






顺序比较乱,自己会一点一点整理。
循环相关
while循环
语法:
while 表达式
do
done
#!/bin/bash
show_menu(){
echo "show disk info(1)"
echo "show mem info(2)"
echo "show cpu info(3)"
echo "help(4)"
echo "quit(5)"
}
show_menu
while true;
do
read -p "input your choice:" char
case $char in
1)
echo "======disk info======"
df -hT
;;
2)
echo "======memory info======"
free -m
;;
3)
echo "======cpu info======"
uptime
;;
4)
show_menu
;;
5)
exit
;;
esac
done
数组相关
for循环数性别数量案例 ,例子1
jack m
alice f
tom m#数组统计性别示例
#!/bin/bash
declare -A sex
while read line
do
type=`echo $line | awk '{print $2}'`
let sex[$type]++
这个地方实际上是创建一个性别索
引(在sex中的第二行性别为m与f),
当每读到一次不同的性别,性别数组
里对应的‘性别索引’的数值加一。
done <sex.txt
for i in ${!sex[*]}
do
echo "$i:" ${sex[$i]}
done
例子2
#!/bin/bash
declare -A countLogin
while read ii
do
type=`echo $ii | awk -F: '{print $7}'`
let countLogin[$type]++
与上面同理,其目的是读出多个索引作为
不同种类,再对每种不同的种类进行计数。
done < /etc/passwd
for j in ${!countLogin[*]}
do
echo "$j: ${countLogin[$j]}"
done
~ 函数相关
函数无非就是把一些经常使用的代码打包起来,方便重复利用。

hello(){
echo hello word
}
#最简单的函数,定义完以后要再shell运行记得要写出函数名,才会运行。
hello
hello
三剑客
grep,sed,awk
正则表达式
正则表达式(regular expression,RE)是一种字符模式,用于在查找过程中匹配指定的字符。在大多数程序里,正则表达式都被置于两个正斜杠之间;例如/[oO]ve/就是由正斜杠界定的正则表达式,它将匹配被查找的行中任何位置出现的相同模式。在正则表达式中,元字符是最重要的概念。
vim awk等使用
示例
需求:匹配数字的脚本:用户输入创建账号的数量
语法:[[ ^[0-9]+$ ]] #用户必须输入数字
基本元字符
^:行首定位符
示例:定位第一行为root
[root@localhost ~]# cat /etc/passwd | grep "^root"
root:x:0:0:root:/root:/bin/bash
[root@localhost ~]#
$ :行尾定位符
示例:查找文本结尾为love
i love you
i love
love i
[root@localhost ~]# cat 123.txt | grep "love$"
i love
[root@localhost ~]#
. :匹配任意字符
示例:如果一个文本里有abc adc,进行筛选a.c的话将会筛选出abc与adc。
* :匹配前导符(0次到多次)
示例,*与前一个符号组成配合,可以筛选出与其有左边有相同字段的字符
a
ab
abc
abcd
abcde
abcdef
abcdefg
[root@localhost ~]# cat 123.txt | grep "abcde*"
abcd
abcde
abcdef
abcdefg
如果选择abcdef*来进行过滤,那么其实就是abcde字段都是能匹配的到的。
[root@localhost ~]# cat 123.txt | grep "abcdef*"
abcde
abcdef
abcdefg
.* :组合字符,匹配任意字符
示例:
[root@localhost ~]# cat 123.txt | grep ".*"
a
ab
abc
abcd
abcde
abcdef
abcdefg
[ ] :匹配指定范围内的一个字符
示例:对于下面文本
love
Love
1ove
|ove
用括号选中需要匹配的字符
[root@localhost ~]# cat 123.txt | grep "[l1L]ove"
love
Love
1ove
[^]:括号之内加^
取反,,将括号之内的排除
[root@localhost ~]# cat 123.txt | grep "[^l1L]ove"
|ove
\:转义符
俩兄弟:" "与' '(都是转义符,转义一个字段)
脱离其右边字符的意义(如果原来其后的字符有别的意思),例如\. (其目的是匹配一个.)
\< 和 \>:词首定位符和词尾定位符
示例:定位出了第一个词为love的字段

示例:定位出了最后一个词为love的字段

():匹配稍后使用的字符的标签
将原来的192.168.1.1替换为123192
% s/替换内容/替换内容/,这个字段是vim的查找替换功能
\(192\) 转义符是为了避免vim将()认为是可执行的文段
123192.168.1.1
~
~
~
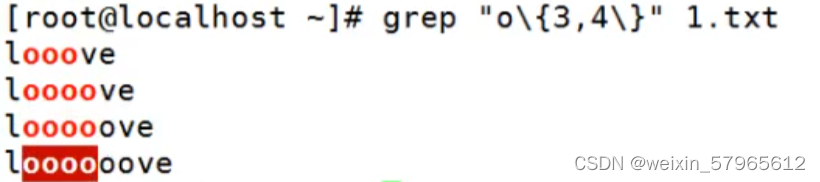
:% s/\(192\)/123\1/x\{m\}:字符x重复出现m次
括弧本身就有含义所以,加上了转义符

x\{m,\}字符x重复出现m次以上
示例大概如下所示
x\{m,n\}字符x重复出现m次以上,n次以下
示例为重复了3次,重复了4次
拓展元子符号
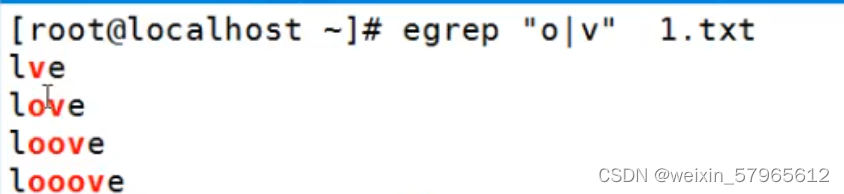
使用时要用egrep
+:匹配1~n个前导字符
示例:与*类似,但是+要求必须出现一次以上

?匹配0~1个前导字符
o可以没有,最多一次

示例
a|b:匹配a或者b
():组字符

众多测试之一
执行这段话以后就是将括弧里第一次组合的词与第二次组合的词语进行顺序上的调换,执行后的结果为:fair and square。

grep相关
找到了寻找的目标,返回值$?为0

流编辑器sed
sed 是一种在线的、非交互式的编辑器,它一次处理一行内容。处理时,把当前处理的行存储在
临时缓冲区中,称为“模式空间”( patternspace),接着用sed命令处理缓冲区中的内容处理完成后,把缓冲区的内容送往屏幕。接着处理下一行,这样不断重复,直到文件末尾。文件内容并没有改变,除非你使用重定向存储输出。sed主要用来自动编辑一个或多个文件;简化对文件的反复操作;
命令格式

sed的返回值一般都是0

示例汇总

删除命令
示例
# sed -r '/root/d' passwd #对这个文件操作
# sed -r '3d'passwd #删除第三行
# sed -r '3{d}' passwd #删除第三行
# sed -r '3{d;}' passwd #删除第三行;后面跟下一步操作
# sed -r '3,$d' passwd #删除三到某一行
# sed -r '$d' passwd #删除最后一行
替换指令
#替换语法:s/#内容/#内容/,替换语法与vim中相同
# sed -r 's/root/aofa/' passwd #将root替换为aofa
[root@localhost ~]# sed -r 's/[0-9][0-9]$/&.5/' passwd.txt #and符号代表查找到的内容。这里是将正则匹配到的内容替换为查找到的内容加.5。
# sed -r 's/^root/aofa/' passwd
# sed -r 's/root/aofa/g' passwd #/g戴
# sed -r 's/[0-9][0-9]$/&.5/' passwd
VI中也有类似功能,
# sed -r 's/(mail)/E\1/g' passwd
sed -r 's#(mail)#E\1#g' passwd对于这种写法:sed -r 's#(mail)#E\1#g' passwd,实际是为了避免在查找替换带有/的内容时,系统误认为第一个/就是s///查找替换的第一个/。

读文件命令:r
sed时逐行读取,如果在第一行r没有加$,那么每一行行尾都会被追加所添加值
# sed -r '$r 1.txt' passwd
# sed -r '/root/r 1.txt' passwd
Vim 中也有类似命令
在当前文件中,读取其他文件“部分”内容写文件命令(另存为):w
# sed -r 'w 111.txt' 1.txt #将111的内容写入1.txt
# sed -r '/root/w 123.txt' passwd #将有root的内容写入passwd.txt
# sed -r '1,5w 123.txt' passwd #将有1到5行的内容写入1.txt追加命令(之后):a(append)
# sed -r 'a123' passwd # 每一行追加123
# sed -r '2a123' passwd #
sed -r'2a 1111\需要连续追加,在追加第一行字的后面加一个转义符\,再按回车即可逐行追加添加
[root@localhost ~]# sed -r '1a 1111\
> 222222\
> 333333' passwd.txt
root:x:0:0:root:/root:/bin/bash1
1111
222222
333333
bin:x:1:1:bin:/bin:/sbin/nologin2
daemon:x:2:2:daemon:/sbin:/sbin/nologin3
adm:x:3:4:adm:/var/adm:/sbin/nologin4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5
sync:x:5:0:sync:/sbin:/bin/sync6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown7
halt:x:7:0:halt:/sbin:/sbin/halt8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin9
operator:x:11:0:operator:/root:/sbin/nologin10插入命令(之前):i(insert)
# sed -r '2iaaaaaaaa' passwd
此时第二行和第三行中间会出现aaaaaaaa
[root@localhost ~]# sed -r '2i232323' passwd.txt
root:x:0:0:root:/root:/bin/bash1
232323
bin:x:1:1:bin:/bin:/sbin/nologin2
若想插入多行,使用方法与a同理
替换整行c
第二行passwd文件被替换成为了222222
sed -r '2c 222222' passwd.txt
root:x:0:0:root:/root:/bin/bash1
222222
daemon:x:2:2:daemon:/sbin:/sbin/nologin3
获取下一行命令:n
# sed -r '/root/{n;d}' passwd
# sed -r '/root/{n;s/bin/ding/g}' passwd
没删除前
root:x:0:0:root:/root:/bin/bash1
bin:x:1:1:bin:/bin:/sbin/nologin2
daemon:x:2:2:daemon:/sbin:/sbin/nologin3
adm:x:3:4:adm:/var/adm:/sbin/nologin4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5
sync:x:5:0:sync:/sbin:/bin/sync6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown7
halt:x:7:0:halt:/sbin:/sbin/halt8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin9
operator:x:11:0:operator:/root:/sbin/nologin10
删除root的下一行之后:
[root@localhost ~]# sed -r '/root/{n;d}' passwd.txt
root:x:0:0:root:/root:/bin/bash1
daemon:x:2:2:daemon:/sbin:/sbin/nologin3
adm:x:3:4:adm:/var/adm:/sbin/nologin4
大括号分割语句,将root的下一行bin替换为ding
[root@localhost ~]# sed -r '/root/{n;s/bin/ding/}' passwd.txt
root:x:0:0:root:/root:/bin/bash1
ding:x:1:1:bin:/bin:/sbin/nologin2
反向选择:!
# sed -r '2,$d' passwd
# sed -r '2,$!d' passwd
例如第一句话将第二行至最后一行删除,第二句话则将第二行和最后一行之外的内容删除。
多重编辑-e
# sed -r '1,3d;4s/adm/admin/g' passwd
效果和下面类似,只不过俩个命令之间用;隔开了,没有多余的操作
# sed -r -e '1,3d' -e '4s/adm/admin/g' passwd
使用-e进行一个指令多重操作,这个指令在删除1到3前加-e,下一个操作“将第四行admin替换成adminnistrator”也加上-e
[root@localhost ~]# sed -r -e '1,3d' -e '4s/admin/administrator/' passwd.txt
adm:x:3:4:adm:/var/adm:/sbin/nologin4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5
sync:x:5:0:sync:/sbin:/bin/sync6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown7
halt:x:7:0:halt:/sbin:/sbin/halt8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin9
operator:x:11:0:operator:/root:/sbin/nologin10
对第二行进行分别进行一次命令
# sed -r 2s/bin/ding/g;2s/nologin/bash/ passwd
对第二行进行俩次命令
# sed -r '2{s/bin/ding/g;s/nologin/bash/} passwd
练习示例:
# sed -r '2,6s/^/#/' a.txt #第二行到第六行行首替换为#
# sed -r '2,6s/(.*)/#\1/' a.txt #第二行到第六行所有字符连接到#的后面
# sed -r '2,6s/.*/#&/' a.txt #第二行到第六行所有字符连接到#的后面
修改vsftp.conf文件1-10行行首,为其添加#
[root@localhost ~]# sed -ri '1,10s/^/#/' /etc/vsftpd/vsftpd.conf
[root@localhost ~]# cat /etc/vsftpd/vsftpd.conf
#anonymous_enable=NO
#local_enable=YES
#write_enable=YES
#local_umask=022
#dirmessage_enable=YES
#xferlog_enable=YES
#connect_from_port_20=YES
#xferlog_std_format=YES
#listen=NO
#listen_ipv6=YES
pam_service_name=vsftpd
userlist_enable=YES
chroot_local_user=Yes
sed使用外部变量
[root@localhost ~]# sed -ri "1a$var1" passwd.txt 这里命令不能不能用单引号,''单引号的强引用会是$var1取不出var1的值。
awk
awk 是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,awk的处理文本和数据的方式是这样的它逐行扫描文件,从第一行到最后一行寻找匹配的特定模式的行,并在这些行上进行你想要的操作。如果没有指定处理动作,则把匹配的行显示到标准输出(屏幕)awk分别代表其作者姓氏的第一个字母。因为它的作者是三个人,分别是Alfred Aho、Peter Weinberger.Kernighan.
工作原理
# awk -F: '{print $1,$3}' /etc/passwd
(1)awk使用一行作为输入,并将这一行赋给内部变量$0,每一行也可称为一个记录,以换行符结束
(2)然后,行被:(默认为空格或制表符)分解成字段(或域),每个字段存储在已编号的变量中从$1开始,最多达100个字段。
(3)awk输出之后,将从文件中获取另一行,并将其存储在$0中,覆盖原来的内容,然后将新的字
符串分隔成字段并进行处理。该过程将持续到所有行处理完毕。
语法
awk [options] 'commands' filenames(推荐)
==options
=command(时空)
BEGIN{} 发生在行处理前(注意大写)
{} 发生行处理模式之时
END {} 发生在行处理前(注意大写)
示例
[root@localhost ~]# awk -F: 'BEGIN{print "work started"}{print $0}END{print"work finished"}' passwd.txt
work started
root:x:0:0:root:/root:/bin/bash1
$var1
bin:x:1:1:bin:/bin:/sbin/nologin2
daemon:x:2:2:daemon:/sbin:/sbin/nologin3
adm:x:3:4:adm:/var/adm:/sbin/nologin4
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin5
sync:x:5:0:sync:/sbin:/bin/sync6
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown7
halt:x:7:0:halt:/sbin:/sbin/halt8
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin9
operator:x:11:0:operator:/root:/sbin/nologin10
work finished















 343
343











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









