







目录

① Zookeeper 介绍
ZooKeeper 是 Apache 软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册。
ZooKeeper 的架构通过冗余服务实现高可用性。
Zookeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
zookeeper 数据结构
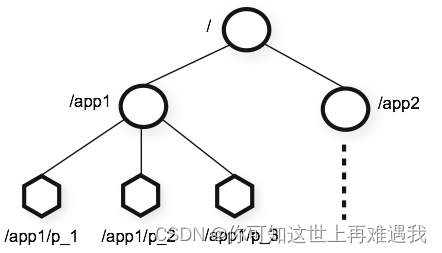
zookeeper 提供的名称空间非常类似于标准文件系统,key-value 的形式存储。名称 key 由斜线 / 分割的一系列路径元素,zookeeper 名称空间中的每个节点都是由一个路径标识。
相关 CAP 理论
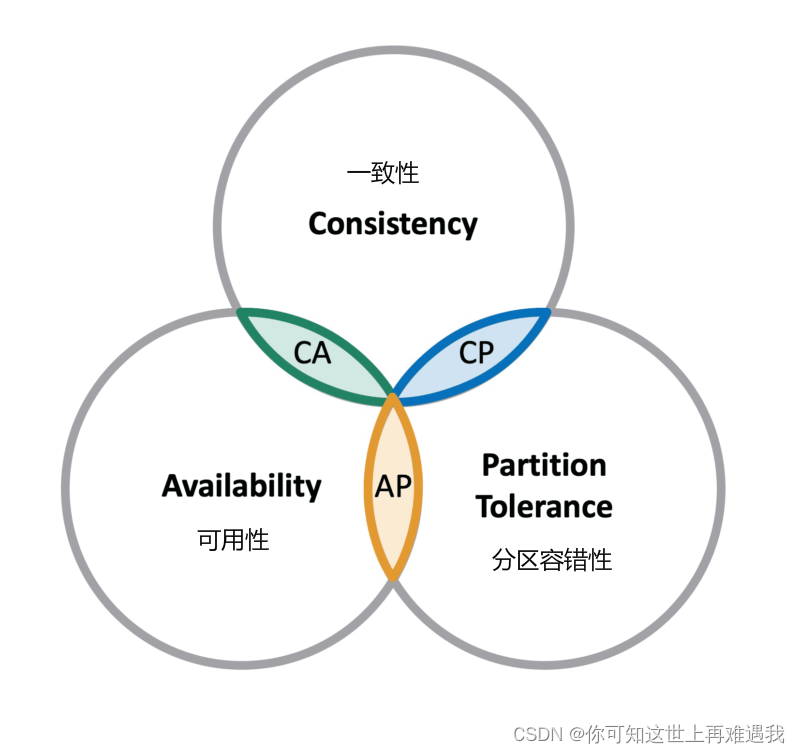
CAP 理论指出对于一个分布式计算系统来说,不可能同时满足以下三点:
- 一致性:在分布式环境中,一致性是指数据在多个副本之间是否能够保持一致的特性,等同于所有节点访问同一份最新的数据副本。在一致性的需求下,当一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。
-
可用性:每次请求都能获取到正确的响应,但是不保证获取的数据为最新数据。
-
分区容错性:分布式系统在遇到任何网络分区故障的时候,仍然需要能够保证对外提供满足一致性和可用性的服务,除非是整个网络环境都发生了故障。
一个分布式系统最多只能同时满足一致性(Consistency)、可用性(Availability)和分区容错性(Partition tolerance)这三项中的两项。
在这三个基本需求中,最多只能同时满足其中的两项,P 是必须的,因此只能在 CP 和 AP 中选择,zookeeper 保证的是 CP,对比 spring cloud 系统中的注册中心 eruka 实现的是 AP。
BASE 理论
BASE 是 Basically Available(基本可用)、Soft-state(软状态) 和 Eventually Consistent(最终一致性) 三个短语的缩写。
-
基本可用:在分布式系统出现故障,允许损失部分可用性(服务降级、页面降级)。
-
软状态:允许分布式系统出现中间状态。而且中间状态不影响系统的可用性。这里的中间状态是指不同的 data replication(数据备份节点)之间的数据更新可以出现延时的最终一致性。
- 最终一致性:data replications 经过一段时间达到一致性。
BASE 理论是对 CAP 中的一致性和可用性进行一个权衡的结果,理论的核心思想就是:我们无法做到强一致,但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性。
② Zookeeper 安装配置
Linux 安装
zookeeper 下载地址为: Apache ZooKeeper。
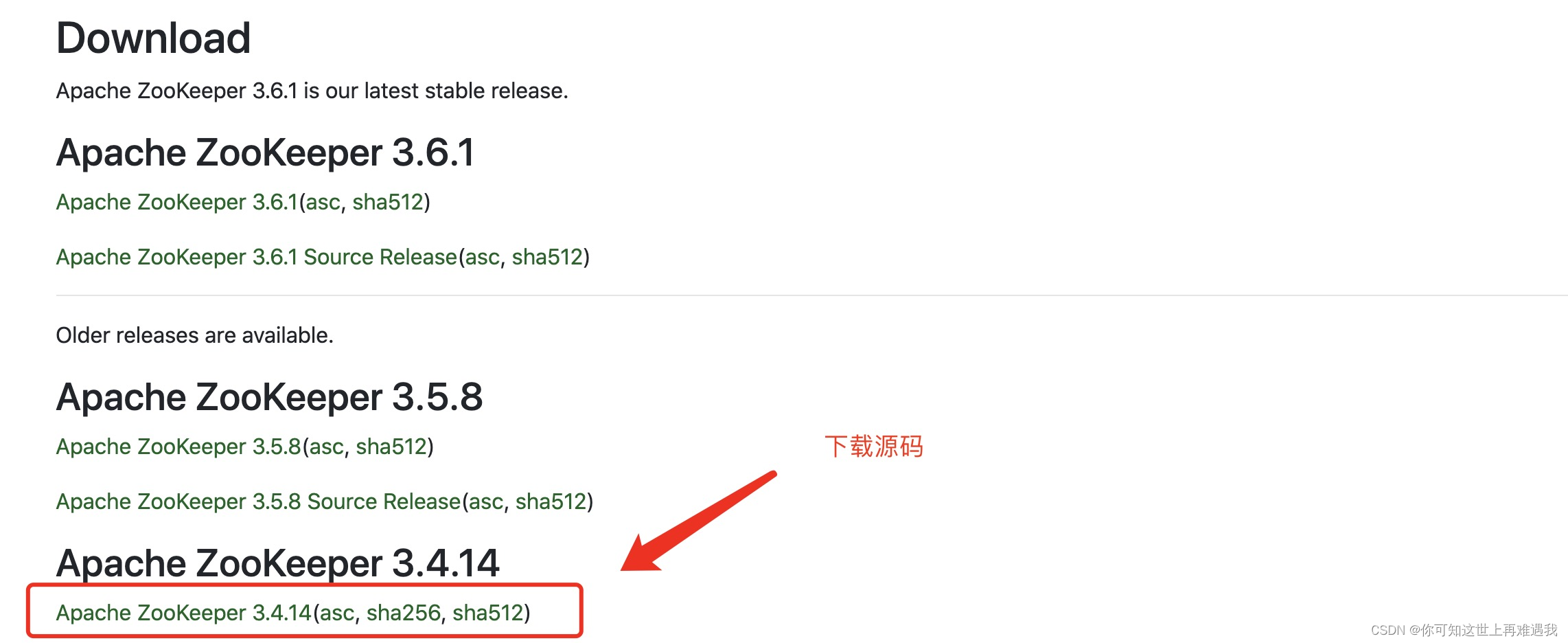
选择一稳定版本,本教程使用的 release 版本为3.4.14,下载并安装。
打开网址 https://www.apache.org/dyn/closer.lua/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz,看到如下界面:
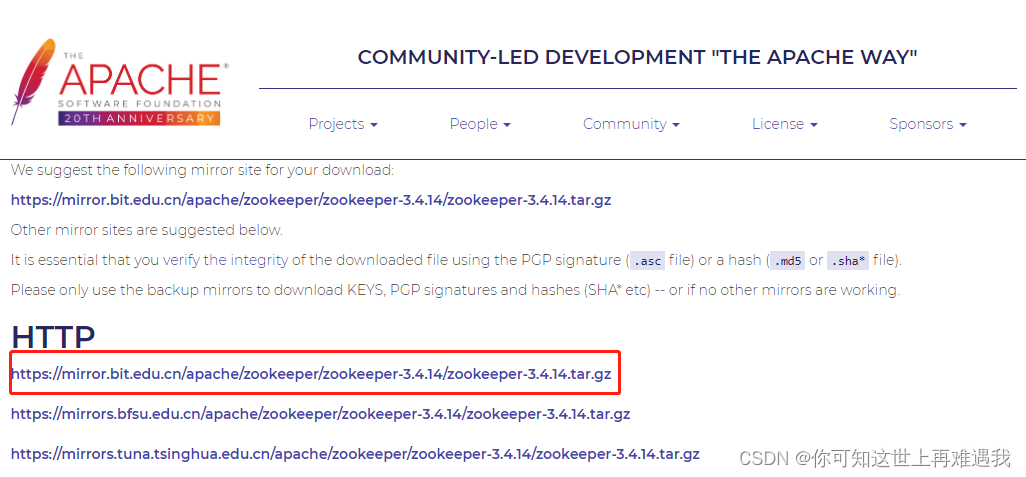
选择一个下载地址,使用 wget 命令下载并安装:
$ wget https://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
$ tar -zxvf zookeeper-3.4.14.tar.gz
$ cd zookeeper-3.4.14
$ cd conf/
$ cp zoo_sample.cfg zoo.cfg
$ cd ..
$ cd bin/
$ sh zkServer.sh start执行后,服务端启动成功:

启动客户端:
$ sh zkCli.sh
帮助命令:
ZooKeeper -server host:port cmd args
stat path [watch]
set path data [version]
ls path [watch]
delquota [-n|-b] path
ls2 path [watch]
setAcl path acl
setquota -n|-b val path
history
redo cmdno
printwatches on|off
delete path [version]
sync path
listquota path
rmr path
get path [watch]
create [-s] [-e] path data acl
addauth scheme auth
quit
getAcl path
close
connect host:port
Windows 下安装
zookeeper 下载地址为: Apache ZooKeeper。
选择一个地址点击版本下载:
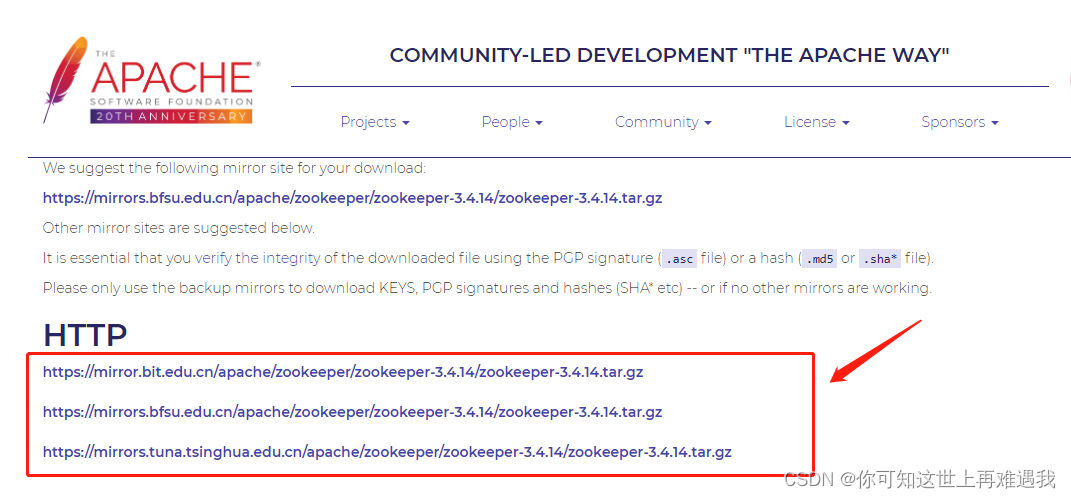
下载后解压:

将 conf 目录下的 zoo_sample.cfg 文件,复制一份,重命名为 zoo.cfg:
在安装目录下面新建一个空的 data 文件夹和 log 文件夹:
修改 zoo.cfg 配置文件,将 dataDir=/tmp/zookeeper 修改成 zookeeper 安装目录所在的 data 文件夹,再添加一条添加数据日志的配置(需要根据自己的安装路径修改)。

双击 zkServer.cmd 启动程序:
控制台显示 bind to port 0.0.0.0/0.0.0.0:2181,表示服务端启动成功!

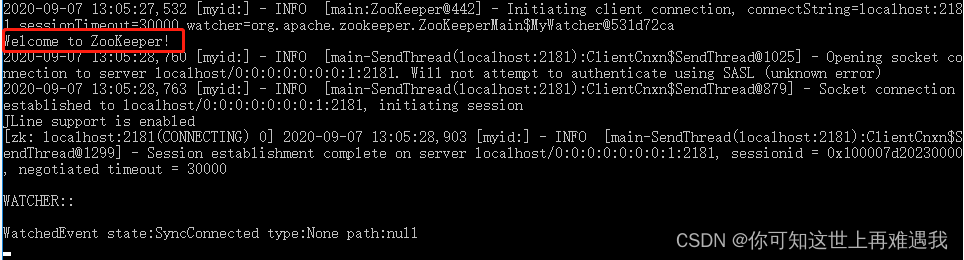
出现 Welcome to Zookeeper!,表示我们成功启动客户端。
③ Zookeeper linux 服务端集群搭建步骤
本章节将示范三台 zookeeper 服务端集群搭建步骤。
所需准备工作,创建三台虚拟机环境并安装好 java 开发工具包 JDK,可以使用 VM 或者 vagrant+virtualbox 搭建 centos/ubuntu 环境,本案例基于宿主机 windows10 系统同时使用 vagrant+virtualbox 搭建的 centos7 环境,如果直接使用云服务器或者物理机同理。
步骤一:准备三台 zookeeper 环境和并按照上一教程下载 zookeeper 压缩包,三台集群 centos 环境如下:
机器一:192.168.3.33

机器二:192.168.3.35

机器三:192.168.3.37

提示: 查看 ip 地址可以用 ifconfig 命令。
步骤二:别修改 zoo.cfg 配置信息
zookeeper 的三个端口作用
- 1、2181 : 对 client 端提供服务
- 2、2888 : 集群内机器通信使用
- 3、3888 : 选举 leader 使用
按 server.id = ip:port:port 修改集群配置文件:
三台虚拟机 zoo.cfg 文件末尾添加配置:
server.1=192.168.3.33:2888:3888 server.2=192.168.3.35:2888:3888 server.3=192.168.3.37:2888:3888
根据 id 和对应的地址分别配置 myid
vim /tmp/zookeeper/myid
本案例配置完成后查询显示如下:
IP 192.168.3.33 机器配置 myid,因为这台机器上个教程单机启动过,所以出现 version-2,没有也没关系。

IP 192.168.3.35 机器配置 myid

IP192.168.3.37 机器配置 myid

步骤三:启动集群
启动前需要关闭防火墙(生产环境需要打开对应端口)
systemctl stop firewalld
启动 192.168.3.33 并查看日志,此时日志出现报错是正常现象,因为另外两台还没启动,暂时连接不上。
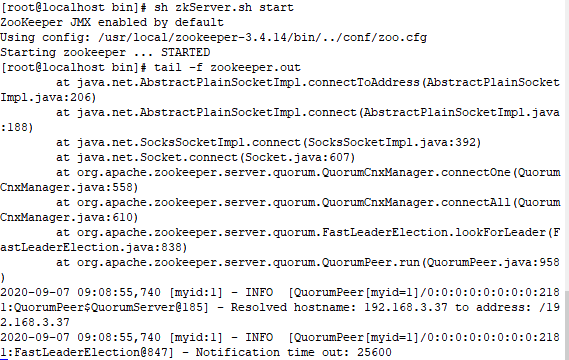
另两台分别启动后,查看三台机器状态:
IP 192.168.3.33

IP 192.168.3.35

IP 192.168.3.37

最后显示集群搭建成功!Mode:leader 代表主节点,follower 代表从节点,一主二从。
④ Zookeeper Java 客户端搭建
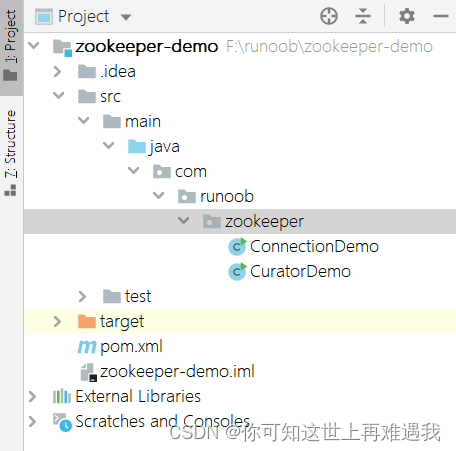
使用的 IDE 为 IntelliJ IDEA,创建一个 maven 工程,命名为 zookeeper-demo,并且引入如下依赖,可以自行在maven中央仓库选择合适的版本,介绍原生 API 和 Curator 两种方式。
IntelliJ IDEA 相关介绍:
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.0.0</version>
</dependency>maven 工程目录结构:
一、客户端的 zookeeper 原生 API
使用 zookeeper 原生 API,连接上一教程搭建的三台服务组成的集群,因为连接需要时间,用 countDownLatch 阻塞,等待连接成功,控制台输出连接状态!
...public static void main(String[] args) {
try {
final CountDownLatch countDownLatch=new CountDownLatch(1);
ZooKeeper zooKeeper=
new ZooKeeper("192.168.3.33:2181," +
"192.168.3.35:2181,192.168.3.37:2181",
4000, new Watcher() {
@Override
public void process(WatchedEvent event) {
if(Event.KeeperState.SyncConnected==event.getState()){
//如果收到了服务端的响应事件,连接成功
countDownLatch.countDown();
}
}
});
countDownLatch.await();
//CONNECTED
System.out.println(zooKeeper.getState());
}
}
...控制台输出 connected 显示连接成功!
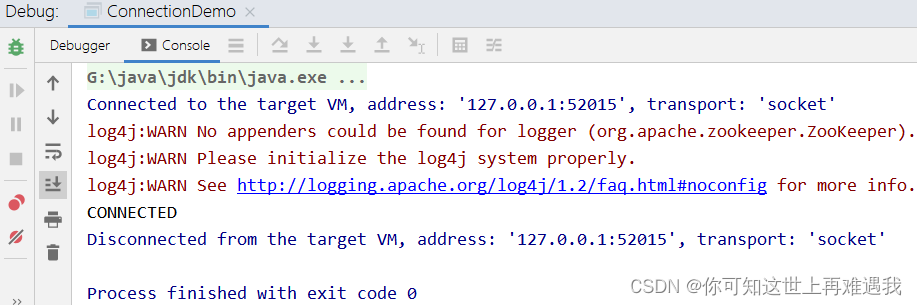
简单示例添加节点 API:
zooKeeper.create("/runoob","0".getBytes(),ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
提示:更多命令功能使用请参考本教程后面章节。
同时在服务端终端执行命令,显示设置成功。
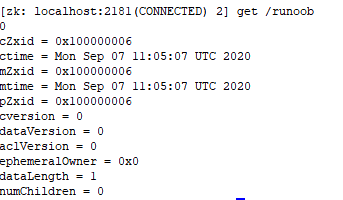
二、客户端的curator连接
Curator 是 Netflix 公司开源的一套 zookeeper 客户端框架,解决了很多 Zookeeper 客户端非常底层的细节开发工作,包括连接重连、反复注册 Watcher 和 NodeExistsException 异常等。
Curator 包含了几个包:
- curator-framework:对 zookeeper 的底层 api 的一些封装。
- curator-client:提供一些客户端的操作,例如重试策略等。
- curator-recipes:封装了一些高级特性,如:Cache 事件监听、选举、分布式锁、分布式计数器、分布式 Barrier 等。
简单使用示例:
public class CuratorDemo {
public static void main(String[] args) throws Exception {
CuratorFramework curatorFramework=CuratorFrameworkFactory.
builder().connectString("192.168.3.33:2181," +
"192.168.3.35:2181,192.168.3.37:2181").
sessionTimeoutMs(4000).retryPolicy(new
ExponentialBackoffRetry(1000,3)).
namespace("").build();
curatorFramework.start();
Stat stat=new Stat();
//查询节点数据
byte[] bytes = curatorFramework.getData().storingStatIn(stat).forPath("/runoob");
System.out.println(new String(bytes));
curatorFramework.close();
}
}上一步设置了 /runoob 节点值,所以控制台输出。
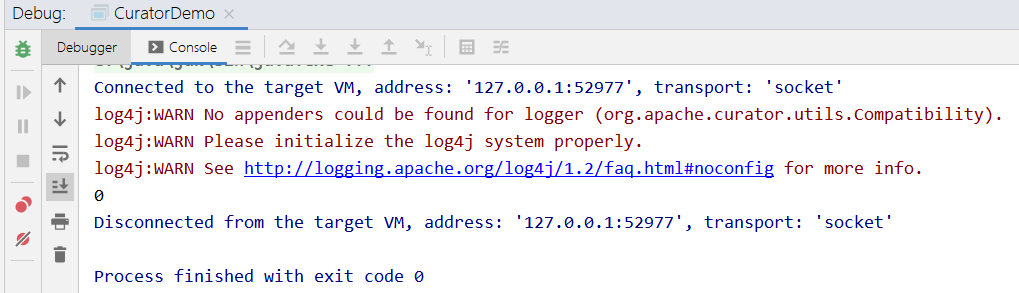

















 1914
1914

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











