






最近尝试新的模型中,要求Voxceleb2数据集的格式为.wav,而原文件的格式为.m4a格式,需要进行转换。其实网上是有相关的开源工程的,https://github.com/clovaai/voxceleb_trainer,但是由于这个作者的注释写的非常少,在没有人帮助的情况下我也看不太懂多少,只能自己根据https://www.robots.ox.ac.uk/~vgg/data/voxceleb/meta/train_list.txt所提供的trainlist列表自行转换。
于是,我写了如下代码:
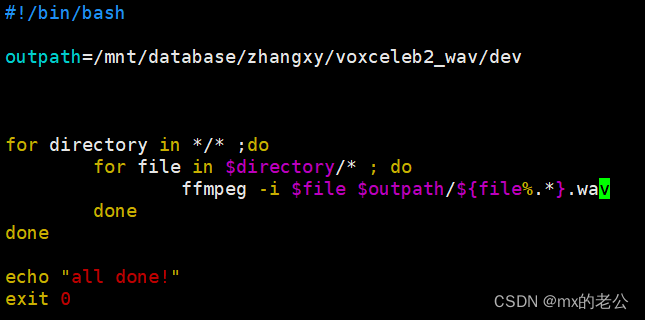
目的文件夹的创建部分,在我做完之后就已经删除了。我是直接将原文件生成wav格式之后,改一个后缀名就放在了目录下面。
但是在我跑了一晚上之后才发现,原本数据集的音频标号方式是每个video编一个号码,而trainlist中是每一个人编一个号码。不能用简单的直接将原始的m4a文件换个后缀就直接生成,还要涉及到一个编号的问题。
于是我稍加调整,更改的代码如下:
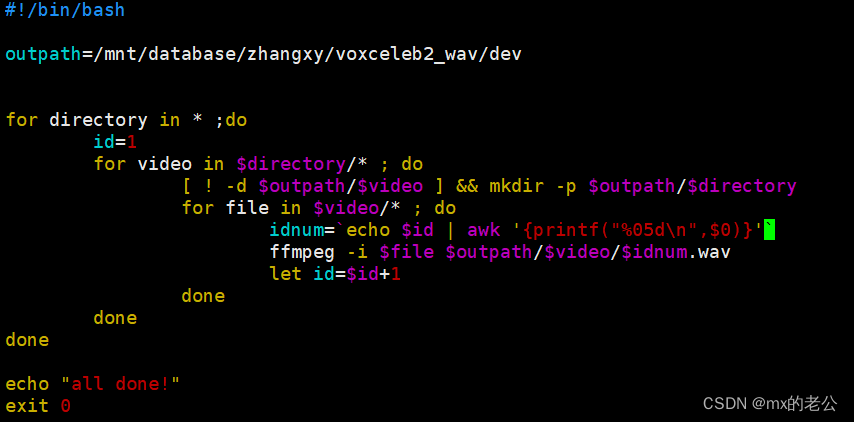
这样就按文件顺序,按说话人生成连续编号的wav文件了。
但是在跑了一段脚本之后,我进行检查发现,我的编号和list中的编号不一致。仔细检查才发现,原来trainlist中的排序顺序是0-9-A-Z-a-z-*,而linux系统下的文件排序顺序则是0-9-Aa-Zz-*。会导致不同目录下的标号顺序是交错的。
因此不能直接按照原始的数据集文件进行直接生成,还是需要读取trainlist文件,按行生成连续编号的wav文件。
#!/bin/bash
outpath=------- # 你自己的目录
listfile=-------/train_list.txt # 你存放的trianlist的位置for directory in */* ; do
[ ! -d $outpath/$video ] && mkdir -p $outpath/$directory
done
while read line ; do
wav=`echo $line | awk '{printf($2)}'`
m4a=${wav%.*}.m4a
[ -f $m4a ] && [ ! -f $outpath/$wav ] && ffmpeg -y -i $m4a -ac 1 -vn -acodec pcm_s16le -ar 16000 $outpath/$wav[ ! -f $m4a ] && echo -e "\n\n\n\nit went wrong! can not found $m4a!\n" && exit 0
done < $listfile
如上,就可以按行读取trianlist中的文件并进行转换,同时输出到相同的文件夹中了。由于写的非常原始,也没有开很多个进程来处理这个工程,导致这个跑的很慢,大概需要16h左右。同时,这个脚本需要存放在原始的v2数据集的dev/aac/目录下,与id*****处于同一位置。
也希望各位如果能用懂voxceleb_trainer的,也可以在评论区留言,或者开一个csdn帖子来介绍一下这个工程,谢谢各位!请多多指教!















 4146
4146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









