskID);
// 发送告警信息
Utils.alert("环境是:"+environment+"任务 " + taskID + " 已超时,请及时处理。"+"错误的userId为:"+uid+",数字人id为:"+dpUid);
updateTaskStatus(conn, taskID, 4); // 更新任务状态为4
updateDigitalHumanStatus(conn, dpUid, 4); // 更新数字人状态为4
System.out.println("Task ID " + taskID + " and Digital Human ID " + dpUid + " updated to status 4.");
}
}
}
} catch (SQLException e) {
e.printStackTrace();
}
}
/**
* 停止制作任务的逻辑
* 任务Id@param taskID
*/
private static void stopTheTask(int taskID) {
// 停止任务的逻辑
}
/**
* 更新任务状态
*/
private static void updateTaskStatus(Connection conn, int taskID, int status) throws SQLException {
String updateQuery = "UPDATE tasks SET status = ? WHERE taskID = ?";
try (PreparedStatement pstmt = conn.prepareStatement(updateQuery)) {
pstmt.setInt(1, status);
pstmt.setInt(2, taskID);
pstmt.executeUpdate();
}
}
/**
* 更新数字人状态
*/
private static void updateDigitalHumanStatus(Connection conn, int dpUid, int status) throws SQLException {
String updateQuery = "UPDATE digital_humans SET status = ? WHERE uid = ?";
try (PreparedStatement pstmt = conn.prepareStatement(updateQuery)) {
pstmt.setInt(1, status);
pstmt.setInt(2, dpUid);
pstmt.executeUpdate();
}
}
}
部署和运行
在测试环境运行
-
确保
config-test.properties文件存在,并配置了测试环境的数据库信息。 -
使用以下命令运行脚本:
java -Denv=test -cp . TaskMonitor
在开发环境运行
-
确保
config-dev.properties文件存在,并配置了开发环境的数据库信息。 -
使用以下命令运行脚本:
java -Denv=dev -cp . TaskMonitor
配置Cron任务
在Linux服务器上,为每个环境配置Cron任务。
测试环境Cron配置
编辑Cron任务:
crontab -e
添加以下内容:
*/15 * * * * java -Denv=test -cp /path/to/your/java/program TaskMonitor >> /path/to/your/task_monitor_test.log 2>&1开发环境Cron配置
编辑Cron任务:
crontab -e
添加以下内容:
*/15 * * * * java -Denv=dev -cp /path/to/your/java/program TaskMonitor >> /path/to/your/task_monitor_dev.log 2>&1目录结构示例
/path/to/your/java/program/
├── TaskMonitor.java
├── TaskMonitor.class
├── config-test.properties
├── config-dev.properties
└── run_task_monitor.sh这个bug给我的启示是什么
①做测试的时候,需要站在用户的角度,多站在用户使用习惯的角度来考虑可能出现的bug;
②接口测试的时候,不仅仅需要考虑单个接口的运行情况,还需要考虑其他接口和这个接口的依赖关系。如果有涉及到相互联调的问题,那么就应当考虑下游/上游服务异常时候的处理办法。
Q4:对于同一个数字人,变更性别之后,尝试再次变更性别,提示错误
bug的现象以及原因
当一个数字人从男变女,再变回男的时候,下游会报错。
报错原因:下游接到上游传入的uid+dp_uid的时候,如果变更一个数字人,那么就会针对这次变更生成一个taskId。这个taskId是由uid+dp_uid拼接,但是当再次制作的时候,如果taskId重复,那么下游的接口就会报错。
解决办法
在和下游联调的时候,多传入一个参数,是当前的时间戳,下游拼接的时候,就以
dp_uid+uid+时间戳来生成taskId。这样就可以避免再次变更一个数字人的时候报错。确保taskId的唯一性
Q5:用户同时变更大量的数字人,可能导致下游大模型崩溃
用户变更数字人性别的时候,可以选择自己制作的一个或者多个数字人来进行变更。但是,由于用户可以制作无限多个数字人,如果同时针对这些数字人一起变更性别,那么也会有比较大的风险。因为下游的模型没办法同时接受这么多个变更的任务。
风险评估
对于这个风险。我们这边做了这样一个评估,首先跟下游的大模型接口进行了一下衡量,下游的大模型最多只能同时变更大约5000个数字人。如果超过这个数,可能会引起模型崩溃。
我们这个app日活跃用户在1000人左右,也就是如果每个用户都同时变更5个左右的数字人,有可能会引起模型的崩溃。
所以选择最极端的情况:
并发设置:1000个用户,每个变更5个数字人。
有没有实际上对于这种情况进行测试(选)
测试环境的选择:
选择的环境是集成测试环境,因为在这个环境当中,适合做压力测试。而在单机的测试环境当中不适合做压力测试。
测试步骤(Jmeter实现):
测试计划下面添加HTTP请求默认值,设置为"keep-Alive"(选,因为HTTP1.1默认是保持连接的)
步骤1:新建线程组:考虑线程数量:设置为1000;(新建一个线程组,线程数量为1000),启动时间为0,模拟瞬间启动的场景。
步骤2:线程组下面新建循环控制器,循环次数为5。代表单个用户依次按照顺序(非并发)点击5个数字人进行性别变更。
步骤3:在循环控制器下面新建csv数据文件设置,采用分隔符隔开参数uid,dpUid,gender
步骤4:在循环控制器下面新建固定定时器,设置线程延迟数量为500毫秒,模拟用户每隔0.5秒切换一个数字人。
步骤5:在循环控制器下添加HTTP请求指定ip,port,url以及接口参数等等。
步骤6:在线程组的同级目录下面新增查看结果数以及汇总报告。
整体Jmeter结构
测试计划
├── HTTP请求默认值 (配置协议、服务器地址、端口号,启用Keep-Alive)
└── 线程组 (用户数: 1000, 启动时间: 0)
├── 循环控制器 (循环次数: 5)
│ ├── CSV 数据文件设置 (读取test.csv文件)
│ ├── 固定定时器 (500 毫秒)
│ └── HTTP请求 (POST /change-gender)
└── 监听器 (查看结果树、聚合报告)有没有设置单个接口的响应超时时间处理?(选)
有的,在HTTP请求当中,找到“高级”选项,设置连接超时时间以及响应超时时间
这样当请求建立超时或者读取响应超时就会抛出异常
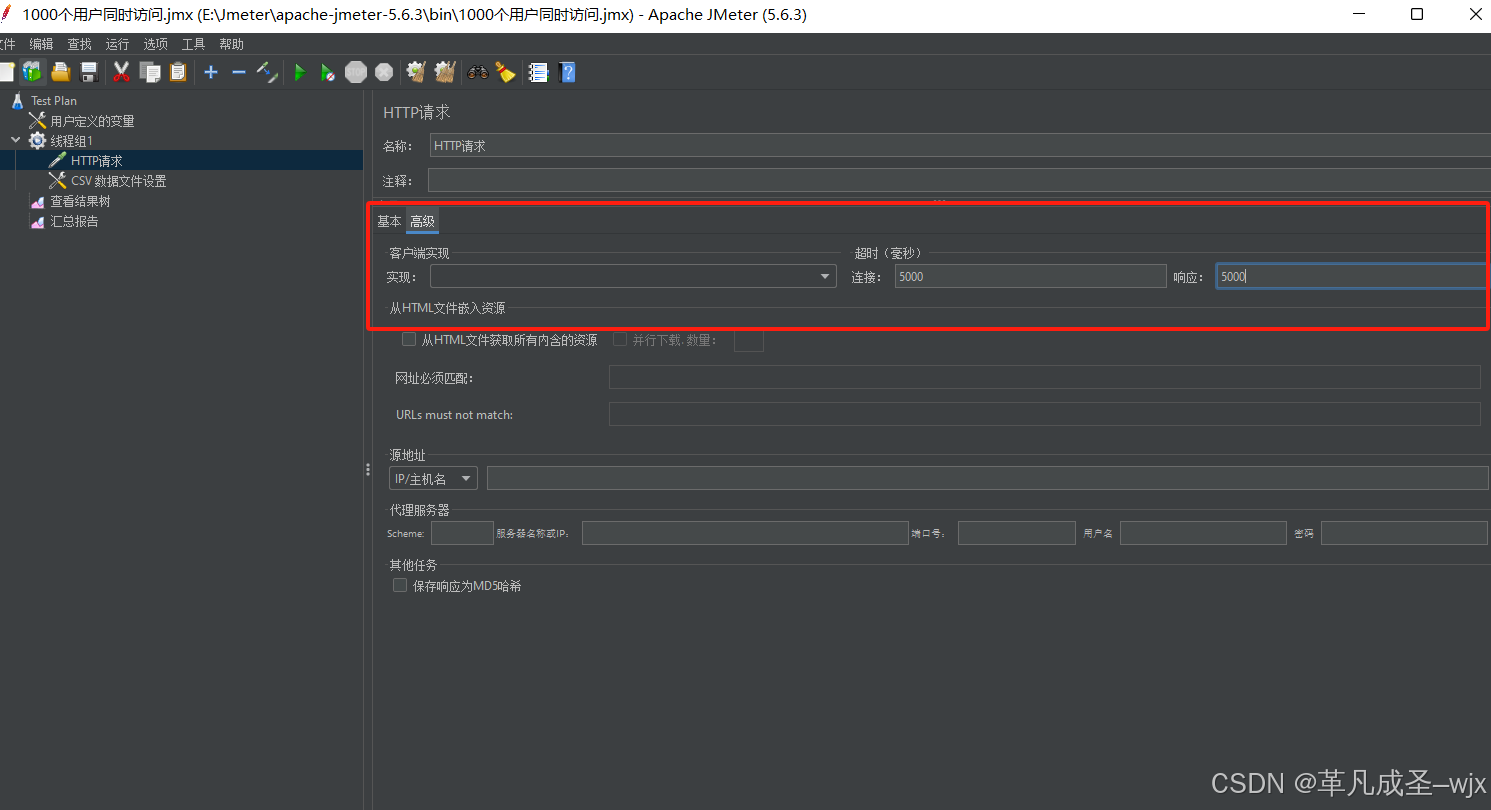
连接超时时间和响应超时时间的区别
1. 连接超时时间(Connect Timeout)
连接超时时间是指 客户端与服务器建立连接的最大等待时间。具体来说,它涵盖了以下阶段:
-
DNS 解析:将域名解析为 IP 地址的时间。
-
TCP 握手:与服务器建立 TCP 连接的时间(即三次握手)。
-
SSL/TLS 握手(如果使用 HTTPS):与服务器建立安全连接的时间。
如果在这个时间内未能成功建立连接,JMeter 会抛出 ConnectTimeoutException,并标记请求为失败。
适用场景
-
当服务器网络不稳定或无法访问时,连接超时会触发。
-
如果 DNS 解析时间过长,也可能导致连接超时。
示例
-
设置连接超时为
5000毫秒(5 秒):-
如果客户端在 5 秒内无法与服务器建立连接,请求会失败。
-
2. 响应超时时间(Response Timeout)
响应超时时间是指 从连接建立成功到接收到完整响应的最大等待时间。具体来说,它涵盖了以下阶段:
-
发送请求:客户端将 HTTP 请求发送到服务器的时间。
-
服务器处理:服务器处理请求并生成响应的时间。
-
接收响应:客户端从服务器接收完整响应数据的时间。
如果在这个时间内未能接收到完整的响应,JMeter 会抛出 SocketTimeoutException,并标记请求为失败。
考虑HTTP建立连接/断开连接是否会产生额外的消耗?实际上用户切换不同数字人是否会断开连接?(选)
关于这个问题,需要考虑的地方是:服务端连接会保持多久,超时时间是多少/同一个连接最多支持多少个HTTP请求,服务器的配置如下:
server: port: 8083 tomcat: keep-alive-timeout: 60000 # Keep-Alive 超时时间,单位毫秒 max-keep-alive-requests: 100 # 最大 Keep-Alive 请求数
设计方案:(暂未实现)
配置1000个可以使用的代理ip,模拟1000个用户所发起请求去ip地址,写入到csv文件当中,然后发起HTTP请求。
代码实现:(Java代码实现):
package com.example;
import io.qameta.allure.Allure;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.http.ResponseEntity;
import org.springframework.web.client.RestTemplate;
import org.testng.annotations.Test;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
@SpringBootTest
public class ModifyDigitalPersonByUidAndDpUidTest {
private static final int NUM_DIGITAL_HUMANS_PER_USER = 5;
private static final int USER_COUNT = 1000; // 并发线程数
AtomicInteger successCount = new AtomicInteger(0); // 成功请求计数器
AtomicInteger failureCount = new AtomicInteger(0); // 失败请求计数器
RestTemplate restTemplate=new RestTemplate();
@Test
public void testModify() throws Exception {
ExecutorService executorService = Executors.newFixedThreadPool(USER_COUNT);
// 读取CSV文件,按用户分组
List<String[]> userTasks = readCsvFile();
//输出5000,代表5000个数字人
System.out.println(userTasks.size());
//并发1000个用户
for (int i = 0; i < userTasks.size(); i += 5) {
int finalI = i;
executorService.submit(() -> {
//每一次切换其他用户之前都重建HTTP请求
for (int j = 0; j < NUM_DIGITAL_HUMANS_PER_USER; j++) {
String[] params = userTasks.get(finalI + j);
int userId = Integer.parseInt(params[0]);
int dpId = Integer.parseInt(params[1]);
int gender = Integer.parseInt(params[2]);
try {
String url = String.format("http://127.0.0.1:8083" +
"/digitalPerson" +
"/modifyDigitalPersonByUidAndDpUid?" +
"userId=%s&dpUid=%s&gender=%s", userId, dpId, gender);
ResponseEntity<String> response = restTemplate.getForEntity(url, String.class);
// 验证状态码
if (response.getStatusCode().is2xxSuccessful()) {
successCount.incrementAndGet();
} else {
failureCount.incrementAndGet();
Allure.step("请求失败,状态码: " + response.getStatusCodeValue());
}
//线程等待半秒,模拟用户切换数字人的时间
//每一个用户按照顺序提交5个变更数字人的HTTP请求,每一个请求间隔0.5秒
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
failureCount.incrementAndGet();
Allure.step("请求失败的userId:" + params[0]);
Allure.step("请求失败的dpId:" + params[1]);
Allure.step("请求失败的gender:" + params[2]);
Allure.step("请求失败,失败原因: " + e.getMessage());
}
}
});
}
executorService.shutdown();
boolean terminated = executorService.awaitTermination(Long.MAX_VALUE, TimeUnit.MILLISECONDS);
if (!terminated) {
System.out.println("线程池未在指定时间内关闭,仍有任务未完成");
Allure.step("线程池未在指定时间内关闭,仍有任务未完成");
} else {
System.out.println("线程池正常关闭");
Allure.step("线程池正常关闭");
}
System.out.println("成功数量:" + successCount);
System.out.println("失败数量:" + failureCount);
Allure.step("成功数量:" + successCount);
Allure.step("失败数量:" + failureCount);
}
private static List<String[]> readCsvFile() throws Exception {
List<String[]> userTasks = new ArrayList<>();
BufferedReader br = new BufferedReader(new FileReader("src/test/Resource/modifyDigitalPersonByUidAndDpUid.csv"));
String line;
br.readLine(); // 跳过标题行
// 按用户分组读取CSV文件
while ((line = br.readLine()) != null) {
userTasks.add(line.split(","));
}
br.close();
return userTasks;
}
}上述代码有没有内存溢出的风险,如果有,请问原因是什么,怎样解决?
产生内存泄露的原因
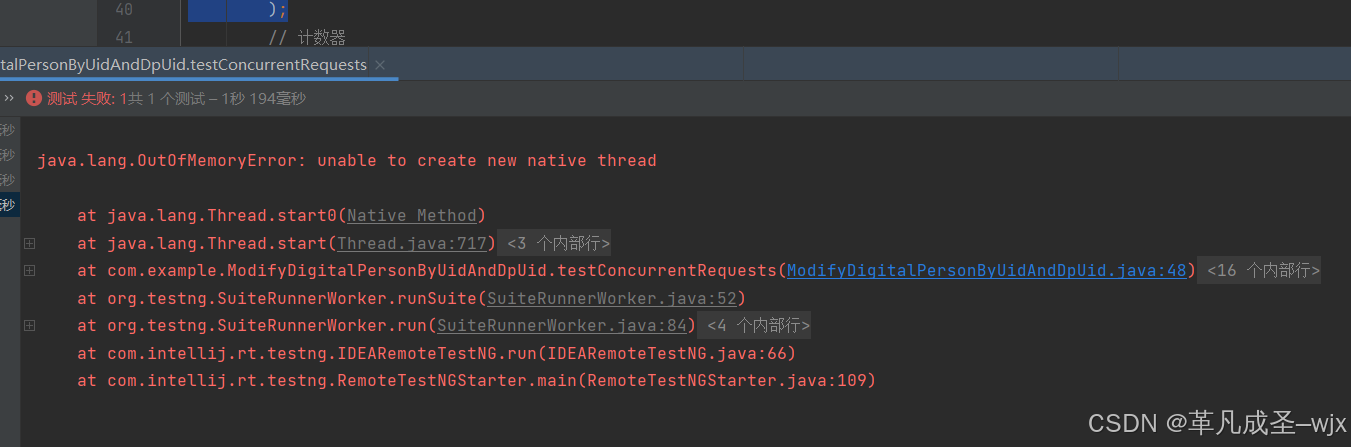
原因一:在不断产生线程的时候,有可能会抛出:java.lang.OutOfMemoryError: unable to create new native thread,操作系统限制线程数量,无法创建更多线程。
原因二:在不断生产线程的时候,有可能出现一些JVM堆内存被占满的情况,例如:
java.lang.OutOfMemoryError: Java heap space
原因三:没有对阻塞队列的长度进行限制,阻塞队列的默认最大长度是Integer.MAX_VALUE,这也就意味着在不断申请内存的时候,极有可能导致内存不够使用的风险。
java.lang.OutOfMemoryError: unable to create new native thread和java.lang.OutOfMemoryError: Java heap space哪一个异常先出现
unable to create new native thread 会先出现。
原因:线程数量限制:
操作系统对每个进程的线程数量有严格限制(通常为几千个),而 JVM 的堆内存限制通常较大(几百 MB 到几十 GB)。因此,线程数量耗尽的速度通常比堆内存耗尽更快。
java.lang.OutOfMemoryError: unable to create new native thread。是因为堆内存当中放不下这么多线程对象吗?
java.lang.OutOfMemoryError: unable to create new native thread并不是因为堆内存中放不下线程对象,而是因为 操作系统无法分配更多的资源来创建新的本地线程。主要原因包括操作系统的线程数限制、栈内存耗尽和进程资源限制。通过增加操作系统的线程数限制、减少线程栈大小、优化线程使用和增加系统内存,可以有效解决此问题。
如果限制了阻塞队列的长度,就一定不会出现内存泄露的风险吗?
不一定,因为线程池是先不断产生线程,如果达到了核心最大线程数量,再把任务存到阻塞队列当中。所以在产生线程的时候,就有可能发生内存泄漏的风险。
比如下面的线程池配置,就发生了内存泄露:
ExecutorService executorService = new ThreadPoolExecutor(
//corePoolSize
3000,
//maximumPoolSize
3000,
60L, TimeUnit.SECONDS,
new ArrayBlockingQueue<>(250)
);
怎样解决上述两个异常?
方案一:解决
unable to create new native thread通过 JVM 参数
-Xss减小线程栈大小(如-Xss256k),但需确保栈空间足够。方案二: 解决
Java heap space增加堆内存,通过 JVM 参数
-Xmx增加最大堆内存(如-Xmx4g)。方案三:分布式压测:建立数据中心分发数据,各个节点处理数据。确保各个节点的线程大小,内存空间足够使用。
在上述代码当中,有没有考虑接口请求超时的情况?(选)
有的,对于RestTemplate采用了设置请求超时的参数来进行,下面是修改过后的完整代码:
package com.example;
import io.qameta.allure.Allure;
import org.apache.http.client.config.RequestConfig;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.http.ResponseEntity;
import org.springframework.http.client.HttpComponentsClientHttpRequestFactory;
import org.springframework.web.client.RestTemplate;
import org.testng.annotations.Test;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.*;
import java.util.concurrent.atomic.AtomicInteger;
@SpringBootTest
public class ModifyDigitalPersonByUidAndDpUidTest {
private static final int NUM_DIGITAL_HUMANS_PER_USER = 5;
private static final int USER_COUNT = 1000; // 并发线程数
AtomicInteger successCount = new AtomicInteger(0); // 成功请求计数器
AtomicInteger failureCount = new AtomicInteger(0); // 失败请求计数器
RestTemplate restTemplate=restTemplateWithTimeout();
@Test
public void testModify() throws Exception {
ExecutorService executorService = Executors.newFixedThreadPool(USER_COUNT);
// 读取CSV文件,按用户分组
List<String[]> userTasks = readCsvFile();
//输出5000,代表5000个数字人
System.out.println(userTasks.size());
//并发1000个用户
for (int i = 0; i < userTasks.size(); i += 5) {
int finalI = i;
executorService.submit(() -> {
//每一次切换其他用户之前都重建HTTP请求
for (int j = 0; j < NUM_DIGITAL_HUMANS_PER_USER; j++) {
String[] params = userTasks.get(finalI + j);
int userId = Integer.parseInt(params[0]);
int dpId = Integer.parseInt(params[1]);
int gender = Integer.parseInt(params[2]);
try {
String url = String.format("http://127.0.0.1:8083" +
"/digitalPerson" +
"/modifyDigitalPersonByUidAndDpUid?" +
"userId=%s&dpUid=%s&gender=%s", userId, dpId, gender);
ResponseEntity<String> response = restTemplate.getForEntity(url, String.class);
// 验证状态码
if (response.getStatusCode().is2xxSuccessful()) {
successCount.incrementAndGet();
} else {
failureCount.incrementAndGet();
Allure.step("请求失败,状态码: " + response.getStatusCodeValue());
}
//线程等待半秒,模拟用户切换数字人的时间
//每一个用户按照顺序提交5个变更数字人的HTTP请求,每一个请求间隔0.5秒
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
failureCount.incrementAndGet();
Allure.step("请求失败的userId:" + params[0]);
Allure.step("请求失败的dpId:" + params[1]);
Allure.step("请求失败的gender:" + params[2]);
Allure.step("请求失败,失败原因: " + e.getMessage());
}
}
});
}
executorService.shutdown();
boolean terminated = executorService.awaitTermination(Long.MAX_VALUE, TimeUnit.MILLISECONDS);
if (!terminated) {
System.out.println("线程池未在指定时间内关闭,仍有任务未完成");
Allure.step("线程池未在指定时间内关闭,仍有任务未完成");
} else {
System.out.println("线程池正常关闭");
Allure.step("线程池正常关闭");
}
System.out.println("成功数量:" + successCount);
System.out.println("失败数量:" + failureCount);
Allure.step("成功数量:" + successCount);
Allure.step("失败数量:" + failureCount);
}
private static List<String[]> readCsvFile() throws Exception {
List<String[]> userTasks = new ArrayList<>();
BufferedReader br = new BufferedReader(new FileReader("src/test/Resource/modifyDigitalPersonByUidAndDpUid.csv"));
String line;
br.readLine(); // 跳过标题行
// 按用户分组读取CSV文件
while ((line = br.readLine()) != null) {
userTasks.add(line.split(","));
}
br.close();
return userTasks;
}
private RestTemplate restTemplateWithTimeout() {
// 超时时间(毫秒)
int timeout = 50000;
RequestConfig config = RequestConfig.custom()
.setConnectTimeout(timeout)
.setConnectionRequestTimeout(timeout)
.setSocketTimeout(timeout)
.build();
CloseableHttpClient client = HttpClients.custom()
.setDefaultRequestConfig(config)
.build();
HttpComponentsClientHttpRequestFactory factory = new HttpComponentsClientHttpRequestFactory(client);
return new RestTemplate(factory);
}
}
在上述代码当中,如果想模拟Jmeter一样,在规定时间内启动所有线程,可以怎样设置
可以使用ScheduledExecutorService来安排每个线程的启动时间,而不是立即启动所有线程。
1. 计算每个线程的启动间隔
首先,你需要计算每个线程的启动间隔时间。假设你希望1000个线程在
RAMP_UP_TIME秒内逐步启动,那么每个线程的启动间隔为RAMP_UP_TIME / USER_COUNT秒。2. 使用
ScheduledExecutorService来逐步启动线程你可以使用
ScheduledExecutorService来安排每个线程的启动时间,而不是立即启动所有线程。
代码实现:
package com.example;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import io.qameta.allure.Allure;
import org.springframework.http.HttpHeaders;
import org.springframework.http.ResponseEntity;
import org.springframework.web.client.RestTemplate;
import org.testng.annotations.Test;
import java.io.BufferedReader;
import java.io.FileReader;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicInteger;
public class ModifyDigitalPersonByUidAndDpUidRangeUpTimeTest {
private static final int NUM_DIGITAL_HUMANS_PER_USER = 5;
private static final int USER_COUNT = 1000; // 并发线程数
private static final int RAMP_UP_TIME = 60; // 设置1000个线程在60秒内逐步启动
AtomicInteger successCount = new AtomicInteger(0); // 成功请求计数器
AtomicInteger failureCount = new AtomicInteger(0); // 失败请求计数器
RestTemplate restTemplate = new RestTemplate();
@Test
public void testModify() throws Exception {
ScheduledExecutorService scheduler = Executors.newScheduledThreadPool(USER_COUNT);
// 读取CSV文件,按用户分组
List<String[]> userTasks = readCsvFile();
//输出5000,代表5000个数字人
System.out.println(userTasks.size());
long delayBetweenTasks = RAMP_UP_TIME * 1000 / USER_COUNT; // 每个任务的启动间隔时间(毫秒)
//并发1000个用户
for (int i = 0; i < userTasks.size(); i += 5) {
int finalI = i;
scheduler.schedule(() -> {
//每一次切换其他用户之前都重建HTTP请求
//每一次切换其他用户之前都重建HTTP请求
for (int j = 0; j < NUM_DIGITAL_HUMANS_PER_USER; j++) {
String[] params = userTasks.get(finalI + j);
int userId = Integer.parseInt(params[0]);
int dpId = Integer.parseInt(params[1]);
int gender = Integer.parseInt(params[2]);
try {
String url = String.format("http://127.0.0.1:8083" +
"/digitalPerson" +
"/modifyDigitalPersonByUidAndDpUid?" +
"userId=%s&dpUid=%s&gender=%s", userId, dpId, gender);
ResponseEntity<String> response = restTemplate.getForEntity(url, String.class);
// 获取响应体
String responseBody = response.getBody();
System.out.println("Response Body: " + responseBody);
// 获取响应头
HttpHeaders headers = response.getHeaders();
System.out.println("Headers: " + headers);
// 获取状态码
int statusCode = response.getStatusCodeValue();
System.out.println("Status Code: " + statusCode);
// 验证状态码
if (response.getStatusCode().is2xxSuccessful()) {
successCount.incrementAndGet();
// 将响应体解析为 JsonNode
ObjectMapper objectMapper = new ObjectMapper();
JsonNode jsonNode = objectMapper.readTree(response.getBody());
// 提取字段
int code = jsonNode.get("code").asInt();
String requestId = jsonNode.get("requestId").asText();
String message=jsonNode.get("message").asText();
System.out.println("Extracted code: " + code);
System.out.println("Extracted requestId: " + requestId);
System.out.println("Extracted message: " + message);
//采用Allure来录制内容
Allure.step("Extracted code: " + code);
Allure.step("Extracted requestId: " + requestId);
Allure.step("Extracted message: " + message);
} else {
failureCount.incrementAndGet();
Allure.step("请求失败,状态码: " + response.getStatusCodeValue());
}
//线程等待半秒,模拟用户切换数字人的时间
//每一个用户按照顺序提交5个变更数字人的HTTP请求,每一个请求间隔0.5秒
Thread.sleep(500);
} catch (Exception e) {
e.printStackTrace();
failureCount.incrementAndGet();
Allure.step("请求失败的userId:" + params[0]);
Allure.step("请求失败的dpId:" + params[1]);
Allure.step("请求失败的gender:" + params[2]);
Allure.step("请求失败,失败原因: " + e.getMessage());
}
}
}, delayBetweenTasks * (i / 5), TimeUnit.MILLISECONDS); // 按顺序安排每个任务的启动时间
}
scheduler.shutdown();
boolean terminated = scheduler.awaitTermination(Long.MAX_VALUE, TimeUnit.MILLISECONDS);
if (!terminated) {
System.out.println("线程池未在指定时间内关闭,仍有任务未完成");
Allure.step("线程池未在指定时间内关闭,仍有任务未完成");
} else {
System.out.println("线程池正常关闭");
Allure.step("线程池正常关闭");
}
System.out.println("成功数量:" + successCount);
System.out.println("失败数量:" + failureCount);
Allure.step("成功数量:" + successCount);
Allure.step("失败数量:" + failureCount);
}
private static List<String[]> readCsvFile() throws Exception {
List<String[]> userTasks = new ArrayList<>();
BufferedReader br = new BufferedReader(new FileReader("src/test/Resource/modifyDigitalPersonByUidAndDpUid.csv"));
String line;
br.readLine(); // 跳过标题行
// 按用户分组读取CSV文件
while ((line = br.readLine()) != null) {
userTasks.add(line.split(","));
}
br.close();
return userTasks;
}
}关键点解释:
RAMP_UP_TIME:设置1000个线程在多少秒内逐步启动。这里设置为60秒。
delayBetweenTasks:计算每个任务的启动间隔时间,单位为毫秒。
scheduler.schedule():使用ScheduledExecutorService来安排每个任务的启动时间,确保线程逐步启动。
delayBetweenTasks * (i / 5):根据任务的索引计算每个任务的启动时间,确保任务按顺序逐步启动。
测试数据:
接口相关:
没有上压力测试的时候:单个接口响应时间:10毫秒以内波动
发送HTTP请求数量:5000
总体响应时间:60秒=60,000毫秒
平均响应时间:60,000毫秒/5000个HTTP请求=12毫秒/个,一个HTTP请求耗时12毫秒
最长响应时间1秒,也就是1000毫秒
超过0.5秒(500毫秒)的占比10%
下游接口报错率:3%~5%(试了5次左右)
QPS(平均每秒处理多少个HTTP请求):5000(个)/60(秒)≈83.33(个/秒)
接口异常分析:
下游接口报错信息:{"code":"503","message":"服务器当前无法处理请求,原因是服务器暂时过载或正在维护。请稍后再试。"} ->服务不可用。
报错原因分析:大模型运行需要大量的复杂算法的运算,过度的算法运算导致cpu利用率/内存使用空间接近100%或者超出对应的比例,因此需要做出限制,避免内存泄漏。
为什么不是500错误:如果是500错误,说明有可能已经出现了内存泄露,这个时候其他线程如果想要再次申请内存空间,就会出现异常或者崩溃,因此有一定的预警机制,避免出现500错误。
还有没有可能有其他的报错:
500报错:下游出现了oom,因为瞬时创建了太多的任务导致oom
操作系统相关:(选)
主机:
cpu核心数量(主机):4
CPU使用情况(主机):原本是20%左右,但是运行的时候在50%左右徘徊。
最大内存使用情况(主机):都是在13GB/15GB之间徘徊。
JVM:
CPU核心数量:8
CPU使用情况(JVM):0%~12.8%之间徘徊
内存的最大使用情况(JVM):
8629760bytes/16842752bytes->12842752bytes/16842752bytes
8百万bytes/16百万bytes->12百万bytes/16百万bytes,整体从1/2左右到2/3左右。
如果需要构造的数据量比较大,例如要测试1万个或者更多的数字人,那么可以怎样操作?
使用虚拟数据或Mock数据
如果不需要真实数据,可以在测试代码中直接使用虚拟数据或Mock数据。
-
示例(Python中使用Faker库):
from faker import Faker fake = Faker() # 生成10000条虚拟数据 mock_data = [{'name': fake.name(), 'age': fake.random_int(18, 65)} for _ in range(10000)]
在做压力测试的时候,如何考虑压测脚本/jmeter运行的稳定性
方案一,参数化设计:(已经实现)
对于接口的参数,可以采用${userId}等方式来参数化,实际的参数来自于csv文件当中导入的数据,避免硬编码。
方案二,加入异常处理机制:(已经实现)
例如在执行接口测试的时候,添加超时处理机制:如超过规定时间没有建立连接/没有收到响应就抛出异常,超时重新请求等等,但是最好的还是超时抛出异常。
方案三,在指定环境环境运行:(已经实现)
压力测试在集成测试环境运行,这个环境的压力承受能力类似于线上环境,而且集成了其他的功能,更加能贴合实际的用户使用场景。
方案四,结合实际情况压测:(已经实现)
例如设置两个HTTP请求之间的间隔时间。例如用户切换数字人的时候,会有至少500毫秒的间隔,如果不考虑这个间隔,也把这个间隔算在并发上面,这样一定会给服务器造成不必要的压力。
方案五,不断增加并发数量:(已经实现)
在测试的时候不断增加线程的数量与HTTP请求的数量,逐步测试系统的性能瓶颈。
例如:
第一组压测数据是100个用户,500个数字人;
第二组压测数据是200个用户,1000个......
逐步测试系统的性能瓶颈。
方案六,合理设置线程启动时间(Ramp-Up时间(秒))
避免一下子启动所有线程引起jmeter的崩溃。
方案七,分布式压测:(暂未实现)
由于压力测试时候需要创建大量的线程来进行,因此不断创建线程可能导致本机出现内存泄漏问题,因此需要考虑分布式压测。
例如:
主节点为数据中心,配置压测所需要的数据(读取csv文件),然后把这些数据通关负载均衡算法分发到各个子节点发送HTTP请求,最后获取运行的汇总报告。
在做压力测试的时候,如何考虑数据库的稳定性?
索引优化(已实现):对于索引读取数据,查询的条件采用覆盖索引的方式。
分库分表(已实现):单表在高并发的场景下可能成为性能的瓶颈,采用水平分库分表的方式来读取。
查询优化(已实现):查询时候尽量通过索引覆盖查询需要的字段,避免使用select*
缓存机制(部分实现):对于热数据,也就是读多写少的数据,采用redis缓存,减少数据库服务器压力。
事务优化(选):尽量使用短事务代替长事务,减小事务的粒度,这样也就减少了其他事务的超时等待时间
数据库性能监控(选):对于数据库采取性能监控,确保数据库的运行的服务cpu不会飙升100%,不会出现内存溢出等等情况。
连接池优化(选):合理设置最大连接数,最小空闲连接数,连接超时时间等等。
这个压测方案,还有没有可以优化的地方(总结性):
方案一:实现用户在不同的ip地址访问,更加模拟真实的业务场景,配置代理客户端;
方案二:采用分布式压测,解决内存泄漏问题:实现思路大概是这样的:配置数据中心(csv文件),然后把HTTP请求发送到不同的ip主机上面,然后获取每一个HTTP请求的响应时间等信息。
方案三:逐步增加压力:
①100个用户,每个用户各自变更1个数字人
②200个用户,每个用户各自变更1个数字人
③400个用户,每个用户各自变更1个数字人
④800个用户,每个用户各自变更1个数字人
⑤1000个用户,每个用户各自变更1个数字人(APP的日活跃用户已经达到上限)
⑥1000个用户,每个用户变更2个数字人......单个用户两个数字人之间间隔0.5秒
⑦1000个用户,每个用户变更4个数字人......没有报错,接口最长延迟为60ms......反复试了好多次都没有报错,也没有过度延长。
⑧1000个用户,每个用户变更8个数字人......出现了报错异常:503...错误率:3%到5%之间......反复试了好多次(极限在(4,8) 都是开区间之间)......接口出现1秒以上的延迟
⑨1000个用户,每个用户变更5个数字人......出现了报错:503,错误率3%到5%之间...接口出现1秒以上的延迟
得出结论:1000个用户,变更5个数字人是极限
方案四(选:考虑到对一个数字人没有办法并发变更):不是测试瞬时压力,而是用户在线峰值(1000人)的持久性,稳定性测试...稳定1小时
Jmeter结构示意图:
测试计划
├─ 线程组:1000用户持续压测
│ ├─ CSV数据文件配置
│ ├─ 循环控制器(控制3个数字人顺序执行)
│ │ ├─ 固定定时器(500ms间隔)
│ │ └─ HTTP请求:变更性别接口
│ ├─ 吞吐量定时器(控制整体循环节奏)
│ └─ 监听器
│ ├─ 聚合报告
│ └─ 活跃线程监控
├─ 配置元件
│ ├─ HTTP请求默认值
│ └─ HTTP头管理器
└─ 定时器(全局)
└─ 常数吞吐量定时器(可选)关键配置步骤
1. 线程组设置
-
线程数(用户数):
1000 -
Ramp-Up时间:
0(立即并发所有用户) -
持续时间:
3600秒(1小时) -
循环次数:
勾选"永远"
2. CSV数据配置
-
文件路径:包含3000行(1000用户×3数字人)
-
变量名:
uid,dpUid,gender -
共享模式:
当前线程组
(确保每个线程独占一组3个数字人)
3. 循环控制器(控制3个数字人)
-
循环次数:
3(每个用户执行3个数字人) -
内部逻辑:
java
复制
// 示例BeanShell代码(动态读取CSV行) int loopCount = ${__iterationNum}; // 1,2,3 vars.put("currentDpUid", vars.get("dpUid_" + loopCount)); vars.put("currentGender", vars.get("gender_" + loopCount));
4. 定时器配置
-
固定定时器:
500ms(数字人间隔) -
常数吞吐量定时器(可选):
若需限制总吞吐量(例如3000请求/分钟),设置:
目标吞吐量:60(请求/秒,即3600/小时)
5. HTTP请求参数
java
复制
{
"uid": "${uid}",
"dp_uid": "${currentDpUid}",
"gender": "${currentGender}"
}
6. 监听器
-
聚合报告:统计TPS、响应时间、错误率
-
活跃线程监控:观察并发用户稳定性
执行逻辑流程图
sequenceDiagram
participant 用户线程
participant JMeter
participant 服务端
用户线程->>JMeter: 启动1000线程
loop 每个用户循环1小时
loop 3个数字人
JMeter->>服务端: 请求1(dpUid_1)
服务端-->>JMeter: 返回status=3
JMeter->>JMeter: 等待500ms
JMeter->>服务端: 请求2(dpUid_2)
服务端-->>JMeter: 返回status=3
end
end预期结果
总请求量:1000用户 × 3数字人 × (3600秒/0.5秒) = 21,600,000次请求
平均吞吐量:6000请求/秒(500ms间隔 × 1000用户)
服务端要求:需至少支持6000 QPS的并发处理能力。
方案五:回调接口的稳定性压测
当上游请求下游接口,堆积任务时候,下游接口回调时候可能导致我们服务的回调接口产生性能问题(例如上游并发3000个HTTP请求,下游AI回调时候也同时并发调用我们服务的回调接口)
风险评估:
上游的接口已经经过了压力测试,发现没有问题,下游的接口也是在我们这边的服务的,所以出现问题的概率比较小,而且回调时候同时并发的概率不大,会有时间间隔
解决风险:
直接构造数据,并发对下游接口进行测试,及时达到了3000HTTP请求的并发也没有问题
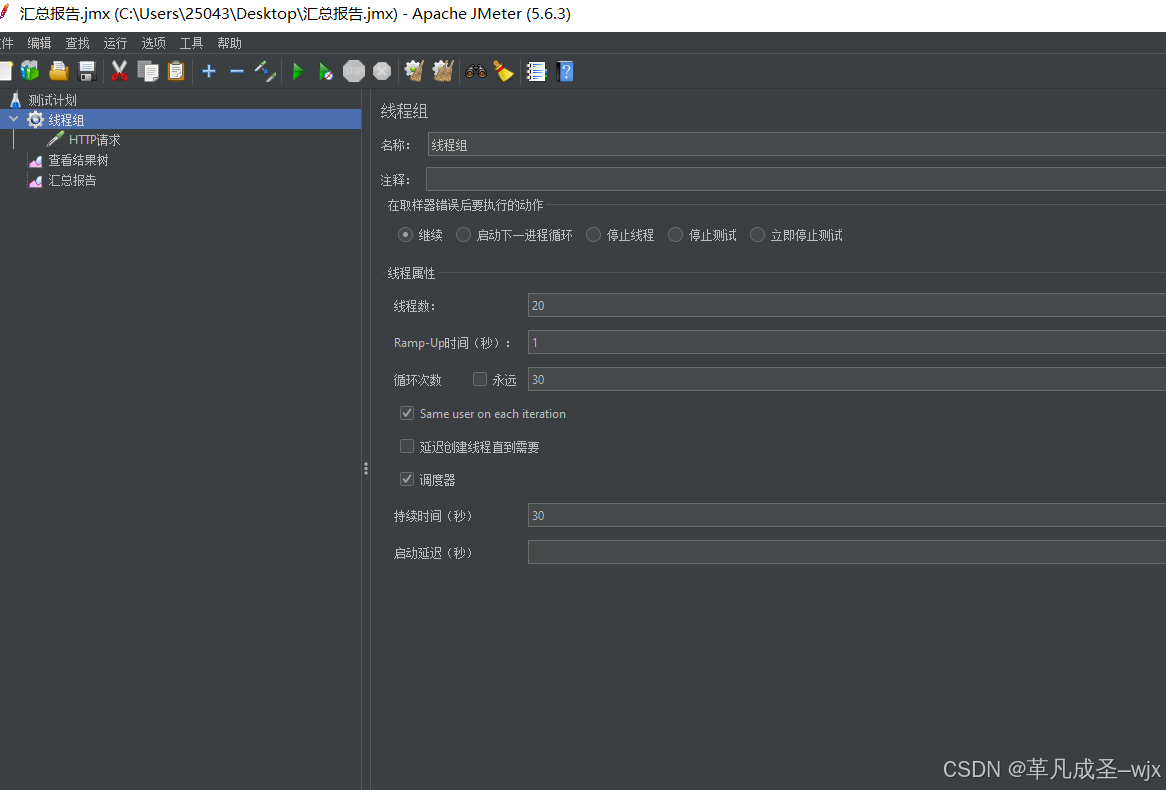
经典面试题:如果想要jmeter进行压测,每秒20个HTTP请求,持续30秒,应该怎样配置
方案一(不到30秒):线程组设置为20,Ramp-Up时间(秒)设置为1,循环次数为30,持续时间为30秒(选),实际上2秒不到就执行完了。
项目结构:
运行结果如下:
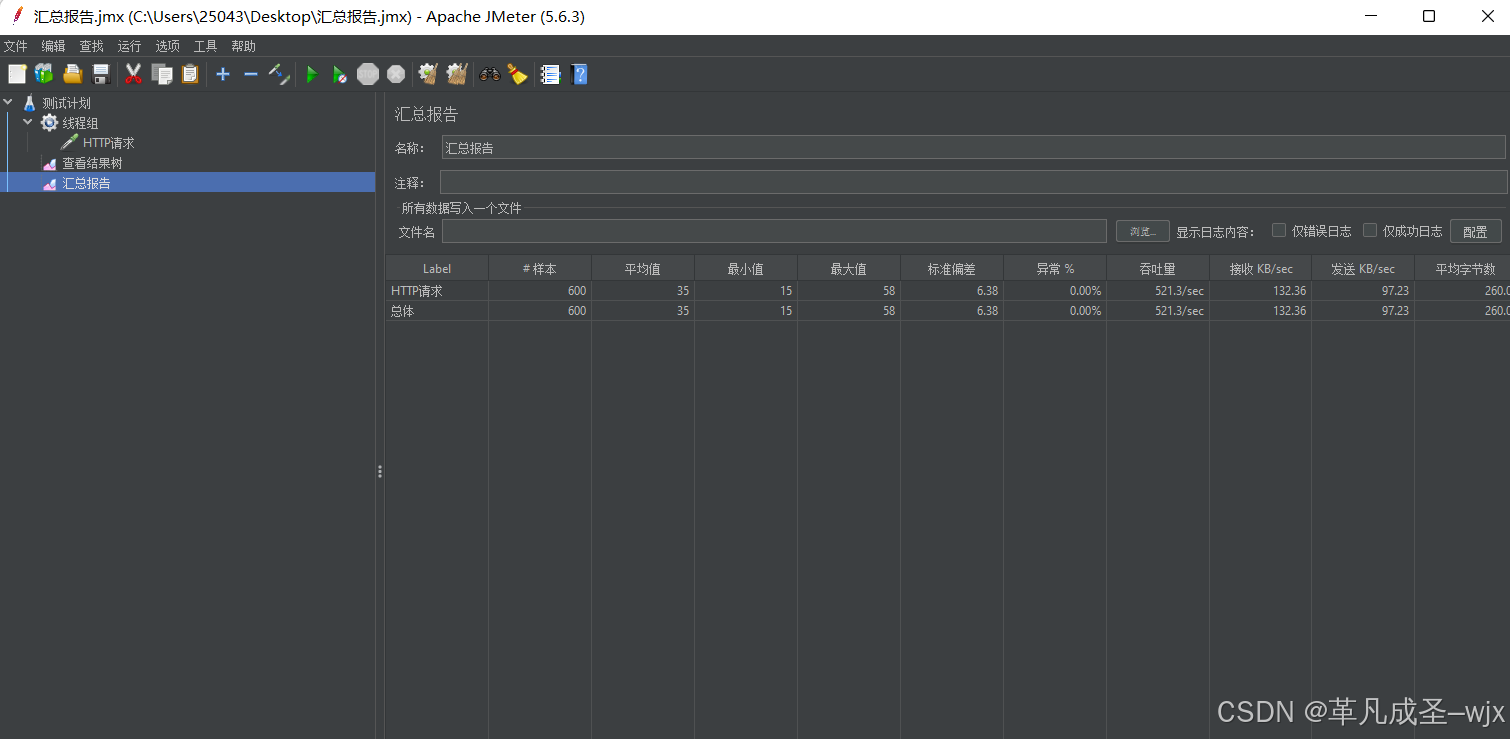
方案一缺点:任务执行过快,可能导致一个线程在一秒内执行不止一次的任务(多次任务)
方案二:达到了30秒,但是线程数量过多
线程组设置为600,Ramp-Up时间(秒)设置为30,循环次数为1,持续时间为30秒(选)。
项目结构:
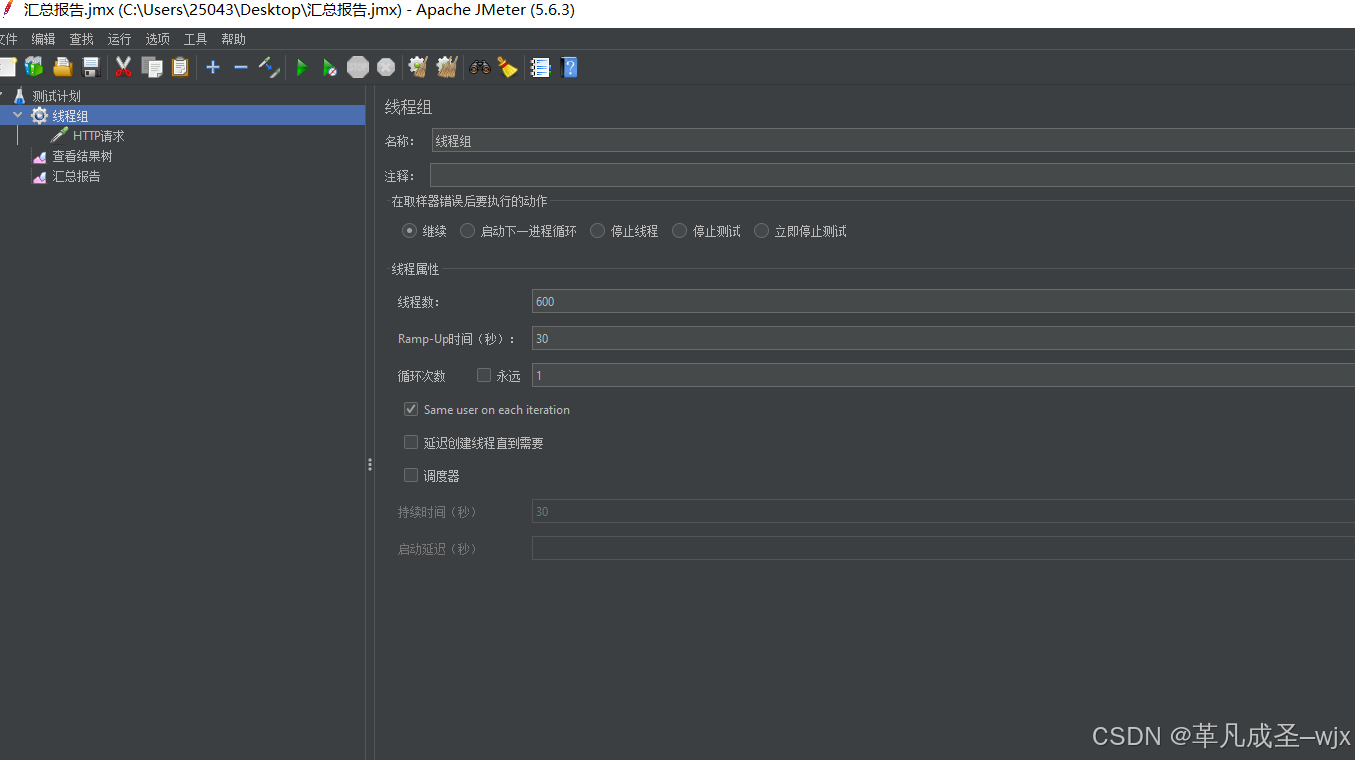
运行截图: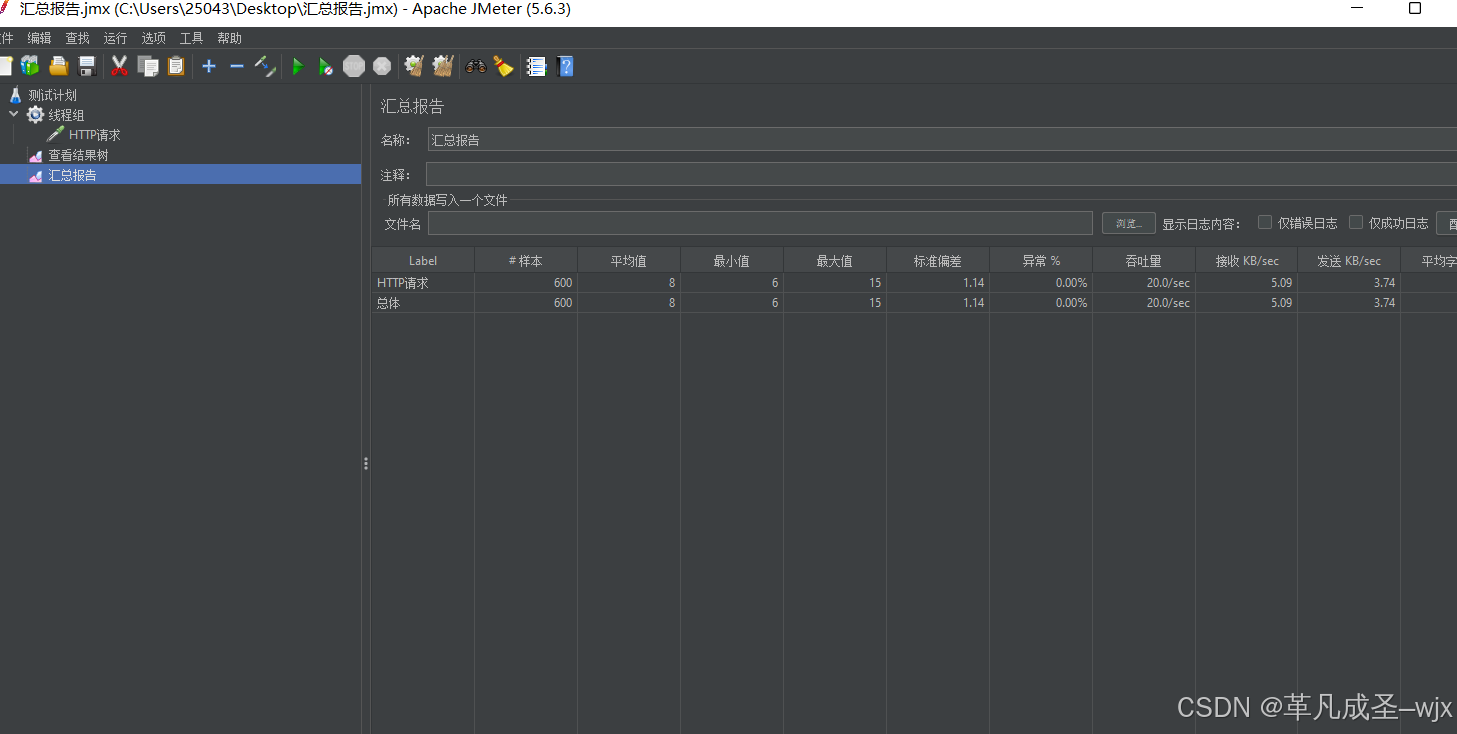
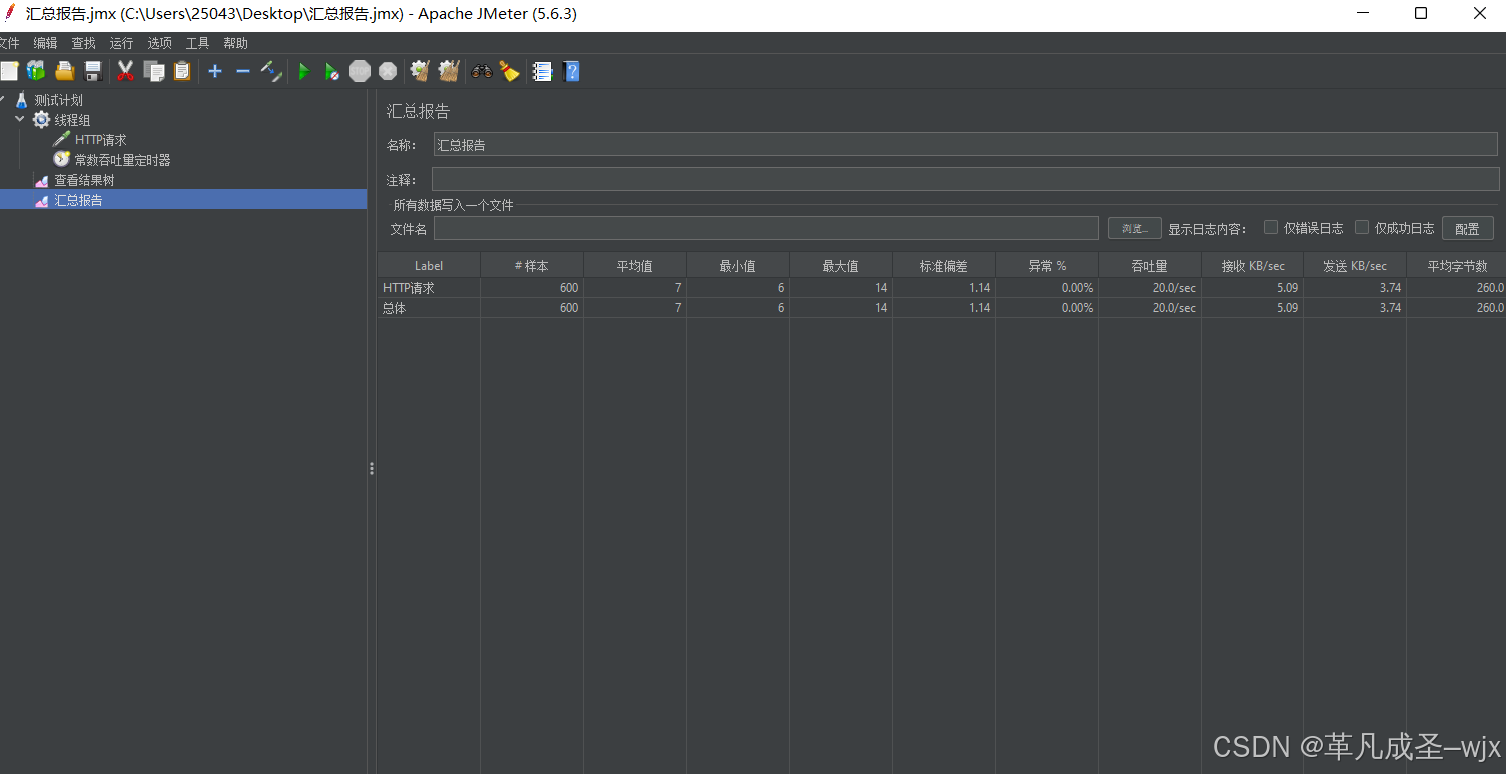
方案三(最优解):
①新建一个线程组,线程组设置为20,Ramp-Up时间(秒)设置为1,调度器的持续时间是30秒;
②线程组同级目录下,新建一个HTTP请求;
③线程组的同级目录下新建一个"常数吞吐量定时器",目标吞吐量(每分钟的样本容量)设置为60。
③的含义:限定每个线程每分钟只有60次的HTTP请求,也就是每秒只有一次的HTTP请求
项目结构:
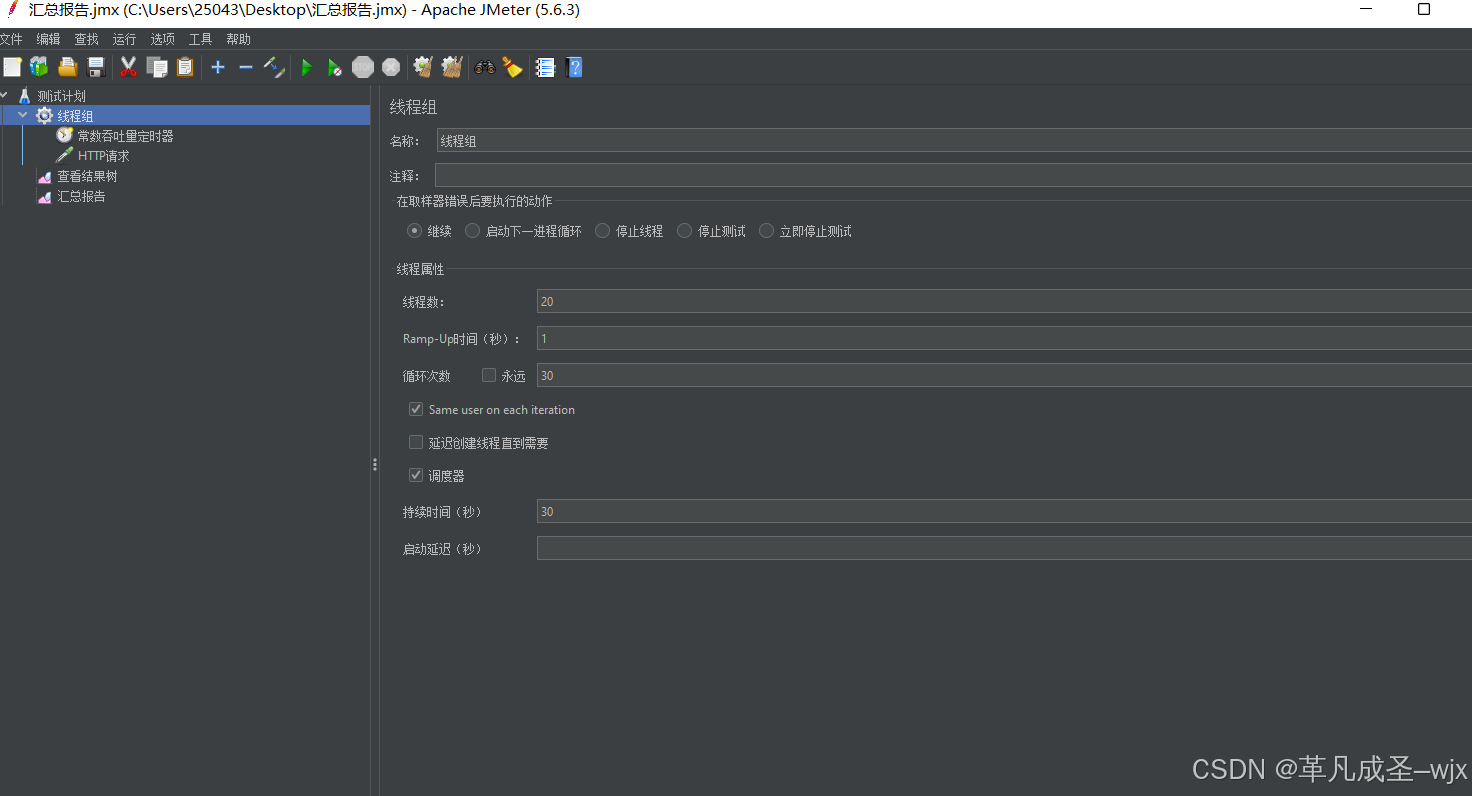
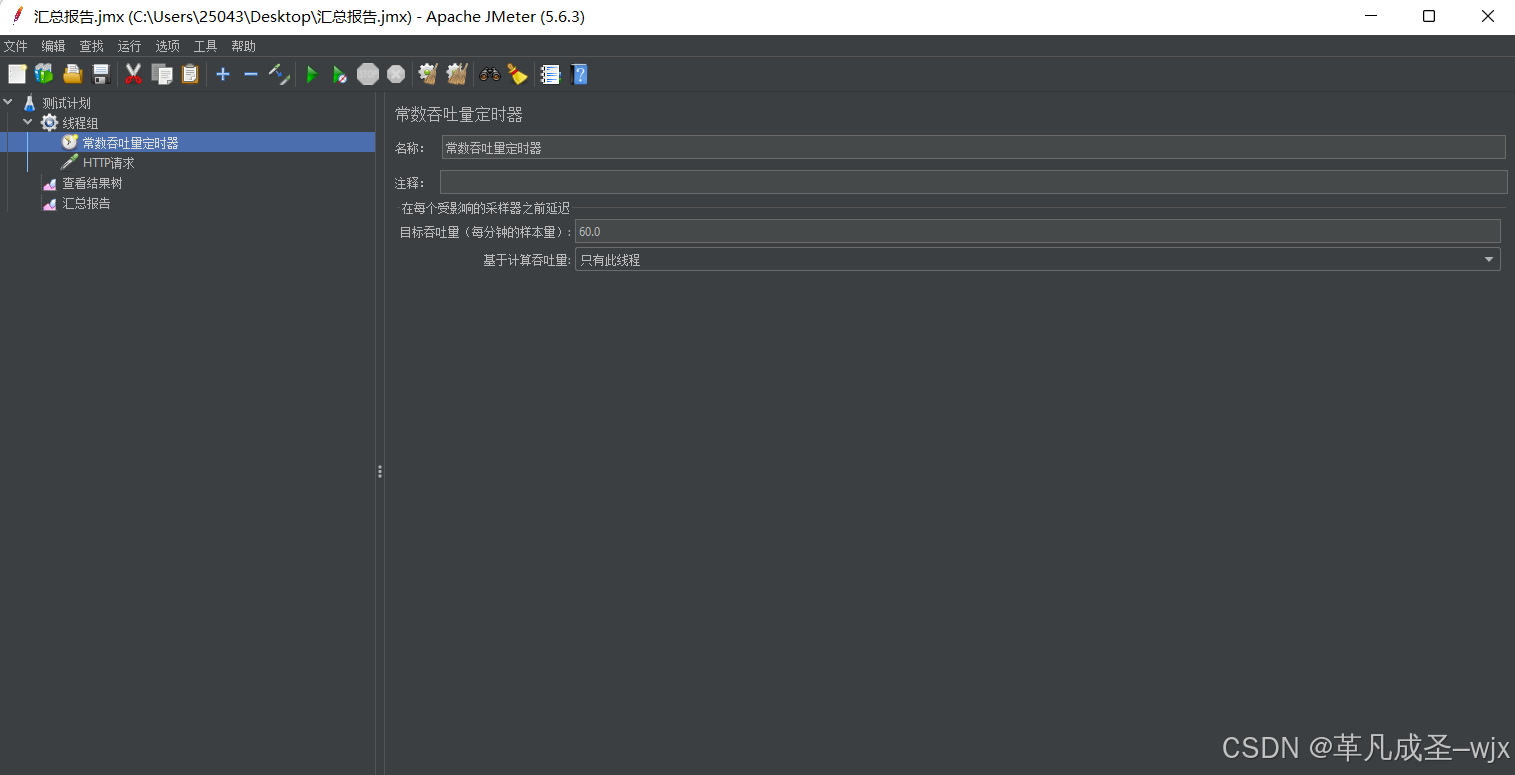
运行截图:可以看出来,线程每秒执行一次的结果下,HTTP请求总量达到了600,平均响应时间是20/seconds
解决风险
为了解决这个风险,我们做了一个限定,当用户尝试变更数字人性别的时候,先查询一下当前这个用户有多少个数字人同时是处于“变更中”这样一个状态,如果>=3个正在变更中的,那么接口就会提示:现在正在制作的数字人数量已经超过3个,等变更成功之后再制作!
不选择5是因为怕达到性能极限,可能触发异常。
(选)
考虑到中午时间可能大量用户会长时间使用这个功能,所以继续降低到一个用户只能同时变更3个
(选)经过如上的方案设计:
还是成功验证得到:一个用户同时变更3个数字人可以持续1小时稳定运行
还有其他解决这个问题的办法吗?
使用Redis进行限流:通过IP地址和URI拼接作为唯一标识,统计用户访问接口的次数。当访问次数超过设定的阈值(如200次)时,拒绝后续请求。可以使用Lua脚本在Redis中实现高效的限流逻辑。
设置全局访问限制:在服务器端设置请求速率限制,例如每秒钟最多允许200次请求。对于超过限制的请求,直接拒绝访问。
使用代理服务器:在服务器前面加一个代理服务器,对请求进行计数。当在一个定时周期内请求数超过最大次数(如1000次),关闭在此之后的所有连接。下一个定时周期开始时,清空计数,重新开始计数。
配置TCP服务端参数:设置TCP服务端的最大连接数参数,当排队连接的客户端个数超过最大值时,拒绝新的连接请求。
下游大模型采用分布式策略:大模型从单机改为分布式,提高并访问量
Q6:数字人的status变更的时期从联调前变为联调后
存在问题分析:
我们的主流程大致是这样的:上游接口接受参数uid,dp_uid,gender;
然后完成基本的参数验证顺序,在请求下游大模型的ip地址之前,就把status变更为3.
但是这样就会有一个问题,如果先修改status为3,但是下游服务如果没有正常运行,那么这个时候就会出现一个Bug:数字人明明没有处于变更状态,但是也会显示"变更中"。
解决bug:先联调,然后修改status
因为请求下游的ip得到响应之后,仍然可以继续运行代码,所以先请求了这个下游的服务成功之后,再修改status为3,这样就可以避免了数字人处于“变更中”但是实际上没有发生变更的Bug
Q7:请求的超时"回滚"措施(选)
回滚的场景:
情况1:上游请求下游的时候一直卡顿。
情况2:下游服务回调的时候一直卡顿,或者回调请求的时候出现异常状态码。
在HTTP请求中,一旦请求发出,通常无法直接“撤回”或“取消”已经发出的请求。
这也就意味着,如果上游请求下游超时,或者下游回调的时候超时,那么就会出现响应迟钝并且状态不一致的问题。
但是HTTP协议本身是无状态的,请求一旦发送到服务器,客户端就无法直接干预服务器的处理过程。不过,可以通过以下方式实现类似“撤回”或“取消”请求的效果:
我们这边使用的是同步请求,因此可以通过下面的方式来实现请求的撤回:
回滚措施第一步:当请求出现错误的时候进行回滚
package main
import (
"fmt"
"io/ioutil"
"net/http"
"time"
)
func main() {
// 创建请求
req, err := http.NewRequest("GET", "https://example.com", nil)
if err != nil {
fmt.Println("创建请求失败:", err)
return
}
// 创建客户端,设置超时时间为 5 秒
client := &http.Client{
Timeout: 5 * time.Second,
}
// 发送请求
resp, err := client.Do(req)
if err != nil {
// 捕获超时错误
if err, ok := err.(interface{ Timeout() bool }); ok && err.Timeout() {
fmt.Println("请求超时:", err)
} else {
fmt.Println("请求失败:", err)
}
return
}
defer resp.Body.Close()
// 读取响应
body, err := ioutil.ReadAll(resp.Body)
if err != nil {
fmt.Println("读取响应失败:", err)
return
}
fmt.Println("响应内容:", string(body))
}如果请求在 5 秒内未完成,会输出如下错误:
请求超时: Get "https://example.com": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
回调的执行时机
-
成功回调:
-
当服务器返回响应(如 HTTP 状态码 200)时,
response -> {}部分的代码会被执行。 -
例如,如果服务器返回
{"data": "example"}, 则response的值就是{"data": "example"}。
-
-
失败回调:
-
如果请求过程中发生错误(如网络超时、服务器返回 500 错误等),
error -> {}部分的代码会被执行。 -
例如,如果服务器返回 504 网关超时,
error.getMessage()会包含错误信息。
-
回滚措施第二步:执行回滚任务
由于http请求本身是无状态的,因此没有办法撤销这次请求,也就意味着下游的大模型仍然有可能会继续执行正在变更当中的任务。也就是如果报了504等错误,也有可能正常执行变更任务。
对于这个问题的解决办法如下:
标记任务失败
往task表当中插入一条失败的数据:
task(taskID,uid,dp_uid,status,lastChangeTime):插入的status为4.
修改数字人的status为4:变更失败:
dp(uid,dp_uid,status,fsid):status=4。
调用终止接口,终止本次任务
本次变更任务终止。
总结:
回调失败出现的场景:
场景一:请求下游响应延迟
场景二:下游回调响应延迟/下游调用我方服务时候出现崩溃。
修改措施:
措施一:设置请求超时回滚机制:修改任务状态为失败,修改数字人status=4。
措施二:回调接口先查询数字人以及任务状态,如果为3那么进行修改成功的变更。如果本身已经是4了,那么就不再修改为statu=1的状态。
Q8:数字人变更的效果评估
对于数字人变更的效果,主要对比的地方在于:变更前和变更之后数字人的缩略图的对比区别是什么?是否有明显的区别?
对于这个问题,我也跟研发提出来过,是否需要同时构造大量的的数字人来进行性别的变更,评估大模型的变更效果如何。
后面研发给出的答复是:变更效果的评估主要在于下游大模型的参数,而且后面还会继续完善变更的效果。于是本期需求实现的要求就是变更成功即可。
如果要对这个效果鉴定,应该怎样做:
性别特征分析:
使用计算机视觉库(如OpenCV)检测面部特征
应用性别识别模型验证合成图片的性别表现
检查二次元特征是否保留(如果适用)
图像质量评估:
使用PSNR、SSIM等指标评估图像质量
检查是否存在伪影、扭曲等异常
验证分辨率是否符合要求
Q9: 讲一下测试过程当中的难点
测试过程当中整体的难点
自动化脚本运行的稳定性
方案一,把脚本以代码模块分区运行:(已经实现)
不同的代码模块有不同的自动化case负责。例如:百度网盘有很多业务线,例如主端业务线,网盘B端业务线,网盘海外版业务线,一刻相册业务线等等,每一个业务线都有自己的代码模块,这些代码模块执行自动化测试的时候分开独立运行。
如果需要大规模联调的时候再统一添加到正式集合里面运行。
方案二,参数化设计:(已经实现)
对于接口的参数,可以采用${userId}等方式来参数化,实际的参数来自于上游其他接口的传入数据或者在csv文件当中导入的数据,避免硬编码。
方案三,加入异常处理机制:(已经实现)
例如在执行接口测试的时候,添加超时处理机制:如超过规定时间没有建立连接/没有收到响应就抛出异常,超时重新请求等等,但是最好的还是超时抛出异常。
方案四,脚本定期维护/集成到测试流水线:(已经实现)
在每次研发合并好代码准备上线之前,都会在单机测试环境,集成测试环境运行一次当前代码模块的自动化测试case,查看运行报告,获取运行日志,上线之后再在线上环境运行。
方案五,隔离环境运行:(已经实现)
例如在线下测试的时候,请求的ip+port是线下的。在线上运行的时候,请求的ip是线上的。做到请求除了url以外没有其他的区别。
方案六:定期运行/冒烟测试:(可以实现但是没有实现)
把集成环境的自动化case定期运行一下,例如每天定时运行,获取自动化测试报告等等。
一个接口的case数量比较大的时候,新的case和老的case的兼容性
方案一:完善接口文档,对于接口的主要功能有一个大致描述。
方案二:代码覆盖率查看:借助覆盖率看板,查看一次执行接口测试覆盖了多少代码。
方案三:查看以往测试报告,以往测试报告当中,有没有哪些执行没有通过的断言
方案四:增量模型:新增的case对应新增的代码,有没有覆盖到
方案五:CI/CD流水线集成。把接口case添加到自动化集合当中,并且只要是修改代码,就必须重走流水线,触发自动化测试。
测试AI数字人项目的难点
Jmeter压测脚本的稳定性
方案一,参数化设计:(已经实现)
对于接口的参数,可以采用${userId}等方式来参数化,实际的参数来自于csv文件当中导入的数据,避免硬编码。
方案二,加入异常处理机制:(已经实现)
例如在执行接口测试的时候,添加超时处理机制:如超过规定时间没有建立连接/没有收到响应就抛出异常,超时重新请求等等,但是最好的还是超时抛出异常。
方案三,在指定环境环境运行:(已经实现)
压力测试在集成测试环境运行,这个环境的压力承受能力类似于线上环境,而且集成了其他的功能,更加能贴合实际的用户使用场景。
方案四,结合实际情况压测:(已经实现)
例如设置两个HTTP请求之间的间隔时间。例如用户切换数字人的时候,会有至少500毫秒的间隔,如果不考虑这个间隔,也把这个间隔算在并发上面,这样一定会给服务器造成不必要的压力。
方案五,不断增加并发数量:(已经实现)
在测试的时候不断增加线程的数量与HTTP请求的数量,逐步测试系统的性能瓶颈。
例如:
第一组压测数据是100个用户,500个数字人;
第二组压测数据是200个用户,1000个......
逐步测试系统的性能瓶颈。
方案六,合理设置线程启动时间(Ramp-Up时间(秒))
避免一下子启动所有线程引起jmeter的崩溃。
方案七,分布式压测:(暂未实现)
由于压力测试时候需要创建大量的线程来进行,因此不断创建线程可能导致本机出现内存泄漏问题,因此需要考虑分布式压测。
例如:
主节点为数据中心,配置压测所需要的数据(读取csv文件),然后把这些数据通关负载均衡算法分发到各个子节点发送HTTP请求,最后获取运行的汇总报告。
第三方接口的稳定性
方案一:编写监控脚本,及时处理规定时间内没有变更性别成功的数字人。
方案二:采用限流措施,如限制单个用户变更数字人的数量,限制下游TCP连接的最大数量。
方案三(选/未实现):搭建mockserver,在集成测试环境使用mockserver代替第三方接口。
Q10:讲一下这个测试平台的主要原理
数据库设计
代码块(code)表
我们部署测试环境的时候,一般都是以代码块为单位进行部署,每一个代码块可以单独启动。
| codeId | url | codeName | link |
| 主键 | 访问这个代码块的相对路径 | 代码块的名称 | 点击链接,可以查看代码模块下面的case |
接口(collection)表
| collectionId | collectionName | collectionURL | codeId | method |
| 主键 | 接口命名 | 访问这个接口的相对路径 | 外键,关联code的codeId | 方法 |
接口的若干case(case)表
| caseId | collectionId | caseName | beforeStep | afterStep | stepId |
| 主键 | 接口的主键Id,关联collection | 这个case的名称 | 前置的脚本:可以是一些js代码,或者数据库操作 | 后置的脚本,可以是一些js代码或者数据库操作 | 如果这些前置脚本或者后置脚本需要请求其他的Ip,可以在这里填写 |
redis表
key:caseId
value:哈希类型
paramA1,A2...:param<K,V>...arg:参数列表:K是请求参数名称,V是请求参数的值
headerB1,B2...:header<K,V>...arg:请求头列表:K是请求头名称,V是请求头参数的值
AssertC1,C2...:assert<K,V>...arg:断言列表:K是 断言的名称,V是断言的值
测试框架设计
单个接口执行测试
对于某一个接口,可以通过pyrequest发送接口测试的http请求,并且获取响应response。
可以通过pymysql来运行。
批量接口执行自动化测试(未完待续)
通过点击junit执行的按钮,来一次执行全部的测试用例,获取代码覆盖率报告,接口执行报告,断言是否通过。可以选择告警通知对象。

















 2174
2174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









