







知识回顾:
顺序表的特点:以物理位置相邻表达逻辑关系。
线性表的优点:数据元素随机存取。
线性表的缺点:插入、删除操作需要移动大量元素;存储空间不灵活。
1.线性表的链式存储结构
1.1 链式存储结构的介绍
链式存储结构(又称非顺序映像或链式映像):结点在存储器中的顺序是任意的,即可以连续,也可以不连续,甚至是零散分布在内存的任意位置。(链表中元素的逻辑次序与物理次序不一定相同)
那么问题来了,既然结点的存储是任意的,那我们应该如何确定节点的顺序呢?我们可以在每个节点上开辟一块空间来存储下一个节点的地址,这样就把整个链表串起来了。
例1:线性表:(赵,钱,孙,李,周,吴,郑,王)
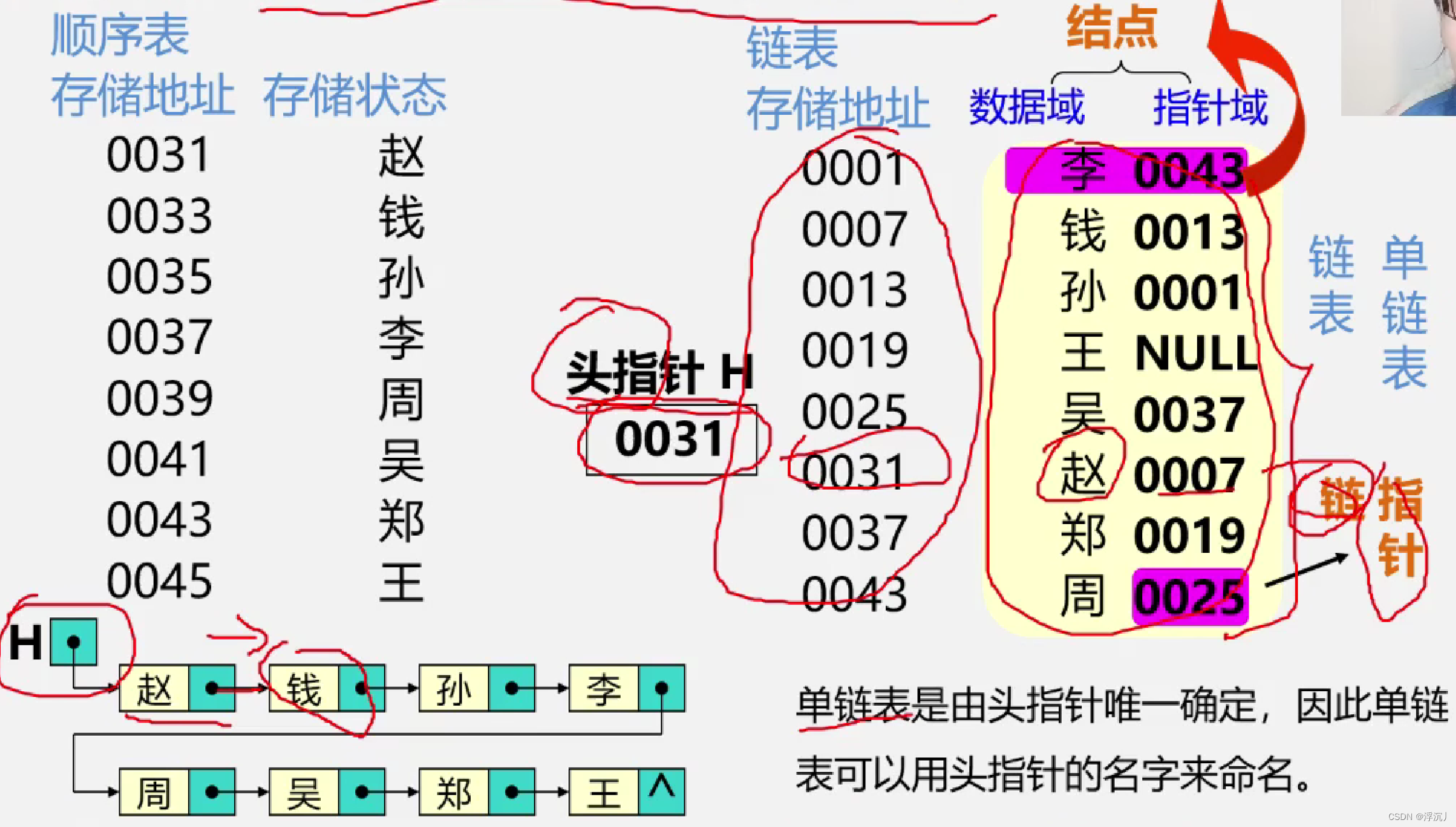
例2:26个小写字母的表的链式存储结构
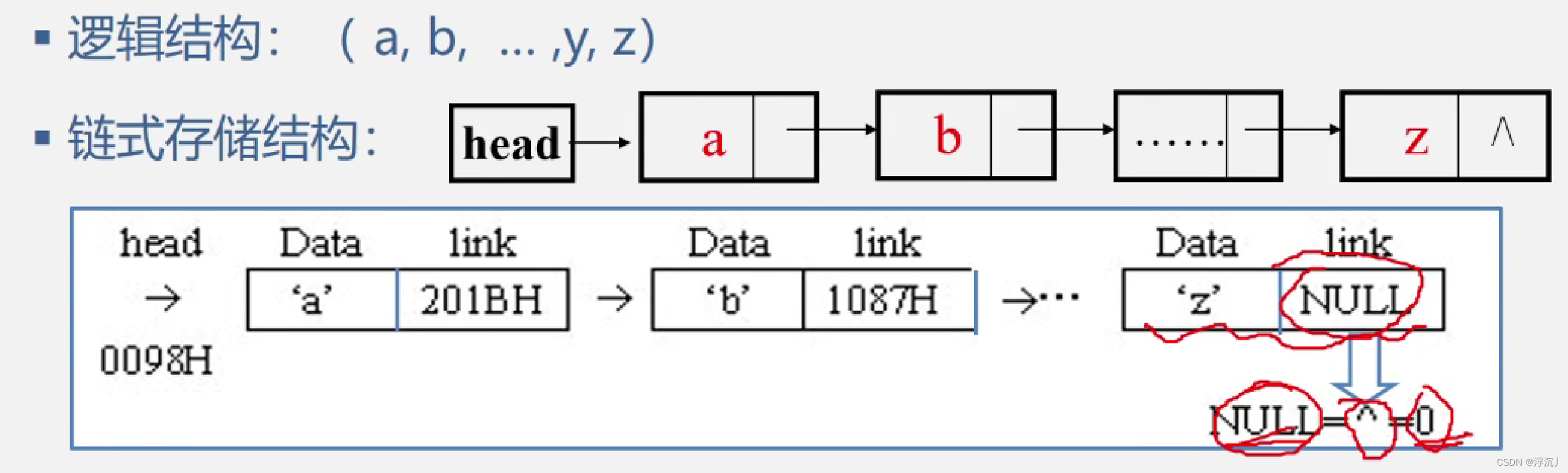
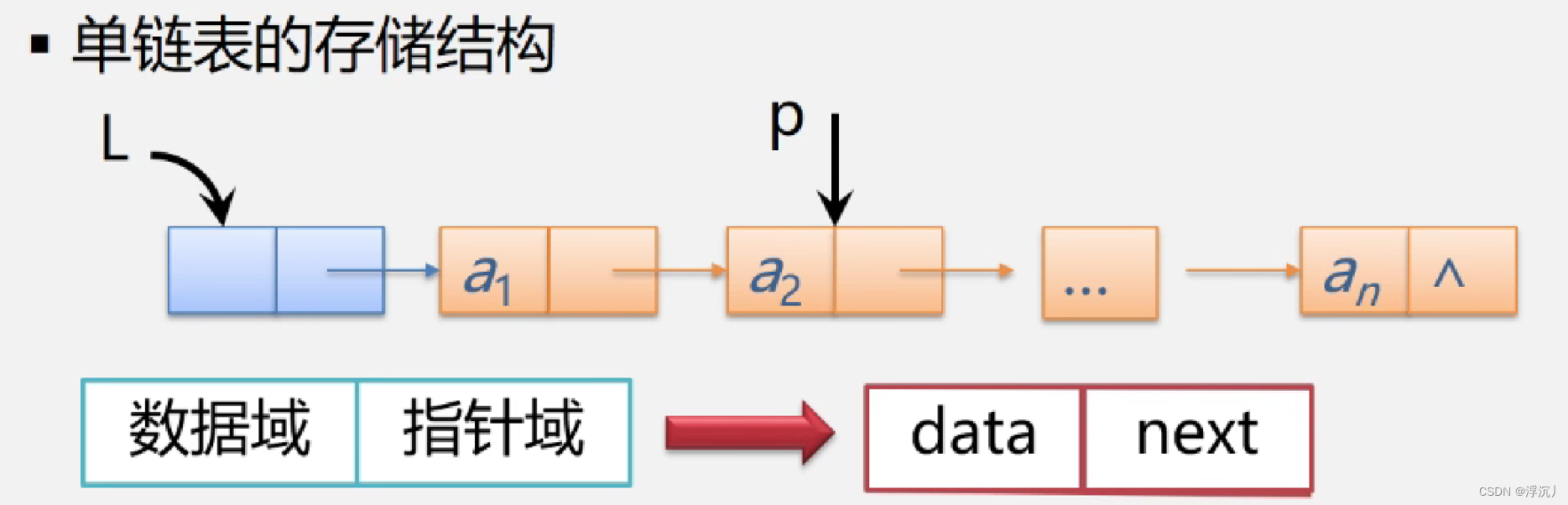
通过以上两例我们不难发现,每个结点都是由数据域(存储元素数值数据)和指针域(存储后继结点的存储位置)组成的。
1.2 链式存储结构的相关术语
1.结点:数据元素的存储映像。由数据域和指针域两部分组成;
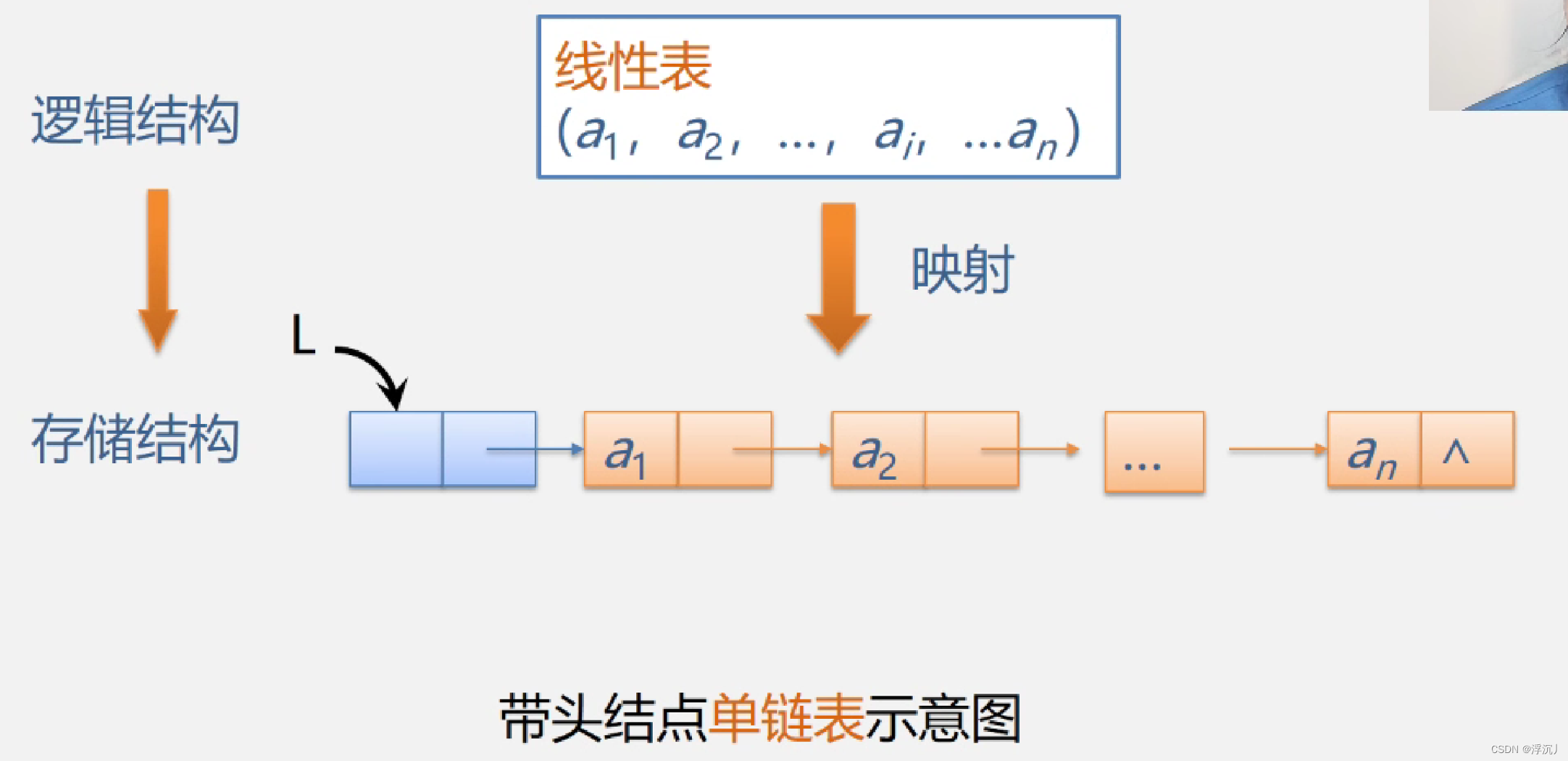
2.链表:n个结点由指针链组成一个链表。(它是线性表的链式存储映像,称为线性表的链式存储结构);
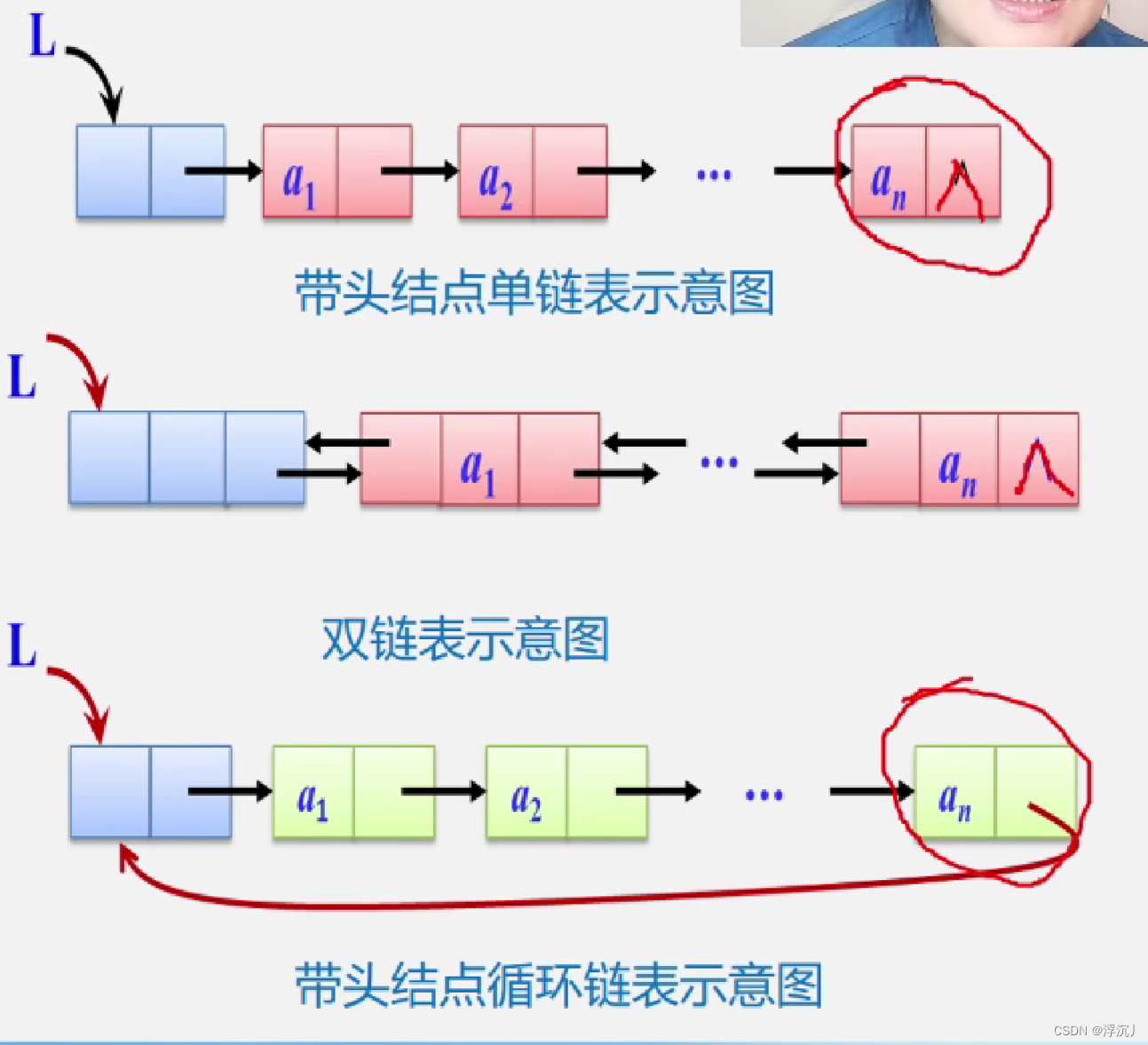
3.单链表、双链表和循环链表:
①单链表:结点只有一个指针域的链表;
②双向链表:在单链表的每个结点中,再设置一个指向其前驱结点的指针域;
③循环链表:尾结点的指针域指向头结点的链表。
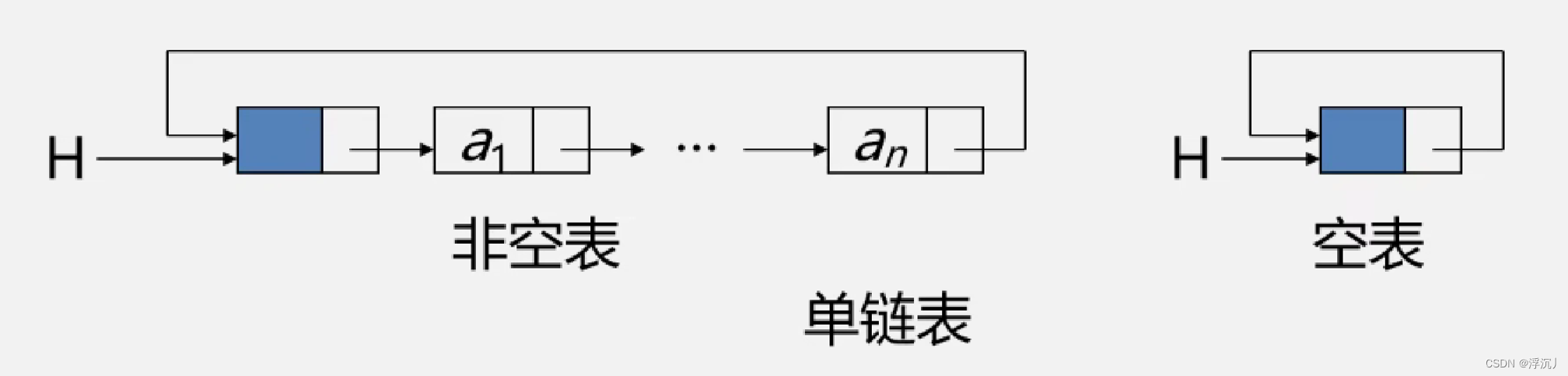
4.头指针、头指针和首元结点
头指针:指向链表第一个结点的指针;
首元结点:链表存储元素的第一个结点;
头结点:在头结点前附设的一个节点。

带头结点与不带头结点的链表存储结构示意图:
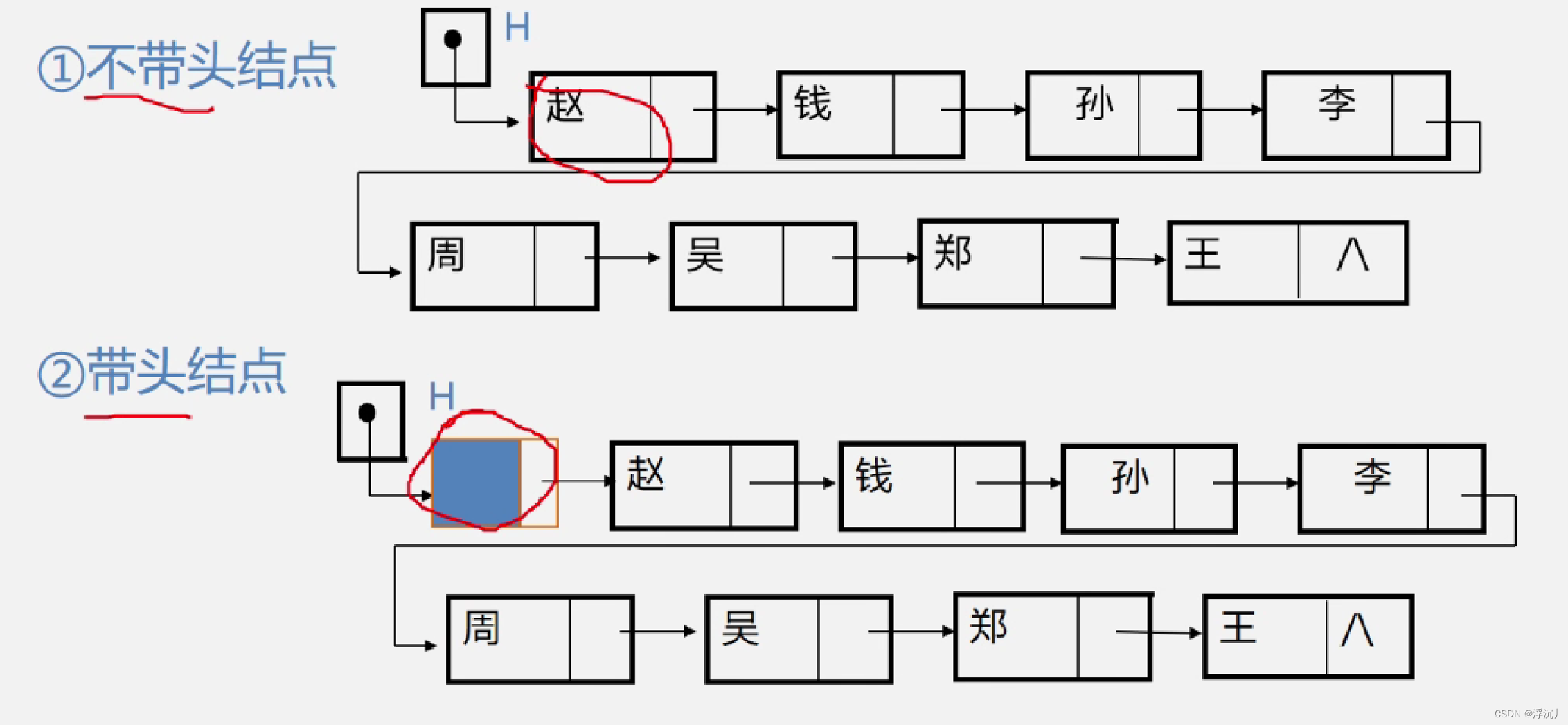
讨论:
1.如何表示空表?
①不带头结点:头指针为空时表示空表;
②带头结点:头结点的指针域为空时表示空表。
2.在链表中设置头结点的好处?
①便于首元结点的处理:首元结点的地址存储在头结点之中,所以在链表上的第一个位置的操作与其他位置一致,无需进行特殊处理;
②便于空表和非空表的处理:无论链表是否为空,头指针都是指向头结点的非空指针,因此空表和非空表的处理也就变得统一了。
3.头结点的数据域内可以装什么?
可以为空,也可以存放链表的长度等附加信息,但此结点不能计入链表长度值。
1.3 链式存储结构的特点
1.结点在存储器中的位置是随意的;
2.访问时只能通过头结点进入链表,并通过每个结点的指针域依次扫描其他结点。(称为顺序存取,顺序表为随机存取)
2. 单链表的基本操作的实现
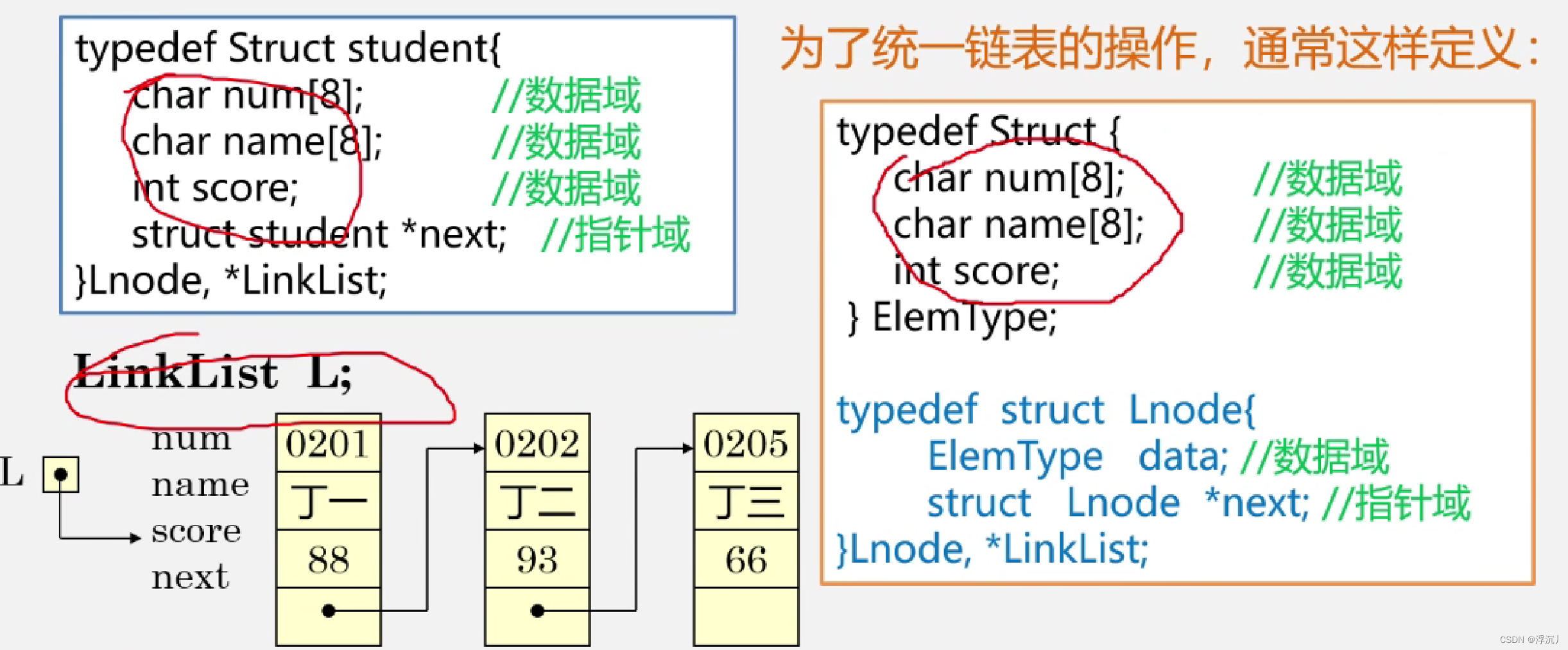
定义链表结构体:
typedef struct LNode //声明节点的类型和指向结点的指针类型
{
ElemType data; //结点的数据域
LNode* next; //结点的指针域
}LNode,*LinkList; //LinkList为指向结点的指针类型,后续使用LNode创建结点,用LinkList创建链表,这样做可以避免产生不必要的混淆,使得结点与链表分明
int main()
{
LinkList L; //创建链表L
LNode *p; //定义结点指针p
p = (LNode*)malloc(sizeof(LNode)); //分配空间
assert(p != NULL);
return 0;
}
举例:存储学生学号、姓名、成绩的单链表结点类型的定义
2.1 单链表的初始化(带头结点)

Status InitList_L(LinkList& L)
{
L = (LNode*)malloc(sizeof(LNode)); //分配空间
assert(L != NULL);
L->next = NULL;
return OK;
}
2.2 判断链表是否为空

int EmptyList_L(LinkList L)
{
if (L->next)
return 0; //不为空,返回0
else
return 1; //为空,返回1
}
2.3 销毁单链表
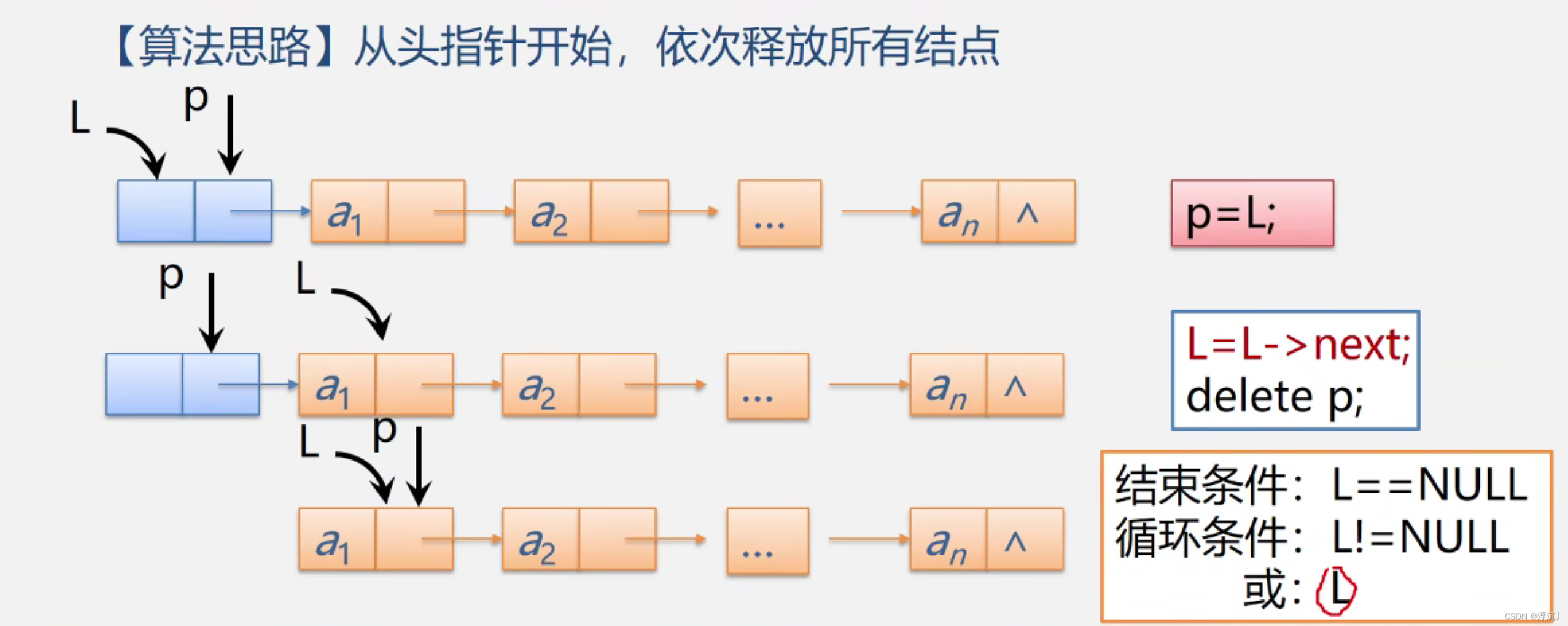
Status DestroyList_L(LinkList& L)
{
LNode* p ;
while (L)
{
p = L;
L = L->next;
free(p);
}
return OK;
}
2.3 清空单链表
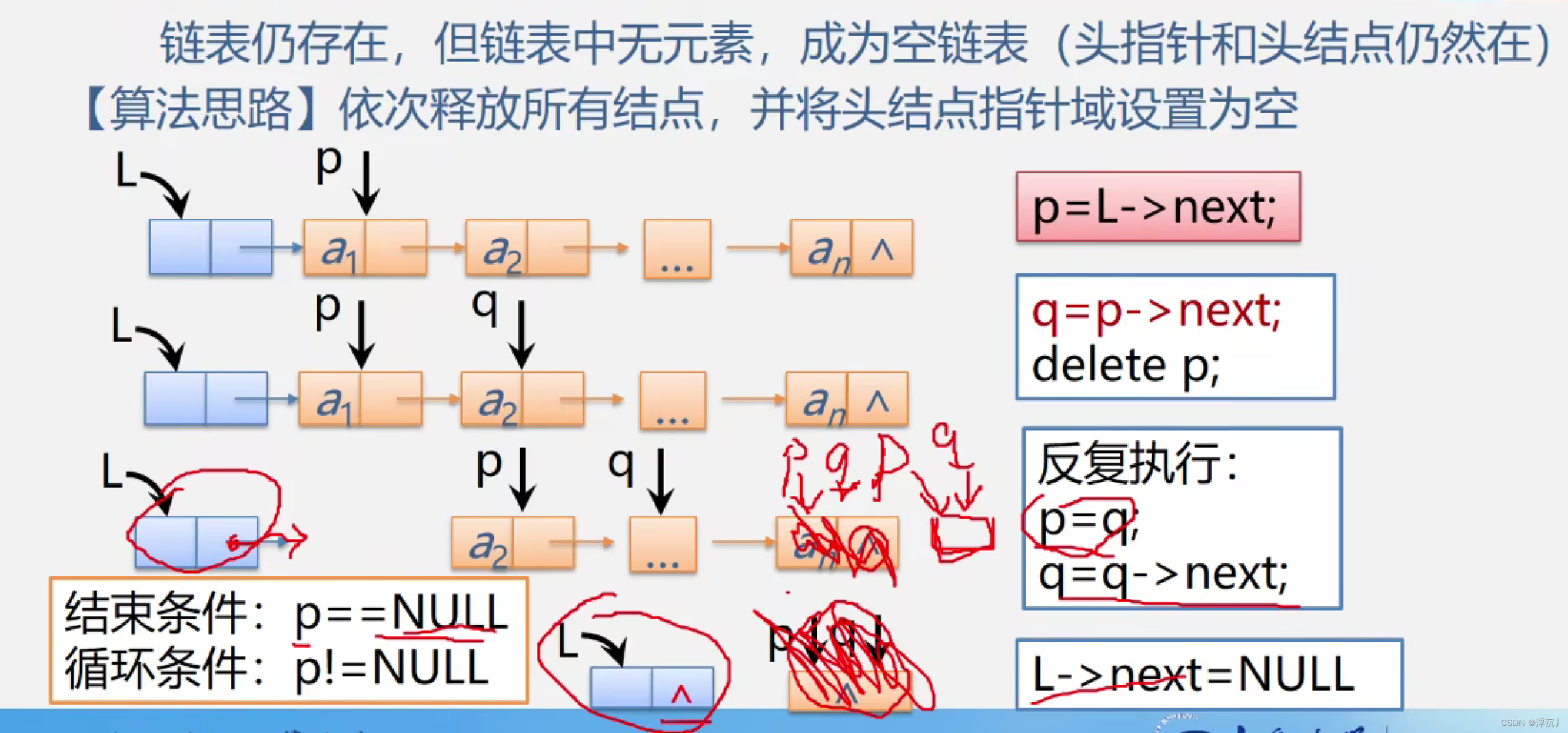
Status ClearList_L(LinkList& L)
{
LNode* p, * q;
p = L->next;
while (p) //while(q)也可
{
q = p->next;
free(p);
p = q;
}
L->next = NULL;
return OK;
}
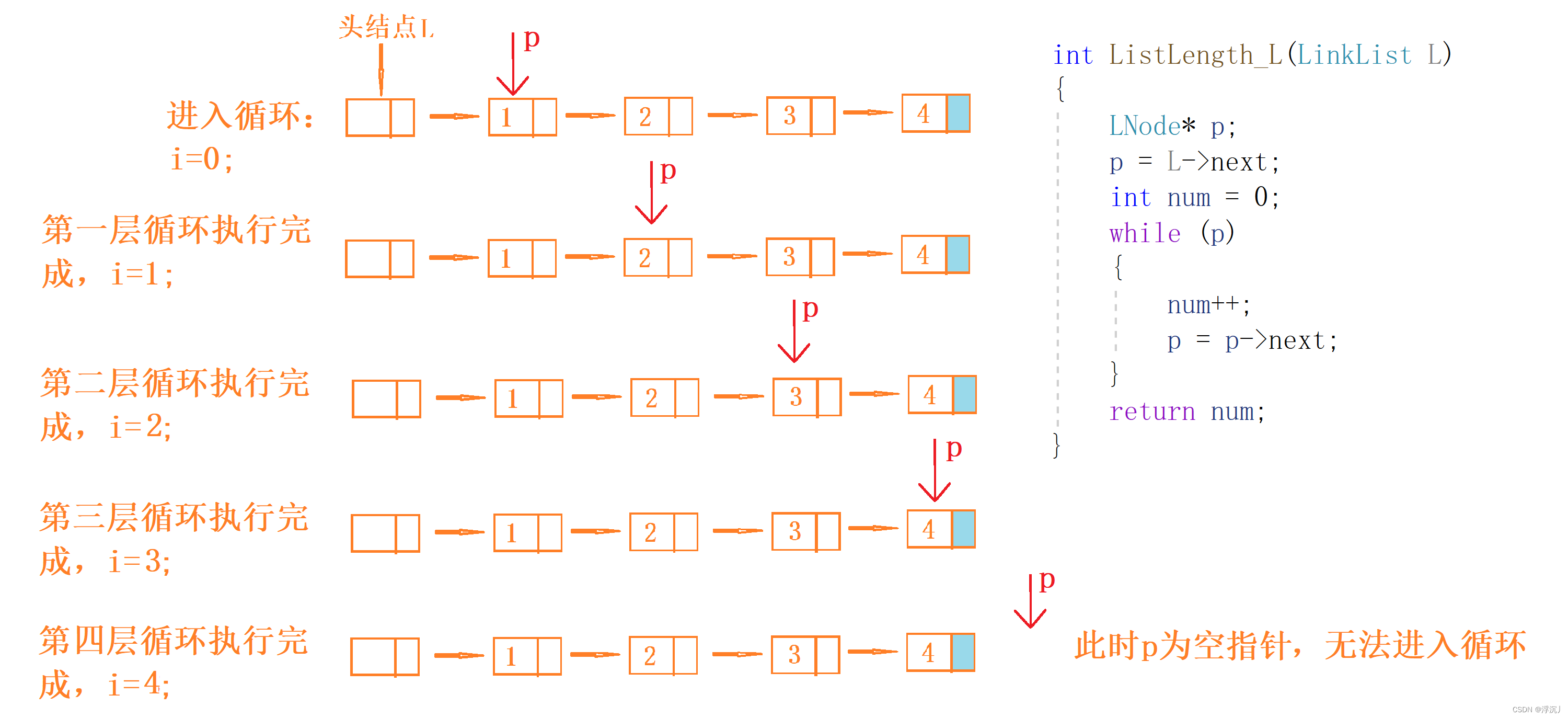
2.4 求链表的表长
算法思想:从首元结点开始,依次计数所有结点。
int ListLength_L(LinkList L)
{
LNode* p;
p = L->next;
int num = 0;
while (p)
{
num++;
p = p->next;
}
return num;
}
2.5 取值(取链表中第i个元素的内容)
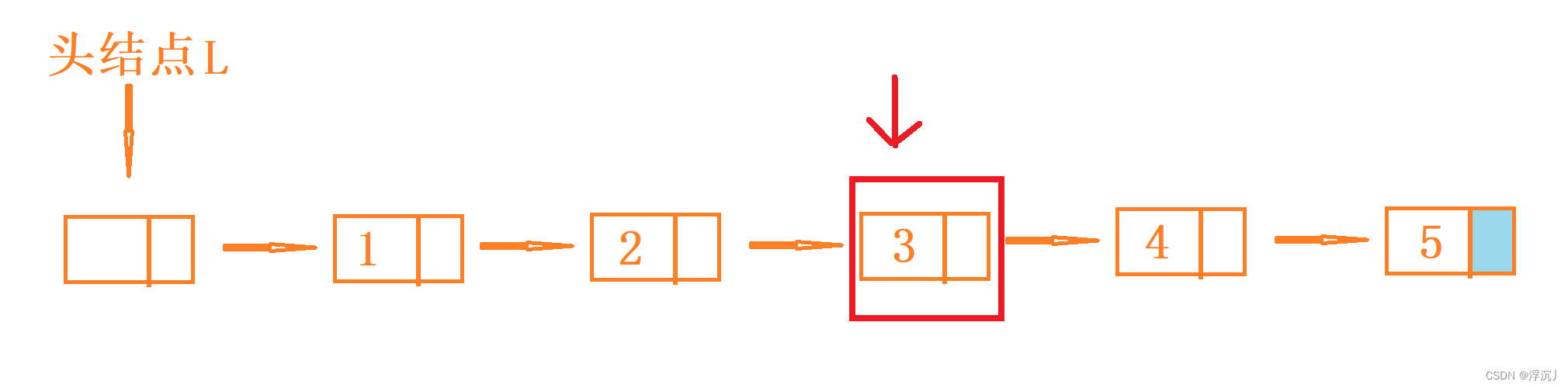
算法思想:定义指针p,从头开始遍历到第i个位置,然后保存第i个位置的数据域到e即可。
算法分析:提起遍历,我们肯定就要使用循环。那么应该使用for循环还是使用while 循环呢?那么就要根据问题具体分析了。
问题分析:
1.输入的位置非法。
当输入的 i<0 或 i>表长 时,就会出现问题。
解决思路:
由于无法确定表长,因此 i>表长 的问题不好判断。仔细想想,当i大于表长时,p遍历到最后一个元素时继续遍历,p不就指向NULL了吗?因此,我们可以使用根据 p是否为空 来判断i是否大于表长。如果使用for循环,那么只需在for循环内部添加条件判断(p是否为空)即可。而对于 i<0 的问题,我们遍历链表时肯定会定义整型变量j,而循环的条件肯定是 j<i 。因此,循环的条件刚好可以解决 i<0 的问题。接下来,我们一起梳理一下算法步骤!
算法步骤:

Status GetElem_L(LinkList L, int i, ElemType& e)
{
LNode* p;
int j = 1;
p=L->next;
while (j < i && p)
{
j++;
p = p->next;
}
if (!p || j > i)
return ERROR; //位置不合法
e = p->data;
return OK;
}
从这个算法我们可以看输出,顺序表的取值算法可比链表的取值算法简单的多。因此,顺序表是随机存取,而链表确实顺序存取。
2.6 按值查找
算法思想:通过遍历数组来比较每个结点的值是否与e相等。
算法步骤:

int LocateElem_L(LinkList L, ElemType e)
{
LNode* p;
p = L->next;
int j = 1;
while (p->data != e && p)
{
p = p->next;
j++;
}
if (p)
return j; //找到返回元素位置
else
return 0; //未找到返回0
}
2.7 插入算法
算法思想:定位到指针指向要插入的位置的前一个结点,然后插入即可。
算法步骤:

Status ListInsert_L(LinkList& L, int i, ElemType e)
{
LNode* p, * s;
p = L->next;
int j = 1;
while (j < i-1 && p) //移动p,使其指向要插入结点的前一个结点
{
p = p->next;
j++;
}
if (p || j > i-1) //如果输入的位置不合法(i>表长 或 i<1),则返回ERROR
return ERROR;
s = (LNode*)malloc(sizeof(LNode)); //创建新节点并初始化
assert(s != NULL);
s->data = e;
s->next = p->next; //插入
p->next = s;
return OK;
}
2.8 删除算法
算法思想:
算法步骤:

Status ListDelete_L(LinkList& L, int i, ElemType& e)
{
LNode* p, * q;
p = L->next;
int j = 1;
while (j < i - 1 && p) //移动p,使其指向要删除结点的前一个结点
{
p = p->next;
j++;
}
if (p || j > i - 1) //如果输入的位置不合法(i>表长 或 i<1),则返回ERROR
return ERROR;
q = p->next;
p->next = q->next;
e = q->data;
free(q);
return OK;
}
2.9 建立单链表
2.9.1 头插法
建立单链表,元素插入在头部。
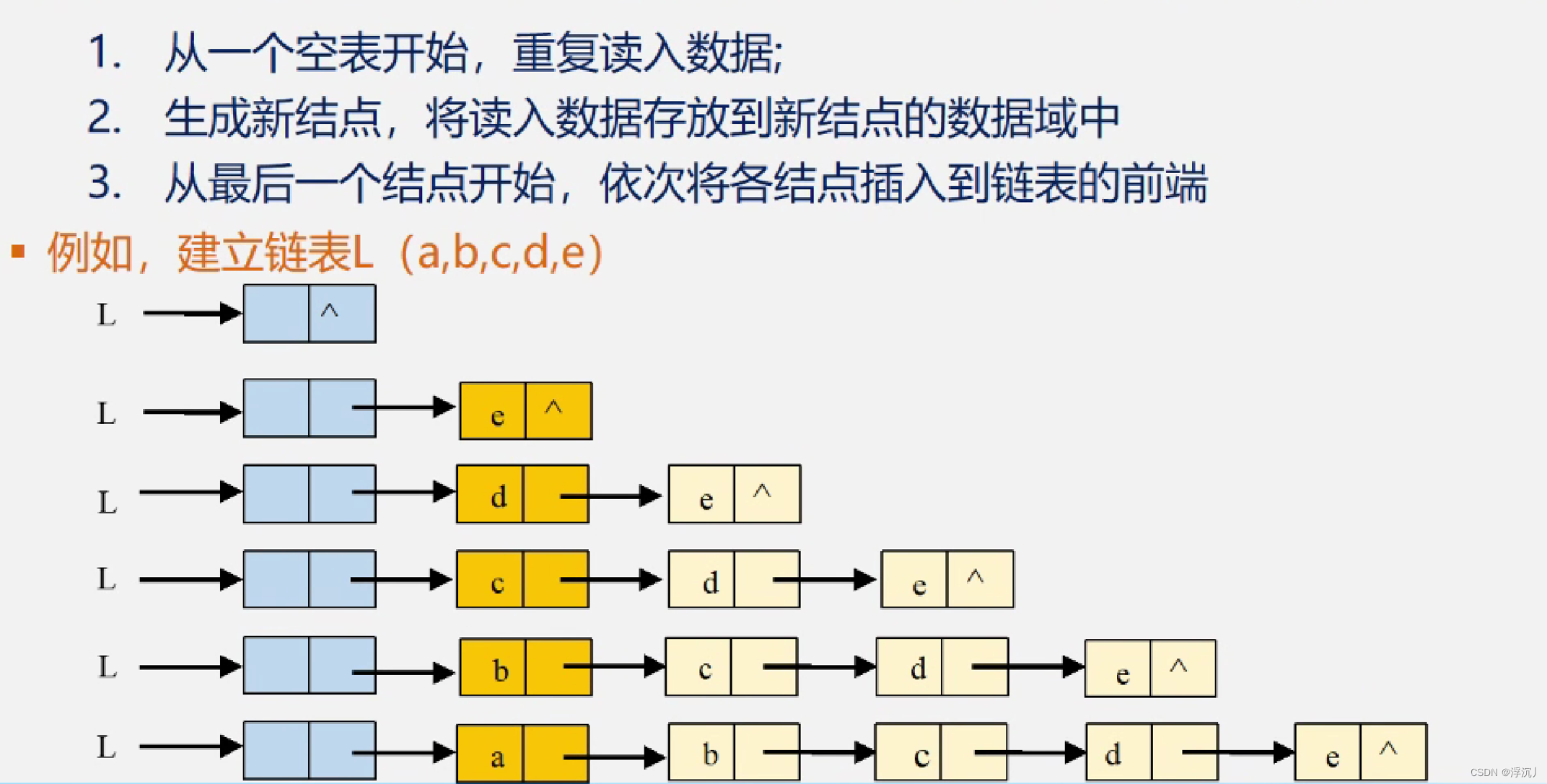
void CreateList_H(LinkList& L, int n)
{
LNode* p;
L = (LinkList)malloc(sizeof(ElemType));
assert(L != NULL);
L->next = NULL;
for (int i = n; i > 0; i--)
{
p = (LNode*)malloc(sizeof(ElemType));
assert(p != NULL);
scanf_s("%d", &(p->data));
p->next = L->next;
L->next = p;
}
}
时间复杂度为O(n);
2.9.2 尾插法
建立单链表,元素插入在尾部。
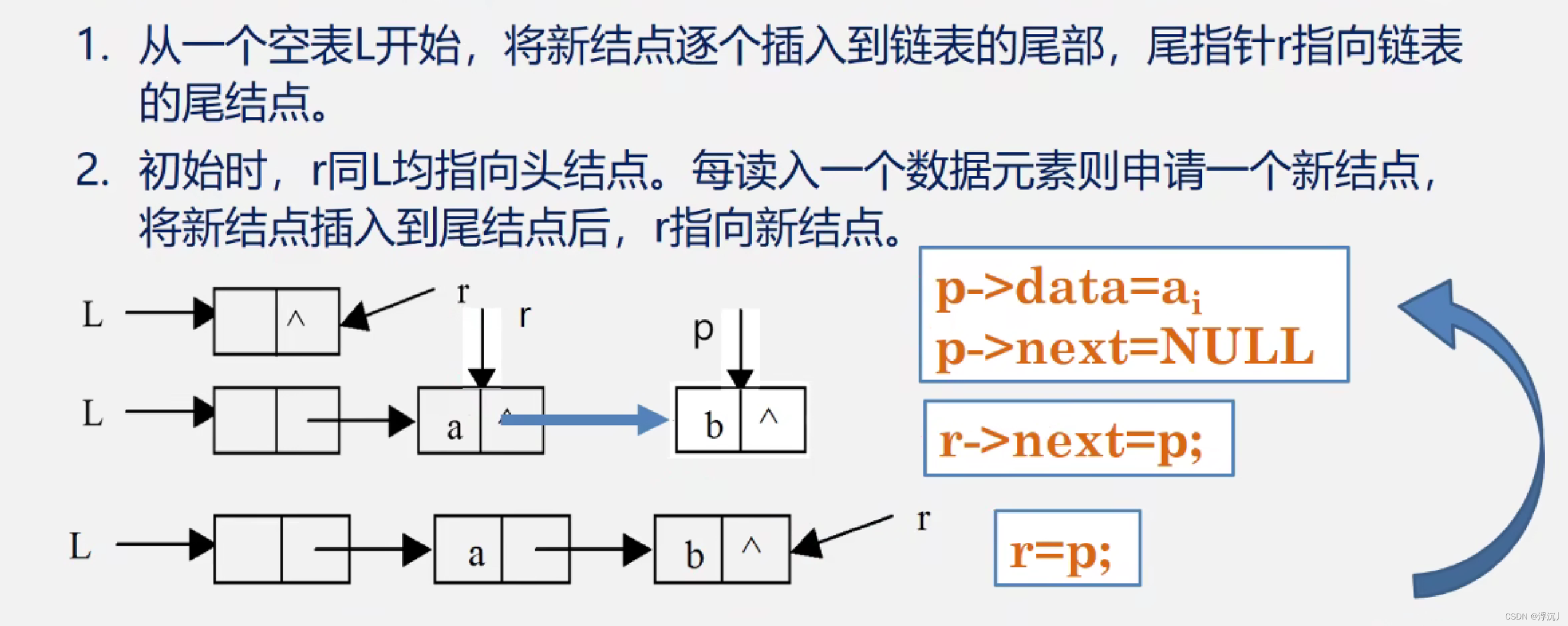
void CreateList_R(LinkList& L, int n)
{
L = (LinkList)malloc(sizeof(ElemType));
assert(L != NULL);
L->next = NULL;
LNode* p, * r; //创建指针p,r p用来产生新节点,r指向链表尾部元素
r = L;
for (int i = 0; i < n; i++)
{
p = (LNode*)malloc(sizeof(ElemType));
assert(p != NULL);
scanf_s("%d", &(p->data));
p->next = NULL;
r->next = p;
r = p; //r指向表尾
}
}
时间复杂度为O(n);
3. 循环链表
循环链表:是一种头尾相接的链表(表中最后一个节点的指针域指向头结点)
思考一下,我们在遍历单链表时的循环结束条件是指针指向NULL,那么使用循环链表遍历时的循环结束条件是什么?当然是遍历链表的指针是否与头指针相等啦!
注意:

3.1 带尾指针的循环链表的合并

LinkList Connect(LinkList &Ta, LinkList &Tb)
{
LNode* p;
p = Ta->next; //p保存Ta的头结点地址
Ta->next = Tb->next->next; //Ta表尾连接Tb的首元结点
free(Tb->next); //释放Tb的头结点
Tb->next = p; //Tb的表尾结点连接Ta的头结点
return Tb; //返回Tb的地址
}
该操作的时间复杂度为O(1)。
4.双向链表
定义:每个结点中还有一个指针域指向其前驱结点的单链表。
双向链表可以解决普通的单链表无法找其前驱结点的问题。
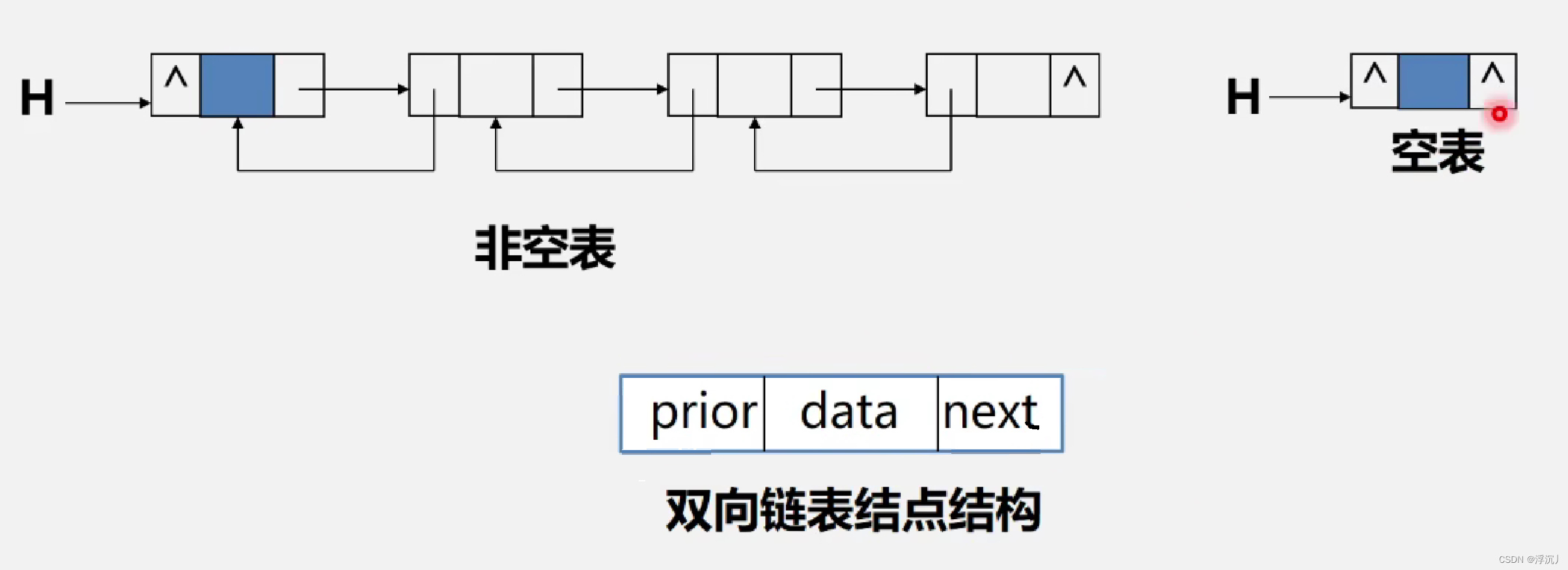
双向链表的结构定义如下:
typedef struct DuNode
{
ElemType data;
DuNode* prior, * next;
}DuNode, * DuLinkList;
4.1 双向循环链表
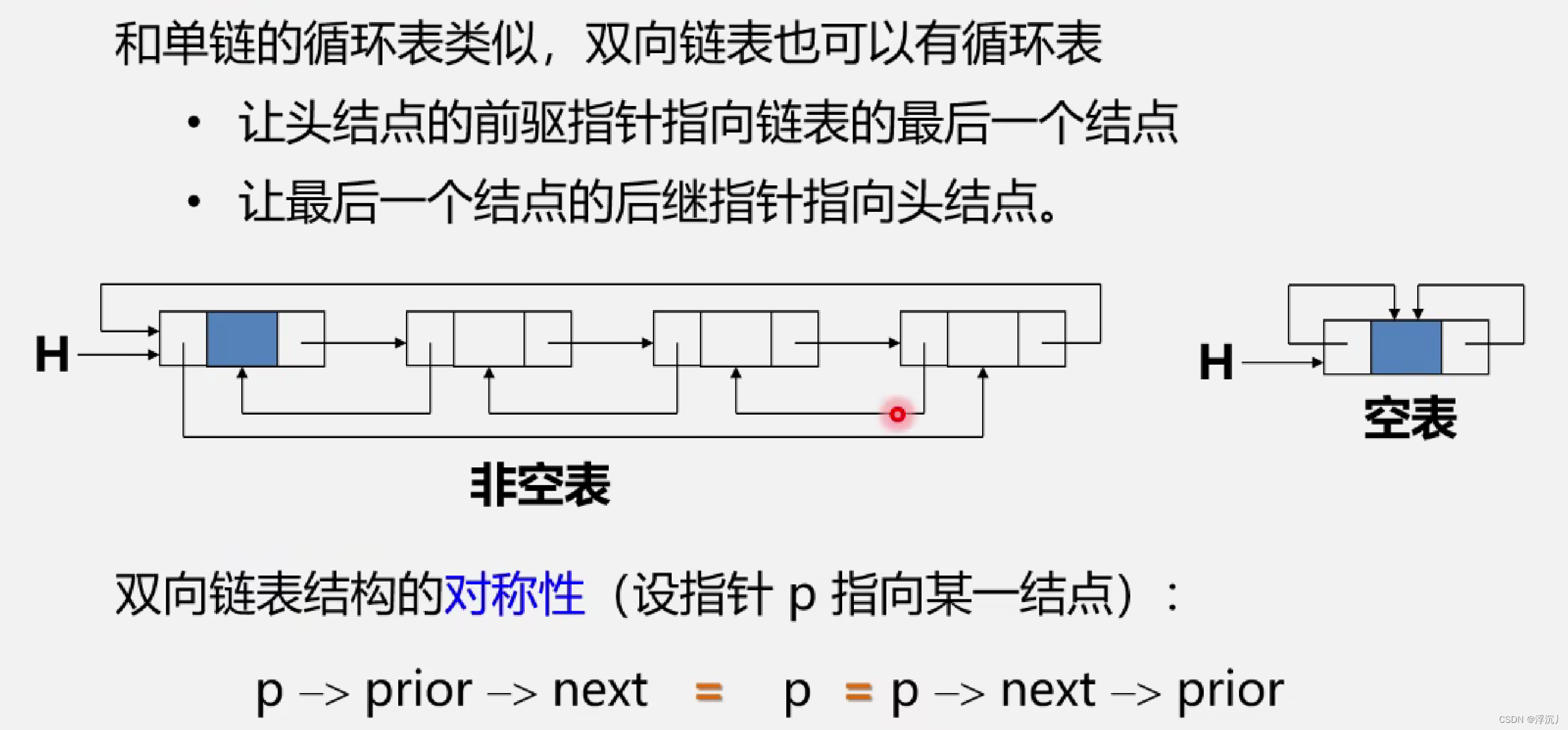
4.2 双向链表的插入算法

int ListInsert_DuL(LinkList& L, int i, ElemType e)
{
DuNode* p, * s;
if (!(p=GetElem_DuL(L, e)))
return ERROR;
s = (DuNode*)malloc(sizeof(DuNode));
s->data = e;
p->prior->next = s; //p结点的前一个结点的next域指向s
s->prior = p->prior; //s结点的prior域指向p结点的前一个结点
s->next = p; //s结点的next域指向p
p->prior = s; //p结点的prior域指向s
return OK;
}
4.3 双向链表的删除算法
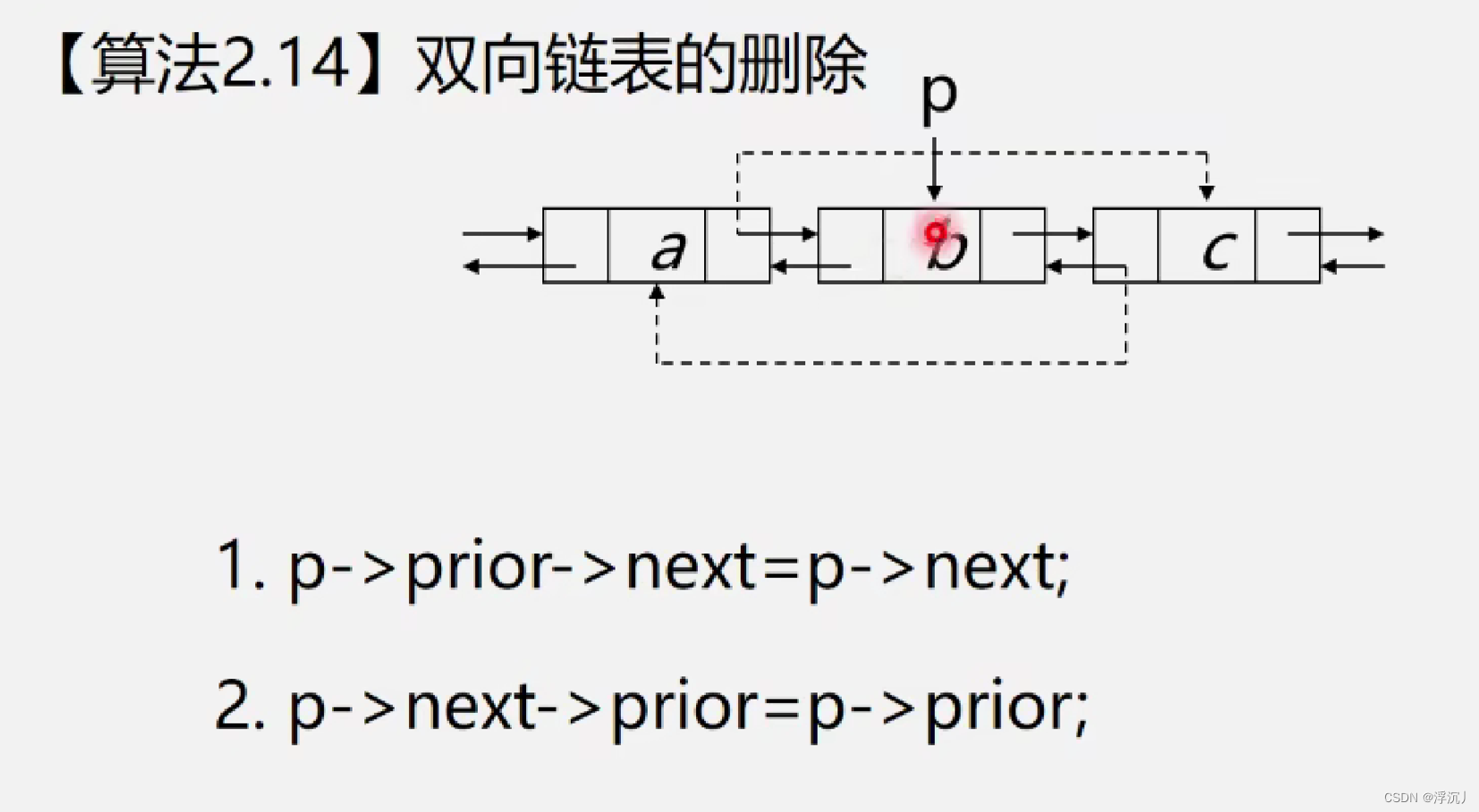
int ListInsert_DuL(LinkList& L, int i, ElemType e)
{
DuNode* p, * s;
if (!(p=GetElem_DuL(L, e)))
return ERROR;
p->prior->next = p->next;
p->next->prior = p->prior;
free(p);
return OK;
}
5.效率比较
5.1 单链表、循环链表和 双向链表的时间效率比较
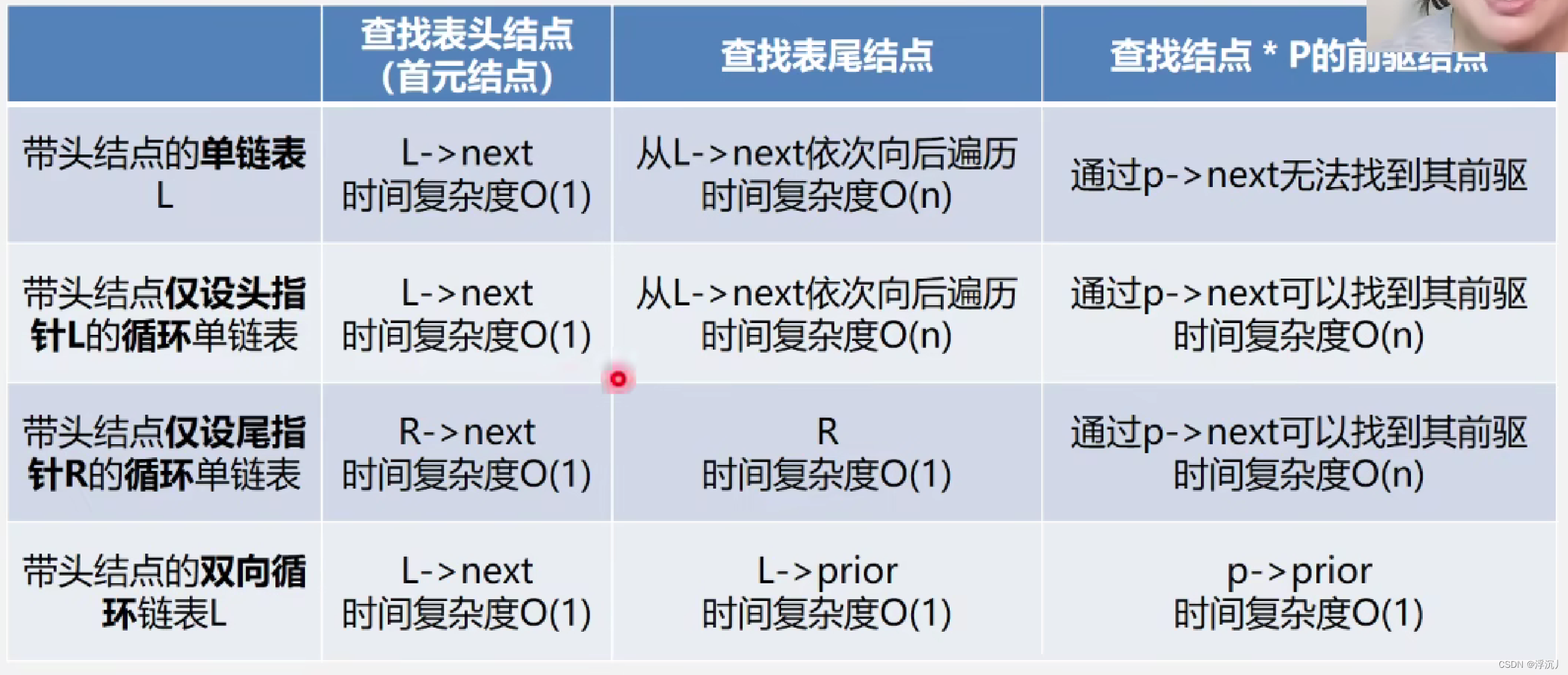
存取相同的数据,双向链表所占用的空间更大,但双向链表的操作所需的时间却更少。这是因为双向链表有两个指针域,所以会产生更多的空间开销。而花费的时间更少,是因为双向链表增加的指针域便利了操作,所以时间复杂度更小(以空间换时间)。
5.2 顺序表与链表的比较

















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











