







bs4是python的一个第三方库,用来做数据解析的
目录
4.2 查找页面中的第一个符合要求的内容 BeautifulSoup.find()
4.3 查找页面所有符合条件的内容 BeautifulSoup.find_all()
4.4 查找符合选择器的所有内容 BeatuifulSoup.select()
5 获取指定标签的文本内容 text string get_text()
1 安装bs4

顺便把lxml下来了,可以与bs4配合使用

2 解析本地的html文件
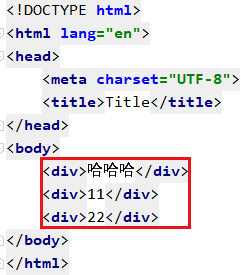
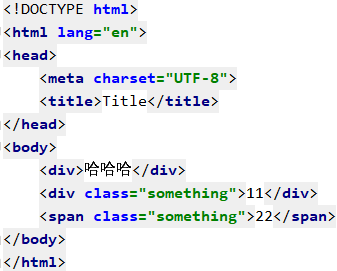
我们先搞一个html文件
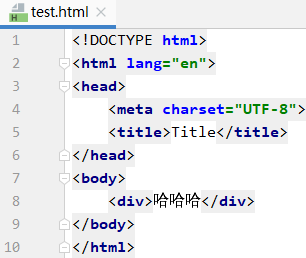
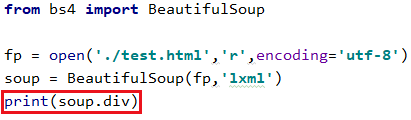
然后用代码解析

可以获取该网页的内容

3 解析网上的html
请求之后就不用存网页了,直接把内容给BeautifulSoup()就行了
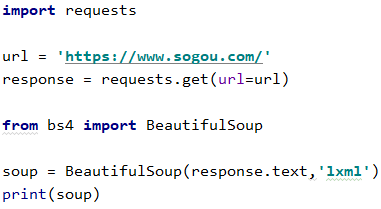

4 找到指定的标签
4.1 获取页面中第一个指定标签的内容
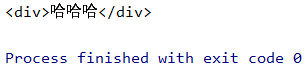
比如我想获取这里的div
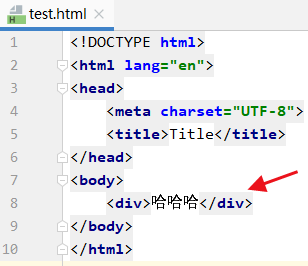
那你就使用soup.div
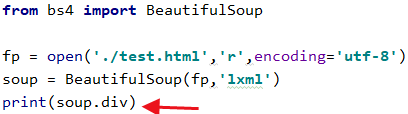
可以得到div的结果
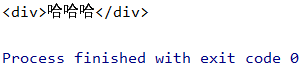
如果有多个div,只会返回第一个div
4.2 查找页面中的第一个符合要求的内容 BeautifulSoup.find()
4.2.1 标签
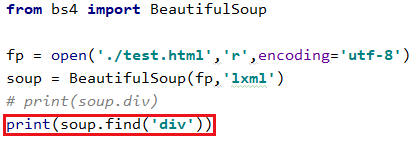
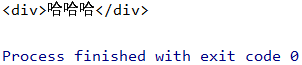
使用soup.find('div'),与soup.div效果相同

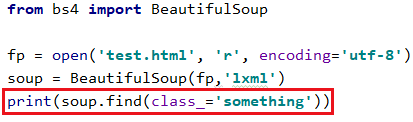
4.2.2 类名

4.2.3 多个条件
比如我想筛选出 span标签与类名something
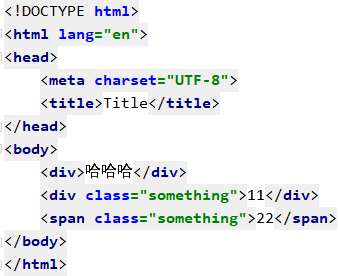
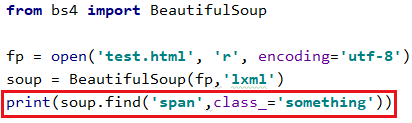

4.2.4 id
id是唯一的,一个页面不会有两个相同id的标签
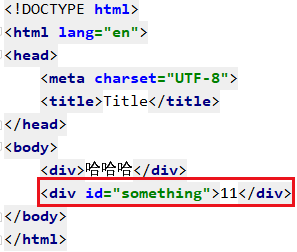
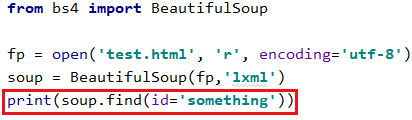
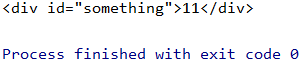
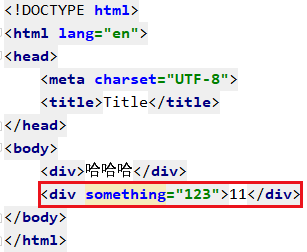
4.2.5 自定义属性


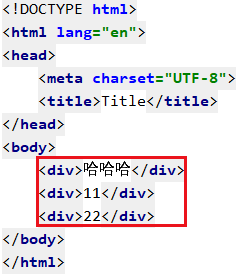
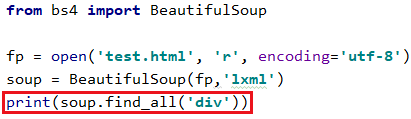
4.3 查找页面所有符合条件的内容 BeautifulSoup.find_all()
与find()的用法相同

4.4 查找符合选择器的所有内容 BeatuifulSoup.select()
选择器可以看一下 CSS3笔记中的基础选择器 2.基础选择器_基础选择器包括_Suyuoa的博客-CSDN博客 与复合选择器 7.复合选择器_Suyuoa的博客-CSDN博客
我们简单做个例子
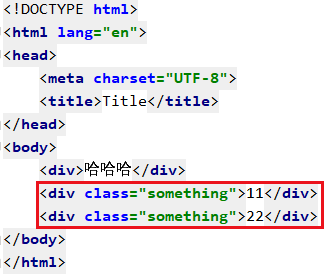
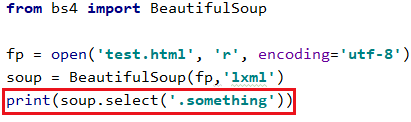

5 获取指定标签的文本内容 text string get_text()
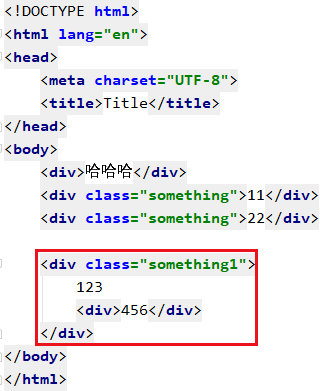
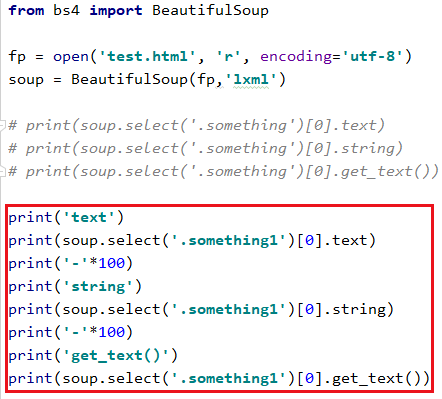
比如我想找 第一个类名为something标签的文本内容
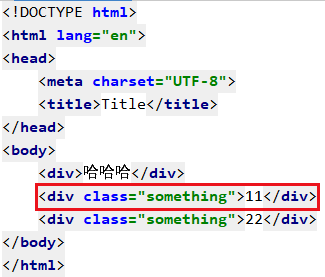
可以使用 text string get_text() 这三个方式功能相似
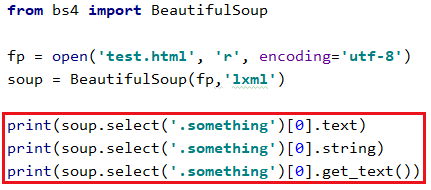

text与get_text()可以获取标签中的所有文本内容,string只能获取标签的直系文本内容(如果在子节点不仅仅包含文本内容就会返回None)

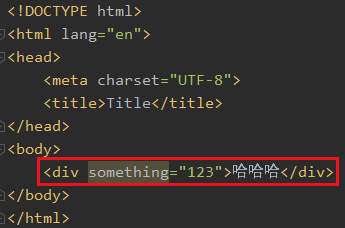
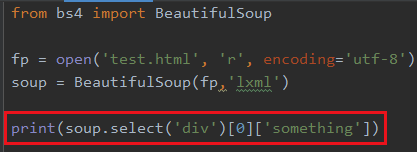
6 获取属性
比如我想获取这里的something属性
找到元素之后直接从索引里拿就行了















 5245
5245











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











