







任务描述
设计一个识别图片服饰的模型。
数据集
Fashion-MNIST是Zalando的研究论文中提出的一个数据集,由包含60000个实例的训练集和包含10000个实例的测试集组成。每个实例包含一张28x28的灰度服饰图像和对应的类别标记(共有10类服饰)。
服饰图像已经被处理成CSV格式,每行表示一个实例,都由785个值组成,其中后784个(28x28)为像素值。训练集fashion-mnisttrain.csv的第一个值为该实例的类别,测试集fashion-mnisttest.csv的第一个值为该实例的Id,唯一表示该实例。像素值表示像素的黑白强度,取0~255之间的整数。
十种服饰的类别编号:
| 编号 | 类别 | 编号 | 类别 |
| 0 | T-shirt/top | 5 | Sandal |
| 1 | Trouser | 6 | Shirt |
| 2 | Pullover | 7 | Sneaker |
| 3 | Dress | 8 | Bag |
| 4 | Coat | 9 | boot |
ResNet简介
ResNet(Residual Neural Network)是由何凯明等人于2015年提出的一种深度神经网络结构,在计算机视觉领域引起了广泛关注并取得了重大突破。
传统的深度神经网络机构往往将输入数据不断“压缩”成低维特征,表现为“层数越多,模型表达能力越强”,但在实际训练中容易出现梯度消失问题,使得前面的层难以收敛。为了解决这个问题,ResNet提出了残差块的设计,即输入特征图直接和输出特征图相加、产生残差,从而使前向传播更加容易学到恒等映射,从而增加训练效率,并可用更深的网络进行训练和优化。
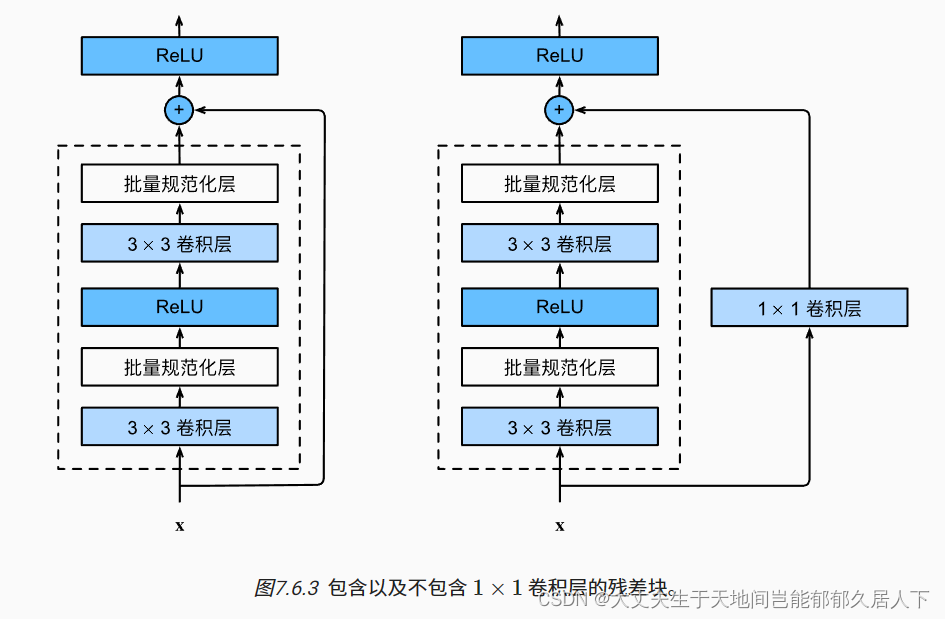
ResNet与传统卷积神经网络的区别主要在于其残差块的设计:每个残差块包含了两个分支,其中一个分支为跨层直连的shortcut,另一个分支则是两个卷积层组成的主干。每个残差块内部采用了Bottleneck设计,即对通道数进行压缩(1x1卷积降维)再进行处理,最后再对通道数进行扩展(1x1卷积升维),并通过Batch Normalization和全局平均池化等技术优化模型。残差块的使用可以训练出更深的神经网络,因此在ResNet中可以轻松地训练超过1000层的深层网络,使得网络的性能和泛化能力有了进一步提高。
与LeNet、AlexNet相比,ResNet是更深的模型,因此具有更好的性能。ResNet通过残差块的设计使得网络可以训练得更深,从而进一步提升了模型的准确度。同时,ResNet还具有更少的参数和计算量,因此具有更好的运行效率。ResNet相比于其他深度网络结构如VGG和GoogleNet网络,具有更少的参数和计算量,其实现效果更高。
残差块
在传统的卷积神经网络模型中,每个层都接收前一层输出的特征图为输入,并且产生一个新的特征图作为下一层的输入。而在ResNet中,每个残差结构(也称为残差块)则将前一个块的特征图与当前块的处理结果进行相加,从而使信号被直接捷径连向下游层。
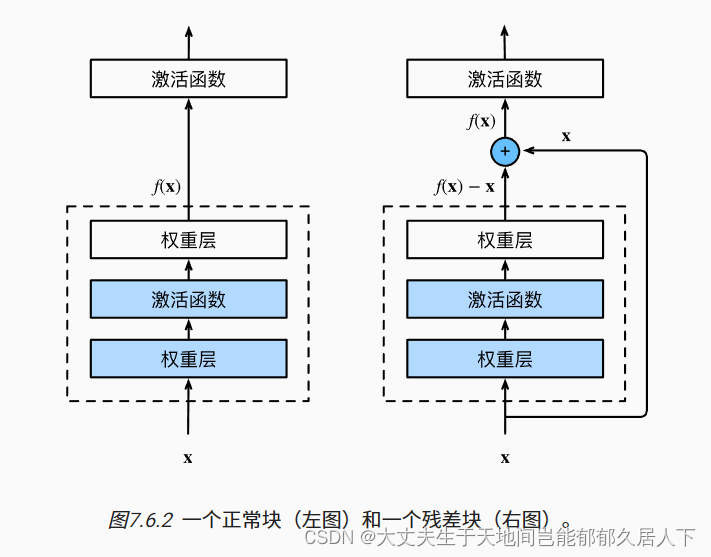
ResNet沿用了VGG完整的3×3卷积层设计。 残差块里首先有2个有相同输出通道数的3×3卷积层。 每个卷积层后接一个批量规范化层和ReLU激活函数。 然后我们通过跨层数据通路,跳过这2个卷积运算,将输入直接加在最后的ReLU激活函数前。 这样的设计要求2个卷积层的输出与输入形状一样,从而使它们可以相加。 如果想改变通道数,就需要引入一个额外的1×1卷积层来将输入变换成需要的形状后再做相加运算。
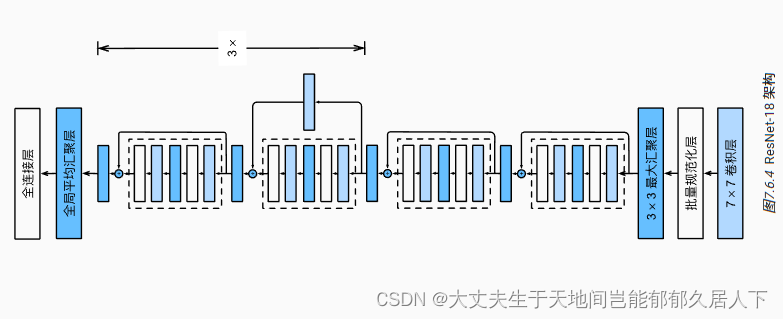
ResNet模型
ResNet的前两层跟GoogLeNet中的一样: 在输出通道数为64、步幅为2的7×7卷积层后,接步幅为2的3×3的最大汇聚层。 不同之处在于ResNet每个卷积层后增加了批量规范化层。
后面接了4使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。 第一个模块的通道数同输入通道数一致。 由于之前已经使用了步幅为2的最大汇聚层,所以无须减小高和宽。 之后的每个模块在第一个残差块里将上一个模块的通道数翻倍,并将高和宽减半。
最后,与GoogLeNet一样,在ResNet中加入全局平均汇聚层,以及全连接层输出。
每个模块有4个卷积层(不包括恒等映射的1×1卷积层)。 加上第一个7×7卷积层和最后一个全连接层,共有18层。 因此,这种模型通常被称为ResNet-18。
ResNet已成为计算机视觉领域中重要的基础模型,衍生出多种不同的版本,包括ResNet-18、ResNet-34、ResNet-50、ResNet-101和ResNet-152等,可根据任务和数据规模的大小选择合适的模型进行训练。
代码实现
导入相关库
#Pytorch 基于ResNet的服饰分类
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
import matplotlib.pyplot as plt
from torchvision.transforms import functional as TF
import random
import os
from torchvision import datasets,models
from torch.utils.data.dataset import Dataset
from PIL import Image
from torch.utils.data import DataLoader
import copy
from d2l import torch as d2l
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
#内存占用过大导致内核死亡,用这个
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
#可以指定CPU 或者GPU重写Dataset类,加载本地csv文件
class DatasetFromCSV(Dataset):
#为了使用pytorch的dataloader进行数据的加载,实现三个函数
# 初始化函数主要用于数据的加载,这里直接使用pandas将数据读取为dataframe,然后将其转成numpy数组来进行索引
def __init__(self, csv_path, height, width, transforms=None):
self.data = pd.read_csv(csv_path)
self.labels = np.asarray(self.data.iloc[:, 0])
self.height = height
self.width = width
self.transforms = transforms
# 会返回单张图片,它包含一个index,返回值为样本及其标签。
def __getitem__(self, index):
single_image_label = self.labels[index]
# 读取所有像素值,并将 1D array ([784]) reshape 成为 2D array ([28,28])
img_as_np = np.asarray(self.data.iloc[index][1:]).reshape(28, 28).astype(float)
# 把 numpy array 格式的图像转换成灰度 PIL image
img_as_img = Image.fromarray(img_as_np)
img_as_img = img_as_img.convert('L')
# 将图像转换成 tensor
if self.transforms is not None:
img_as_tensor = self.transforms(img_as_img)
# 返回图像及其 label
return (img_as_tensor, single_image_label)
# 返回数据集的总数,pytorch里面的datalorder需要知道数据集的总数的
def __len__(self):
return len(self.data.index)加载数据
import numpy as np
import pandas as pd
trans = transforms.Compose([transforms.Resize((224, 224)), transforms.ToTensor()])
train_data= DatasetFromCSV( "../data/fashion-mnist_train.csv", 224,224,trans)#../上一级目录
test_data = DatasetFromCSV("../data/fashion-mnist_test.csv",224,224,trans)
print(len(train_data))拆分训练集和验证集
batch_num = len(train_data) # batch数量
# train_batch_num = round(batch_num * 0.8) # 将80%的batch用于训练,round()函数四舍五入
train_size,validate_size=int(batch_num*0.8),int(batch_num*0.2)
train_size,validate_size
#first param is data set to be saperated, the second is list stating how many sets we want it to be.
train_set,validate_set=torch.utils.data.random_split(train_data,[train_size, 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 812
812

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









