







数据库的本质:
-
一种可以永久保存、查询速度快的数据存储的数据存储的方式。
数据库服务器的三种连接方法:
-
通过管理服务打开

-
通过图形用户界面(navicat)打开。
-
通过任务栏的上三角符号打开。

关系图:

数据库:
table:
-
每一行称为一个记录
-
每一列称为一个字段
-
一般要指定有多少列,不需要指定有都多少行
关于对数据库操作的基本命令:
-
显示数据库服务器上的所有的数据库文件:show databases 数据库名字
-
创建数据库:creat database 数据库名字
-
删除数据库; drop database 数据库名字
- 切换数据库:use database 数据库的名字

图形用户界面创建:

SQL语法:
-
关键字不区分大小写,一般小写
-
sql语句不能重复运行
SQL语法的分类:
-
Data Definition Language (DDL 数据定义语言) 如:建库,建表。
-
Data Manipulation Language(DML 数据操纵语言),如:对表中的记录操作增删改。
-
Data Query Language(DQL 数据查询语言),如:对表中的查询操作。
-
Data Control Language(DCL 数据控制语言),如:对用户权限的设置。
数据类型:

DDL:
创建表table:

注意:
- 日期的数据类型可以传字符串,比较日期的时候,比较字符串即可 。
- 对于字段来说,多个约束是可以同时存在的,比如stu_id 。
复制表的内容:
查看表结构(表头):
desc 表名;
删除表:
drop table if exists 表名;
修改表结构(alter):
注意:这个是对列的操作。
DDM:(修改记录)
增加:(insert into---values)

指定主键的序列后,当再次添加的时候,就会从指定的主键序列开始 .
修改:(update---set)

删除:(delete from---where)
注意:如果删除的时候不加where筛选条件,就会把整个表给删了,且这种删除是保留主键序列的(也就是如果再添加新的行,则主键不是从一开始,而是接着原来的序列)
truncate 是不保留主键序列的:

逻辑删除:

数据约束:
注意:null就是代表没有值,不存在重复的问题
 在创建表的时候添加约束:(多个约束可以修饰一个)
在创建表的时候添加约束:(多个约束可以修饰一个)

拥有主键自增的列(只能是整数int),全部插入元素的时候,主键是null。

在已有表中操作主键:
-- 删除 st5 表的主键
alter table st5 drop primary key;
-- 添加主键
alter table st5 add primary key(id);
外键约束:
- 是什么:外键是表和表直接产生关系的途径。外键连接的从表的某一列只能是主表的主键值的某一个。主表只能有一个,从表可以有多个,外键是连接主表和从表之间的桥梁。
- 创建表时创立外键:[CONSTRAINT] [ 外键约束名称] FOREIGN KEY( 外键字段名) REFERENCES 主表名(主键字段名)
- 已有表中创立外键:ALTER TABLE 从表 ADD [CONSTRAINT] [ 外键约束名称] FOREIGN KEY ( 外键字段名) REFERENCES 主表( 主键字段名);
- 级联操作: 在修改和删除主表的主键时,同时更新或删除副表的外键值,称为级联操作
| 级联操作语法 | 描述 |
| ON UPDATE CASCADE | 级联更新,只能是创建表的时候创建级联关系。更新主表中的主键,从表中的外键 列也自动同步更新 |
| ON DELETE CASCADE | 级联删除 |
| ON DELETE SET NULL | 删除时从表外键字段设置为NULL |
外键删除:ALTER TABLE 从表 drop foreign key 外键约束名称;
示范:(外键是在从表上面创建的)
创建主表B:

创建从表A:(设置了级联删除和级联更新)
从表插入值:

删除:

DQL :(查询)
基本语法:
SELECT [ALL | DISTINCT]
{* | table.* | [table.field1[as alias1][,table.field2[as alias2]][,...]]}
FROM table_name [as table_alias]
[left | right | inner join table_name2] -- 联合查询
[WHERE ...] -- 指定结果需满足的条件
[GROUP BY ...] -- 指定结果按照哪几个字段来分组
[HAVING] -- 过滤分组的记录必须满足的次要条件
[ORDER BY ...] -- 指定查询记录按一个或多个条件排序
[LIMIT {[offset,]row_count | row_countOFFSET offset}];
-- 指定查询的记录从哪条至哪条
注意 : [ ] 括号代表可选的 , { }括号代表必选得where和having的区别:where是拆分计算前,根据条件筛选。having是合并时候,根据对表的要求筛选。
-- 查询不同课程的平均分,最高分,最低分
-- 前提:根据不同的课程进行分组
SELECT subjectname,AVG(studentresult) AS 平均分,MAX(StudentResult) AS 最高分,MIN(StudentResult) AS 最低分
FROM result AS r
INNER JOIN `subject` AS s
ON r.subjectno = s.subjectno
GROUP BY r.subjectno
HAVING 平均分>80;
/*
where写在group by前面.
要是放在分组后面的筛选
要使用HAVING..
因为having是从前面筛选的字段再筛选,而where是从数据表中的字段直接进行的筛选的
*/
distinct关键字(去重)select distinct sex from emp;(性别相同的将会删除)
like关键字:(模糊查询)
SELECT * FROM 表名 WHERE 字段名 LIKE '通配符字符串';
| % | 匹配多个字符 |
| _ | 匹配一个字符 |
降序排列和升序排列:(类似于介词短语)
- asc:升序;
- desc:降序;

组合排序:并列的先按前者排序,前者相同的情况下,再按后者排序。
desc:(还有个意思是表示查看表结构)
聚合函数查询:(纵向查询==>用于统计个数)
五个聚合函数:
| SQL中的聚合函数 | 作用 |
| max( 列名) | 求这一列的最大值 |
| min( 列名) | 求这一列的最小值 |
| avg( 列名) | 求这一列的平均值 |
| count( 列名) | 统计这一列有多少条记录 |
| sum( 列名) | 对这一列求总和 |

注意:如果统计的某一列有NULL(空),那么函数不会统计在内的。对于统计count(*)来说,只有某一行的全部都是空,才不统计在内。
关于NUll运算:null和其他的所有的数据计算后的结果仍然是null,所以在某些情况下需要把NULL转化成0或者1.采用ifnull(a,b)语句,当false的时候,这个就是a,当是true的时候,这个就是b;

分组:group by----(类似介词短语)

注意:where在group by的前面。
分页查询:limit x,y(其中x代表这一页的起始页,y代表这一页有多少记录)(类似介词短语)
??????注意:索引是从0开始的。

下面这个是先把整张表按照hiredate降序排列的,然后再分页的。
索引:(加速查询)看这个吧:狂神说MySQL学习笔记_兴趣使然的草帽路飞-CSDN博客_狂神说mysql笔记 https://blog.csdn.net/weixin_43591980/article/details/109526825
https://blog.csdn.net/weixin_43591980/article/details/109526825
作用:
- 提高查询速度
- 确保数据的唯一性
- 可以加速表和表之间的连接 , 实现表与表之间的参照完整性
- 使用分组和排序子句进行数据检索时 , 可以显著减少分组和排序的时间
- 全文检索字段进行搜索优化.

手动创建索引:
DCL:
我们现在默认使用的都是 root 用户,超级管理员,拥有全部的权限。但是,一个公司里面的数据库服务器上面
可能同时运行着很多个项目的数据库。所以,我们应该可以根据不同的项目建立不同的用户,分配不同的权限来管理和维护数据库。
- 语法:
| CREATE USER ' 用户名'@' 主机名' IDENTIFIED BY '密码’; |
- 关键字说明:
| 关键字 | 说明 |
| ' 用户名' | 将创建的用户名 |
| ' 主机名' | 指定该用户在哪个主机上可以登陆,如果是本地用户可用 localhost,如果想让该用户可以从任意远程主机登陆,可以使用通配符% |
| ' 密码' | 该用户的登陆密码,密码可以为空,如果为空则该用户可以不需要密码登陆服务器 |
演示:
| # 创建 user1 用户,只能在 localhost 这个服务器登录 mysql 服务器,密码为 123 # 创建 user2 用户可以在任何电脑上登录 mysql 服务器,密码为 123 create user 'user2'@'%' identified by '123'; |
注:创建的用户名都在 mysql 数据库中的 user 表中可以查看到,密码经过了加密。
- 删除用户语法:
| DROP USER ' 用户名'@' 主机名'; |
演示:
| # 删除用户user2 drop user 'user2'@'%'; |
- 授权
- 用户创建之后,没什么权限!需要给用户授权
| GRANT 权限 1, 权限 2... ON 数据库名. 表名 TO ' 用户名'@' 主机名’; |
- 关键字说明:
| 关键字 | 说明 |
| GRANT…ON…TO | 授权关键字 |
| 权限 | 授予用户的权限,如 CREATE、ALTER、SELECT、INSERT、UPDATE 等。如果要授 予所有的权限则使用 ALL |
| 数据库名. 表名 | 该用户可以操作哪个数据库的哪些表。如果要授予该用户对所有数据库和表的相应操作权限则可用*表示,如*.* |
| ' 用户名'@' 主机名' | 给哪个用户授权,注:有 2 对单引号 |
演示:
| # 给 user1 用户分配对 demo这个数据库操作的权限:创建表,修改表,插入记录,更新记录,查询 grant create,alter,insert,update,select on demo.* to 'user1'@'localhost'; # 给 user2 用户分配所有权限,对所有数据库的所有表 grant all on *.* to 'user2'@'%'; |
- 撤销授权语法:
| REVOKE 权限 1, 权限 2... ON 数据库. 表名 revoke all on test.* from 'user1'@'localhost'; ' 用户名'@' 主机名'; |
| 关键字 | 说明 |
| REVOKE…ON…FROM | 撤销授权的关键字 |
| 权限 | 用户的权限,如 CREATE、ALTER、SELECT、INSERT、UPDATE 等,所有的权 限则使用 ALL |
| 数据库名. 表名 | 对哪些数据库的哪些表,如果要取消该用户对所有数据库和表的操作权限则可用*表示,如*.* |
| ' 用户名'@' 主机名' | 给哪个用户撤销 |
演示:
| # 撤销 user1 用户对 demo数据库所有表的操作的权限 revoke all on demo.* from 'user1'@'localhost'; |
- 查看权限语法:
| SHOW GRANTS FOR ' 用户名'@'主机名’; |
演示:
| # 查看 user1 用户的权限 show grants for 'user1'@'localhost'; |
- 修改密码
- 语法:
| ALTER user '用户名'@'主机名' IDENTIFIED by '新密码'; |
演示:
| # 修改root用户的密码为 root alter user 'root'@'localhost' IDENTIFIED by 'root'; |
MYSQL8 版本下 账户的密码 加密规则 要改一下
| alter user 'root'@'localhost' IDENTIFIED with mysql_native_password by 'root'; |
| 我们使用root账户 来创建用户 和 给其授权 , 授权本身也是个权限. 如果我们想要把授权这个权限 给 普通用户 , Grant ................................................to 用户@主机地址 with grant option |
多表查询:
举例:
# 创建部门表
create table dept01(
id int primary key auto_increment,
name varchar(20)
);
insert into dept01 (name) values ('开发部'),('市场部'),('财务部');
# 创建员工表
create table emp01 (
id int primary key auto_increment,
name varchar(10),
gender char(1), -- 性别
salary double, -- 工资
join_date date, -- 入职日期
dept_id int,
CONSTRAINT fx foreign key (dept_id) references dept01(id) -- 外键,关联部门表(部门表的主键)
);
insert into emp01(name,gender,salary,join_date,dept_id) values('孙悟空','男',7200,'2013-02-24',1);
insert into emp01(name,gender,salary,join_date,dept_id) values('猪八戒','男',3600,'2010-12-02',2);
insert into emp01(name,gender,salary,join_date,dept_id) values('唐僧','男',9000,'2008-08-08',2);
insert into emp01(name,gender,salary,join_date,dept_id) values('白骨精','女',5000,'2015-10-07',3);
insert into emp01(name,gender,salary,join_date,dept_id) values('蜘蛛精','女',4500,'2011-03-14',1);
select * from emp01,dept01;#两张表会产生笛卡尔积
select * from emp01,dept01 where emp01.dept_id = dept01.id;#过滤
select emp01.name, dept01.name from emp01,dept01 where emp01.dept_id = dept01.id;

1.内连接:用左边表的记录去匹配右边表的记录,如果符合条件的则显示(左表的每一行都要扫描右边的全部行)。如:从表.外键=主表.主键(上述的查询就是通过隐式内连接查询的)
- 隐式内连接:SELECT 字段名 FROM 左表, 右表 WHERE 条件
- 显示内连接:SELECT 字段名 FROM 左表 [INNER] JOIN 右表 ON 条件 where 条件;(多个条件可以用where,也可以通过and)
- 两者是等价的。
select * from emp e inner join dept d on e.dept_id = d.id where e.name='唐僧';
注:(本质上是一模一样的,没什么区别)
2.外连接:
左外连接:SELECT 字段名 FROM 左表 LEFT [OUTER] JOIN 右表 ON 条件
右外连接: SELECT 字段名 FROM 左表 RIGHT [OUTER ]JOIN 右表 ON 条件
总结:
外连接相对于内连接来说,增加了在没有匹配的情况下,把某张表的全部信息显示出来。左外连接保证把左表的全部都显示出来,右外连接保证把右表的全部都显示出来。
注意:如果两个表之间没有外键约束,仍然是可以进行多表查询的。
子查询:(在主查询前先建个值|集合|表)
根据子查询的结果来分:
- 单列单行:SELECT 查询字段 FROM 表 WHERE 字段=(子查询);(当作值)
- 多列单行:SELECT 查询字段 FROM 表 WHERE 字段 IN (子查询);(当作集合)
- 多列多行: SELECT 查询字段 FROM (子查询) 表别名 WHERE 条件;(当作表)
查询 2011-1-1 以后入职的员工及其对应的部门:(三种查询的结果一样)
 注意:多行多列子查询当作表来用的时候,一定要取个别名。
注意:多行多列子查询当作表来用的时候,一定要取个别名。
练习:
表emp:
表dept:
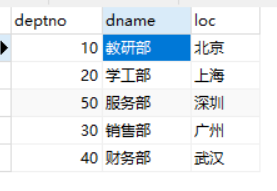
代码:(and符号最好别连用)
-- 1: 查询名字是三个字且薪资sal和奖金comm的和不低于30000的员工信息和其所在部门名字和地址
SELECT
emp.*, dept.dname,
dept.loc
FROM
emp
LEFT JOIN dept ON (sal + IFNULL(comm, 0)) > 30000
WHERE
emp.deptno = dept.deptno
AND ename LIKE '___';
-- 2: 查询emp中每个部门号,该部门中所有员工的薪资和,该部门的部门名字 ,工资和升序排列.
SELECT
h.deptno,
h.dname,
IFNULL(h.summ, 0) AS '工资和'
FROM
(
SELECT
dept.deptno,
dname,
sum(sal) summ
FROM
dept
LEFT JOIN emp ON emp.deptno = dept.deptno
GROUP BY
emp.deptno
) h
ORDER BY
h.summ ASC;
-- 或者:
SELECT
dept.deptno,
dname,
sum(sal) summ
FROM
dept
LEFT JOIN emp ON emp.deptno = dept.deptno
GROUP BY
emp.deptno
ORDER BY
summ DESC;
-- 3: 查询emp中各个部门号,部门中文员的个数,部门所在地点和部门名字.
SELECT
dept.deptno,
dname,
count(job) '文员个数'
FROM
dept
LEFT JOIN emp ON emp.deptno = dept.deptno
AND job = '文员'
GROUP BY
emp.deptno;
-- 4: 查询emp中各个部门号,部门所有薪资和,部门所在地点,只显示薪资和最高的两个部门的信息.
SELECT
dept.deptno,
loc,
dname,
sum(sal) '工资和'
FROM
dept
LEFT JOIN emp ON emp.deptno = dept.deptno
GROUP BY
dept.deptno
ORDER BY
'工资和' DESC
LIMIT 0,
2 -- 5: 查询emp中每个员工名字,员工入职日期,员工薪水,他领导的名字,领导的入职日期,领导的薪水
SELECT
ee.ename,
ee.hiredate,
ee.sal,
eer.ename,
eer.hiredate,
eer.sal
FROM
emp ee
LEFT JOIN emp eer ON ee.mgr = eer.empno;
-- 6: 在第5题的基础上查询出那些入职日期早于他领导且薪水低于领导的员工的信息.
SELECT
ee.ename,
ee.hiredate,
ee.sal
FROM
emp ee
LEFT JOIN emp eer ON ee.mgr = eer.empno
WHERE
ee.hiredate > eer.hiredate
AND ee.sal < eer.sal;
-- 7: 在第6题的基础上继续查询员工所在的部门名字和部门地点.
SELECT
e.*, dept.dname,
dept.loc
FROM
(
SELECT
ee.deptno,
ee.ename,
ee.hiredate,
ee.sal
FROM
emp ee
LEFT JOIN emp eer ON ee.mgr = eer.empno
WHERE
ee.hiredate > eer.hiredate
AND ee.sal < eer.sal
) e
LEFT JOIN dept ON dept.deptno = e.deptno;
-- 或者:三表连接:注意where语句是最后写的
SELECT
ee.ename,
ee.hiredate,
ee.sal,
dept.dname,
dept.loc
FROM
emp ee
LEFT JOIN emp eer ON ee.mgr = eer.empno
LEFT JOIN dept ON ee.deptno = dept.deptno
WHERE
ee.hiredate > eer.hiredate
AND ee.sal < eer.sal;
-- 8: 查询emp中薪水高于所有文员薪水的员工信息.
SELECT
*
FROM
emp
WHERE
sal > (
SELECT
MAX(emp.sal)
FROM
emp
WHERE
job = '文员'
);
-- 或者:
SELECT
*
FROM
emp
WHERE
sal > ALL (
SELECT
sal
FROM
emp
WHERE
job = '文员'
);
-- 09:查找入职日期早于2007-05-01的员工信息
SELECT
*
FROM
emp
WHERE
hiredate < '2007-05-01';
-- 10:查询emp中各个职业中,入职日期早于2007-05-01的员工数量
SELECT
job,
COUNT(*)
FROM
emp
WHERE
hiredate < '2007-05-01'
GROUP BY
job;
-- 11:查询emp中各个部门里的最大工资和最小工资,并且按照最大工资和最小工资差降序排列
SELECT
emp.deptno,
dept.dname,
max(sal) '最高工资',
MIN(sal) '最小工资',
MAX(sal) - MIN(sal) '工资差'
FROM
dept
LEFT JOIN emp ON emp.deptno = dept.deptno
GROUP BY
emp.deptno
ORDER BY
(max(sal) - min(sal)) DESC;
-- 12:查询emp中经理和销售员的名字,薪水,奖金,部门名,部门地点,只查询月薪和奖金和最低的三个人的信息
SELECT
emp.ename,
emp.sal,
emp.comm,
dept.dname,
dept.loc,
sal + IFNULL(comm, 0) '奖金+工资'
FROM
emp
LEFT JOIN dept ON job = '经理'
OR '文员'
AND emp.deptno = dept.deptno
ORDER BY
(sal + IFNULL(comm, 0)) ASC
LIMIT 0,
3;总结:on --- where--- group by ---- order by ----
视图:(放置查询结果的)
创建:create or replace view 视图名 as 查询结果(with check option)??????
create or replace view ggg0
as SELECT ee.ename '雇员',ee.hiredate 'hiredate01',ee.sal 'sal01',eer.ename '雇主',eer.hiredate 'hiredate02',
eer.sal 'sal02'
FROM emp ee LEFT join emp eer on ee.mgr = eer.empno;
删除:drop view 视图名;
查看:show tables;
注意:
- 一张视图的字段名称是不允许重复的,但是我们在查询的时候可以(查询结果的字段会被修改)
- 视图的内容是会根据被查询表的内容的变化而变化的。
- 视图和普通的表一样,可以再经行查询。
SELECT * FROM ggg0 ORDER BY sal01 DESC;
数据库函数:
1.处理NULL的函数:
ifnull(exper1,exper2):如果exper1为null,则返回exper2,否则返回exper1
nullif(exper1,exper2):如果exper1和exper2相等,则返回null,否则返回exper1
if(exper1,exper2,exper3):类似于?:三目运算符,如果exper1为true,不等于0且不等于null,则返回exper2,否则返回exper3
isnull(exper1):判断exper1是否为null,如果为null作为查询结果返回为1 , null返回0
SELECT NULLIF(111,111);-- NULL
SELECT IFNULL(NULL,5);-- 5
-- 0或者null代表false,1代表true
SELECT IF(NULL,2,3);-- 3
SELECT IF(0,2,3);-- 3
SELECT IF(1,2,3);-- 2
-- 注意:sql语句中,布尔运算符等号是‘=’;
SELECT if(CHAR_LENGTH('123456') = 6,'111','222');--111
SELECT if(CHAR_LENGTH('123456') != 6,'111','222');--222
SELECT ISNULL(NULL);--12.case语句:(多重分支)
第一种用法:
case value
when compare_value1 then result1
when compare_value2 then result2
else result3
end
--compare_value1 和 compare_value2 都是值 ,
如果value和谁相等,就会执行then第二种用法:
case
when condition1 then result1
when condition2 then result2
……..
else result
end
condition1,2都是布尔表达式,所以比第一种方式更加的灵活示例:
3.常用的单行函数:
-- 01 char_length(str):计算字符长度:
SELECT
ename,
CHAR_LENGTH(ename) '长度'
FROM
emp;
#字符长度,不是字节
-- 02 date_add:增加某段时间后的日期
-- 使用date_add函数需要两个参数,日期、数值类型带单位
-- select date_add('1998-01-02',interval 12 month); -- year month day、
-- 查找员工工作十年后的日期:
SELECT
ename,
hiredate,
DATE_ADD(hiredate, INTERVAL 10 DAY)
FROM
emp;
-- 03 now() 表示当前的年月日时分秒
-- 查找入职时间大于十年的员工
SELECT
ename hiredate,
DATE_ADD(hiredate, INTERVAL 10 YEAR) '入职十年后的时间'
FROM
emp
WHERE
DATE_ADD(hiredate, INTERVAL 10 YEAR) < NOW();
-- 04 虚表dual,仅能出现这一次,当然也可以不写
SELECT
CURDATE(),
CURTIME(),
NOW()
FROM
DUAL;
-- 2021-09-07****12:05:21*****2021-09-07 12:05:21
SELECT
CURDATE(),
CURTIME(),
NOW();
-- 上述的虚表也可以不写其他函数:
uuid():同一列的uuid()是不会重复的;
ALTER TABLE emp ADD sss VARCHAR(40);
UPDATE emp SET sss = UUID();
事务:
特性:(ACID)
- 原子性(atomicity):要么成功,要么失败;
- 一致性(consistency):事务前后数据的完整性要保持一致
- 持久性(durability):事务一旦提交就不可逆被持久化到数据库。
- 隔离性(isolation):用户在操作事务 的时候,数据库为每一个用户开启一个事务,该事务不能被其他事务操作的数据所干扰。
由于隔离性差所导致的一些问题:
- 脏读:一个事务读取了另一个事务没有提交的数据。
- 不可重复读:在一个事务中,多次读取某一行的内容,但是读取的结果不一样。
- 幻读(虚读):一个事务读取到了别的事务插入的数据,导致前后读的不一样。
事务提交的基本语法
-- 使用set语句来改变自动提交模式
SET autocommit = 0; /*关闭*/
SET autocommit = 1; /*开启*/
-- 注意:
--- 1.MySQL中默认是自动提交
--- 2.使用事务时应先关闭自动提交
-- 开始一个事务,标记事务的起始点
START TRANSACTION
-- 提交一个事务给数据库
COMMIT
-- 将事务回滚,数据回到本次事务的初始状态
ROLLBACK
-- 还原MySQL数据库的自动提交
SET autocommit =1;
-- 保存点
SAVEPOINT 保存点名称 -- 设置一个事务保存点
ROLLBACK TO SAVEPOINT 保存点名称 -- 回滚到保存点
RELEASE SAVEPOINT 保存点名称 -- 删除保存点
转账实现:
CREATE TABLE if not EXISTS shiwu (
id INT PRIMARY KEY auto_increment,-- 被两个条件所约束
name VARCHAR(3) NOT NULL,
cash DECIMAL(7,2) not NULL
);
INSERT INTO shiwu (name,cash)
VALUES('A',2000.00),('B',10000.00);
-- 实现转账:
set autocommit = 0;
START TRANSACTION;
UPDATE shiwu SET cash=cash+500 WHERE name= 'A';
UPDATE shiwu SET cash=cash-500 WHERE name='B';
COMMIT;
ROLLBACK;
SET autocommit = 1;存储过程:
目的:为以后的使用而保存的一条或多条MySQL语句的集合。(可以理解成java中的方法)
格式:
drop procedure if exists 存储过程名;
create procedure 存储过程名(pram[参数列表])
begin
sql语句
end;
参数列表中 使用in关键字 表示入参 ,使用out关键字表示返回值
格式: in 参数 类型 out 参数 类型
调用:
call 存储过程名(入参1,入参2,....@返回值);
select @返回值;
-- 删除
drop procedure 存储过程名;示例:创建存储过程:
drop PROCEDURE IF EXISTS foo;
-- 创建函数:
CREATE PROCEDURE foo (in newname VARCHAR(20),in dis VARCHAR(100),OUT sum INT)
BEGIN
INSERT into tsinger(sname,display) VALUES (newname,dis);
SET sum = (SELECT COUNT(*) FROM tsinger);-- 赋值操作,一定要带括号
END;
-- 调用函数
call foo('lll','cekhhkb',@cou);
SELECT @cou;-- 查询返回值
注意:不是存储函数里面的sql语句(普通的sql语句)都是以分号结尾的,而在存储过程里面的sql语句在navicat里面是以分号结尾,其他软件不一定!!!
声明变量:
1.使用declare声明变量
declare 变量名 类型 default 初始值;
2.使用set声明变量, 变量的值可以来自于子查询
set @变量 = (查询);(注意:之后这个变量的使用要带有@)
赋值:
set 变量 = 值;
分支:
if 条件 then 操作 end if;
if 条件 then 操作 else 操作 end if;
注意:sql的分支语句没有if... if... else或者if...else if ... else...的分子语句,只有上述的两种。如果需要更多的分支,那么就需要用case...when语句。
循环:
- while语句
while 条件 do 操作 end while;
2.repeat语句 类似java里的do-while 不管条件成立与否首先执行一次
repeat 操作 until 条件 end repeat;
# 创建存储过程pro2, 指定姓名和描述新增歌手,返回salary为null的歌手数量
drop PROCEDURE if EXISTS pro2;
create procedure pro2(in spc_name varchar(20),in spc_display varchar(100),out count int)
BEGIN
# 指定的名字为null时 ,设置为系统测试+随机字符串
if ISNULL(spc_name)
then set spc_name = concat('系统测试',SUBSTR(UUID(),1,8));
end if;
insert into tsinger (sname , display) values (spc_name,spc_display);
set count = (select count(*) from tsinger where salary is null);
end;
# 存储过程3:修改salary为null的salary为 表中最小的salary
drop procedure if exists pro3;
create procedure pro3()
BEGIN
set @min_sal = (select min(salary) from tsinger);
update tsinger set salary = @min_sal where salary is null;
end;
call pro3();
# 存储过程4:按照指定的性别新增歌手
# 如果性别为'女',则设置salary为10000
# 如果性别为'男',则设置salary为表中最小的salary
drop PROCEDURE if EXISTS pro4;
CREATE PROCEDURE pro4(in sex char(1))
BEGIN
set @minsalary = (SELECT min(salary) from tsinger);
if(sex = '男') THEN
INSERT tsinger(sex,salary) VALUES ('男',@minsalary);
else
INSERT tsinger(sex,salary) VALUES ('女',10000) ;
end if;
end;
call pro5('男');
call pro4('女');
-- 使用case when 语句
drop PROCEDURE if EXISTS pro4;
create procedure pro5(in sex1 char(1))
BEGIN
DECLARE salary1 int DEFAULT 0;
set @minsalary = (SELECT min(salary) from tsinger);
case
when sex1 = '男' then set salary1 = @minsalary;
when sex1 = '女' then SET salary1 = 10000;
ELSE set salary1 = null;
end case;-- 与结束符冲突
INSERT into tsinger(sex,salary) VALUES (sex1,salary1);
end;
# 存储过程5: 插入指定数量的记录到tsinger表中, 名字和描述采用uuid随机,性别依次为'女''男'
drop PROCEDURE IF EXISTS pro5;
create PROCEDURE pro5(in count int)
BEGIN
declare a int default 1;
declare gender char(1) default '女';
while a<=count DO
if a%2!=0 then set gender = '女';
else set gender = '男';
end if;
insert into tsinger (sname,sex,display) values (SUBSTR(UUID(),1,8),gender,UUID());
set a = a+1;
end while;
end;
call pro5(4);
# 存储过程6: 向tsinger表中插入指定数量的记录, sname采取随机
drop PROCEDURE if exists pro6;
create procedure pro6(in count int)
BEGIN
repeat
insert into tsinger (sname) values (SUBSTR(UUID(),1,8));
set count = count +1;
until count>=10 end repeat;
end;
# 100 已经满足 >=10 停止循环的条件 , 但还是执行一次
call pro6(100);总结:
- 写sql函数的时候,一般先通过declare或者set先声明变量,期间的绝大多数的操作都是对这些变量(begin,end里面声明的和形参)操作,最后再对具体表的具体字段和记录操作。
- sql存储过程中的形参和begin...end里面的值可以与操作表的字段名字相同,不过,最好还是不要相同
带有事务的存储过程:
设计一个存储过程带事务处理.
-- 修改tsinger表 指定sid的那条记录的display 为新指定的display,--可能会出错,所以需要建立事务
-- 修改tsinger表 薪水小于等于1万就乘以3,薪水大于1万就乘以0.9
-- 返回表中月薪大于1万的歌手总数.
drop PROCEDURE if EXISTS pro10;
CREATE PROCEDURE pro10 (in sidp INT,in newdisplay VARCHAR(20),OUT sum INT)
BEGIN
-- 声明状态变量:
DECLARE flag int DEFAULT 1;
-- 声明sql异常处理器,出现sql异常的时候,设flag = 0;
DECLARE CONTINUE HANDLER for SQLEXCEPTION SET flag = 0;
-- 事务:修改可能违反唯一约束
START TRANSACTION;
UPDATE tsinger SET display = newdisplay WHERE sid = sidp;
UPDATE tsinger set salary = salary *3 WHERE salary < 10000;
UPDATE tsinger set salary = salary*0.9 WHERE salary >10000;
if flag = 1 THEN
COMMIT;
ELSE
ROLLBACK;
end IF;
set sum = (SELECT COUNT(*) FROM tsinger WHERE salary>10000);
end;
call pro10(1002,'kkjg',@sum);
SELECT @sum;
游标:
# 存储过程中使用游标:
# 计算tsinger中salary的总和并返回,当记录中display为null时 就设置为随机字符串uuid
drop procedure if exists pro_cursor;
create procedure pro_cursor(out sum decimal(11,2))
BEGIN
declare flag int default 1;
declare singer_id int default 0;
declare singer_sal decimal(7,2) default 0;
declare singer_dis varchar(100) default '';-- ‘’等于null
# 声明游标cur1
declare cur1 cursor for select sid,salary,display from tsinger;-- 基于某次查询设立的游标
declare continue handler for not found set flag = 0;-- 设置一个处理器当找不到的时候
set sum = 0;
# 开启游标
open cur1;
# 从游标中取出数据
fetch cur1 into singer_id,singer_sal,singer_dis;
# 循环操作
while flag = 1 do
if singer_sal is not null then
set sum = sum + singer_sal;
end if;
if singer_dis is null then
update tsinger set display = UUID() where sid = singer_id;-- 不写where该字段全都会更新
end if;
# 游标继续向下走
fetch cur1 into singer_id,singer_sal,singer_dis;
end while;
# 关闭游标
close cur1;
end;
CALL pro_cursor(@summm);
SELECT @summm;触发器:(类似GUI里面的监听器)
创建:create trigger trigger_name trigger_time trigger_event on table_name for each row
触发器是与表操作相关的数据库对象,所以触发的命名与表相关,在创建触发器时需要指定表名table_name,表为永久性的表,所以触发器不能与临时表和视图建立关联。
trigger:创建触发器的关键字,定义触发器名称。
trigger_name:触发器的名称。
trigger_time:触发器的执行时间,它的值为before或者after,是指在激活它的语句之前还是之后执行。一般情况下是在激活它的语句运行完成后再执行触发器。
trigger_event:触发事件,它的值可以使insert、update、delete。在这个三个动作上我们需要了解数据库里两个临时的虚拟表:deleted、inserted,在mysql中使用old和new关键字来表示。(方言)(新表和老表字段的名字都和加了触发器的表一样的)。
for each row:对每行都添加触发操作,只要被更改了就触发。
对于每一行,先是感知是否有修改操作==>触发触发器==>前?后更新到表。
| 动作 | deleted表(old) | inserted表(new) |
| insert | 不存储记录 | 存储新插入的记录 |
| update | 存放之前的记录 | 存放更新后的记录 |
| delete | 存放被删除的记录 | 不存储记录 |
删除:drop trigger 触发器名字;
查看:show triggers;
drop table if exists trecord;
create table trecord(
rid varchar(32) primary key, -- 主键
sid int , -- 歌手id
sname varchar(20), -- 歌手名字
display varchar(100), -- 歌手描述
newdisplay varchar(100), -- 歌手新描述
updatetime datetime -- 修改时间
);
DROP TRIGGER update_display_record;
CREATE TRIGGER update_display_record AFTER UPDATE ON tsinger FOR EACH ROW
BEGIN
DECLARE rid VARCHAR (32) DEFAULT '';
SET rid = REPLACE (UUID(), '-', '');
INSERT INTO trecord
VALUES
(
rid,
old.sid,-- 这都是对应行的值
old.sname,
old.display,
new.display,
now()
);
END;示例:
设计一个触发器 , 在向tsinger表中插入数据时,如果salary没有给值或小于500,就赋值为1000.01,
-- 如果birthday没有给值,就赋值为当前日期
DROP TRIGGER if EXISTS pro9;
CREATE TRIGGER pro9 BEFORE INSERT ON tsinger FOR EACH row
BEGIN
if new.salary < 500 or new.salary is null THEN
SET new.salary = 1000.01;
end if;
if new.birthday is NULL then
set new.birthday = NOW();-- birthday是个字符串,所以是可以接日期的;
end if;
END;
INSERT into tsinger(salary,birthday) VALUES (500,NULL);
INSERT into tsinger(salary,birthday) VALUES (400,NULL);














 1704
1704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









