







简介
bs4(Beautifulsoup)是html的解析器,主要的功能是解析和提取数据。
缺点是:效率不是很高。优点是:接口设计人性化,使用方便。
安装以及创建
1. 安装
pip install bs4
2. 导入
from bs4 import BeautifulSoup
3. 创建对象
服务器响应文件生成对象:
soup = BeautifulSoup(response.read().decode(), 'lxml')
'lxml'是python第三方库,一个解析器,用于解析HTML代码。
本地文件生成对象:
soup = BeautifulSoup(open('1.html'), 'lxml')
注意:默认打开方式的编码格式为gbk,所以需要指定打开编码格式。
节点定位
- 根据签名查找节点
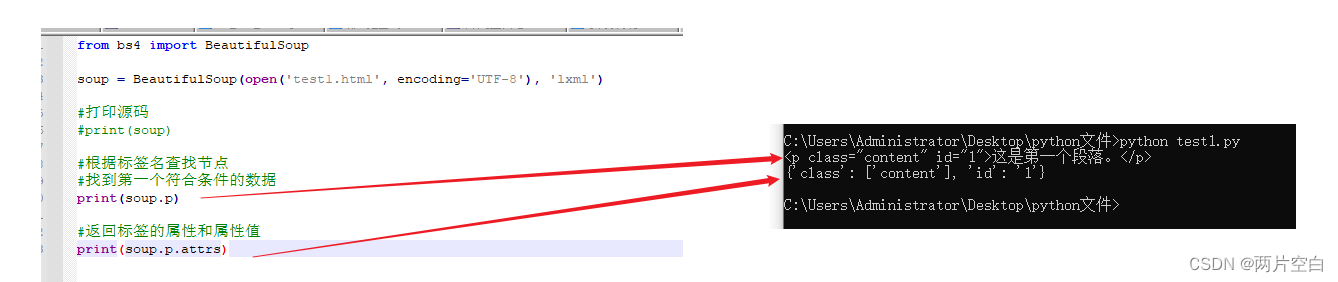
soup.a 只能找到匹配的第一个数据
soup.a.attrs 找到第一个符合标签数据的属性和属性值
- 函数
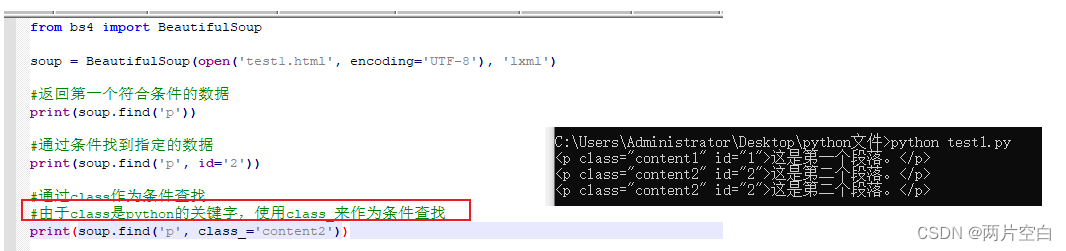
1. find:
2. find_all:

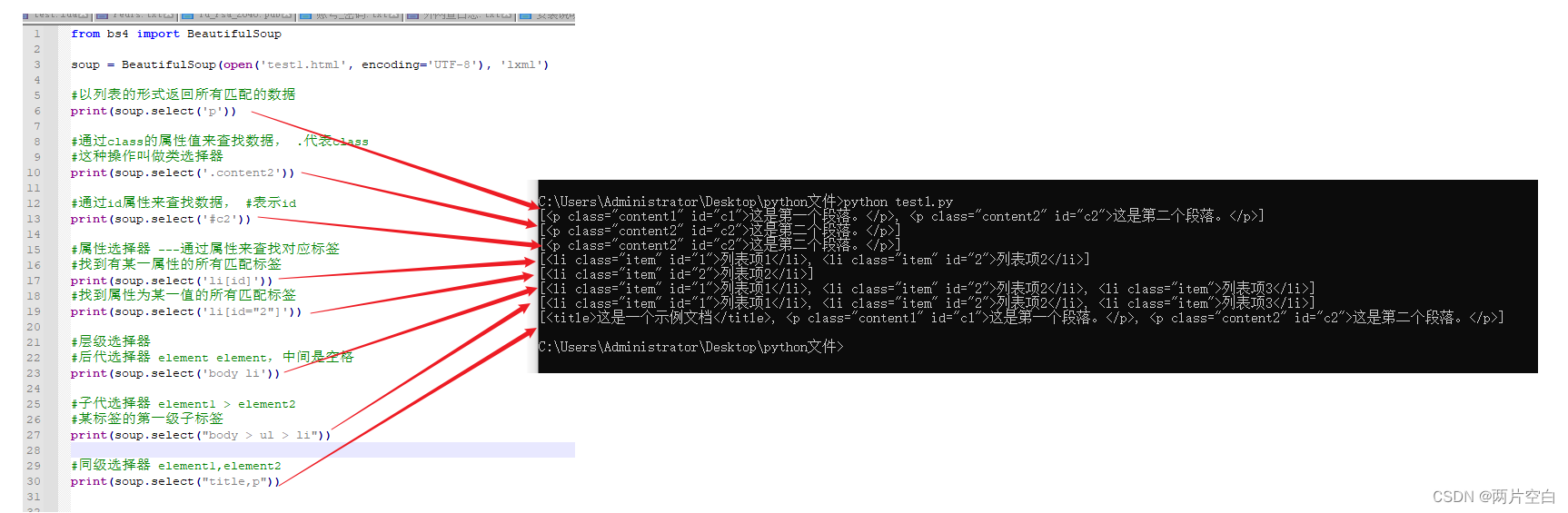
3. select:
节点信息
获取节点内容
obj.string
obj.get_text()

获取节点的属性

爬取星巴克数据
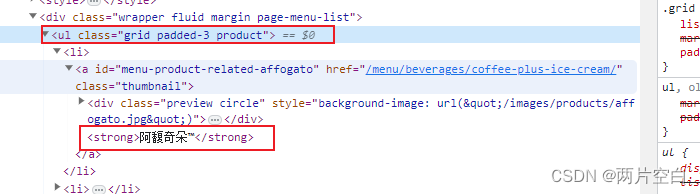
进入星巴克官网/菜单,F12获取到网页链接。查看网页源码,查看菜单数据所在标签。是在属性值为class="grid padded-3 product"的ul标签下的strong标签里。
import requests
#星巴克菜单地址
url = 'https://www.starbucks.com.cn/menu/'
#获得星巴克菜单源码
req = requests.get(url = url)
content = req.text
from bs4 import BeautifulSoup
#解析菜单数据
soup = BeautifulSoup(content, 'lxml')
name_list = soup.select("ul[class=\"grid padded-3 product\"] strong")
for name in name_list:
print(name.get_text())














 2553
2553

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









