






目录
论文信息
本blog用于记录读论文《Deep Visual-Semantic Alignments for Generating Image Descriptions》的一些理解,如有错误,欢迎指出。
论文地址:https://arxiv.org/abs/1412.2306
论文时间:2015年
论文代码:无
一、前言
本人是在阅读多模态相关任务时阅读到这篇文章的,最初主要想了解其图像与文本这两个模态之间的对齐操作。在阅读完这篇文章后,对其整体的脉络也有了初步的把握。本人才疏学浅,本文不纠结于公式细节(也没有源码),重点在于讲清楚作者做了什么工作。
二、论文工作
作者这篇文章具体做了两个工作:
1.提出一个多模态对齐模型alignment model
2.提出了一个多模态描述生成模型Multimodal Recurrent Neural Network
虽然最初读这篇是奔着他的对齐模型来的,但读完也会好奇论文的整体脉络。论文是先做好第一个多模态对齐模型(第一个工作)后,获得了很多图像的“精细”标注,再将这些“精细“标注用于训练最终的描述生成模型(第二个工作)。
这里的”精细“标注指的不是标注质量高,而是对生成模型来说,我得到的标注由原先的一张图片与一段描述的pair对,变成了一张图片中,多个bounding box与多段文字描述的pair对。
两个模型结合后,最终可以输出单张图片中对多个bounding box的描述(细粒度预测),而输入仅需要图片与描述的pair对(粗粒度标注),因此属于弱监督学习中的”不确切监督“(三种弱监督类型:不完全监督、不确切监督、不精确监督)
三、模型一:多模态对齐模型
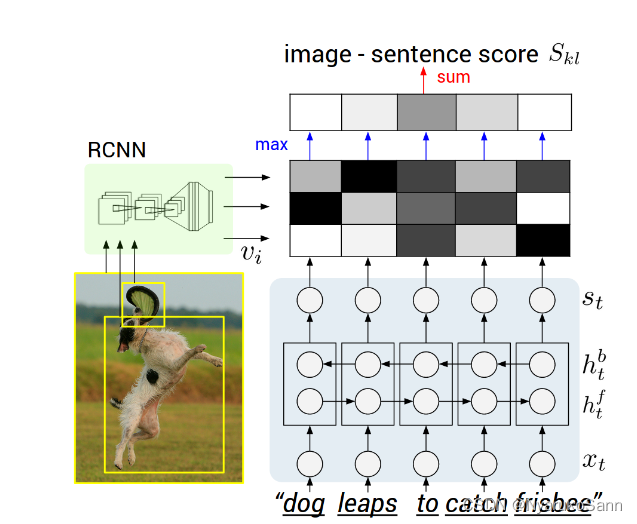
图像模态:通过预训练的RCNN网络检测出N个框(论文中N=20,包括19个检测框与整图),对20个框中的图像通过常规的CNN提取出N个特征。
文本模态:假设图像的描述是长度为L的一段文本,将其进行embeding后,通过双向RNN提取出L个特征。
对齐方式:一个图像文本的pair中,每个文本特征(L个)均与其中检测框的特征(N个)计算相似度(点乘),相似度最高的图像特征作为该文本特征的匹配特征。
具体地,在论文公式中,在一张图像与一段文本
的匹配分数
的计算中,对于文本
中的每一个文本特征
,计算其与图像
中所有区域特征
的相似度,并取最大值。取最大值后将所有文本特征的分数进行累加,得到图像
与文本
的匹配分数
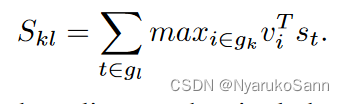
对齐方式论文图片举的例子也比较清楚了,图像模态部分,三个图像区域(包括整图)提取出三个图像特征;文本模态部分,5个word通过BRNN提取特征后与图像特征计算相似度矩阵(颜色越浅代表相似度越高),取出其中相似度最高作为分数,最终求和获得匹配分数。
相似度分数(损失):
在讲损失计算前,先说明比较不容易理解的两个符号含义,当初在读到这里的时候与实验室小伙伴研究了好一会:
:当
时,代表一个batch中选取的图像与文本是匹配的pair ,其匹配分数为
:当
时,代表一个batch中选取的图像与文本是不匹配的pair,其匹配分数为
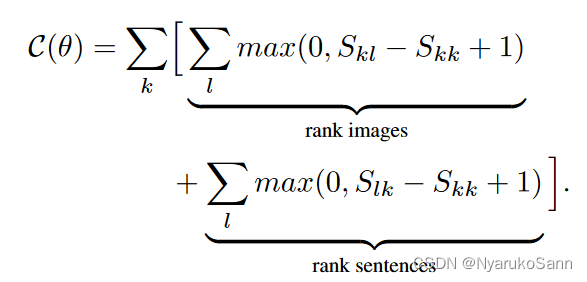
损失的计算采用了边缘损失(margin loss)的方法,如在第一项rank images中,优化目标是要拉高,降低
,使得匹配的图像文本对分数尽可能高,不匹配的图像文本对的分数尽量低。当
时停止优化,可以防止网络的过拟合。
损失函数第二项rank sentence相比rank images,相当于把文本特征与图像特征地位交换了一下,为每个图像特征匹配一个文本特征,相当于在上图的相似度矩阵中按行取max求和计算匹配分数。
这里也是整篇文章的精髓所在,由于图像文本pair的匹配分数、
是由图像中的每个区域与word的相似度分数构成的,因此在损失函数优化图像文本pair整体时,实际上也优化了每个区域与word 的匹配(你要让
大,那你的每个区域与word匹配要尽可能准确才行),通过这种方式,网络能自发地从粗粒度标注中挖掘细粒度的信息。
马尔可夫随机场(MRF):我们希望最终一个图片对应的应该是一段文本,而不是单个孤立的word。因此在推理时,我们会希望相邻的多个word能对应图片中同个区域,而不是使用贪心解码仅取每个word相似度分数最高的区域与其匹配。作者在相似度矩阵中,通过最大化能量函数的方式选取路径,并通过超参控制对连续的单词匹配同一个bounding box的鼓励程度。
由公式可以看出,公式的第一项相当于贪心解码,若能量函数仅包含第一项,最终每个word的匹配将会是其相似度分数最高的区域;公式的第二项引入了额外的控制,当第j个word对应的图像区域与j+1个word对应的图片区域
相同时,即
,每出现一个相同,E(a)值将增大一个
。
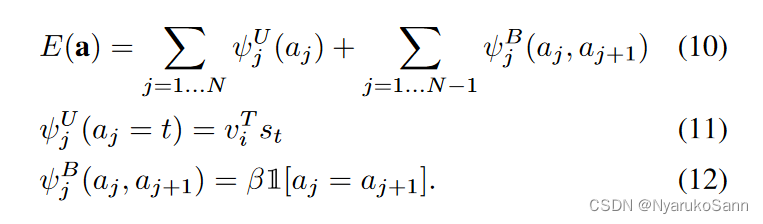
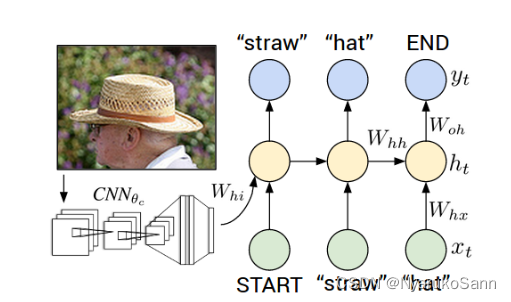
四、模型二:多模态描述生成模型
图像特征:简单的CNN特征提取(后全连接或直接高度压到维度上形成一条向量),图像若是整图则生成全图描述,若是检测框则生成小图的描述。
描述文本生成:采用RNN形式生成文本特征。最开始初始化全0的START向量作为输入x,并以图像特征作为(虽然文章公式与这里有点出入,但实际上就是这么个意思),输入RNN(或LSTM)中,获得零时刻输出
与
。将
经embeding后作为
,与
再一次送入得到
与
。循环直至解码至终止符或预设的最大长度。
训练时,将不以上一时刻输出,
...作为输入
,
...,而是直接使用标注描述作为输入。
五、总结
1.弱监督的方式具有意义,通过模型生成更”精细"的标注,节省人工标注成本,提高了模型性能。
2.通过将图像与文本pair的匹配分数分解为区域与word的相似度,实现了弱监督。
3.对齐方式为简单的点乘计算相似度。
4.生成的“精细”标注不一定具有很高质量,且整个方法本质上算是扩充了数据集(原先一个图片描述pair,生成后N个图像描述pair)。此后的预训练模型(clip)直接从网络中采集海量的图像描述pair(不好说哪个的质量高,但我数量多.jpg)替代了这一步生成。
5.对齐没有进行额外监督,纯让网络自己判断,可能你认为cat应该对齐到图片中的猫,但网络可能把cat对齐到网络中的无意义图像块(取决于数据分布)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









