







并发
并发:介绍
线程(thread)
经典观点是一个程序只有一个执行点(一个程序计数器,用来存放要执行的指令),但多线程(multi-threaded)程序会有多个执行点(多个程序计数器,每个都用于取指令和执行)。换一个角度来看,每个线程类似于独立的进程,只有一点区别:它们共享地址空间,从而能够访问相同的数据。
线程有一个程序计数器(PC),记录程序从哪里获取指令。每个线程有自己的一组用于计算的寄存器。所以,如果有两个线程运行在一个处理器上,从运行一个线程(T1)切换到另一个线程(T2)时,必定发生上下文切换(context switch)。线程之间的上下文切换类似于进程间的上下文切换。对于进程,我们将状态保存到进程控制块(Process Control Block,PCB)。现在,我们需要一个或多个线程控制块(Thread Control Block,TCB),保存每个线程的状态。但是,与进程相比,线程之间的上下文切换有一点主要区别:地址空间保持不变(即不需要切换当前使用的页表)。
线程和进程之间的另一个主要区别在于栈。在简单的传统进程地址空间模型 [我们现在可以称之为单线程(single-threaded)进程] 中,只有一个栈,通常位于地址空间的底部

在多线程的进程中,每个线程独立运行,当然可以调用各种例程来完成正在执行的任何工作。不是地址空间中只有一个栈,而是每个线程都有一个栈。
1.1 实例:线程创建
主程序创建了两个线程,分别执行函数mythread(),但是传入不同的参数(字符串类型的A或者B)。一旦线程创建,可能会立即运行(取决于调度程序的兴致),或者处于就绪状态,等待执行。创建了两个线程(T1和T2)后,主程序调用pthread_join(),等待特定线程完成。
1 #include <stdio.h>
2 #include <assert.h>
3 #include <pthread.h>
4
5 void *mythread(void *arg) {
6 printf("%s\n", (char *) arg);
7 return NULL;
8 }
9
10 int
11 main(int argc, char *argv[]) {
12 pthread_t p1, p2;
13 int rc;
14 printf("main: begin\n");
15 rc = pthread_create(&p1, NULL, mythread, "A"); assert(rc == 0);
16 rc = pthread_create(&p2, NULL, mythread, "B"); assert(rc == 0);
17 // join waits for the threads to finish
18 rc = pthread_join(p1, NULL); assert(rc == 0);
19 rc = pthread_join(p2, NULL); assert(rc == 0);
20 printf("main: end\n");
21 return 0;
22 }
这个小程序的可能执行顺序
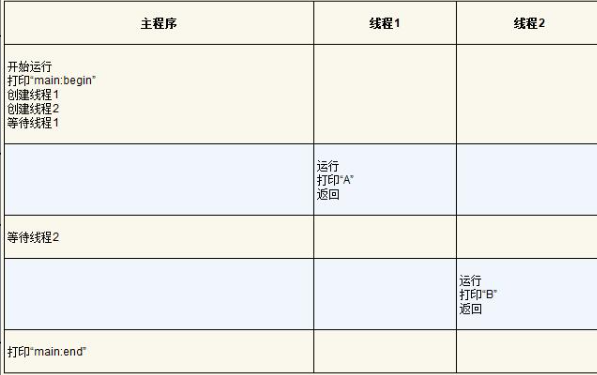
但请注意,这种排序不是唯一可能的顺序。实际上,给定一系列指令,有很多可能的顺序,这取决于调度程序决定在给定时刻运行哪个线程。例如,创建一个线程后,它可能会立即运行,这将导致表26.2中的执行顺序。
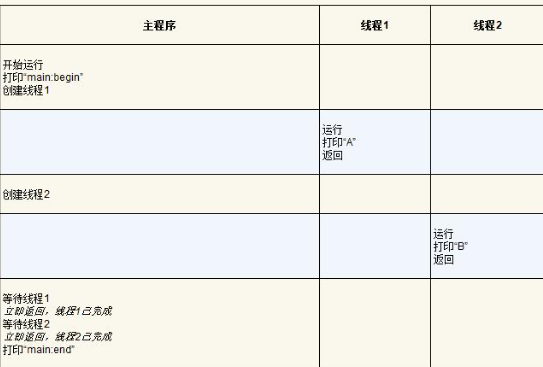
我们甚至可以在“A”之前看到“B”,即使先前创建了线程1,如果调度程序决定先运行线程2,没有理由认为先创建的线程先运行。
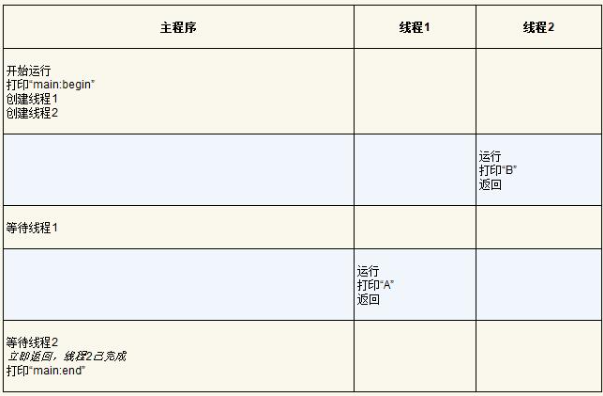
线程创建有点像进行函数调用。然而,并不是首先执行函数然后返回给调用者,而是为被调用的例程创建一个新的执行线程,它可以独立于调用者运行,可能在从创建者返回之前运行,但也许会晚得多。
1.2 为什么更糟糕:共享数据
1 #include <stdio.h>
2 #include <pthread.h>
3 #include "mythreads.h"
4
5 static volatile int counter = 0;
6
7 //
8 // mythread()
9 //
10 // Simply adds 1 to counter repeatedly, in a loop
11 // No, this is not how you would add 10,000,000 to
12 // a counter, but it shows the problem nicely.
13 //
14 void *
15 mythread(void *arg)
16 {
17 printf("%s: begin\n", (char *) arg);
18 int i;
19 for (i = 0; i < 1e7; i++) {
20 counter = counter + 1;
21 }
22 printf("%s: done\n", (char *) arg);
23 return NULL;
24 }
25
26 //
27 // main()
28 //
29 // Just launches two threads (pthread_create)
30 // and then waits for them (pthread_join)
31 //
32 int
33 main(int argc, char *argv[])
34 {
35 pthread_t p1, p2;
36 printf("main: begin (counter = %d)\n", counter);
37 Pthread_create(&p1, NULL, mythread, "A");
38 Pthread_create(&p2, NULL, mythread, "B");
39
40 // join waits for the threads to finish
41 Pthread_join(p1, NULL);
42 Pthread_join(p2, NULL);
43 printf("main: done with both (counter = %d)\n", counter);
44 return 0;
45 }
以下是关于代码的一些说明。首先,如Stevens建议的[SR05],我们封装了线程创建和合并例程,以便在失败时退出。对于这样简单的程序,我们希望至少注意到发生了错误(如果发生了错误),但不做任何非常聪明的处理(只是退出)。因此,Pthread_create()只需调用pthread_create(),并确保返回码为0。如果不是,Pthread_create()就打印一条消息并退出。
其次,我们没有用两个独立的函数作为工作线程,只使用了一段代码,并向线程传入一个参数(在本例中是一个字符串),这样就可以让每个线程在打印它的消息之前,打印不同的字母。
最后,最重要的是,我们现在可以看看每个工作线程正在尝试做什么:向共享变量计数器添加一个数字,并在循环中执行1000万(107)次。因此,预期的最终结果是:20000000。


每次运行不但会产生错误,而且得到不同的结果!
1.3 核心问题:不可控的调度
编译器为更新计数器生成的代码序列。编译器为更新计数器生成的代码序列。
mov 0x8049a1c, %eax
add $0x1, %eax
mov %eax, 0x8049a1c
这个例子假定,变量counter位于地址0x8049a1c。在这3条指令中,先用x86的mov指令,从内存地址处取出值,放入eax。然后,给eax寄存器的值加1(0x1)。最后,eax的值被存回内存中相同的地址。
设想我们的两个线程之一(线程1)进入这个代码区域,并且因此将要增加一个计数器。它将counter的值(假设它这时是50)加载到它的寄存器eax中。因此,线程1的eax = 50。然后它向寄存器加1,因此eax = 51。现在,一件不幸的事情发生了:时钟中断发生。因此,操作系统将当前正在运行的线程(它的程序计数器、寄存器,包括eax等)的状态保存到线程的TCB。
现在更糟的事发生了:线程2被选中运行,并进入同一段代码。它也执行了第一条指令,获取计数器的值并将其放入其eax中 [请记住:运行时每个线程都有自己的专用寄存器。上下文切换代码将寄存器虚拟化(virtualized),保存并恢复它们的值]。此时counter的值仍为50,因此线程2的eax = 50。假设线程2执行接下来的两条指令,将eax递增1(因此eax = 51),然后将eax的内容保存到counter(地址0x8049a1c)中。因此,全局变量counter现在的值是51。
最后,又发生一次上下文切换,线程1恢复运行。还记得它已经执行过mov和add指令,现在准备执行最后一条mov指令。回忆一下,eax=51。因此,最后的mov指令执行,将值保存到内存,counter再次被设置为51。
简单来说,发生的情况是:增加counter的代码被执行两次,初始值为50,但是结果为51。这个程序的“正确”版本应该导致变量counter等于52。
由于执行这段代码的多个线程可能导致竞争状态,因此我们将此段代码称为临界区(critical section)。临界区是访问共享变量(或更一般地说,共享资源)的代码片段,一定不能由多个线程同时执行。
1.4 原子性愿望
解决这个问题的一种途径是拥有更强大的指令,单步就能完成要做的事,从而消除不合时宜的中断的可能性。
因此,我们要做的是要求硬件提供一些有用的指令,可以在这些指令上构建一个通用的集合,即所谓的同步原语(synchronization primitive)。通过使用这些硬件同步原语,加上操作系统的一些帮助,我们将能够构建多线程代码,以同步和受控的方式访问临界区,从而可靠地产生正确的结果—— 尽管有并发执行的挑战。
提示:使用原子操作
原子操作是构建计算机系统的最强大的基础技术之一,从计算机体系结构到并行代码(我们在这里研究的内容)、文件系统(我们将很快研究)、数据库管理系统,甚至分布式系统。
将一系列动作原子化(atomic)背后的想法可以简单用一个短语表达:“全部或没有”。看上去,要么你希望组合在一起的所有活动都发生了,要么它们都没有发生。不会看到中间状态。有时,将许多行为组合为单个原子动作称为事务(transaction),这是一个在数据库和事务处理世界中非常详细地发展的概念。
2 锁
2.1 锁的基本思想
举个例子,假设临界区像这样,典型的更新共享变量:
balance = balance + 1;
1 lock_t mutex; // some globally-allocated lock 'mutex'
2 ...
3 lock(&mutex);
4 balance = balance + 1;
5 unlock(&mutex);
锁就是一个变量,因此我们需要声明一个某种类型的锁变量(lock variable,如上面的mutex),才能使用。这个锁变量(简称锁)保存了锁在某一时刻的状态。它要么是可用的(available,或unlocked,或free),表示没有线程持有锁,要么是被占用的(acquired,或locked,或held),表示有一个线程持有锁,正处于临界区。我们也可以保存其他的信息,比如持有锁的线程,或请求获取锁的线程队列,但这些信息会隐藏起来,锁的使用者不会发现。
调用lock()尝试获取锁,如果没有其他线程持有锁(即它是可用的),该线程会获得锁,进入临界区
2.2 Pthread锁
1 pthread_mutex_t lock = PTHREAD_MUTEX_INITIALIZER;
2
3 Pthread_mutex_lock(&lock); // wrapper for pthread_mutex_lock()
4 balance = balance + 1;
5 Pthread_mutex_unlock(&lock);
POSIX的lock和unlock函数会传入一个变量,因为我们可能用不同的锁来保护不同的变量。这样可以增加并发:不同于任何临界区都使用同一个大锁(粗粒度的锁策略),通常大家会用不同的锁保护不同的数据和结构,从而允许更多的线程进入临界区(细粒度的方案)。
2.4 评价锁
在实现锁之前,我们应该首先明确目标,因此我们要问,如何评价一种锁实现的效果。为了评价锁是否能工作(并工作得好),我们应该先设立一些标准。第一是锁是否能完成它的基本任务,即提供互斥(mutual exclusion)。最基本的,锁是否有效,能够阻止多个线程进入临界区?
第二是公平性(fairness)。当锁可用时,是否每一个竞争线程有公平的机会抢到锁?用另一个方式来看这个问题是检查更极端的情况:是否有竞争锁的线程会饿死(starve),一直无法获得锁?
最后是性能(performance),具体来说,是使用锁之后增加的时间开销。有几种场景需要考虑。一种是没有竞争的情况,即只有一个线程抢锁、释放锁的开支如何?另外一种是一个CPU上多个线程竞争,性能如何?最后一种是多个CPU、多个线程竞争时的性能
2.5 控制中断
最早提供的互斥解决方案之一,就是在临界区关闭中断。
1 void lock() {
2 DisableInterrupts();
3 }
4 void unlock() {
5 EnableInterrupts();
6 }
假设我们运行在这样一个单处理器系统上。通过在进入临界区之前关闭中断(使用特殊的硬件指令),可以保证临界区的代码不会被中断,从而原子地执行。结束之后,我们重新打开中断(同样通过硬件指令),程序正常运行。
优点
没有中断,线程可以确信它的代码会继续执行下去,不会被其他线程干扰
缺点
- 第一,一个贪婪的程序可能在它开始时就调用lock(),从而独占处理器。更糟的情况是,恶意程序调用lock()后,一直死循环。后一种情况,系统无法重新获得控制,只能重启系统。关闭中断对应用要求太多,不太适合作为通用的同步解决方案。
- 第二,这种方案不支持多处理器。如果多个线程运行在不同的CPU上,每个线程都试图进入同一个临界区,关闭中断也没有作用。线程可以运行在其他处理器上,因此能够进入临界区。多处理器已经很普遍了,我们的通用解决方案需要更好一些。
- 第三,关闭中断导致中断丢失,可能会导致严重的系统问题。假如磁盘设备完成了读取请求,但CPU错失了这一事实,那么,操作系统如何知道去唤醒等待读取的进程?
- 最后一个不太重要的原因就是效率低。与正常指令执行相比,现代CPU对于关闭和打开中断的代码执行得较慢。
2.6 测试并设置指令(原子交换)
因为关闭中断的方法无法工作在多处理器上,所以系统设计者开始让硬件支持锁。
最简单的硬件支持是测试并设置指令(test-and-set instruction),也叫作原子交换(atomic exchange)
1 typedef struct lock_t { int flag; } lock_t;
2
3 void init(lock_t *mutex) {
4 // 0 -> lock is available, 1 -> held
5 mutex->flag = 0;
6 }
7
8 void lock(lock_t *mutex) {
9 while (mutex->flag == 1) // TEST the flag
10 ; // spin-wait (do nothing)
11 mutex->flag = 1; // now SET it!
12 }
13
14 void unlock(lock_t *mutex) {
15 mutex->flag = 0;
16 }
当第一个线程正处于临界区时,如果另一个线程调用lock(),它会在while循环中自旋等待(spin-wait),直到第一个线程调用unlock()清空标志。然后等待的线程会退出while循环,设置标志,执行临界区代码。
遗憾的是,这段代码有两个问题:正确性和性能。
2.7 实现可用的自旋锁
1 int TestAndSet(int *old_ptr, int new) {
2 int old = *old_ptr; // fetch old value at old_ptr
3 *old_ptr = new; // store 'new' into old_ptr
4 return old; // return the old value
5 }
测试并设置指令做了下述事情。它返回old_ptr指向的旧值,同时更新为new的新值。当然,关键是这些代码是原子地(atomically)执行。因为既可以测试旧值,又可以设置新值,所以我们把这条指令叫作“测试并设置”。这一条指令完全可以实现一个简单的自旋锁(spin lock)。
1 typedef struct lock_t {
2 int flag;
3 } lock_t;
4
5 void init(lock_t *lock) {
6 // 0 indicates that lock is available, 1 that it is held
7 lock->flag = 0;
8 }
9
10 void lock(lock_t *lock) {
11 while (TestAndSet(&lock->flag, 1) == 1)
12 ; // spin-wait (do nothing)
13 }
14
15 void unlock(lock_t *lock) {
16 lock->flag = 0;
17 }
2.8 评价自旋锁
锁最重要的一点是正确性(correctness):能够互斥吗?答案是可以的:自旋锁一次只允许一个线程进入临界区。因此,这是正确的锁。
下一个标准是公平性(fairness)。自旋锁对于等待线程的公平性如何呢?能够保证一个等待线程会进入临界区吗?答案是自旋锁不提供任何公平性保证。实际上,自旋的线程在竞争条件下可能会永远自旋。自旋锁没有公平性,可能会导致饿死。
2.9 比较并交换
1 int CompareAndSwap(int *ptr, int expected, int new) {
2 int actual = *ptr;
3 if (actual == expected)
4 *ptr = new;
5 return actual;
6 }
比较并交换的基本思路是检测ptr指向的值是否和expected相等;如果是,更新ptr所指的值为新值。否则,什么也不做。不论哪种情况,都返回该内存地址的实际值,让调用者能够知道执行是否成功。
如何让锁不会不必要地自旋,浪费CPU时间?
2.13 简单方法:让出来吧,宝贝
如果临界区的线程发生上下文切换,其他线程只能一直自旋,等待被中断的(持有锁的)进程重新运行。有什么好办法
1 void init() {
2 flag = 0;
3 }
4
5 void lock() {
6 while (TestAndSet(&flag, 1) == 1)
7 yield(); // give up the CPU
8 }
9
10 void unlock() {
11 flag = 0;
12 }
在这种方法中,我们假定操作系统提供原语yield(),线程可以调用它主动放弃CPU,让其他线程运行。线程可以处于 3 种状态之一(运行、就绪和阻塞)。yield()系统调用能够让运行(running)态变为就绪(ready)态,从而允许其他线程运行。因此,让出线程本质上取消调度(deschedules)了它自己。
现在来考虑许多线程(例如100个)反复竞争一把锁的情况。在这种情况下,一个线程持有锁,在释放锁之前被抢占,其他99个线程分别调用lock(),发现锁被抢占,然后让出CPU。假定采用某种轮转调度程序,这99个线程会一直处于运行—让出这种模式,直到持有锁的线程再次运行。虽然比原来的浪费99个时间片的自旋方案要好,但这种方法仍然成本很高,上下文切换的成本是实实在在的,因此浪费很大。
更糟的是,我们还没有考虑饿死的问题。一个线程可能一直处于让出的循环,而其他线程反复进出临界区。很显然,我们需要一种方法来解决这个问题。
2.14 使用队列:休眠替代自旋
调度程序决定如何调度。如果调度不合理,线程或者一直自旋(第一种方法),或者立刻让出CPU(第二种方法)。无论哪种方法,都可能造成浪费,也能防止饿死。
因此,我们必须显式地施加某种控制,决定锁释放时,谁能抢到锁。为了做到这一点,我们需要操作系统的更多支持,并需要一个队列来保存等待锁的线程。
1 typedef struct lock_t {
2 int flag;
3 int guard;
4 queue_t *q;
5 } lock_t;
6
7 void lock_init(lock_t *m) {
8 m->flag = 0;
9 m->guard = 0;
10 queue_init(m->q);
11 }
12
13 void lock(lock_t *m) {
14 while (TestAndSet(&m->guard, 1) == 1)
15 ; //acquire guard lock by spinning
16 if (m->flag == 0) {
17 m->flag = 1; // lock is acquired
18 m->guard = 0;
19 } else {
20 queue_add(m->q, gettid());
21 m->guard = 0;
22 park();
23 }
24 }
25
26 void unlock(lock_t *m) {
27 while (TestAndSet(&m->guard, 1) == 1)
28 ; //acquire guard lock by spinning
29 if (queue_empty(m->q))
30 m->flag = 0; // let go of lock; no one wants it
31 else
32 unpark(queue_remove(m->q)); // hold lock (for next thread!)
33 m->guard = 0;
34 }
在这个例子中,我们做了两件有趣的事。首先,我们将之前的测试并设置和等待队列结合,实现了一个更高性能的锁。其次,我们通过队列来控制谁会获得锁,避免饿死。















 994
994











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









