





使用浏览器XPATH获取的路径://*[@id="content"]/div/div[1]/div/table[1]/tbody/tr/td[2]/div[1]/a
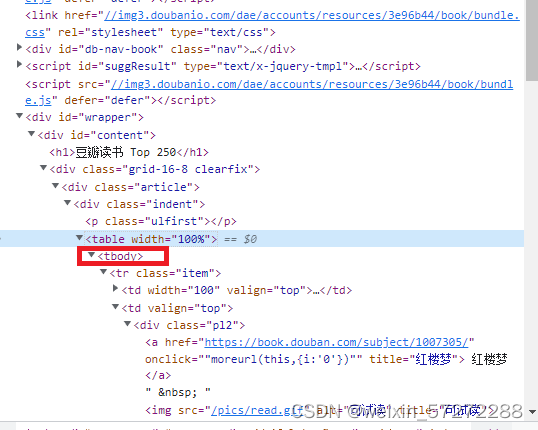
但是用requests库爬取的时候它是空的
结论:在写xpath路径的时候 直接去掉tbody就可以了 : //[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a
因为浏览器会自动添加tbody这一个项目,所以以后要小心,它的出现!!!!

使用浏览器XPATH获取的路径://*[@id="content"]/div/div[1]/div/table[1]/tbody/tr/td[2]/div[1]/a
但是用requests库爬取的时候它是空的
结论:在写xpath路径的时候 直接去掉tbody就可以了 : //[@id="content"]/div/div[1]/div/table[1]/tr/td[2]/div[1]/a
因为浏览器会自动添加tbody这一个项目,所以以后要小心,它的出现!!!!
 472
1280
472
1280











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























