






2024年的夏天,一场突如其来的“微软蓝屏”事件席卷全球,成为了科技领域乃至全球经济的一次重大冲击波。这次事件并非源自传统的黑客攻击或恶意软件传播,而是由于一次软件更新的失误,凸显了全球IT基础设施的脆弱性和对单一技术巨头的过度依赖,同时也敲响了关于系统韧性和网络安全的警钟。
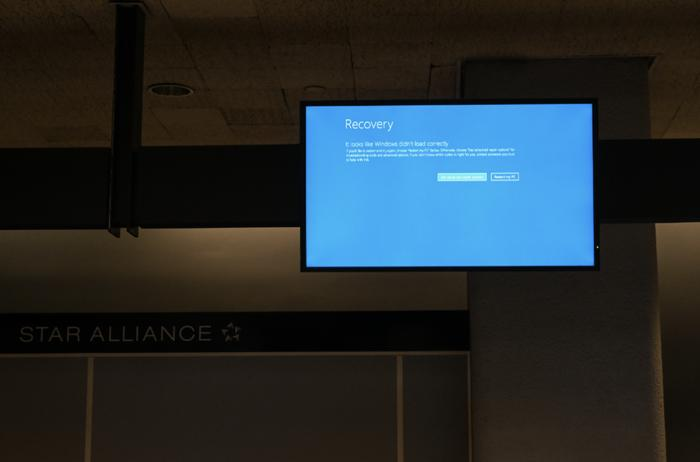
事件起源:CrowdStrike的“缺陷”更新
事件的核心在于美国电脑安全技术公司CrowdStrike所提供的一次软件更新。CrowdStrike作为业界领先的网络安全解决方案提供商,其产品广泛应用于全球范围内的企业和政府机构,旨在抵御各种形式的网络威胁。然而,一次看似常规的软件更新却成为了全球性的灾难源头。
据初步分析,CrowdStrike的更新包中包含了一个未被充分测试的组件,该组件在与微软Windows操作系统的关键服务交互时触发了严重错误,导致系统崩溃并呈现经典的“蓝屏死机”画面。这一看似微小的技术失误,却因CrowdStrike软件的广泛应用和Windows系统的全球普及率,迅速演变为了一场前所未有的IT危机。
CrowdStrike是一家总部位于美国加利福尼亚州的网络安全技术公司,公司的核心产品是Falcon平台,这是一个基于云的网络安全平台,利用人工智能(AI)和机器学习(ML)技术来检测、预防和响应网络威胁。Falcon平台提供了一系列服务,包括威胁搜寻、响应、漏洞管理、反恶意软件保护等,旨在为企业提供全方位的网络安全解决方案。CrowdStrike仅次于全球最大的网络安全公司Palo Alto Networks(派拓网络)。
影响范围:从个人用户到关键基础设施
“微软蓝屏”事件的影响远远超出了单个企业或行业的范畴,它波及到了航空、医疗、金融、零售、物流等众多领域,对全球经济造成了直接和间接的损失。个人用户面临数据丢失、工作延误的问题,而企业则可能遭受业务中断、客户信任度下降等后果。更重要的是,关键基础设施的受影响引发了对国家安全和社会稳定性的担忧。
网络安全与IT韧性:未来的挑战与机遇
此次事件不仅暴露了全球IT基础设施的脆弱性,也促使各界重新审视网络安全和IT韧性的重要性。企业、政府和个人用户都被提醒,需要更加重视软件供应链的安全、加强内部的灾难恢复计划,并投资于更先进的防护技术。
此外,事件还加速了对替代技术和去中心化解决方案的兴趣,如开源软件、国产操作系统和去中心化的网络架构,这些被视为降低对单一技术提供商依赖程度的可能途径。
预防类似事件的实践
严格的软件开发和更新流程:
- 实施全面的代码审查和测试,包括单元测试、集成测试、性能测试和安全性测试。
- 使用持续集成/持续部署(CI/CD)管道,确保每一次更新都在隔离环境中经过严格测试。
- 引入自动化测试工具和框架,覆盖各种边缘案例和异常情况。
分阶段部署:
- 避免一次性大规模推送更新,而是采用逐步部署策略,如灰度发布,先向一小部分用户推送,监控反馈和性能。
- 设定回滚机制,一旦发现异常立即停止更新并恢复到前一版本。
建立应急响应计划:
- 制定详细的应急响应计划,包括事故报告流程、数据恢复策略和业务连续性计划。
- 定期进行应急演练,确保团队能够在紧急情况下迅速行动。
360集团创始人、董事长表示,此次事故给我们敲响了警钟,我们国家的电脑网络安全必须要掌握在自己手里,杀毒软件一定要是国产品牌。
结语
“微软蓝屏”事件是一次警醒,提醒我们数字时代下网络安全与IT韧性建设的紧迫性。它不仅是对现有技术体系的一次考验,更是对未来发展方向的一种指引。随着全球社会日益数字化,构建一个更加安全、韧性和多元的网络空间已成为不可回避的挑战和机遇。各方需共同努力,强化合作,确保信息技术的发展能够惠及所有人,同时有效抵御潜在的风险与威胁。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











