






一:算法评估
P(精确率)=TP/(TP+FP)
R(召回率)=TP/(TP+FN)
精度=(TP+TN)/(TP+FP+TN+FN)
其中TP为被正确地划分为正例的个数,FP为被错误地划分为正例的个数,FN为被错误地划分为负例的个数,TN为被正确地划分为负例的个数。
均值平均准确率mAP:
对于每一个类别均可确定对应的AP,在多类的检测中,取每个类AP的平均值,即为mAP
二:YOLO
早期的目标检测算法采用滑动窗口的方法,该方法会带来滑动次数太多,计算太慢 以及目标大小不同,每一个滑动位置需要用很多框等问题,经过改进将目标分类检测和定位问题合在一个网络里,称为一步法(YOLO)。
YOLO网络的官方模型结构图: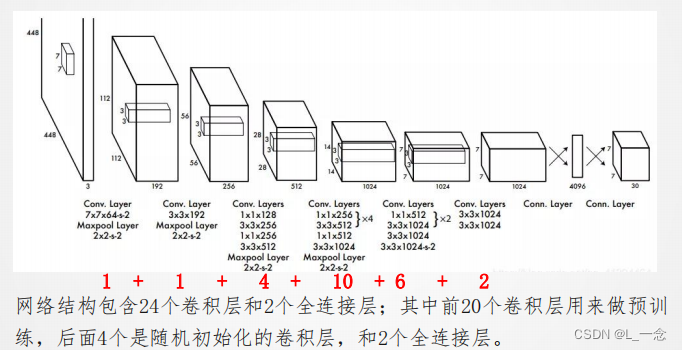
YOLO损失函数:

三:语义分割
与目标检测不同,语义分割找到同一画面中的不同类型目标区域,可以识别并理解图像中每一个像素的内容,语义区域的标注和预测是像素级的。
1.基本操作
转置卷积:假设有一个2*2的输入张量和一个2*2的核张量,计算转置卷积就是将输入张量的每个张量乘以核张量,再将得到的结果相加。如图所示:其中转置卷积的步幅为1.
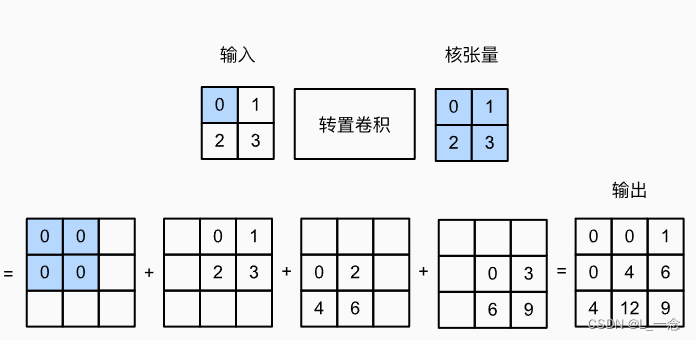
实现上述的转置卷积:
def trans_conv(X, K):
h, w = K.shape
Y = torch.zeros((X.shape[0] + h - 1, X.shape[1] + w - 1))
for i in range(X.shape[0]):
for j in range(X.shape[1]):
Y[i: i + h, j: j + w] += X[i, j] * K
return Y
X = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
K = torch.tensor([[0.0, 1.0], [2.0, 3.0]])
trans_conv(X, K)还可以通过pytorch自带的函数实现:可以设置填充,步幅大小以及是否有偏置。
tconv = nn.ConvTranspose2d(1, 1, kernel_size=2, padding=2, stride=2, bias=False)
tconv.weight.data = K
tconv(X)2.全卷积网络(FCN)
FCN采用卷积神经网络实现了从图像像素到像素类别的变换。
FCN网络模型:卷积部分

反卷积部分:
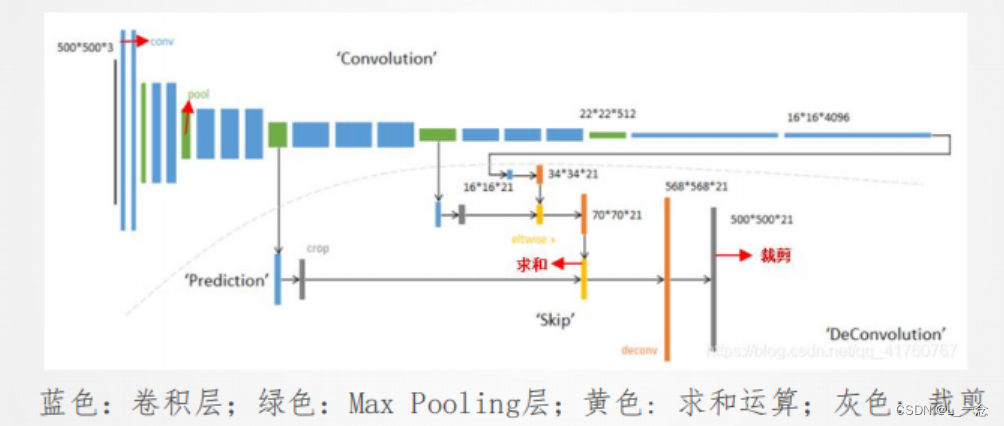
四:风格迁移
风格迁移即为使用卷积神经网络,自动将一个图像中的风格应用在另一图像之上。这里我们需要两张输入图像:一张是内容图像,另一张是风格图像。 我们将使用神经网络修改内容图像,使其在风格上接近风格图像。
步骤:
(1)初始化合成图像
(2)选择一个预训练的卷积神经网络来抽取图像的特征,其中的模型参数在训练中无须更新。
(3)通过前向传播计算风格迁移的损失函数,并通过反向传播迭代模型参数,即不断更新合成图像。
(4)模型训练结束时,输出风格迁移的模型参数,得到最终的合成图像。
内容代价函数
风格代价函数
 、
、
总体代价函数
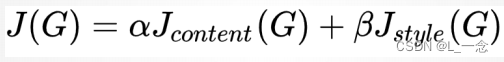















 1807
1807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









