






一:循环神经网络(RNN)
对隐状态使用循环计算的神经网络称为循环神经网络。
当前时间步隐藏变量计算公式如下:
输出层的输出计算公式如下:
注意,即使在不同的时间步,循环神经网络也总是使用这些模型参数。 因此,循环神经网络的参数开销不会随着时间步的增加而增加。
RNN的模型如下:
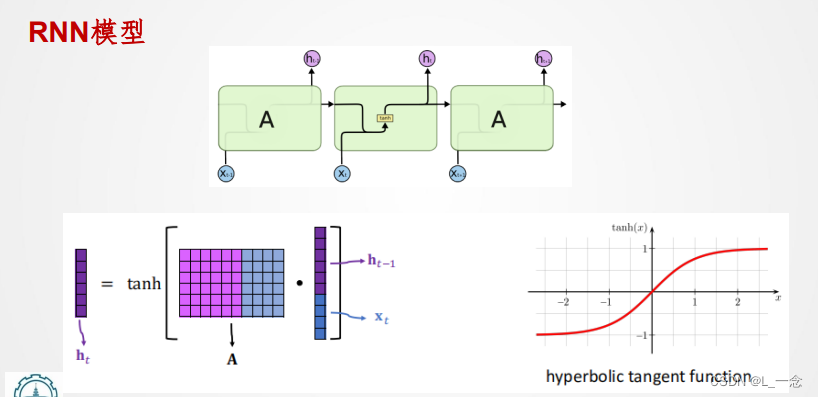
RNN代码实现:
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 构建具有256个隐藏单元的单隐藏层RNN
num_hiddens = 256
rnn_layer = nn.RNN(len(vocab), num_hiddens)
class RNNModel(nn.Module):
"""循环神经网络模型"""
def __init__(self, rnn_layer, vocab_size, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1
if not self.rnn.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens, self.vocab_size)
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)
def forward(self, inputs, state):
X = F.one_hot(inputs.T.long(), self.vocab_size)
X = X.to(torch.float32)
Y, state = self.rnn(X, state)
# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)
# 它的输出形状是(时间步数*批量大小,词表大小)。
output = self.linear(Y.reshape((-1, Y.shape[-1])))
return output, state
def begin_state(self, device, batch_size=1):
if not isinstance(self.rnn, nn.LSTM):
# nn.GRU以张量作为隐状态
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens),
device=device)
else:
# nn.LSTM以元组作为隐状态
return (torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device),
torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device))
device = d2l.try_gpu()
net = RNNModel(rnn_layer, vocab_size=len(vocab))
net = net.to(device)
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)二:门控循环单元(GRU)
门控循环单元有专门的机制来确定应该何时更新隐状态, 以及应该何时重置隐状态。例如某一个词元的影响至关重要,加入GRU可以在不给该词元指定一个非常大的梯度的情况下存储重要的信息。或者,加入GRU还可以跳过某些词元。
GRU的结构如下: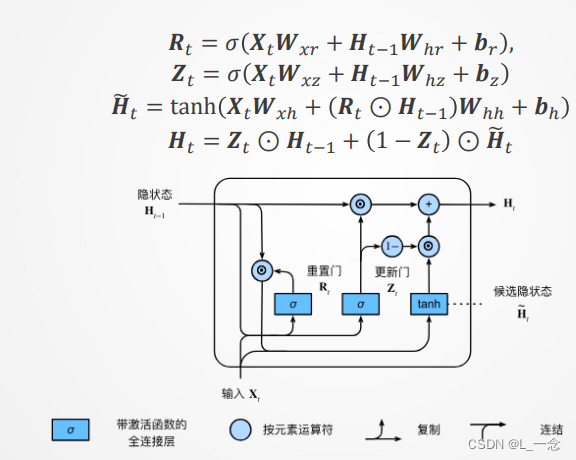
代码实现GRU模型:
gru_layer = nn.GRU(num_inputs, num_hiddens)三:长短期记忆网络(LSTM)
长短期记忆网络引入了记忆元。记忆元的目的是用于记录附加的信息。,为了控制记忆元,我们需要许多门。
如图所示为LSTM中包含的输入门,遗忘门和输出门,他们都通过sigmoid激活函数处理,所以这三个门的值都在(0,1)之间。
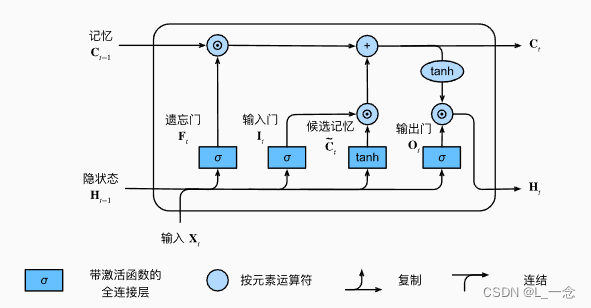
计算公式如下:
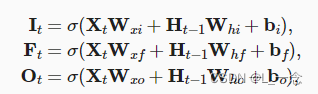
输入门中的it确定传送带的哪些值被更新,更新之后的新值
加到
上,然后更新传送带。
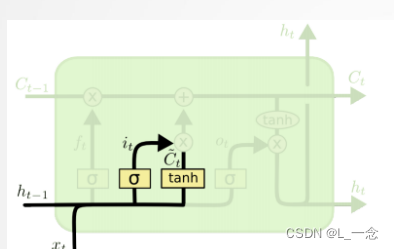
从网络结构来看,LSTM的参数量是RNN的四倍,输入和输出都与RNN相同。
LSTM的代码实现:
lstm_layer = nn.LSTM(num_inputs, num_hiddens)四:生成式对抗网络(GAN)
生成式对抗网络由两个神经网络组成,即生成器和判别器。生成器的作用是估计真实样本的概率分布,以便提供与真实数据相似的生成样本。判别器被训练来估计一个给定样本来自真实数据而不是由生成器提供的概率。生成器和鉴别器被训练成相互竞争的状态:生成器试图更好地欺骗鉴别器,而鉴别器则试图更好地识别生成的样本。
GAN的网络架构:
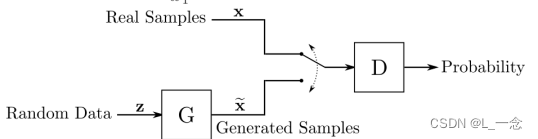
生成器 G的 输入为隐空间的随机数据,它的作用是生成类似于真实样本的数据。可以使用各种的深度学习网络来架构生成器G。鉴别器D接收来自训练数据集的真实样本或G提供的生成样本,其作用是估计 输入属于真实数据集的概率。输入来自真实样本时输出1,来自生成样本时 输出0。也可以使用各种神经网络来构建鉴别器D。
五:Transformer
Transformer模型完全基于注意力机制,没有任何卷积层或循环神经网络层。
Transformer模型架构:
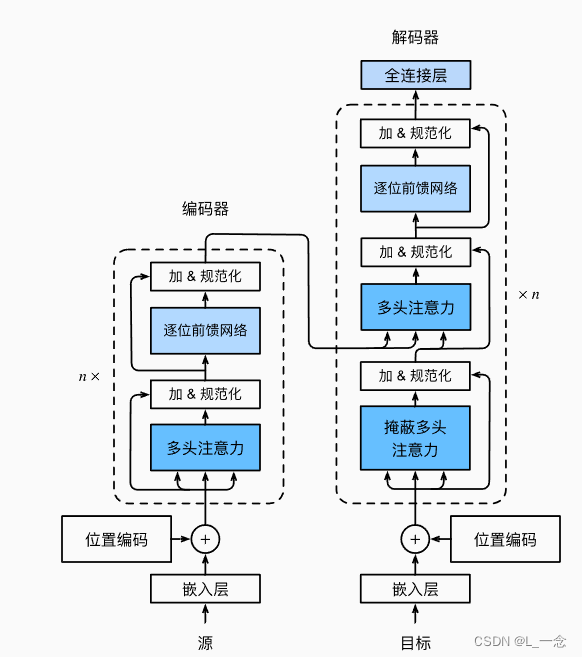
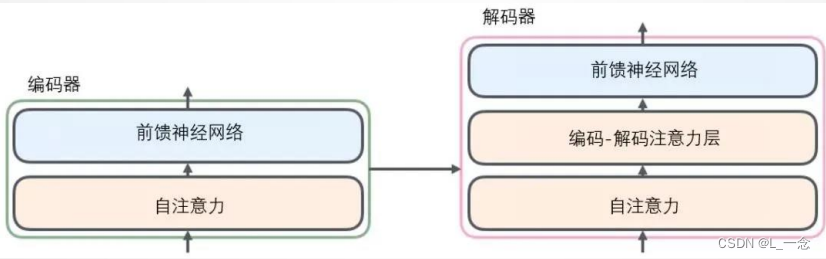
Transformer是由编码器和解码器组成的,编码器和解码器是基于自注意力的模块叠加而成的。编码器是由多个相同的层叠加而成的,每个层都有两个子层,包括多头自注意力汇聚和基于位置的前馈网络。解码器也是由多个相同的层叠加而成的,并且层中使用了残差连接和层规范化,解码器除了有编码器中的两个层之外,还有第三个子层,称为编码器-解码器注意力层,在编码器-解码器注意力中,查询来自前一个解码器层的输出,如图所示:
计算注意力机制:
1.从每个编码器的输入向量中生成三个向量。一个查询向量Q、一个键向量K和一个值向量V。
2.计算得分,这些得分决定了在编码单词的过程中有多重视句子的其它部分。
3.将分数除以8,然后通过softmax传递结果,使得到的分数都是正值且和为1。
4.每个值向量乘以softmax分数。
5.对加权值向量求和然后即得到自注意力层在该位置的输出。
所有步骤合并为如下计算公式:
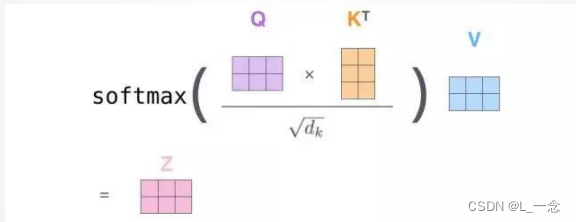
多头注意力机制扩展了模型专注于不同位置的能力,并且给出了注意力层的多个“表示子空间”。计算多头注意力机制时需要八次不同的权重矩阵运算,得到8个不同的Z矩阵。
多头注意力机制代码实现:
import math
import torch
from torch import nn
class MultiHeadAttention(nn.Module):
"""多头注意力"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# queries,keys,values的形状:
# (batch_size,查询或者“键-值”对的个数,num_hiddens)
# valid_lens 的形状:
# (batch_size,)或(batch_size,查询的个数)
# 经过变换后,输出的queries,keys,values 的形状:
# (batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
# 在轴0,将第一项(标量或者矢量)复制num_heads次,
# 然后如此复制第二项,然后诸如此类。
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# output的形状:(batch_size*num_heads,查询的个数,
# num_hiddens/num_heads)
output = self.attention(queries, keys, values, valid_lens)
# output_concat的形状:(batch_size,查询的个数,num_hiddens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
def transpose_qkv(X, num_heads):
"""为了多注意力头的并行计算而变换形状"""
# 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)
# 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,
# num_hiddens/num_heads)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
X = X.permute(0, 2, 1, 3)
# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
return X.reshape(-1, X.shape[2], X.shape[3])
#@save
def transpose_output(X, num_heads):
"""逆转transpose_qkv函数的操作"""
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,
num_hiddens, num_heads, 0.5)
attention.eval()
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









