







文章目录
进程间通信介绍
进程间通信的本质
进程之间可能会存在特定的协同工作的场景,一个进程要把自己数据交付给另一个进程,让其进行处理,例如:cat test.txt | wc -l cat打印的数据给wc指令进行处理。
每个进程都有一份独立的虚拟地址空间和页表,使得进程具有独立性,一个进程是看到另一个进程的资源,进程交互数据成本一定很高。
此时的进程是不具备通信能力的,就这样的原因,操作系统要设计通信方式。两个进程要互相通信,必须得先看到一份由操作系统管理的公共资源,这里其实就是一段内存,可能以文件方式提供也可能提供的就是原始的内存块,这也就是通信方式有很多种的原因。
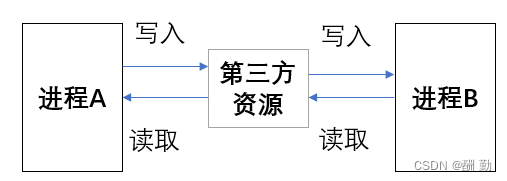
进程间通信目的
- 数据传输:一个进程需要将它的数据发送给另一个进程
- 资源共享:多个进程之间共享同样的资源。
- 通知事件:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)。
- 进程控制:有些进程希望完全控制另一个进程的执行(如Debug进程),此时控制进程希望能够拦截另一个进程的所有陷入和异常,并能够及时知道它的状态改变。
进程间通信分类
管道
- 匿名管道pipe
- 命名管道
System V IPC
- System V 消息队列
- System V 共享内存
- System V 信号量
- POSIX IPC
消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 读写锁
管道
管道的原理
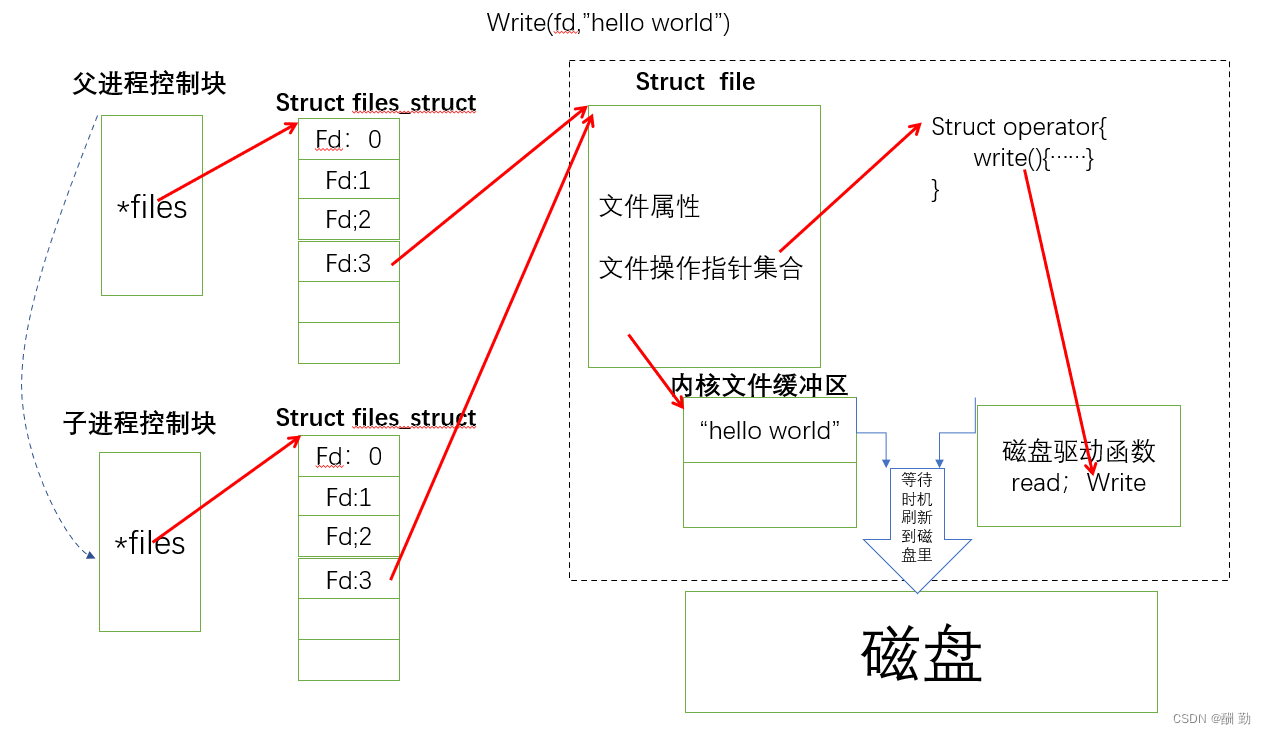 当我们创建子进程时,子进程以父类为模版创建进程控制块。文件以1:n的关系,子进程的files_struct完成父进程的浅拷贝,父子进程指向同一份资源。
当我们创建子进程时,子进程以父类为模版创建进程控制块。文件以1:n的关系,子进程的files_struct完成父进程的浅拷贝,父子进程指向同一份资源。
当我们要完成写入文件时,调用用户层的write(),完成以下两步:1、把数据从用户层拷贝到内核层里。2、触发内核层的write()。
Linux下一切皆文件,这时我们如果不把内核数据刷新到磁盘里,父子进程分别向同一份的文件进行读写操作,进而完成进程通信。
管道是最早期的进程通信方式,操作系统创建了一个特殊的文件,该文件不能写入到磁盘里,但是却能该通过公共的文件的读写方式能够完成进程间数据的交互,达到进程通信。
站在文件描述符角度-深度理解管道
1、父进程创建管道
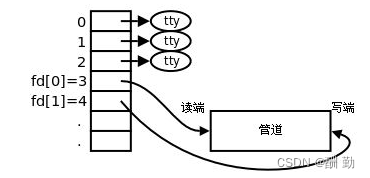
2、父进程fork出子进程
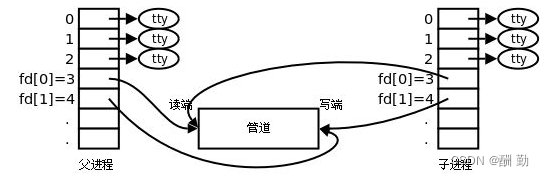
3、父进程关闭fd[0] ,子进程关闭fd[1]
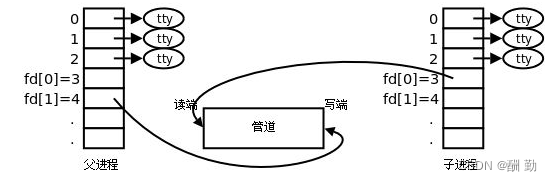
为什么要有两个fd?
如果是以写的方式打开文件,那么子进程继承下去也能写入操作。如果以读写的方式打开文件,因为管道具有单向性,操作系统为了让用户不出错,设定了两个fd,一个是写端,另一个是读端,进程负责读取时就关闭写端,负责写入就关闭读端。
匿名管道pipe
pipe函数
pipe函数用于创建匿名管道,pip函数的函数原型如下:
#include<unistd.h>
int pipe(int pipefd[2]);
pipe函数的参数是一个输出型参数,数组pipefd用于返回两个指向管道读端和写端的文件描述符:
| 数组元素 | 意义 |
|---|---|
| pipefd[0] | 管道读端的文件描述符 |
| pipefd[1] | 管道写端的文件描述符 |
pipe函数调用成功时返回0,调用失败时返回-1。
匿名管道使用步骤
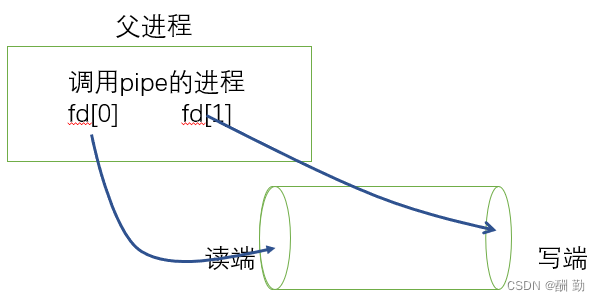
在创建匿名管道实现父子进程间通信的过程中,需要pipe函数和fork函数搭配使用,具体步骤如下:
1、父进程调用pipe函数创建管道。
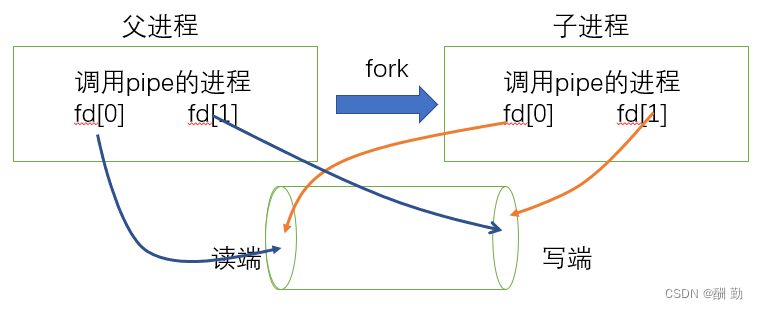
2、父进程创建子进程。
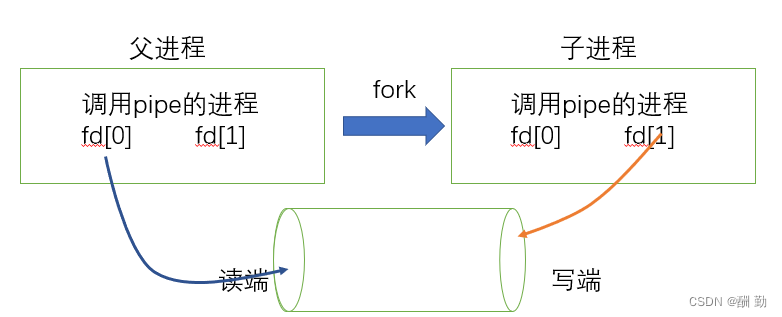
3、父进程关闭写端,子进程关闭读端。
如下代码实现:
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <sys/wait.h>
#include <stdlib.h>
int main()
{
int pipe_fd[2] = {0};
if(pipe(pipe_fd) < 0){
perror("pipe");
return 1;
}
printf("%d, %d\n", pipe_fd[0], pipe_fd[1]);
pid_t id = fork();
if(id < 0){
perror("fork");
return 2;
}
else if(id == 0) {
//write
//child
close(pipe_fd[0]);
const char *msg = "hello parent, I am child";
while(1){
write(pipe_fd[1], msg, strlen(msg)); //strlen(msg) + 1??
sleep(1);
}
close(pipe_fd[1]);
exit(0);
}
else{
//read
//parent
close(pipe_fd[1]);
char buffer[64];
while(1){
sleep(1);
buffer[0] = 0;
ssize_t size = read(pipe_fd[0], buffer, sizeof(buffer)-1);
if(size > 0){
buffer[size] = 0;
printf("parent get messge from child# %s\n", buffer);
}
else if(size == 0){
printf("pipe file close, child quit!\n");
break;
}
else{
//TODO
break;
}
}
close(pipe_fd[0]);
}
return 0;
}
运行结果:

管道读写规则
pipe2函数与pipe函数类似,也是用于创建匿名管道,其函数原型如下:
int pipe2(int pipefd[2], int flags);
pipe2函数的第二个参数用于设置选项。
1、当没有数据可读时:
O_NONBLOCK disable:read调用阻塞,即进程暂停执行,一直等到有数据来为止。
O_NONBLOCK enable:read调用返回-1,errno值为EAGAIN。
2、当管道满的时候:
O_NONBLOCK disable:write调用阻塞,直到有进程读走数据。
O_NONBLOCK enable:write调用返回-1,errno值为EAGAIN。
3、如果所有管道写端对应的文件描述符被关闭,则read返回0。
4、如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程退出。
5、当要写入的数据量不大于PIPE_BUF时,Linux将保证写入的原子性。
6、当要写入的数据量大于PIPE_BUF时,Linux将不再保证写入的原子性。
匿名管道的特点
1、管道的生命周期是随进程的。
2、管道是面向字节流的。(网络部分)
3、具有血缘关系的进程进行进程通信
4、管道自带同步机制,原子性写入。
我们将一次只允许一个进程使用的资源,称为临界资源。管道在同一时刻只允许一个进程对其进行写入或是读取操作,因此管道也就是一种临界资源。
临界资源是需要被保护的,若是我们不对管道这种临界资源进行任何保护机制,那么就可能出现同一时刻有多个进程对同一管道进行操作的情况,进而导致同时读写、交叉读写以及读取到的数据不一致等问题。
为了避免这些问题,内核会对管道操作进行同步与互斥:
- 同步: 两个或两个以上的进程在运行过程中协同步调,按预定的先后次序运行。比如,A任务的运行依赖于B任务产生的数据。
- 互斥: 一个公共资源同一时刻只能被一个进程使用,多个进程不能同时使用公共资源。
实际上,同步是一种更为复杂的互斥,而互斥是一种特殊的同步。对于管道的场景来说,互斥就是两个进程不可以同时对管道进行操作,它们会相互排斥,必须等一个进程操作完毕,另一个才能操作,而同步也是指这两个不能同时对管道进行操作,但这两个进程必须要按照某种次序来对管道进行操作。
也就是说,互斥具有唯一性和排它性,但互斥并不限制任务的运行顺序,而同步的任务之间则有明确的顺序关系。
5、管道是半双工的,数据只能向一个方向流动
在数据通信中,数据在线路上的传送方式可以分为以下三种:
-
单工通信(Simplex Communication):单工模式的数据传输是单向的。通信双方中,一方固定为发送端,另一方固定为接收端。
-
半双工通信(Half Duplex):半双工数据传输指数据可以在一个信号载体的两个方向上传输,但是不能同时传输。
-
全双工通信(Full Duplex):全双工通信允许数据在两个方向上同时传输,它的能力相当于两个单工通信方式的结合。全双工可以同时(瞬时)进行信号的双向传输。
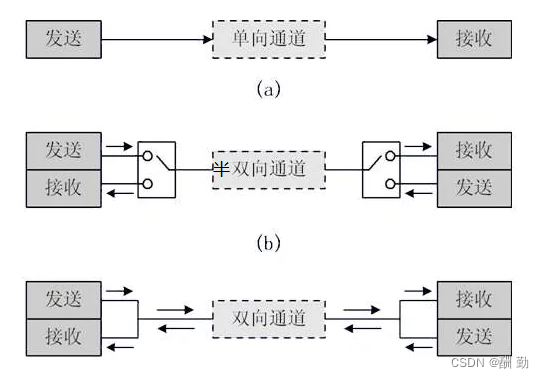
管道是半双工的,数据只能向一个方向流动,需要双方通信时,需要建立起两个管道。
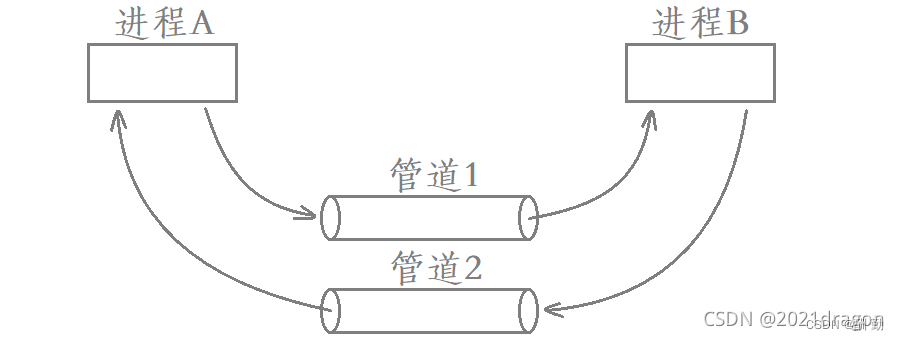
匿名管道的4中情况
1、读端不读或者读的慢,写端要等待读端。
2、读端关闭,写端收到SIGPIPE信号直接终止进程。
3、写端不写或者写的慢,读端要等待写端。
4、写端关闭,读端读完pipe内部的数据然后再读,会读到0,表明读到文件结尾。
其中1和3两种情况就能够很好的说明,管道是自带同步与互斥机制的,读端进程和写端进程是有一个步调协调的过程的,不会说当管道没有数据了读端还在读取,而当管道已经满了写端还在写入。读端进程读取数据的条件是管道里面有数据,写端进程写入数据的条件是管道当中还有空间,若是条件不满足,则相应的进程就会被挂起,直到条件满足后才会被再次唤醒。
第2种情况当我们读端关闭,写端还在写入,此时站在OS的层面,这严重不合理,本质就是在浪费OS的资源,OS会直接终止写入进程,OS给目标发送信号SIGPIPE。
第4中情况,写端关闭,读端下次读取为0时代表数据读取完毕,而且此后也不会有写端再进行写入了,那么此时读端进程也就可以执行该进程的其他逻辑了,而不会被挂起。
匿名管道的大小
读端不读,写端写满后会等待读端读取,我们可以通过这种情况,每次向管道写入一个字节,统计写入次数,即可知道管道大小。
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/wait.h>
int main()
{
int fd[2] = { 0 };
if (pipe(fd) < 0){ //使用pipe创建匿名管道
perror("pipe");
return 1;
}
pid_t id = fork(); //使用fork创建子进程
if (id == 0){
//child
close(fd[0]); //子进程关闭读端
char c = 'a';
int count = 0;
//子进程一直进行写入,一次写入一个字节
while (1){
write(fd[1], &c, 1);
count++;
printf("%d\n", count); //打印当前写入的字节数
}
close(fd[1]);
exit(0);
}
//father
close(fd[1]); //父进程关闭写端
//父进程不进行读取
waitpid(id, NULL, 0);
close(fd[0]);
return 0;
}
可以看到,在读端进程不进行读取的情况下,写端进程最多写65536字节的数据就被操作系统挂起了,也就是说,我当前Linux版本中管道的最大容量是65536字节。
注意:不同版本下,pipe的容量会有所变化。我们可以使用ulimit -a 命令,查找当前资源设定。
命名管道Fifo
命名管道的原理
匿名管道只能在有“血缘关系”的进程间通信。
两个互不关联的进程需要通信时,可以采用文件的方式,A进程把数据写到磁盘文件里,B进程这磁盘文件进行读取,但是读取磁盘效率太低了。两个进程都要找到同一份资源,我们通常采用路径+文件名的方式标识一个磁盘文件,路径+文件名具有唯一性。命名管道就是一种特殊类型的文件,两个进程通过命名管道的文件名打开同一个管道文件,此时可以保证这两个进程看到了同一份资源,进而就可以进行通信了。一旦我们具有了一个命名管道,此时,我们只需要让通信双发按照文件操作即可。
注意:
-
普通文件是很难做到通信的,即便做到通信也无法解决一些安全问题。
-
命名管道和匿名管道一样,都是内存文件,只不过命名管道在磁盘有一个简单的映像,但这个映像的大小永远为0,因为命名管道和匿名管道都不会将通信数据刷新到磁盘当中。
使用命令创建命名管道
我们可以使用mkfifo命令创建一个命名管道。
[BBQ@VM-20-3-centos ~]$ mkfifo fifo
创建出来的文件类型为p,代表管道文件。
我们让一个会话bash往fifo里写入管道,另一个会话读取管道。

mkfifo函数
在程序中创建命名管道使用mkfifo函数,mkfifo函数的函数原型如下:
int mkfifo(const char *pathname, mode_t mode);
函数参数:
- 若pathname以路径的方式给出,则将命名管道文件创建在pathname路径下。
- 若pathname以文件名的方式给出,则将命名管道文件默认创建在当前路径下。(注意当前路径的含义)
- 第二个参数是mode,表示创建命名管道文件的默认权限
若想创建出来命名管道文件的权限值不受umask的影响,则需要在创建文件前使用umask函数将文件默认掩码设置为0。
umask(0); //将文件默认掩码设置为0
函数返回值:
- 名管道创建成功,返回0。
- 命名管道创建失败,返回-1。
mkfifo函数不演示了,后面会涉及。
命名管道的打开规则
1、如果当前打开操作是为读而打开FIFO时。
- O_NONBLOCK disable:阻塞直到有相应进程为写而打开该FIFO。
- O_NONBLOCK enable:立刻返回成功。
2、如果当前打开操作是为写而打开FIFO时。
- O_NONBLOCK disable:阻塞直到有相应进程为读而打开该FIFO。
- O_NONBLOCK enable:立刻返回失败,错误码为ENXIO。
用命名管道实现serve&client通信
实现服务端(server)和客户端(client)之间的通信之前,我们需要先让服务端运行起来,我们需要让服务端运行后创建一个命名管道文件,然后再以读的方式打开该命名管道文件,之后服务端就可以从该命名管道当中读取客户端发来的通信信息了。
client代码:
#pragma once
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#define MY_FIFO "./fifo"
int main()
{
//用不用在创建fifo?? 我只要获取即可
int fd = open(MY_FIFO, O_WRONLY); //不需要O_CREAT
if(fd < 0){
perror("open");
return 1;
}
//业务逻辑
while(1){
printf("请输入# ");
fflush(stdout);
char buffer[64] = {0};
//先把数据从标准输入拿到我们的client进程内部
ssize_t s = read(0, buffer, sizeof(buffer)-1);
if(s > 0){
buffer[s-1] = 0;// s 为实际读取到的字符个,-1 扶着去掉\n
printf("%s\n", buffer);
//拿到了数据,写进管道里
write(fd, buffer, strlen(buffer)); //要不要-1,不需要包含\0,
}
}
close(fd);
return 0;
}
client 负责写入数据,serve负责读取数据,并处理数据。
serve的代码:
#pragma once
#include <stdio.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#define MY_FIFO "./fifo"
int main()
{
// 创建命名管道文件
umask(0);
if(mkfifo(MY_FIFO, 0666) < 0){
perror("mkfifo");
return 1;
}
//只需要文件操作即可
int fd = open(MY_FIFO, O_RDONLY);
if(fd < 0){
perror("open");
return 2;
}
//业务逻辑,可以进行对应的读写了
while(1){
char buffer[64] = {0};
sleep(50);
ssize_t s = read(fd, buffer, sizeof(buffer)-1); //键盘输入的时候,\n也是输入字符的一部分
if(s > 0){
//success
buffer[s] = 0;
if(strcmp(buffer, "show") == 0){
if(fork() == 0){
execl("/usr/bin/ls", "ls", "-l", NULL);
exit(1);
}
waitpid(-1, NULL, 0);
}
else if(strcmp(buffer, "run") == 0){
if(fork() == 0){
execl("/usr/bin/sl", "sl", NULL);
}
waitpid(-1, NULL, 0);
}
else{
printf("client# %s\n", buffer);
}
}
else if(s == 0){//读取字符个数为0,client端关闭了。
//peer close
printf("client quit ...\n");
break;
}
else{
//error
perror("read");
break;
}
}
close(fd);
return 0;
}
我们给serve 端 实现了简单的功能,读取到的数据为“run”就去执行sl指令,读取到的数据为“show” 就去执行ls -l 的指令。
这样就比较有意思了,我们可以通过一个进程来控制另一个进程的行为。
命名管道和匿名管道的区别
1、匿名管道由pipe函数创建并打开。
2、命名管道由mkfifo函数创建,由open函数打开。
3、命名管道(FIFO)与匿名管道(pipe)之间唯一的区别在于它们创建与打开的方式不同,一旦这些工作完成之后,它们具有相同的语义。
system V进程间通信
管道通信本质是基于文件的通信方式,也就是说操作系统并没有对进程通信做过多的设计工作,而system V IPC 是操作系统专门设计的一种通信方式。但是不管怎么样,它们的本质都是一样的,都是在想尽办法让不同的进程看到同一份由操作系统提供的资源。
system V IPC提供的通信方式有以下三种:
- system V共享内存
- system V消息队列
- system V信号量
其中,system V共享内存和system V消息队列是以传送数据为目的的,而system V信号量是为了保证进程间的同步与互斥而设计的,虽然system V信号量和通信好像没有直接关系,但属于通信范畴。system V属 于OS层,OS为了给用户使用,OS一定会给用户提供系统接口。
system V共享内存
每个进程都有自己独立的地址空间和页表,进程间的数据结构独立并且数据和代码也是独立的。
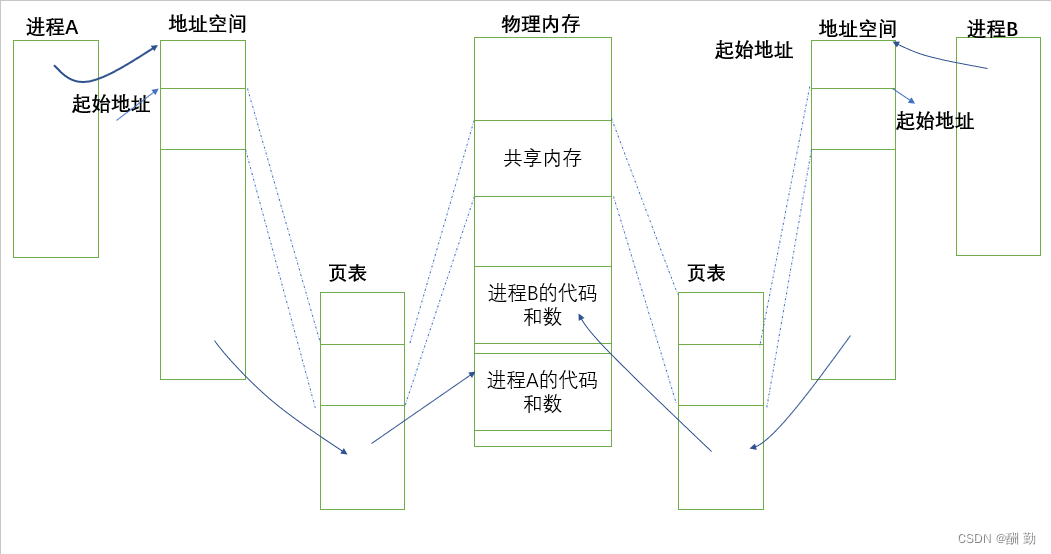
共享内存的方案步骤:
1、在物理内存中创建一块内存空间。
2、通过某种调用让参与通信的多个进程“挂接”到这份新开辟的空间上。
此时让不同的进程看到了同一份资源。
OS内存可能存在多个进程,同时使用不同的共享内存来进行进程间通信(n:m),共享内存在系统中可能存在多份,操作系统需要管理好共享内存,所以不仅要开辟空间,还要有这块空间的数据结构描述,有了ds后,OS对共享内存空间的增删改就变的特别简单了。
怎么保证,两个或多个进程,看到的是同一份共享内存?
在管道里,匿名管道通过继承,命名管道通过路径+文件名的方式打开同一个管道文件。我们要达到的目的就是让通信进程能找到同一份资源。虽然我们没有学下面的内容但是我们可以猜测出,共享内存一定要有一定的标识唯一性的ID,方便让不同的进程能识别同一个共享内存资源。 标识唯一性的ID存在与描述共享内存空间的数据结构里。
3、去关联(去挂接)
4、释放共享内存
共享内存数据结构
共享内存的数据结构如下:
struct shmid_ds {
struct ipc_perm shm_perm; /* operation perms */
int shm_segsz; /* size of segment (bytes) */
__kernel_time_t shm_atime; /* last attach time */
__kernel_time_t shm_dtime; /* last detach time */
__kernel_time_t shm_ctime; /* last change time */
__kernel_ipc_pid_t shm_cpid; /* pid of creator */
__kernel_ipc_pid_t shm_lpid; /* pid of last operator */
unsigned short shm_nattch; /* no. of current attaches */
unsigned short shm_unused; /* compatibility */
void *shm_unused2; /* ditto - used by DIPC */
void *shm_unused3; /* unused */
};
当我们申请了一块共享内存后,为了让要实现通信的进程能够看到同一个共享内存,因此每一个共享内存被申请时都有一个key值,这个key值用于标识系统中共享内存的唯一性。
可以看到上面共享内存数据结构的第一个成员是shm_perm,shm_perm是一个ipc_perm类型的结构体变量,每个共享内存的key值存储在shm_perm这个结构体变量当中,其中ipc_perm结构体的定义如下:
struct ipc_perm{
__kernel_key_t key;
__kernel_uid_t uid;
__kernel_gid_t gid;
__kernel_uid_t cuid;
__kernel_gid_t cgid;
__kernel_mode_t mode;
unsigned short seq;
};
共享内存的创建
创建共享内存我们需要用shmget函数,shmget函数的函数原型如下:
int shmget(key_t key, size_t size, int shmflg);
shmget函数的参数说明:
- 第一个参数key,表示待创建共享内存在系统当中的唯一标识。
- 第二个参数size,表示待创建共享内存的大小。
- 第三个参数shmflg,表示创建共享内存的方式。
shmget函数的返回值说明:
- shmget调用成功,返回一个有效的共享内存标识符(用户层标识符shmid)。
- shmget调用失败,返回-1。
注意: 我们把具有标定某种资源能力的东西叫做句柄,而这里shmget函数的返回值实际上就是共享内存的句柄,这个句柄可以在用户层标识共享内存,当共享内存被创建后,我们在后续使用共享内存的相关接口时,都是需要通过这个句柄对指定共享内存进行各种操作。
传入shmget函数的第一个参数key,需要我们使用ftok函数进行获取
ftok函数的函数原型如下:
key_t ftok(const char *pathname, int proj_id);
ftok函数的作用就是,将一个已存在的路径名pathname和一个整数标识符proj_id转换成一个key值,称为IPC键值,在使用shmget函数获取共享内存时,这个key值会被填充进维护共享内存的数据结构当中。需要注意的是,pathname所指定的文件必须存在且可存取。
注意:
- 使用ftok函数生成key值可能会产生冲突,此时可以对传入ftok函数的参数进行修改。
- 需要进行通信的各个进程,在使用ftok函数获取key值时,都需要采用同样的路径名和和整数标识符,进而生成同一种key值,然后才能找到同一个共享资源。
传入shmget函数的第三个参数shmflg,常用的组合方式有以下两种:
| 组合方式 | 作用 |
|---|---|
| IPC_CREAT | 使用组合IPC_CREAT,一定会获得一个共享内存的句柄,但无法确认该共享内存是否是新建的共享内存。 |
| IPC_CREAT | IPC_EXCL | 使用组合IPC_CREAT | IPC_EXCL,只有shmget函数调用成功时才会获得共享内存的句柄,并且该共享内存一定是新建的共享内存。 |
如下代码演示创建共享内存过程:
common.h文件
#include<sys/shm.h>
#include<sys/ipc.h>
#include<stdio.h>
#include<sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
#define PATH_NAME "./" //必须是路径,普通字符串不可以
#define PROJ_ID 0x666
#define SIZE 4097
#include"commom.h"
int main()
{
key_t key =ftok(PATH_NAME,PROJ_ID);
if(key<0)
{
perror("ftok():");
return 1;
}
// 创建共享内存
int shmid=shmget(key,SIZE,IPC_CREAT|IPC_EXCL);// 创建一个全新的共享内存,如果key对应的共享内存已存在,哪买返回-1;
if(shmid<0)
{
perror("shmget()");
return 1;
}
printf("key:%d\n",key);
printf("shmid:%d\n",shmid);
return 0;
}
运行代码后,在Linux当中,我们可以使用ipcs命令查看有关进程间通信设施的信息。
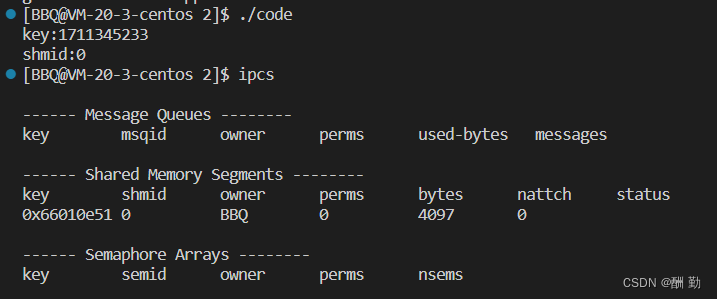
ipcs命令用于报告Linux中进程间通信设施的状态,显示的信息包括消息列表、共享内存和信号量的信息。
-a:显示全部可显示的信息;
-q:显示活动的消息队列信息;
-m:显示活动的共享内存信息;
-s:显示活动的信号量信息。
此时,根据ipcs命令的查看结果和我们的输出结果可以确认,共享内存已经创建成功了。
ipcs命令输出的每列信息的含义如下:
| 标题 | 含义 |
|---|---|
| key | 系统区别各个共享内存的唯一标识 |
| shmid | 共享内存的用户层id(句柄) |
| owner | 共享内存的拥有者 |
| perms | 共享内存的权限 |
| bytes | 共享内存的大小 |
| nattch | 关联共享内存的进程数 |
| status | 共享内存的状态 |
注意:
- key只是用来再系统层面进行标识唯一性的,不能用来管理共享内存。
- shmid是OS给用户返回的id,用来在用户层进程共享内存管理。
- shmid和key之间的关系类似于fd和file*之间的的关系
- systemV的IPC资源,生命周期是随内核的。只能通过,程序员显示的释放(命令,system call)或者是OS重启。
共享内存的销毁
控制共享内存我们需要用shmctl函数,shmctl函数的函数原型如下:
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
shmctl函数的参数说明:
- 第一个参数shmid,表示所控制共享内存的用户级标识符。
- 第二个参数cmd,表示具体的控制动作。
- 第三个参数buf,用于获取或设置所控制共享内存的数据结构。
shmctl函数的返回值说明:
- shmctl调用成功,返回0。
-
shmctl调用失败,返回-1。
其中,作为shmctl函数的第二个参数传入的常用的选项有以下三个:
| 选项 | 作用 |
|---|---|
| IPC_STAT | 获取共享内存的当前关联值,此时参数buf作为输出型参数 |
| IPC_SET | 在进程有足够权限的前提下,将共享内存的当前关联值设置为buf所指的数据结构中的值 |
| IPC_RMID | 删除共享内存段 |
如下代码销毁共享内存的过程:
#include"commom.h"
int main()
{
key_t key =ftok(PATH_NAME,PROJ_ID);
if(key<0)
{
perror("ftok():");
return 1;
}
// 创建共享内存
int shmid=shmget(key,SIZE,IPC_CREAT);// 创建一个全新的共享内存
if(shmid<0)
{
perror("shmget()");
return 1;
}
printf("key:%d\n",key);
printf("shmid:%d\n",shmid);
int ret =shmctl(shmid,IPC_RMID,NULL);
if(ret<0)
{
perror("shmctl()");
return 1;
}
printf("key%d,shmid:%d->destory\n",key,shmid);
return 0;
}
运行结果:
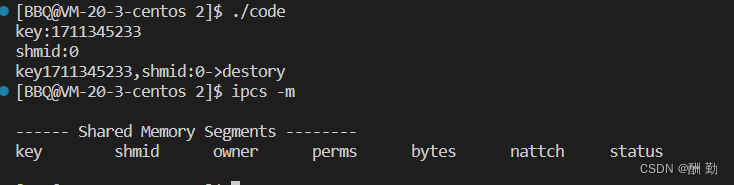
通过
ipcrm指令来销毁共享内存
ipcrm命令用来删除一个或更多的消息队列、信号量集或者共享内存标识。
选项:
-m SharedMemory id 删除共享内存标识 SharedMemoryID。与 SharedMemoryID 有关联的共享内存段以及数据结构都会在最后一次拆离操作后删除。
如图演示:

共享内存的关联
将共享内存连接到进程地址空间我们需要用shmat函数,shmat函数的函数原型如下:
void *shmat(int shmid, const void *shmaddr, int shmflg);
shmat函数的参数说明:
- 第一个参数shmid,表示待关联共享内存的用户级标识符。
- 第二个参数shmaddr,指定共享内存映射到进程地址空间的某一地址,通常设置为NULL,表示让内核自己决定一个合适的地址位置。
- 第三个参数shmflg,表示关联共享内存时设置的某些属性。
shmat函数的返回值说明:
- shmat调用成功,返回共享内存映射到进程地址空间中的起始地址。
- shmat调用失败,返回(void*)-1。
其中,作为shmat函数的第三个参数传入的常用的选项有以下三个:
| 选项 | 作用 |
|---|---|
| SHM_RDONLY | 关联共享内存后只进行读取操作 |
| SHM_RND | 若shmaddr不为NULL,则关联地址自动向下调整为SHMLBA的整数倍。公式:shmaddr-(shmaddr%SHMLBA) |
| 0 | 默认为读写权限 |
这时我们可以尝试使用shmat函数对共享内存进行关联。
#include"commom.h"
int main()
{
umask(0);
key_t key =ftok(PATH_NAME,PROJ_ID);
if(key<0)
{
perror("ftok():");
return 1;
}
int shmid=shmget(key,SIZE,IPC_CREAT | IPC_EXCL | 0666);// 创建一个权限为0666的共享内存
if(shmid<0)
{
perror("shmget()");
return 1;
}
printf("key:%d\n",key);
printf("shmid:%d\n",shmid);
// 关联共享内存返回虚拟地址
char * mem = (char*)shmat(shmid,NULL,0);
if((void*)mem==(void*)-1)
{
perror("shmat");
return 1;
}
printf("attach success\n");
sleep(10);
printf("sleep() exit()\n");
int ret =shmctl(shmid,IPC_RMID,NULL);
if(ret<0)
{
perror("shmctl()");
return 1;
}
printf("key%d,shmid:%d->destory\n",key,shmid);
return 0;
}
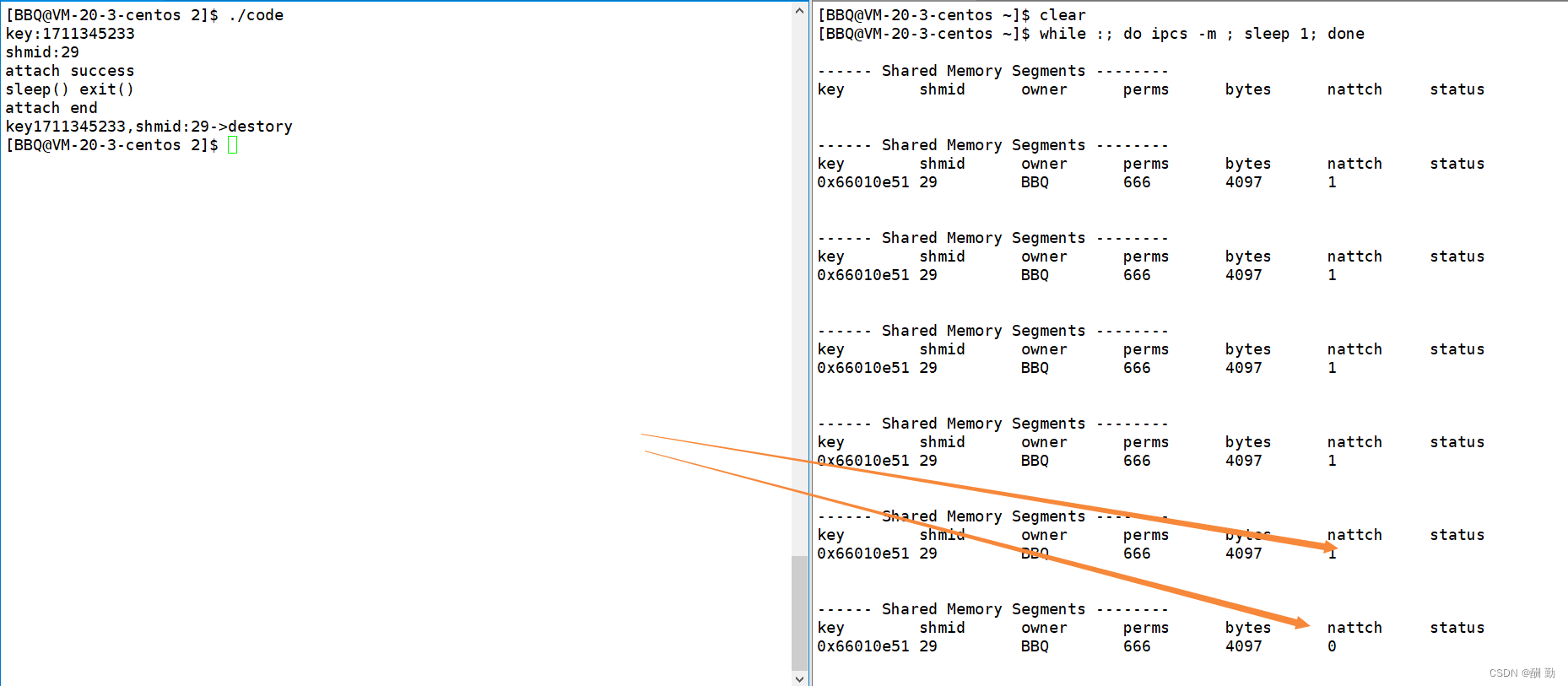
 注意:
注意:
- 进程结束后关联的共享内存 nattch会-1,即系统默认会去关联
共享内存的去关联
取消共享内存与进程地址空间之间的关联我们需要用shmdt函数,shmdt函数的函数原型如下:
int shmdt(const void *shmaddr);
shmdt函数的参数说明:
- 待去关联共享内存的起始地址,即调用shmat函数时得到的起始地址。
shmdt函数的返回值说明:
- shmdt调用成功,返回0。
- shmdt调用失败,返回-1。
现在我们就能够取消共享内存与进程之间的关联了。
#include"commom.h"
int main()
{
umask(0);
key_t key =ftok(PATH_NAME,PROJ_ID);
if(key<0)
{
perror("ftok():");
return 1;
}
int shmid=shmget(key,SIZE,IPC_CREAT | IPC_EXCL | 0666);// 创建一个权限为0x666的共享内存
if(shmid<0)
{
perror("shmget()");
return 1;
}
printf("key:%d\n",key);
printf("shmid:%d\n",shmid);
// 关联共享内存返回虚拟地址
char * mem = (char*)shmat(shmid,NULL,0);
if((void*)mem==(void*)-1)
{
perror("shmat");
return 1;
}
printf("attach success\n");
sleep(5);
printf("sleep() exit()\n");
shmdt(mem);
printf("attach end \n");
sleep(5);
int ret =shmctl(shmid,IPC_RMID,NULL);
if(ret<0)
{
perror("shmctl()");
return 1;
}
printf("key%d,shmid:%d->destory\n",key,shmid);
return 0;
}
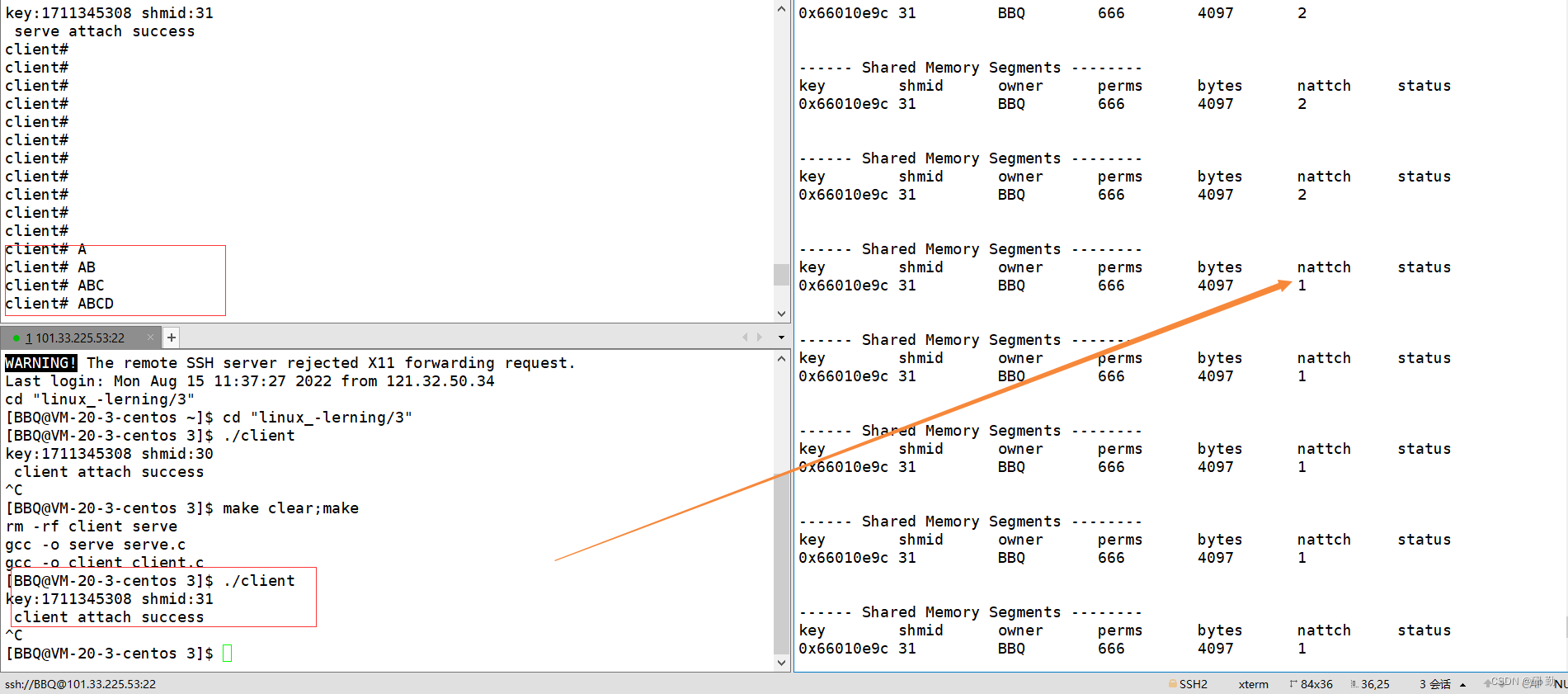
用共享内存实现serve&client通信
让两个进程通过共享内存进行通信了。在让两个进程进行通信,服务端负责创建共享内存,创建好后将共享内存和服务端进行关联,之后进入死循环,便于观察服务端是否挂接成功。
为了让服务端和客户端都能获取同一个共享内存,在使用ftok函数获取key值时,保证ftok两个参数都能保持一样就能够得到同一种key值,进而找到同一个共享资源进行挂接。这里我们可以将这些需要共用的信息放入一个头文件当中,服务端和客户端共用这个头文件即可。
服务端代码如下:
#include"commom.h"
int main()
{
umask(0);
key_t key =ftok(PATH_NAME,PROJ_ID);
if(key<0)
{
perror("ftok():");
return 1;
}
int shmid=shmget(key,SIZE,IPC_CREAT | IPC_EXCL | 0666);// 创建一个权限为0x666的共享内存
if(shmid<0)
{
perror("shmget()");
return 1;
}
// 关联共享内存返回虚拟地址
char * mem = (char*)shmat(shmid,NULL,0);
if((void*)mem==(void*)-1)
{
perror("shmat");
return 1;
}
printf(" serve attach success\n");
// 进程通信过程
while(1)
{
//..
//服务端不断读取共享内存当中的数据并输出
while (1)
{
printf("client# %s\n", mem);
sleep(1);
}
}
shmdt(mem);
int ret =shmctl(shmid,IPC_RMID,NULL);
return 0;
}
客户端代码如下:
#include"commom.h"
int main()
{
umask(0);
key_t key =ftok(PATH_NAME,PROJ_ID);
if(key<0)
{
perror("ftok():");
return 1;
}
int shmid=shmget(key,SIZE,IPC_CREAT);// 创建一个权限为0x666的共享内存
if(shmid<0)
{
perror("shmget()");
return 1;
}
// 关联共享内存返回虚拟地址
char * mem = (char*)shmat(shmid,NULL,0);
if((void*)mem==(void*)-1)
{
perror("shmat");
return 1;
}
// 进程通信过程
while(1)
{
//..
//客户端不断向共享内存写入数据
int i = 0;
while (1)
{
mem[i] = 'A' + i;
i++;
mem[i] = '\0';
sleep(1);
}
}
shmdt(mem);
return 0;
}
运行结果:
共享内存的特点
1、systemV 的IPC资源,生命周期是随内核的。
2、 共享内存是所有的进程通信中速度最快的。
例如:read或者write的本质:将数据从内核拷贝到用户,或者从用户拷贝到内核期间发生多次拷贝。共享内存一旦建立好并映射进自己进程的地址空间,改进程就可以直接看到该共享内存,就如同malloc的空间一般,不需要任何系统调用接口。
3、共享内存不提供任何同步或者互斥机制,需要程序员自行保证数据的安全。
例如:当client没有写入时,甚至没有启动的时候,server端直接读取共享内存,没有等待client的等待。
4、共享内存在内核中申请的基本单位是页(4KB)。
例如:申请4097个字节,内核会给你4096*2个字节。
为何我们看到的shmid是0,1,2,3,4,……?(了解)
内核数据结构用数组来管理system V ipc,所有的System V标准的IPC资源,XXXid_ds结构体的第一个成员都是ipc_perm,并且接口类似。如图所示:

数组为 struct ipc_perm * ipc_id_arr[],虽然system V ipc的结构体都不一样,但是第一个元素是一样的,所以该数组存储 struct ipc_perm * 类型,ipc_id_arr[0]=(struct ipc_perm * ) &shmid_ds;一旦我们需要管理某个IPC,操作系统只需要强转一下类型,就能访问到IPC的其他成员。类似于C++的切片。
如图简单演示:

system V消息队列(了解)
- 息队列提供了一个从一个进程向另外一个进程发送一块数据的方法
- 每个数据块都被认为是有一个类型,接收者进程接收的数据块可以有不同的类型值
- 特性方面
-
- IPC资源必须删除,否则不会自动清除,除非重启,所以system V IPC资源的生命周期随内核
system V信号量(了解)
感性认识:
1、什么是临界资源
凡是要进程通信,必定要引入被多个进程看到的资源(通信需要),同时,也就造就了一个问题,临界资源的问题。
凡是被多个执行流同时能够访问的资源就是临界资源。例如:同时向显示器打印,进程间通信,管道,system V IPC等,都要临界资源。
2、什么是临界区
用来访问临界资源的代码,就叫临界区。
3、什么是原子性
一件事情要么不做,要做就做完,没有中间态。
4、什么是信号量
管道,匿名or命名,共享内存,消息队列:都是以传输数据为目的的!信号量不是以传输数据为目的的。通过共享“资源”的方式,来达到多个进程的同步和互斥的目的。
信号量的本质,是一个计数器,类似 int count;来衡量临界资源的数目。
例如电影院的场景:有100个用户买了票,但是电影院只有90个座位,为了不让用户之间发生纠纷,我们需要一个计数器,每当一个人进去以后,就–,当减到0以后,不能进去了,出来就++,计数器是要被所有的用户访问的,所以计数器也是一个临界资源,临界资源是不安全的非原子性,在计算机里–,++的操作,都不是原子的,在操作的过程中需要被执行好几步,如果中途被打断,那么计数器的数值就是错误了,所以计数器在–,++操作时必须让其具有原子性,进而就能让电影院不会出现问题。
为了保护数据的安全,有了信号量,信号量两层含义:1、统计次数,2、衡量资源数目,
保护好临界资源,我们可以给管理这个资源的数据结构添加信号量成员。初步的了解,学到多线程才能理解。
如下伪代码为:二元信号量根后面学习的互斥锁类似。场景:一份资源在一个时刻只能给一个执行流使用。
sem:信号量
sem=1
if(sum>0){
sem
}
else{
//等待
}
sem++;//等待成功















 1624
1624











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











