






目录
一、前期需要安装的软件
python网址:Welcome to Python.org
pycharm网址:Download PyCharm: The Python IDE for data science and web development by JetBrains
安装chrome和chromedriver:需要注意的是版本问题,不然后面运行时会报错。
本文使用的是129版本,下载地址为:Chrome for Testing availability (googlechromelabs.github.io)
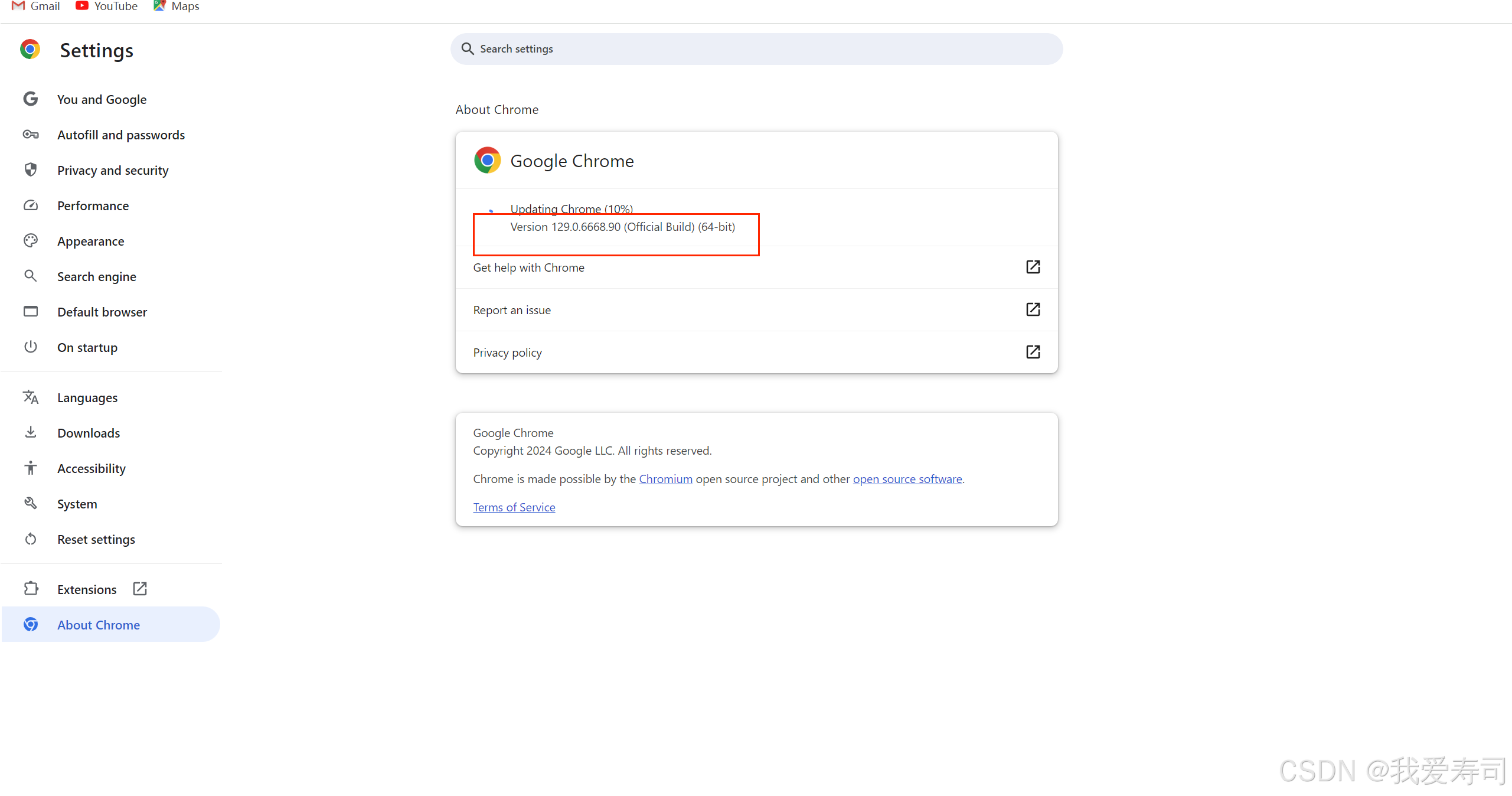
下载完后,将chromedriver放在chrome目录下
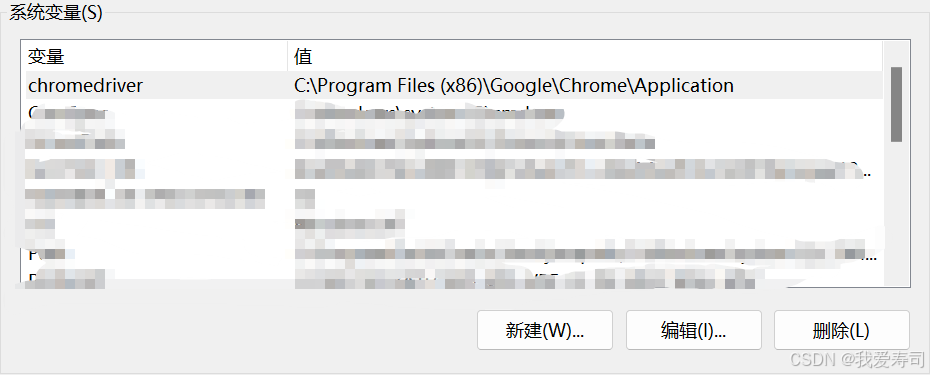
最后一步,打开我们的查看高级系统设置,点击环境变量,打开系统变量里面的path环境。添加我们的驱动路径进去。
二、爬取目标
需要爬取内容: 分类爬取榜单top100视频的标题,up主,观看量,弹幕数, 点赞数,投币数,收藏数。
分析点: 比较观看量,弹幕数, 点赞数,投币数,收藏数的差异。分析是什么因素是的他热度较高和top前100视频哪个类别的视频较多。可以总结出做哪一类视频更容易火和大众更喜欢哪一类的视频。
三、完整代码
import csv
from selenium import webdriver
import pandas as pd
from selenium.webdriver.common.by import By
if __name__ == '__main__':
url = 'https://www.bilibili.com/v/popular/rank/game' #末尾的game是类别,可根据需求修稿
driver = webdriver.Chrome()
driver.get(url)
csv_file = "data/top100_url-游戏.csv"
with open(csv_file, 'a', newline='', encoding='utf-8') as f:
writer = csv.writer(f)
writer.writerow(['b站实时排行榜前一百视频url', 'up主昵称'])
i = 1
print()
while (i < 101):
all_datas = driver.find_elements(By.XPATH,f'//*[@id="app"]/div/div[2]/div[2]/ul/li[{i}]/div/div[2]/a')
#f'//*[@id="app"]/div/div[2]/div[2]/ul/li[{i}]/div/div[2]/a
all_up_name = driver.find_elements(By.XPATH,
f'//*[@id="app"]/div/div[2]/div[2]/ul/li[{i}]/div/div[2]/div/a/span')
href_values = [element.get_attribute("href") for element in all_datas]
up_name = all_up_name[0].text
writer.writerow([href_values[0], up_name])
print(f'第{i}个视频已经爬取完成')
i += 1
########################################################################################################################
# 提取上一步爬取下来的文件中的url
all_urls = pd.read_csv('./data/top100_url-游戏.csv',encoding='utf-8')
# print(all_urls.columns)
all_video_urls = all_urls['b站实时排行榜前一百视频url']
all_video_up = all_urls['up主昵称']
driver = webdriver.Chrome()
csv_file = "data/top100_details-游戏.csv"
with open(csv_file, 'a', newline='', encoding='utf-8') as f:
# driver.find_element(By.LINK_TEXT,u"下一页").click()
writer = csv.writer(f)
writer.writerow(['视频标题', 'up主', '观看量', '弹幕数', '点赞数', '投币数', '收藏数'])
i = 0
for url in all_video_urls:
driver.get(url)
data_title = driver.find_elements(By.XPATH,f'//*[@id="viewbox_report"]/div/div/h1')
##33##3###3// *[ @ id = "viewbox_report"] / h1
title = data_title[0].text ###### 视频标题
up = all_video_up[i] ###### up主
data_watch_dm = driver.find_elements(By.XPATH,'//*[@id="viewbox_report"]/div[2]/div/div/div')
#// *[ @ id = "viewbox_report"] / div / div / span
watch = data_watch_dm[0].text ###### 播放量
if watch[-1] in '万':
num = float(watch[0:-1])
num *= 10000
watch = str(num)
dm = data_watch_dm[1].text ###### 弹幕数
if dm[-1] in '万':
num = float(dm[0:-1])
num *= 10000
dm = str(num)
data_dz_tb_sc_fx = driver.find_elements(By.XPATH,'//*[@id="arc_toolbar_report"]/div/div/div/div/span')
video_like_info = data_dz_tb_sc_fx[0].text ###### 点赞数
if video_like_info[-1] in '万':
num = float(video_like_info[0:-1])
num *= 10000
video_like_info = str(num)
video_coin_info = data_dz_tb_sc_fx[1].text ###### 投币数
if video_coin_info[-1] in '万':
num = float(video_coin_info[0:-1])
num *= 10000
video_coin_info = str(num)
video_fav_info = data_dz_tb_sc_fx[2].text ###### 收藏数
if video_fav_info[-1] in '万':
num = float(video_fav_info[0:-1])
num *= 10000
video_fav_info = str(num)
#data_dz_tb_sc_fx1 = driver.find_elements(By.XPATH, '//*[@id="arc_toolbar_report"]/div/div/div[4]/div/span/div/div/span')
# video_share_info = data_dz_tb_sc_fx1[0].text ###### 分享数
# if video_share_info[-1] in '万':
# num = float(video_share_info[0:-1])
# num *= 10000
# video_share_info = str(num)
# print(video_share_info)
row = [title, up, watch, dm, video_like_info, video_coin_info,
video_fav_info]
#video_share_info
writer.writerow(row)
print(f'第{i + 1}个视频已经爬取成功!')
i += 1

















 271
271

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









