






文章目录
前言
This week, I analysed an paper about the Natural language processing ,and the article proposes a novel model EMLo(Embeddings from Language Models).EMLo is a way of computing word embeddings, aimed at representing richer information about words and introducing context-related properties.At the same time, I learned machine learning algorithms . I learned about the Linear Discriminant Analysis Algorithm and Naive Bayes Classifier Algorithm .
一、论文阅读《Deep contextualized word representations》
阅读之间该了解的知识点:log-likelihood(对数似然),Word Embedding(词嵌入)
这是2018年NAACL上的Best Paper,也就是常常在NLP领域中提到的ELMo,原文地址:原文
一句话概括ELMo:一种计算词嵌入的方式,旨在表示出词的更丰富的信息以及引入上下文相关的性质,同一个词在不同上下文中的表示也不同。
摘要
ELMo是一种新型的深度语境化单词表示,其中有两个特征:(1)它既可以模拟单词使用的复杂特征(例如,语法和语义),(2)也可以模拟这些使用在语言上下文中的变化(即建模多义性)。ELMo的词向量是深度双向语言模型(biLM)内部状态的学习函数,该模型在大型文本语料库上进行了预训练。
文中还表明,这些表示可以很容易地添加到现有的模型中,并在六个具有挑战性的NLP问题(包括问题回答、文本蕴含和情感分析)上显著提高了目前的水平。最后还提出了一项分析,表明暴露预训练网络的深层内部是至关重要的,允许下游模型混合不同类型的半监督信号。
Introduction
对比传统Word2Vec这种形式的词向量,本文提出的模型是一种动态模型。在以往的词向量表示中,词都是一种静态的形式,无论在任何的上下文中都使用同一个向量。这种情况下很难表示一词多义的现象,而ELMo则可以通过上下文动态生成词向量,从理论上会是更好的模型,从实测效果来看在很多任务上也都达到了当时的SOTA成绩。
针对第二个特征,ELMo通过使用LSTM使得整个模型是整个句子的函数来满足。而根据后面提到的实验,LSTM的不同层捕捉到的是不同层次的信息,较高的LSTM层捕捉到的是上下文内容依赖的词义的信息,较低的LSTM层捕捉到的是有关句法的信息。ELMo通过对LSTM的不同层的表示进行加权求和来综合这不同层次的信息,从而满足第一个特征。
ELMo: Embeddings from Language Models
ELMo word representations are functions of the entire input sentence, as described in this section.
如本节所述,ELMo单词表示是整个输入句子的函数
Bidirectional language models
一般的语言模型:
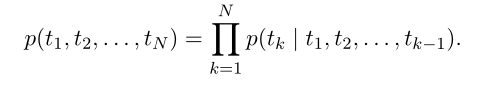
利用前k-1个token来预测第k个token。
ELMo模型,增加了另一个方向的预测,在一般模型的基础上,同时利用k+1~N个token来预测第k个token
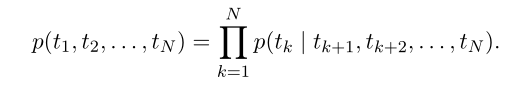
作者这里用LSTM来实现语言模型。
biLM 在构建好正向LSTM与反向LSTM之后,我们的联合优化目标是最大化两个方向上的对数概率,(也就是公式共同最大化了正向和反向方向的对数似然、损失函数)
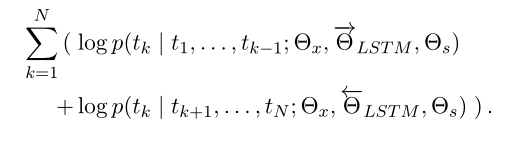
这里需要注意的是θx 是token的表示,而θs 则为softmax参数,同时在每个方向上为lstm保持单独的参数。EMLo还在方向之间共享一些权重,而不是使用完全独立的参数。
ELMo
通过上面的双向LSTM(假设有L层),每个单词我们可以得到2L+1个有关的表示,一个是输入向量,然后正向与反向LSTM的L个层一共产生2L个向量。
进一步将输入向量视为第0层隐藏层的输出:
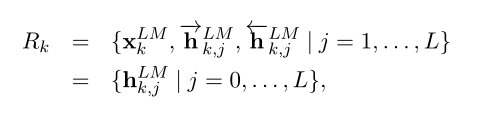
在下游任务中,可以将上述2L+1个表示进行整合:
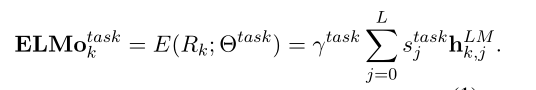
Stask是softmax标准化的权重,标量参数γ任务允许任务模型缩放整个ELMo向量。γ对于帮助优化过程具有实际重要性。考虑到每个biLM层的激活具有不同的分布,在某些情况下,在加权之前对每个biLM层应用层归一化也有帮助。
Using biLMs for supervised NLP tasks
给定一个预先训练好的biLM和目标NLP任务的监督架构,使用biLM来改进任务模型是一个简单的过程。我们只需运行biLM并记录每个单词的所有层表示。然后,我们让最终任务模型学习这些表示的线性组合。
对于下流应用或者模型,原本是有一个上下文无关的输入Xk,我们将所有的这些Xk输入到前面建立的ELMo中得到ELMoktask,我们将这两个向量进行连接得到[Xk,ELMoktask],作为下流模型的新输入即可。
作者提到,这里的ELMo不是只能应用在输入上,而是还可以应用到其他与上下文有关的地方比如输出,有的应用对模型的输出hk,zai 不同层次上进行ELMo也可以提升性能(此hk非ELMo中的hk,而是指下流模型在k时间步的输出)。
此外,dropout和通过||w||22进行正则化都是有帮助的。这会使模型引入对每个层同等权重的偏好,即偏好取所有层的输出的算术平均(非加权)。
Pre-trained bidirectional language model architecture
关于ELMo模型的整体结构及训练,论文中只是简单带过,但总的来说还是按照训练语言模型的方式,使用了CNN-BIG-LSTM结构,和一个层之间的残差链接。最后的结果是,整个模型针对一个token,可以产生三个向量, 原始, 第一层以及第二层。作者认为低层的bi-LSTM层能提取语料中的句法信息,高层的bi-LSTM能提取语料中的语义信息。
实验
论文从 Question answering, Textual entailment, Semantic role labeling, Coreference resolution, Named entity extraction, Sentiment analysis 等六个任务的验证中都取得了提升。
Conclusion
论文介绍了一种从bilm中学习高质量的深度上下文依赖表示的通用方法,并在将ELMo应用于广泛的NLP任务时展示了巨大的改进。通过ablations和其他对照实验,我们也证实了biLM层有效地编码了上下文中关于单词的不同类型的语法和语义信息,并且使用所有层可以提高整体任务性能。
二、机器学习算法(八)- 线性判别分析算法(Linear Discriminant Analysis Algorithm)
在上几周的学习中,已经对流行的回归算法进行了学习,从本周开始,将继续学习机器学习中的分类算法。分类算法中,最为简单的是感知器学习算法(PLA),在此基础上,将进一步学习新的分类算法。
分类算法——线性判别分析算法1(Linear Discriminant Analysis Algorithm / LDA),该算法由罗纳德·艾尔默·费希尔在1936年提出,所以也被称为费希尔的线性鉴别方法(Fisher’s linear discriminant),LDA是在目前机器学习、数据挖掘领域经典且热门的一个算法,在百度的商务搜索部里面就用了不少这方面的算法。
模型介绍
以我个人的愚见,我觉得线性判别分析算法可以称为投影比较算法,将高维的数据映射到低维的超平面上,然后求各个类的均值(中心点),当有新的数据需要判断时,就和均值点比较,离哪个类近就属于哪个类。
ok,我瞎扯完了开始进入正题。
在二元分类中,有数据集,“+”表示正例,“-”表示反例。线性判别分析算法就是要设法找到一条直线,使得同一个类别的点在该直线上的投影尽可能的接近,同时不同分类的点在直线上的投影尽可能的远。该算法的主要思想总结来说就是要“类内小、类间大”,非常类似于在软件设计时说的“低耦合、高内聚”。
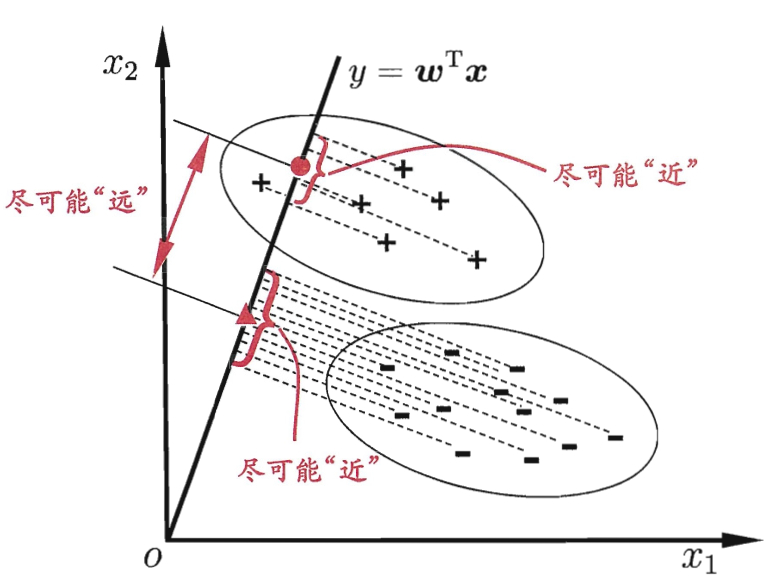
LDA可以作为一种有监督的降维算法。
代价函数
LDA首先是为了分类服务的,因此只要找到一个投影方向ω,使得投影后的样本尽可能按照原始类别分开。
从一个简单的二分类问题出发:
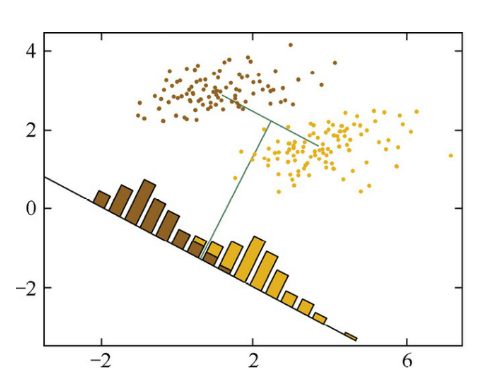
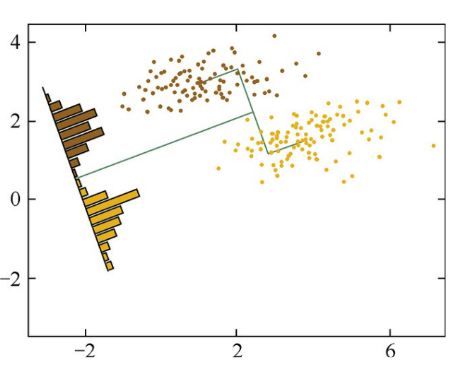
左右两幅图,它们分别投影在两条不同的直线上,产生了两种分类。对左边图的黄棕两种类别的样本点进行降维时,若按照最大化两类投影中心距离的 准则,会将样本点投影到下方的黑线上。但是原本可以被线性划分的两类样本, 经过投影后有了一定程度的重叠,这显然不能满意的。于是找了右边图的直线,虽然两类的中心在投影之后的距离有所减小,但确使投影之后样本的可区分性提高了。
仔细观察两种投影方式的区别,可以发现,在右图中,投影后的样本点似乎在每一类中分布得更为集中了,用数学化的语言描述就是每类内部的方差比左图中更小。这就引出了LDA的中心思想——最大化类间距离和最小化类内距离。
算法希望投影之后两类之间的距离尽可能大:

同时,算法希望投影之后类内的距离尽可能小:

在前文中我们已经找到了使得类间距离尽可能大的投影方式,现在只需要同时优化类内方差,使其尽可能小。我们将整个数据集的类内方差定义为各个类分别的方差之和,将目标函数定义为类间距离和类内距离的比值,于是引出我们需要最大化的代价函数:

至此,我们从最大化类间距离、最小化类内距离的思想出发,推导出了LDA的优化目标以及求解方法。但它对数据的分布做了一些很强的假设,例如,每个类数据都是高斯分布、各个类的协方差相等。尽管这些假设在实际中并不一定完全满足,但LDA已被证明是非常有效的一种降维方法。主要是因为线性模型对于噪声的鲁棒性比较好。
算法步骤
线性判别分析的核心思想在前面也介绍过——“类内小、类间大”,按照最后求得的公式直接计算即可。
(1)分别计算每一类的均值向量
(2)分别计算每一类的内部方差之和
(3)形成类间距离和类内距离的比值的代价函数
(4)对代价函数求w的偏导,得出权重系数 w
(5)求新样本的分类时,只需判断新样本点离哪一个分类的均值向量更近,则新样本就是哪个分类
还有另一种版本是用矩阵和向量分析的,用到了样本点投影的均值向量和样本点投影的协方差矩阵,同时还用了运用拉格朗日乘数法,相对较难理解,可以参考博客:线性判别分析算法
同时还有从概率分布的角度分析的,参考博客:线性判别分析算法(二)
代码实现
def lda(X, y):
"""
线性判别分析(LDA)
args:
X - 训练数据集
y - 目标标签值
return:
w - 权重系数
"""
# 标签值
y_classes = np.unique(y)
# 第一类
c1 = X[y==y_classes[0]][:]
# 第二类
c2 = X[y==y_classes[1]][:]
# 第一类均值向量
mu1 = np.mean(c1, axis=0)
# 第二类均值向量
mu2 = np.mean(c2, axis=0)
sigma1 = c1 - mu1
# 第一类协方差矩阵
sigma1 = sigma1.T.dot(sigma1) / c1.shape[0]
sigma2 = c2 - mu2
# 第二类协方差矩阵
sigma2 = sigma2.T.dot(sigma2) / c2.shape[0]
# 求权重系数
return np.linalg.pinv(sigma1 + sigma2).dot(mu1 - mu2), mu1, mu2
def discriminant(X, w, mu1, mu2):
"""
判别新样本点
args:
X - 训练数据集
w - 权重系数
mu1 - 第一类均值向量
mu2 - 第二类均值向量
return:
分类结果
"""
a = np.abs(X.dot(w) - mu1.dot(w))
b = np.abs(X.dot(w) - mu2.dot(w))
return np.argmin(np.array([a, b]), axis=0)
LDA算法小结
LDA的核心是对数据进行降维,实际上LDA除了可以用于降维以外,还可以用于分类。一个常见的LDA分类基本思想是假设各个类别的样本数据符合高斯分布,这样利用LDA进行投影后,可以利用极大似然估计计算各个类别投影数据的均值和方差,进而得到该类别高斯分布的概率密度函数。当一个新的样本到来后,我们可以将它投影,然后将投影后的样本特征分别带入各个类别的高斯分布概率密度函数,计算它属于这个类别的概率,最大的概率对应的类别即为预测类别。
参考文章:文章
三、机器学习算法(九)- 朴素贝叶斯分类算法(Naive Bayes Classifier Algorithm)
分类算法——朴素贝叶斯分类算法(Naive Bayes Classifier Algorithm/NB)。朴素贝叶斯分类算法在文本分类和自动医疗诊断的领域中有应用到。
模型介绍
在学习朴素贝叶斯分类算法之前,先来看下在概率论中的几个概念。
贝叶斯定理
先验概率:通过经验来判断事情发生的概率。
后验概率:后验概率就是发生结果之后,推测原因的概率。
条件概率:事件 A 在另外一个事件 B 已经发生条件下的发生概率,表示为
P(A|B),读作“在 B 发生的条件下 A 发生的概率”。
如有事件A,B,在 B 事件发生时,A 事件发生的概率等于在 A 事件发生时,B 事件发生的概率乘以 A 事件发生的概率除以 B 事件发生的概率,用公式表示如下: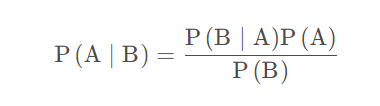
条件独立
两个随机变量 X 和 Y 在给定第三个随机变量 Z 的情况下条件独立当且仅当它们在给定 Z 时的条件概率分布互相独立,也就是说,给定Z的任一值,X 的概率分布和Y的值无关,Y 的概率分布也和X的值无关。
关于条件独立以下三个式子:
P(X,Y∣Z)=P(X∣Z)P(Y∣Z) ①
P(X∣Y,Z)=P(X∣Z) ②
P(Y∣X,Z)=P(Y∣Z) ③
①式等价于下面是②③式,在②中Y对 X 的条件概率没有影响,同理在③中 X 对 Y 的条件概率也没有影响。
朴素贝叶斯分类
朴素贝叶斯分类之所以朴素,就是因为我们做了一个简单的假设,即类中特定特征的存在与任何其他特征的存在无关,这意味着每个特征彼此独立。因此对实际情况有所约束,如果属性之间存在关联,分类准确率会降低。不过在大多数应用的场景,朴素贝叶斯的分类效果都不错。

关于上式中:
(1)假设函数表达式
(2)改写一下,特征变量 x 为 p 维
(3)用贝叶斯定理变换一下
(4)由于分母对最后的结果不影响,不依赖与分类,可以认为是一个常数
(5)根据假设各特征变量之间是条件独立的,所以可以改写成乘积的形式
(6)用连乘符号简化一下
最后就得到了朴素贝叶斯分类的概率模型,针对不同的概率分布可以得到不同的朴素贝叶斯分类方法。常见的算法包括:多项式朴素贝叶斯分类、高斯朴素贝叶斯分类、伯努利朴素贝叶斯分类等。
多项式朴素贝叶斯分类
多项式朴素贝叶斯分类是假设样本服从多项式分布(multinomial distribution),是通过特征出现的频率来估计特征的概率,根据大数定律 (law of large numbers),当样本数据越多,事件出现的频率趋于稳定后,频率即为事件的概率。
有数学表达式:
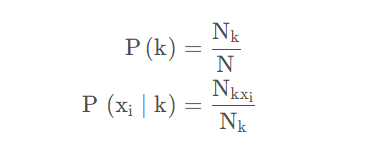
关于上式,分类为 k 的概率可以通过分类 k 在所有样本中出现的频率来估计,即分类为k的样本数 Nk 除以总样本数 N。在分类为 k 时,第 i 个特征为 xi 的概率等于分类为 k 并且特征为 xi 的样本数除以分类为 k 的样本数 Nk。
同时,也有可能出现一种情况:当一种特征中某个分类下没有出现过,会发现用上面的方式计算出的概率为零,这会使得最后的后验概率也等于零。
于是,在上面式子的基础上,提出了平滑处理,这里可以对数据做平滑处理,在计算频率时引入一个平滑参数来避免计算中出现 0 的问题,数学表达式如下: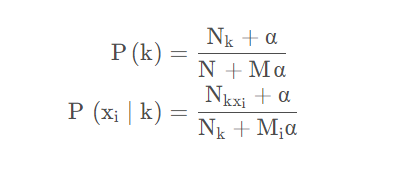
该方式被称为拉普拉斯平滑5(Laplace smoothing)。当样本数足够多时,即 N >> M,这种平滑处理对结果的影响较小。
伯努利朴素贝叶斯分类:伯努利朴素贝叶斯分类是假设样本数据服从伯努利分布,该分类同多项式朴素贝叶斯分类一样适用于离散特征,不同点是伯努利分布的取值只能为 0、1。
高斯朴素贝叶斯分类:当样本的特征是连续的,例如身高、体重时,可能使用高斯朴素贝叶斯分类来处理更合适一些。高斯朴素贝叶斯分类顾名思义是假设样本数据服从正太分布(Normal distribution)或者也叫作高斯分布(Gaussian distribution),计算出对应分类下每个特征的方差与均值,利用正态分布的概率密度函数,估计对应的概率值。
算法步骤
朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
1.设x={a1,a2,a3,……,an}为一个待分类项,而每个a为x的一个特征。
2.有类别集合c={y1,y2,y3,……,ym}
3.计算P(y1|x),P(y2|x),……,P(ym|x)
4.如果P(yk|x)=max{P(y1|x),P(y2|x),……,P(ym|x)},则x∈yk
代码实现
使用 Python 实现多项式朴素贝叶斯分类:
import numpy as np
def mnb(X, y, alpha = 1):
"""
多项式朴素贝叶斯分类
args:
X - 训练数据集
y - 目标标签值
alpha - 平滑参数
return:
priors - 先验概率的对数
pss - 每种特征对应每种标签分类的条件概率的对数
x_classes - 特征分类
y_classes - 标签分类
"""
# 标签分类、每类数量
y_classes, y_counts = np.unique(y, return_counts=True)
y_counts += alpha
# 先验概率
priors = np.log(y_counts / np.sum(y_counts))
# 每种特征对应每种标签分类的条件概率的对数
pss = []
# 特征分类
x_classes = []
for idx in range(X.shape[1]):
# 第 idx 个特征
x_idx = X[:, idx]
# 第 idx 个特征分类、每类数量
x_idx_classes, x_idx_counts = np.unique(x_idx, return_counts=True)
x_classes.append(x_idx_classes)
# 第 idx 个特征对应每种标签分类的条件概率的对数
ps = []
for jdx in range(len(y_classes)):
# 第 idx 个特征对应第 jdx 个标签分类的分类、每类数量
x_jdx_classes, x_jdx_counts = np.unique(x_idx[y==y_classes[jdx]], return_counts=True)
# 第 idx 个特征对应第 jdx 个标签分类的条件概率的对数
p = []
for kdx in range(len(x_idx_classes)):
# 同时满足特征与标签的下标
idxs = np.where(x_jdx_classes == x_idx_classes[kdx])[0]
# 平滑后的分子
a = alpha
if (len(idxs) != 0):
a = x_jdx_counts[idxs[0]] + alpha
# 平滑后的分母
b = np.sum(x_jdx_counts) + len(x_idx_classes) * alpha
p.append(np.log(a/b))
ps.append(np.array(p))
pss.append(np.array(ps))
return priors, pss, x_classes, y_classes
def predict(X, priors, pss, x_classes, y_classes):
"""
预测
args:
X - 数据集
priors - 先验概率的对数
pss - 每种特征对应每种标签分类的条件概率的对数
x_classes - 特征分类
y_classes - 标签分类
return:
预测结果
"""
ys = []
for idx in range(X.shape[0]):
y = np.array(priors)
for jdx in range(X.shape[1]):
for kdx in range(len(y_classes)):
y[kdx] = y[kdx] + pss[jdx][kdx][x_classes[jdx] == X[idx][jdx]]
ys.append(y)
return y_classes[np.argmax(ys, axis=1)]
总结
本周阅读了论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》,这就一篇关于NLP的文章,其内容大意是推出了一个EMLo(Embeddings from Language Models)模型。EMLo是一种计算词嵌入的方式,旨在表示出词的更丰富的信息以及引入上下文相关的性质。这应该是第一个运用双向LSTM进行词预测的模型。同时,本周学习了线性判别分析算法(Linear Discriminant Analysis Algorithm),和朴素贝叶斯分类算法(Naive Bayes Classifier Algorithm),这是两个比较简单的分类算法,下周会继续学习机器学习的分类算法。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









