






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
本周开始一边学习python,一边学台湾大学李宏毅教授的《语音识别》课程,同时也会看几篇中文与语音识别相关的论文。
但由于新的认知,决定先放下《语音识别》,先学习吴恩达教授的《机器学习》。(9-21)
一、HUNG-YI LEE 《Speech Recognition》

Speech:一段声音会被表示为一串的向量,长度为T,宽度为d
Text:翻译之后的文字会被表示为Token(令牌,符号),有N个符号,有V种。
声音被机器录用后,会被分为几个小段Speech,接着被Speech Recognition翻译为几个Token,最后通过Token的字典,翻译成文字。
Token 词典
Phoneme:发音的基本单位,如音标 需要Lexicon(词典) 根据语音的发音,再词典种找到发音词,再从词典中连连看,找出对应的文字。
Grapheme:书写的基本单位,如26个英文字母+空格+标点符号;中文的常用字。每一个发音都有一个文字对应。缺点工作量大,有语音重复如 只、指、纸。
word:根据词直接查找字典,但一般不用,因为工作量十分大。
Morpheme:比word小,比Grapheme大,如unbreakable-> un break able .
Bytes: 用UTF-8表示,如01010101 表示 我,0101010100 表示 你 ;
Vector 声音

声音的截取是以 一个frame为单位,一个单位25ms,其中根据不同标准的取样,直接分为400个sample,宽度为39为一个小单位,宽度为80为一个小单位。
frame向前移动的时候,只会移动10ms,所以不断向前截取是会有重叠部分的。1m中会出现100个frame。

在声音片段的处理中,一般会处理为上面四种样式,波形Wave,声谱spectrogram,过滤器filter bank,和梅尔频率倒谱系数MFCC。(9月21日,目前都不认识这些取样方式,日后会再深入学习)
语音资料库:TIMIT(The DARPA TIMIT Acoustic-Phonetic Continuous Speech Corpus),是由德州仪器、麻省理工学院和SRI International合作构建的声学-音素连续语音语料库),LibriSpeech(开源)
二、Machine learning 机器学习
1.1 简言机器学习
Examples:
- Database mining 数据发掘
Large datasets from growth of automation/web. 从不断自动成长的网站中获取大量的数据
E.g., Web click data, medical records, biology, engineering 网络点击数据,医疗记录,生物学,工程 - Applications can’t program by hand.
E.g., Autonomous helicopter, handwriting recognition, most 自主直升机,手写识别,大多数自然语言处理(NLP),计算机视觉。
Natural Language Processing (NLP), Computer Vision. - Self-customizing programs
E.g., Amazon, Netflix product recommendations 亚马逊,Netflix产品建议,了解人类学习(大脑,真实的AL) - Understanding human learning (brain, real Al).
1.2 机器学习的定义
Tom Mitchell (1998) Well-posed Learning Problem: A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
简单而言就是机器通过做任务Task,学习经验Experience,然后提升性能Performance。
1.3 supervised learning 监督学习
in every example in our data set,we are told what is the “correct answer” that we would have quite liked the algorithms have predicted on that example.
简单而言,就是给出一堆已经分好类的数据,然后在数据中找规律,分类,预测正确答案。
分为两种数学问题
第一是classification problem 分类问题 离散数学问题。通过不同的特征,判断正确性
第二是regression problem 回归线问题 把点连成线 ,按照点的位置,选择预判的正确答案。
1.3 unsupervised learning 无监督学习
在没用贴任何标签的时候,机器自动把数据分类。
两个算法
第一是clustering algorithm类聚算法
第二是Cocktail party problem algorithm鸡尾酒算法 在明确声源中的主声源后去除背景杂音。
这里的鸡尾酒算法:

目前只学习了SVD,其他没用学习:
 SVD解析
SVD解析
2.1 模型描述
从y(x)的角度,建立模型,构造回归方程(线性)。

2.2 cost function 代价方程

θ1:预测函数的切线,y=ax+b中的a
θ2:预测函数y=ax+b中的b
2.3 Gradient descent algorithm 梯度下降

1.虽然 α学习率控制下降的速度,但不是绝对的,偏导数才决定是否下降。
2.w 和 b 是同时更新的,两个变量同时影响一个结果。(9.22)
三、文献阅读
本周阅读了张学文的学位论文《黔中南苗语语音识别研究》,基于李宏毅教授的语音识别课,在一个案例中弄清楚了语音识别的流程。
论文中的主要结构:
3.1 语音语料库
人声录入苗语,建立不同地域的苗语语音语料库。
3.2 孤立词
针对孤立词(也就是单个词语,未连成句子),基于苗语没有自己的拼音和苗语和汉语相似的特点,以汉语拼音为媒介,设计苗语单个词汇的识别模型。
使用了卷积神经网络框架,包括卷积层,池化层,全连接层和激活层。包括4个卷积层,2个池化层,1个全连接层,和一个Softmax函数。

3.2.1 卷积层
卷积层是卷积神经网络特征提取层,用于对原始输入的数据进行声音特征的提取,和降低维度。每层卷积层包含多个卷积核,不同的卷积核提取不同的特征,从大小和个数两方面对数据进行特征的提取。

提取公式: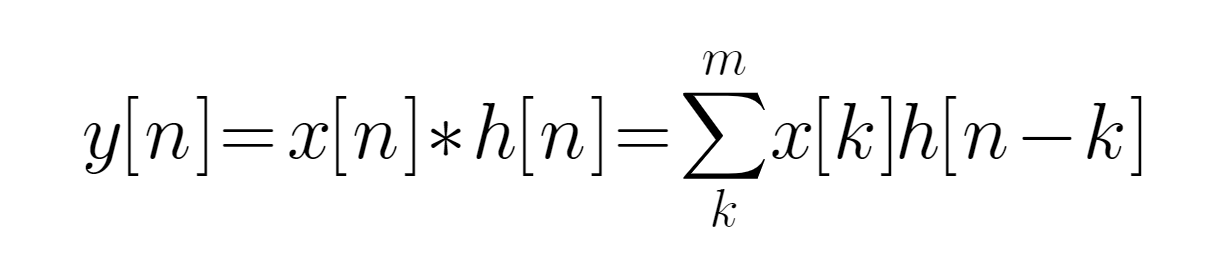
y[n]为输出信号,x[n]为输入信号,h[n]为单位响应。卷积核便利数据矩阵,对应元素相乘求和。
3.2.2 池化层
池化层在卷积运算之后,将数据进行降维操作。有两种,第一对池化区域求平均值,第二对池化区域求最大值。
3.2.3 全连接层
全连接层每个节点都和前一层的节点相连接。全连接层的每一个输出都是前一层的每一个结点乘于一个权重系数w,再加上偏置值b。公式如下:y=wx=b。得出特征之后,将数据传给Softmax分类器分类。
3.2.4 激活层
激活层将卷积层计算出来的数据进行激活函数计算,再输入池化层和全连接层。这里的激活函数为非线性激活函数。
3.2.5 MFCC特征提取
MFCC是在Mel标度频率域提取出的倒谱参数。梅尔倒谱系数和频率之间的关系: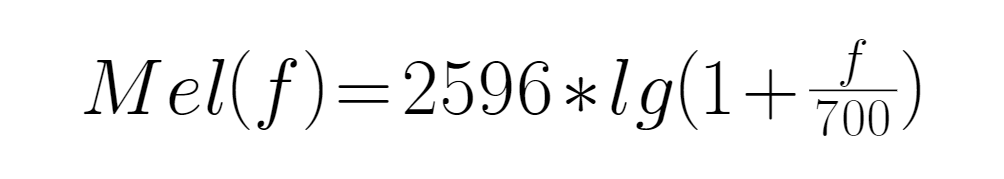
f为频率。
傅里叶变换(FFT):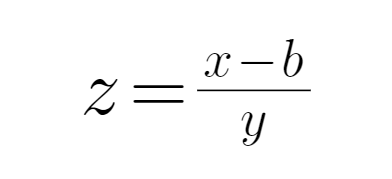
x为语音特征值,b为圆转特征均值,y为标准差。
MFCC提取过程如下:
3.3 连续语音识别
使用汉字为标签的建模方式进行训练模型,不建立单独的苗语发音词典。其中主要用到的是Transformer端对端模型,能通过单个模型实现音频序列映射到文本序列。
3.3.1 Encoder-Decoder 编码和解码
编码器是对语句单词和位置信息进行编码,将语音信号转换为特征向量。
解码器是对编码器生成的特征序列生成文本训练。
Encoder编码器包含Blocks和Embedding两个模块,首先是Embedding对词和词的位置进行编码,然后再相加,以便于自注意力机制关注不同位置的相同字词。公式:
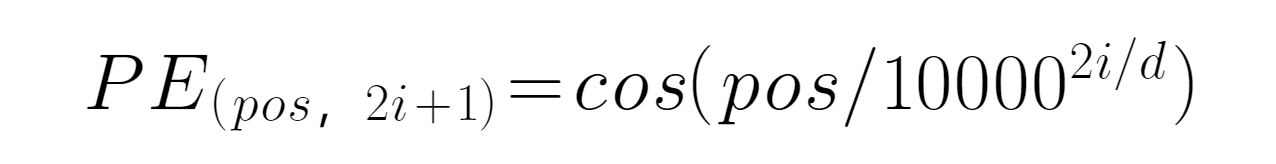
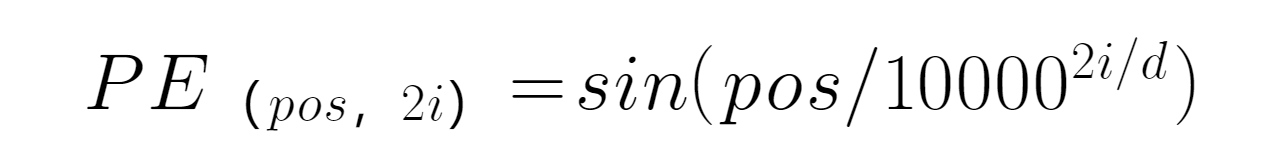
PE表示编码位置,pos表示单词所在位置,d表示PE的维度,2i表示偶数的维度。
在Blocks模块中,也包含很多部分,其中值得注意的是MUlti-Head Attention层。
3.3.1 Attention 注意力机制
Attention包含Q(query)、K(key)、V(value)三个向量值。
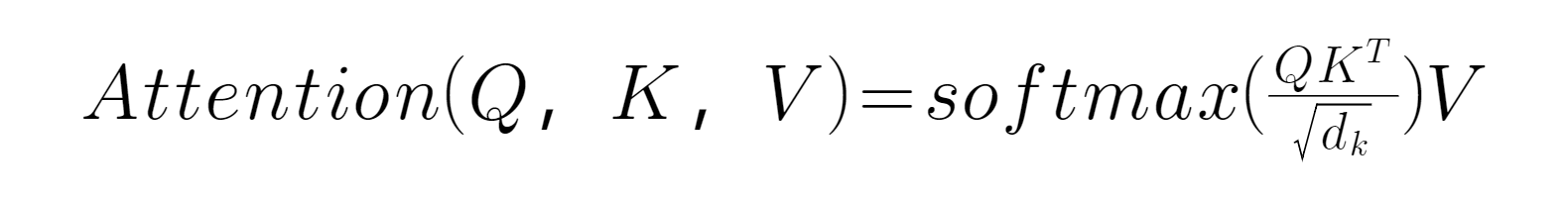
这个公式可以理解为有V对((Q对一些列K)的映射,其中dk为缩放因子。
MUlti-Head Attention是通过多个Attention合并而成:

总结
本周先是学习了李毅宏的《语音识别》,但发现基础知识,实在相差太远,所以决定先学《机器学习》,把基础知识先学一遍。但由于找不到视频中的编码工具,所以这周没有实现,代码模型的复现。 最后是阅读了一篇关于语音识别的中文文献,但里面的公式和模型也并不了解,所以只能了解实验过程,把主要用到的模型记录下来,等自己要做语音识别的时候再学习,或者可能再机器学习中可以学到。
下周计划
以机器学习为主,同时也在学习Python,加阅读一篇语音识别的文献。















 1652
1652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









