









目录
如何避免ConcurrentModificationException?
List
ArrayList
实现List接口,底层是用数组保存所有的元素
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
private static final long serialVersionUID = 8683452581122892189L;
private static final int DEFAULT_CAPACITY = 10;
private static final Object[] EMPTY_ELEMENTDATA = {};ArrayList提供了三种方式的构造器,
1.可以构造一个默认初始容量为10的空列表 2.构造一个指定初始容量的空列表以及构造一个包含指定collection的元素的列表,这些元素按照该collection的迭代器返回它们的顺序排列的 3.手动构造长度
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
public ArrayList(Collection<? extends E> c) {
Object[] a = c.toArray();
if ((size = a.length) != 0) {
if (c.getClass() == ArrayList.class) {
elementData = a;
} else {
elementData = Arrays.copyOf(a, size, Object[].class);
}
} else {
// replace with empty array.
elementData = EMPTY_ELEMENTDATA;
}
}调整数组容量
每当向数组中添加元素时,都要去检查添加后元素的个数是否会超出当前数组的长度,如果超出,数组将会进行扩容,以满足添加数据的需求。数组扩容通过一个公开的方法ensureCapacity(int minCapacity)来实现:
扩容机制:
数组进行扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组容量的增长大约是其原容量的1.5倍。这种操作的代价是很高的,因此在实际使用时,我们应该尽量避免数组容量的扩张。当我们可预知要保存的元素的多少时,要在构造ArrayList实例时,就指定其容量,以避免数组扩容的发生。或者根据实际需求,通过调用ensureCapacity方法来手动增加ArrayList实例的容量。
public void ensureCapacity(int minCapacity) {
int minExpand = (elementData != EMPTY_ELEMENTDATA)
// any size if real element table
? 0
// larger than default for empty table. It's already supposed to be
// at default size.
: DEFAULT_CAPACITY;
if (minCapacity > minExpand) {
ensureExplicitCapacity(minCapacity);
}
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); //此处进行1.5倍扩容
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}Fail—Fast机制
ArrayList也采用了快速失败的机制,通过记录modCount参数来实现。在面对并发的修改时,迭代器很快就会完全失败,而不是冒着在将来某个不确定时间发生任意不确定行为的风险。具体请参看下面HashMap的实现原理,也实现了Fail-Fast机制。
package com.atguigu.codeDemo;
import lombok.extern.slf4j.Slf4j;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
@Slf4j(topic = "c.ListTest")
public class ListTest {
private static List<String> list = new ArrayList<String>();
public static void main(String[] args) {
new ThreadOne().start();
new ThreadTwo().start();
}
private static void printAll() {
String value = null;
Iterator iter = list.iterator();
while (iter.hasNext()) {
value = (String) iter.next();
log.debug(value);
}
}
private static class ThreadOne extends Thread{
@Override
public void run() {
for (int i=0;i<6;i++) {
list.add(String.valueOf("线程一:java的架构师技术栈"+i));
printAll();
}
}
}
private static class ThreadTwo extends Thread {
public void run() {
for (int i=0;i<6;i++) {
list.add(String.valueOf("线程二:java的架构师技术栈"+i));
printAll();
}
}
}
}
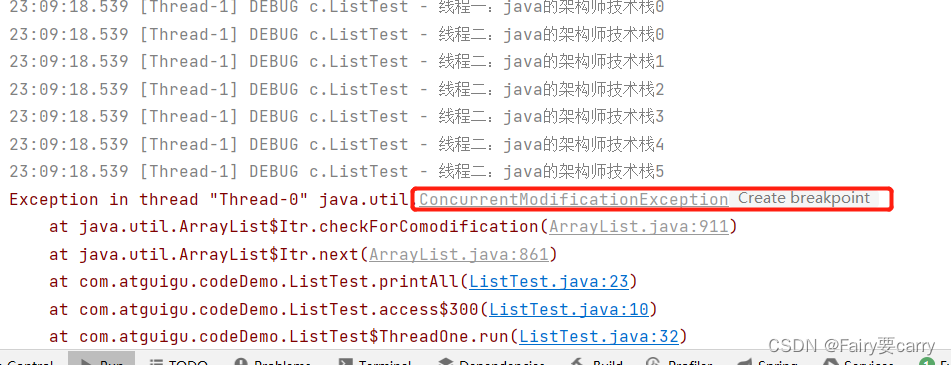
fail-fast是如何抛出ConcurrentModificationException异常的,又是在什么情况下才会抛出?
ConcurrentModificationException都是在操作Iterator时抛出的异常。这里我们就以ArrayList类为例。在ArrayList中,当调用list.iterator()时,其源码是:
public Iterator<E> iterator() {
return new Itr();
}Itr类是ArrayList的内部类,实现了Iterator接口,而ArrayList的Iterator是在父类AbstractList.java中实现的。源码如下:
记住这个int expectedModCount = modCount,每次创建interator时候都会保存新建该对象对应的modCount——>每次遍历的时候都会比较expectedModCount和modCount是否相等;
package java.util;
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> {
...
// AbstractList中唯一的属性
// 用来记录List修改的次数:每修改一次(添加/删除等操作),将modCount+1
protected transient int modCount = 0;
// 返回List对应迭代器。实际上,是返回Itr对象。
public Iterator<E> iterator() {
return new Itr();
}
// Itr是Iterator(迭代器)的实现类
private class Itr implements Iterator<E> {
// index of next element to return
int cursor = 0;
// index of last element returned; -1 if no such
int lastRet = -1;
// 修改数的记录值。
// 每次新建Itr()对象时,都会保存新建该对象时对应的modCount;
// 以后每次遍历List中的元素的时候,都会比较expectedModCount和modCount是否相等;
// 若不相等,则抛出ConcurrentModificationException异常,产生fail-fast事件。
int expectedModCount = modCount;
public boolean hasNext() {
return cursor != size();
}
@SuppressWarnings("unchecked")
public E next() {
// 获取下一个元素之前,都会判断“新建Itr对象时保存的modCount”和“当前的modCount”是否相等;
// 若不相等,则抛出ConcurrentModificationException异常,产生fail-fast事件。
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}
@Override
@SuppressWarnings("unchecked")
public void forEachRemaining(Consumer<? super E> consumer) {
Objects.requireNonNull(consumer);
final int size = ArrayList.this.size;
int i = cursor;
if (i >= size) {
return;
}
final Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length) {
throw new ConcurrentModificationException();
}
while (i != size && modCount == expectedModCount) {
consumer.accept((E) elementData[i++]);
}
// update once at end of iteration to reduce heap write traffic
cursor = i;
lastRet = i - 1;
checkForComodification();
}
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
}
...
}Itr类的三个属性
1.cursor是指集合遍历过程中的即将遍历的元素的索引
2.lastRet是cursor -1,默认为-1,即不存在上一个时,为-1,它主要用于记录刚刚遍历过的元素的索引。
3.expectedModCount这个就是fail-fast判断的关键变量了,它初始值就为ArrayList中的modCount。(modCount是抽象类AbstractList中的变量,默认为0,而ArrayList 继承了AbstractList ,所以也有这个变量,modCount用于记录集合操作过程中作的修改次数,与size还是有区别的,并不一定等于size)
int cursor; // index of next element to return
int lastRet = -1; // index of last element returned; -1 if no such
int expectedModCount = modCount;慢慢深入
haxNext()
迭代器结束的标志就是hasNext为false,说明cursor==size
public boolean hasNext() {
return cursor != size;
}接下来看看最关心的next()和remove()方法,看看为什么在迭代过程中,如果有线程对集合结构做出改变,就会发生fail-fast:
@SuppressWarnings("unchecked")
public E next() {
checkForComodification();
int i = cursor;
if (i >= size)
throw new NoSuchElementException();
Object[] elementData = ArrayList.this.elementData;
if (i >= elementData.length)
throw new ConcurrentModificationException();
cursor = i + 1;
return (E) elementData[lastRet = i];
}
public void remove() {
if (lastRet < 0)
throw new IllegalStateException();
checkForComodification();
try {
ArrayList.this.remove(lastRet);
cursor = lastRet;
lastRet = -1;
expectedModCount = modCount;
} catch (IndexOutOfBoundsException ex) {
throw new ConcurrentModificationException();
}
}简而言之,每次调用next()和remove()方法,在实际访问元素/删除元素前,都会调用checkForComodification方法,该方法源码如下:
判断关键在于modCount和expectedModCount
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}从之前结合来看很明显expectedModCount在整个迭代过程除了一开始赋予初始值modCount外,并没有在任何地方对其进行修改操作,不可能发生改变,所以可能发生改变的就只有modCount。下面我们在通过源码来看一下什么时候modCount 不等于 expectedModCount”,通过ArrayList的源码,来看看modCount是如何被修改的
add()和addAll()和remove(),ensureCapacity()方法
可以发现这些方法设计到修改集合元素个数时候都会改变modCount值,这时候联合之前出现异常的情况不难得到fail-fast机制
package java.util;
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
{
...
// list中容量变化时,对应的同步函数
public void ensureCapacity(int minCapacity) {
modCount++;
int oldCapacity = elementData.length;
if (minCapacity > oldCapacity) {
Object oldData[] = elementData;
int newCapacity = (oldCapacity * 3)/2 + 1;
if (newCapacity < minCapacity)
newCapacity = minCapacity;
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
}
// 添加元素到队列最后
public boolean add(E e) {
// 修改modCount
ensureCapacity(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
// 添加元素到指定的位置
public void add(int index, E element) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(
"Index: "+index+", Size: "+size);
// 修改modCount
ensureCapacity(size+1); // Increments modCount!!
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
elementData[index] = element;
size++;
}
// 添加集合
public boolean addAll(Collection<? extends E> c) {
Object[] a = c.toArray();
int numNew = a.length;
// 修改modCount
ensureCapacity(size + numNew); // Increments modCount
System.arraycopy(a, 0, elementData, size, numNew);
size += numNew;
return numNew != 0;
}
// 删除指定位置的元素
public E remove(int index) {
RangeCheck(index);
// 修改modCount
modCount++;
E oldValue = (E) elementData[index];
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index, numMoved);
elementData[--size] = null; // Let gc do its work
return oldValue;
}
// 快速删除指定位置的元素
private void fastRemove(int index) {
// 修改modCount
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // Let gc do its work
}
// 清空集合
public void clear() {
// 修改modCount
modCount++;
// Let gc do its work
for (int i = 0; i < size; i++)
elementData[i] = null;
size = 0;
}
...
}我们再系统的梳理一下fail-fast是怎么产生的。步骤如下:
1.新建了一个ArrayList,名称为arrayList。
2.向arrayList中添加内容。
3.新建一个“线程a”,并在“线程a”中通过Iterator()反复的读取arrayList的值。
4.新建一个“线程b”,在“线程b”中删除arrayList中的一个“节点A”。
这时,就会产生有趣的事件了。
5.在某一时刻,“线程a”创建了arrayList的Iterator()。此时“节点A”仍然存在于arrayList中,创建arrayList时,expectedModCount = modCount(假设它们此时的值为N)。
6.在“线程a”在遍历arrayList过程中的某一时刻,“线程b”执行了,并且“线程b”删除了arrayList中的“节点A”。“线程b”执行remove()进行删除操作时,在remove()中执行了“modCount++”,此时modCount变成了N+1!
7.线程a”接着遍历,当它执行到next()函数时,调用checkForComodification()比较“expectedModCount”和“modCount”的大小;而“expectedModCount=N”,“modCount=N+1”,这样,便抛出ConcurrentModificationException异常,产生fail-fast事件。
总结:
当多个线程对同一个集合进行操作的时候,某线程访问集合的过程中,该集合的内容被其他线程所改变(即其它线程通过add、remove、clear等方法,改变了modCount的值);这时,就会抛出ConcurrentModificationException异常,产生fail-fast事件。类似的,hashMap中发生的原理也是一样的。
如何避免ConcurrentModificationException?
对于每个能够改变modCount的方法进行上锁,或者用CopyOnWriteArrayList
为什么CopyOnWrite可以保证线程安全?
CopyOnWriterArrayList在是使用上跟 ArrayList几乎一样, CopyOnWriter是写时复制的容器(COW),在读写时是线程安全的。该容器在对add和remove等操作时,并不是在原数组上进行修改,而是将原数组拷贝一份,在新数组上进行修改,待完成后,才将指向旧数组的引用指向新数组,所以对于 CopyOnWriterArrayList在迭代过程并不会发生fail-fast现象。但 CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性(也就是软一致性)。
另外,从下面源码可知ArrayList的Iterator实现类中调用next()时,会“调用checkForComodification()比较‘expectedModCount’和‘modCount’的大小”;但是,CopyOnWriteArrayList的Iterator实现类中,没有所谓的checkForComodification(),更不会抛出ConcurrentModificationException异常!
package java.util.concurrent;
import java.util.*;
import java.util.concurrent.locks.*;
import sun.misc.Unsafe;
public class CopyOnWriteArrayList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
...
// 返回集合对应的迭代器
public Iterator<E> iterator() {
return new COWIterator<E>(getArray(), 0);
}
...
private static class COWIterator<E> implements ListIterator<E> {
private final Object[] snapshot;
private int cursor;
private COWIterator(Object[] elements, int initialCursor) {
cursor = initialCursor;
// 新建COWIterator时,将集合中的元素保存到一个新的拷贝数组中。
// 这样,当原始集合的数据改变,拷贝数据中的值也不会变化。
snapshot = elements;
}
public boolean hasNext() {
return cursor < snapshot.length;
}
public boolean hasPrevious() {
return cursor > 0;
}
public E next() {
if (! hasNext())
throw new NoSuchElementException();
return (E) snapshot[cursor++];
}
public E previous() {
if (! hasPrevious())
throw new NoSuchElementException();
return (E) snapshot[--cursor];
}
public int nextIndex() {
return cursor;
}
public int previousIndex() {
return cursor-1;
}
public void remove() {
throw new UnsupportedOperationException();
}
public void set(E e) {
throw new UnsupportedOperationException();
}
public void add(E e) {
throw new UnsupportedOperationException();
}
}
...
}LinkedList
LinkedList是Collection下的一个list实现,就像ArrayList一样。
和ArrayList的区别
和ArrayList不同的是它是链表结构,而ArrayList是顺序结构。我们平常使用的list是一样的,理论上来说一种list就可以完成我们所有的需求。但是它们在运行过程中有区别的,完成需求所需要的资源也不相同,至于什么情况下使用哪种list就看需求和当前情况了。
查询速度较慢,增删改速度较快,像ArrayList这种基于数组实现的,每次插入删除后面的元素索引都得变,所以慢的一批
- 插入删除不需要移动元素外,可以原地插入删除
- 可以在结构的前后插入数据
- 可以双向遍历
构造函数
// 默认构造函数
LinkedList()
// 创建一个LinkedList,保护Collection中的全部元素。
LinkedList(Collection<? extends E> collection)
线程安全
多线程下,和ArrayList一样都是不安全的
举个例子吧,还是之前的add方法,不难发现下面和ArrayList一样,都是有着modCount,不做解释了
public boolean add(E e) {
linkLast(e);
return true;
}
/**
* Links e as last element.
*/
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
删除remove
public E remove(int index) {
checkElementIndex(index);
return unlink(node(index));
}
//查找对应索引
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* Unlinks non-null node x.
*/
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}

使用场景
1.ArrayList在随机访问方面比较擅长,LinkedList在随机增删方面比较擅长
2.对于需要快速插入,删除元素,使用LinkedList。因为ArrayList要想在数组中任意两个元素中间3.添加对象时,数组需要移动所有后面的对象。
3.对于需要快速随机访问元素(get()),应该使用ArrayList,因为LinkedList要移动指针、遍历节点来定位,所以速度慢。
4.对于“单线程环境” 或者 “多线程环境,但List仅仅只会被单个线程操作”,此时应该使用非同步的类(如ArrayList)。
5.对于“多线程环境,且List可能同时被多个线程操作”,此时,应该使用同步的类(如Vector)。
Vector
和ArrayList不同,Vector中的操作是线程安全的,但速度慢,在每个方法前都加上了锁(即synchronized关键字)。
- Vector实际上是通过一个数组去保存数据的。当我们构造Vecotr时;若使用默认构造函数,则Vector的默认容量大小是10。
- 当Vector容量不足以容纳全部元素时,Vector的容量会增加。若容量增加系数 >0,则将容量的值增加“容量增加系数”;否则,将容量大小增加一倍。
- Vector的克隆函数,即是将全部元素克隆到一个数组中。
详细实现原理博客链接:http://www.cnblogs.com/skywang12345/p/3308833.html
CopyOnWriteArrayList
与 Vector一样,CopyOnWriteArrayList也可以认为是ArrayList的线程安全版,不同之处在于当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。这样做的好处是我们可以对CopyOnWriteArrayList进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWriteArrayList是一种读写分离的思想,读和写不同的容器。
注意:CopyOnWriteArrayList只能保证数据的最终一致性,并不能保证数据的实时一致性,执行读操作时是有可能会读到失效的数据的。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。
HashSet和TreeSet
(31条消息) HashSet和TreeSet的区别_Fairy要carry的博客-CSDN博客
Set集合父接口是Collection,也是单利元素集合,Set集合底层实现的是Map集合,其中Set实现的是Map中的Key值。所以Set集合中的元素是不允许重复的,同时也是只能有一个null值。Set集合常用到的集合有:hashSet、TreeSet.
HashSet
1.底层实现的就是HashMap,所以是根据HashCode来判断是否是重复元素。(下面有hashCode的解释)
因为TreeSet要是额外使用红黑树来保证元素的有序性,所以性能相对来说是hashSet的性能是要比TreeSet的性能要好。
2.初始化容量是:16, 这是因为底层实现的是HashMap。加载因子是0.75
3.HashSet是无序的,也就是说插入的顺序和取出的顺序是不一样的。
4.因为HashSet不能根据索引去数据,所以不能用普通的for循环来取出数据,应该用增强for循环。这也进一步说明了HashSet的查询性能肯定是,没有ArrayList的性能高的。
5.可以有null值,一个
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
static final long serialVersionUID = -5024744406713321676L;
// 底层使用HashMap来保存HashSet中所有元素。
private transient HashMap<E,Object> map;
// 定义一个虚拟的Object对象作为HashMap的value,将此对象定义为static final。
private static final Object PRESENT = new Object();
/**
* 默认的无参构造器,构造一个空的HashSet。
*
* 实际底层会初始化一个空的HashMap,并使用默认初始容量为16和加载因子0.75。
*/
public HashSet() {
map = new HashMap<E,Object>();
}
/**
* 构造一个包含指定collection中的元素的新set。
*
* 实际底层使用默认的加载因子0.75和足以包含指定
* collection中所有元素的初始容量来创建一个HashMap。
* @param c 其中的元素将存放在此set中的collection。
*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<E,Object>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
/**
* 以指定的initialCapacity和loadFactor构造一个空的HashSet。
*
* 实际底层以相应的参数构造一个空的HashMap。
* @param initialCapacity 初始容量。
* @param loadFactor 加载因子。
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<E,Object>(initialCapacity, loadFactor);
}
/**
* 以指定的initialCapacity构造一个空的HashSet。
*
* 实际底层以相应的参数及加载因子loadFactor为0.75构造一个空的HashMap。
* @param initialCapacity 初始容量。
*/
public HashSet(int initialCapacity) {
map = new HashMap<E,Object>(initialCapacity);
}
/**
* 以指定的initialCapacity和loadFactor构造一个新的空链接哈希集合。
* 此构造函数为包访问权限,不对外公开,实际只是是对LinkedHashSet的支持。
*
* 实际底层会以指定的参数构造一个空LinkedHashMap实例来实现。
* @param initialCapacity 初始容量。
* @param loadFactor 加载因子。
* @param dummy 标记。
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<E,Object>(initialCapacity, loadFactor);
}
/**
* 返回对此set中元素进行迭代的迭代器。返回元素的顺序并不是特定的。
*
* 底层实际调用底层HashMap的keySet来返回所有的key。
* 可见HashSet中的元素,只是存放在了底层HashMap的key上,
* value使用一个static final的Object对象标识。
* @return 对此set中元素进行迭代的Iterator。
*/
public Iterator<E> iterator() {
return map.keySet().iterator();
}
/**
* 返回此set中的元素的数量(set的容量)。
*
* 底层实际调用HashMap的size()方法返回Entry的数量,就得到该Set中元素的个数。
* @return 此set中的元素的数量(set的容量)。
*/
public int size() {
return map.size();
}
/**
* 如果此set不包含任何元素,则返回true。
*
* 底层实际调用HashMap的isEmpty()判断该HashSet是否为空。
* @return 如果此set不包含任何元素,则返回true。
*/
public boolean isEmpty() {
return map.isEmpty();
}
/**
* 如果此set包含指定元素,则返回true。
* 更确切地讲,当且仅当此set包含一个满足(o==null ? e==null : o.equals(e))
* 的e元素时,返回true。
*
* 底层实际调用HashMap的containsKey判断是否包含指定key。
* @param o 在此set中的存在已得到测试的元素。
* @return 如果此set包含指定元素,则返回true。
*/
public boolean contains(Object o) {
return map.containsKey(o);
}
/**
* 如果此set中尚未包含指定元素,则添加指定元素。
* 更确切地讲,如果此 set 没有包含满足(e==null ? e2==null : e.equals(e2))
* 的元素e2,则向此set 添加指定的元素e。
* 如果此set已包含该元素,则该调用不更改set并返回false。
*
* 底层实际将将该元素作为key放入HashMap。
* 由于HashMap的put()方法添加key-value对时,当新放入HashMap的Entry中key
* 与集合中原有Entry的key相同(hashCode()返回值相等,通过equals比较也返回true),
* 新添加的Entry的value会将覆盖原来Entry的value,但key不会有任何改变,
* 因此如果向HashSet中添加一个已经存在的元素时,新添加的集合元素将不会被放入HashMap中,
* 原来的元素也不会有任何改变,这也就满足了Set中元素不重复的特性。
* @param e 将添加到此set中的元素。
* @return 如果此set尚未包含指定元素,则返回true。
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
/**
* 如果指定元素存在于此set中,则将其移除。
* 更确切地讲,如果此set包含一个满足(o==null ? e==null : o.equals(e))的元素e,
* 则将其移除。如果此set已包含该元素,则返回true
* (或者:如果此set因调用而发生更改,则返回true)。(一旦调用返回,则此set不再包含该元素)。
*
* 底层实际调用HashMap的remove方法删除指定Entry。
* @param o 如果存在于此set中则需要将其移除的对象。
* @return 如果set包含指定元素,则返回true。
*/
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
/**
* 从此set中移除所有元素。此调用返回后,该set将为空。
*
* 底层实际调用HashMap的clear方法清空Entry中所有元素。
*/
public void clear() {
map.clear();
}
/**
* 返回此HashSet实例的浅表副本:并没有复制这些元素本身。
*
* 底层实际调用HashMap的clone()方法,获取HashMap的浅表副本,并设置到HashSet中。
*/
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
}
}
下面来说说为啥Set集合如何去重的:
当我们试图把某个类的对象当成 HashMap的 key,或试图将这个类的对象放入 HashSet 中保存时,重写该类的equals(Object obj)方法和 hashCode() 方法,而且这两个方法的返回值必须保持一致:当该类的两个的 hashCode() 返回值相同时,它们通过 equals() 方法比较也应该返回 true。
(30条消息) Java 中的 ==, equals 与 hashCode 的区别与联系_书呆子Rico的博客-CSDN博客_equals和hashcode的区别与联系
通常来说,所有参与计算 hashCode() 返回值的关键属性,都应该用于作为 equals() 比较的标准。
如何取到Set集合的第一个元素?
import java.util.ArrayList;
import java.util.HashSet;
import java.util.List;
import java.util.Set;
public class SetTest {
public static void main(String[] args) {
Set set = new HashSet();
set.add("tracy");
set.add("hcx");
set.add(123);
set.add(4.5);
System.out.println(set);//[4.5, hcx, tracy, 123]
//第一种方法
if(!set.isEmpty()){
System.out.println(set.iterator().next());// 4.511 }
}
//第二种方法:将set集合转换成list集合 取第一个
List list = new ArrayList(set);
System.out.println(list.get(0));// 4.5
}
}
TreeSet注意
TreeSet要求存放的对象所属的类必须是实现Comparable接口,该接口提供了比较元素的compareTo方法,当插入元素时会调该方法比较元素的大小.TreeMap要求存放的键值对映射的键必须实现Comparable接口,从而根据键对元素进行排序。
Map



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











