






目录
一、效果呈现
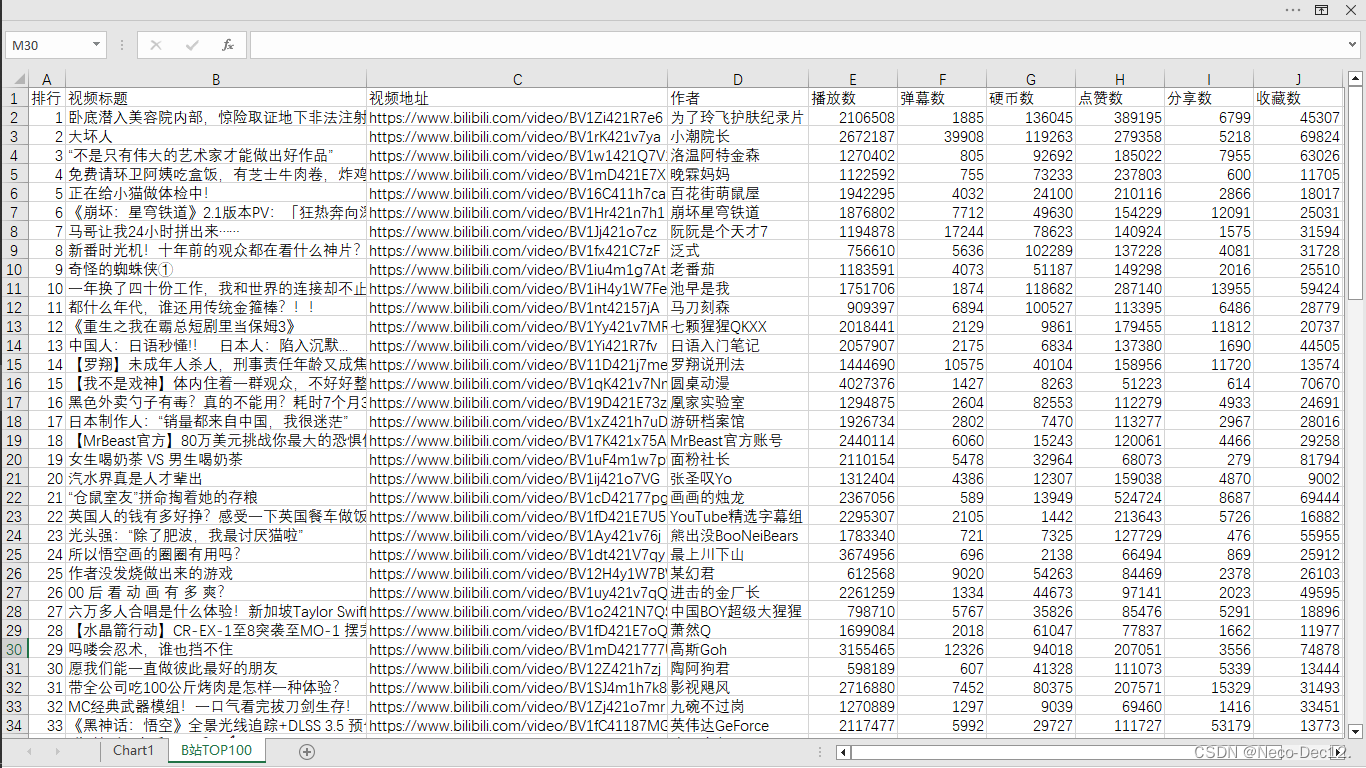
二、讲解
1. 发送请求并获取数据
首先,我们需要定义B站热门视频API的URL,并设置请求头以模拟浏览器访问。这样可以避免被识别为爬虫并提高请求的成功率。
import requests
import json
import pandas as pd
# 定义B站热门视频API的URL
url = 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=all'
# 定义请求头,模拟浏览器访问
headers = {
'Referer': 'https://www.bilibili.com/v/popular/rank/all/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:102.0) Gecko/20100101 Firefox/102.0'
}
# 发送GET请求到B站API并获取响应
response = requests.get(url, headers=headers)
# 解析响应内容为JSON格式
data = json.loads(response.text)2. 提取视频信息
从响应数据中,我们可以提取出视频列表,并初始化一些列表来存储视频的详细信息。(这里的各类数据可以按你自己的需求进行选择)
# 从响应数据中提取视频列表
video_list = data['data']['list']
# 初始化空列表以存储视频信息
rank_list = [] # 排行
title_list = [] # 视频标题
play_cnt_list = [] # 播放数
danmu_cnt_list = [] # 弹幕数
coin_cnt_list = [] # 投币数
like_cnt_list = [] # 点赞数
share_cnt_list = [] # 分享数
favorite_cnt_list = [] # 收藏数
author_list = [] # 作者
video_url = [] # 视频地址
# 遍历视频列表并提取每部视频的信息
for idx, video in enumerate(video_list):
rank_list.append(idx + 1) # 添加视频排行
title_list.append(video['title']) # 添加视频标题
play_cnt_list.append(video['stat']['view']) # 添加播放数
danmu_cnt_list.append(video['stat']['danmaku']) # 添加弹幕数
coin_cnt_list.append(video['stat']['coin']) # 添加投币数
like_cnt_list.append(video['stat']['like']) # 添加点赞数
share_cnt_list.append(video['stat']['share']) # 添加分享数
favorite_cnt_list.append(video['stat']['favorite']) # 添加收藏数
author_list.append(video['owner']['name']) # 添加作者名称
video_url.append(f'https://www.bilibili.com/video/{video["bvid"]}') # 添加视频地址3. 保存为CSV文件
最后,我们使用'pandas'库创建一个DataFrame,并将所有提取的数据存储在这个DataFrame中。然后,我们将这个DataFrame保存为CSV文件。
# 使用pandas创建DataFrame,准备存储所有提取的数据
df = pd.DataFrame({
'排行': rank_list,
'视频标题': title_list,
'视频地址': video_url,
'作者': author_list,
'播放数': play_cnt_list,
'弹幕数': danmu_cnt_list,
'硬币数': coin_cnt_list,
'点赞数': like_cnt_list,
'分享数': share_cnt_list,
'收藏数': favorite_cnt_list,
})
# 将DataFrame保存为CSV文件,不包含索引,使用utf_8_sig编码
df.to_csv('B站TOP100.csv', index=False, encoding="utf_8_sig")三、完整代码
import requests # 导入requests库以发送HTTP请求
import json # 导入json库以处理JSON数据
import pandas as pd # 导入pandas库以创建和操作数据表格
# 定义B站热门视频API的URL
url = 'https://api.bilibili.com/x/web-interface/ranking/v2?rid=0&type=all'
# 定义请求头,模拟浏览器访问
headers = {
'Referer': 'https://www.bilibili.com/v/popular/rank/all/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:102.0) Gecko/20100101 Firefox/102.0'
}
# 发送GET请求到B站API并获取响应
response = requests.get(url, headers=headers)
# 解析响应内容为JSON格式
data = json.loads(response.text)
# 从响应数据中提取视频列表
video_list = data['data']['list']
# 初始化空列表以存储视频信息
rank_list = [] # 排行
title_list = [] # 视频标题
play_cnt_list = [] # 播放数
danmu_cnt_list = [] # 弹幕数
coin_cnt_list = [] # 投币数
like_cnt_list = [] # 点赞数
share_cnt_list = [] # 分享数
favorite_cnt_list = [] # 收藏数
author_list = [] # 作者
video_url = [] # 视频地址
# 遍历视频列表并提取每部视频的信息
for idx, video in enumerate(video_list):
rank_list.append(idx + 1) # 添加视频排行
title_list.append(video['title']) # 添加视频标题
play_cnt_list.append(video['stat']['view']) # 添加播放数
danmu_cnt_list.append(video['stat']['danmaku']) # 添加弹幕数
coin_cnt_list.append(video['stat']['coin']) # 添加投币数
like_cnt_list.append(video['stat']['like']) # 添加点赞数
share_cnt_list.append(video['stat']['share']) # 添加分享数
favorite_cnt_list.append(video['stat']['favorite']) # 添加收藏数
author_list.append(video['owner']['name']) # 添加作者名称
video_url.append(f'https://www.bilibili.com/video/{video["bvid"]}') # 添加视频地址
# 使用pandas创建DataFrame,准备存储所有提取的数据
df = pd.DataFrame({
'排行': rank_list,
'视频标题': title_list,
'视频地址': video_url,
'作者': author_list,
'播放数': play_cnt_list,
'弹幕数': danmu_cnt_list,
'硬币数': coin_cnt_list,
'点赞数': like_cnt_list,
'分享数': share_cnt_list,
'收藏数': favorite_cnt_list,
})
# 将DataFrame保存为CSV文件,不包含索引,使用utf_8_sig编码
df.to_csv('B站TOP100.csv', index=False, encoding="utf_8_sig")
















 740
740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









