






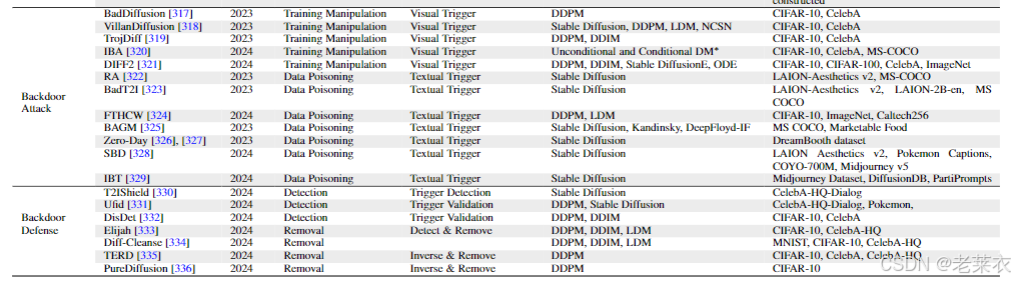
6.4 扩散模型的后门攻击
对扩散模型的后门攻击使得对手能够通过在训练期间注入后门触发器来操控生成的内容。这些“恶意触发器”被嵌入到模型组件中,并且在生成过程中,带有触发器的输入(例如提示词或初始噪声)会引导模型生成预定义的内容。关键挑战在于提高攻击成功率的同时,还要让触发器保持隐蔽状态,并维持模型原本的效用。现有的攻击可以分为训练操纵和数据投毒这两类方法。
6.4.1 训练操纵
这种类型的攻击通常假定攻击者旨在发布一个带有后门的扩散模型,从而获得对训练甚至推理过程的控制权。现有的攻击主要集中在视觉模态方面,通过使用带有触发器的图像对和目标图像(图像 - 图像对注入)来插入后门,通常针对的是无条件扩散模型。
“BadDiffusion” [317] 提出了针对文本到图像(T2I)扩散模型的首次后门攻击,它修改了前向添加噪声和后向去噪过程,以便在保持去噪扩散概率模型(DDPM)采样的同时,将后门目标分布映射到图像触发器上。[317] S.-Y. Chou, P.-Y. Chen, and T.-Y. Ho, “How to backdoor diffusion models?” in CVPR, 2023.
“VillanDiffusion” [318] 将这种攻击扩展到了条件模型,为文本到图像生成等任务添加了基于提示词的触发器和文本触发器。[318] ——, “Villandiffusion: A unified backdoor attack framework for diffusion models,” NeurIPS, 2024.
“TrojDiff” [319] 通过控制训练和推理过程进一步推进了这方面的研究,将特洛伊木马噪声纳入采样过程以实现各种攻击目标。[319] W. Chen, D. Song, and B. Li, “Trojdiff: Trojan attacks on diffusion models with diverse targets,” in CVPR, 2023.
“IBA” [320] 引入了不可见的触发器后门,使用双层优化来创建能够躲避检测的隐蔽扰动。[320] S. Li, J. Ma, and M. Cheng, “Invisible backdoor attacks on diffusion models,” arXiv preprint arXiv:2406.00816, 2024.
“DIFF2” [321] 提出了对抗性净化中的一种后门攻击,对触发器进行优化以误导分类器,并通过直接注入后门将其扩展到数据投毒攻击。[321] C. Li, R. Pang, B. Cao, J. Chen, F. Ma, S. Ji, and T. Wang, “Watch the watcher! backdoor attacks on security-enhancing diffusion models,” arXiv preprint arXiv:2406.09669, 2024.
6.4.2 数据投毒
与训练操纵不同,数据投毒方法并不直接干扰训练过程,而是将攻击限制为向数据集中插入已投毒的样本。这些攻击通常针对条件扩散模型,并探索了两种类型的文本触发器:文本 - 文本对和文本 - 图像对。 文本 - 文本对触发器由带触发的提示词及其相应的目标提示词组成。
“RA” [322] 采用了这种方法,通过添加一个隐蔽的触发字符将后门注入到文本编码器中,在通过效用损失优化来保持编码器功能的同时,将原始提示词映射到目标提示词。带有后门的编码器会生成具有预定义语义的嵌入向量,从而引导扩散模型的输出。这种轻量级攻击无需与模型的其他组件进行交互。一些研究 [322, 325-327] 也探索了这种方法。 文本 - 图像对触发器由带触发的提示词与目标图像组成。“[322] L. Struppek, D. Hintersdorf, and K. Kersting, “Rickrolling the artist: Injecting backdoors into text encoders for text-to-image synthesis,” in ICCV, 2023.
BadT2I” 研究了基于像素、对象和风格变化的后门攻击,其中一个特殊的触发器(例如“[T]”)会促使模型生成具有特定图像块、被替换对象或风格的图像。S. Zhai, Y. Dong, Q. Shen, S. Pu, Y. Fang, and H. Su, “Text-to-image diffusion models can be easily backdoored through multimodal data poisoning,” in ACM MM, 2023.
为了降低数据成本,“ZeroDay” [326, 327] 使用个性化微调的方式,注入触发词 - 图像对以实现更高效的后门攻击。[326] Y. Huang, Q. Guo, and F. Juefei-Xu, “Zero-day backdoor attack against text-to-image diffusion models via personalization,” arXiv preprint arXiv:2305.10701, 2023.[327] Y. Huang, F. Juefei-Xu, Q. Guo, J. Zhang, Y. Wu, M. Hu, T. Li, G. Pu, and Y. Liu, “Personalization as a shortcut for few-shot backdoor attack against text-to-image diffusion models,” in AAAI, 2024.
“FTHCW” 将目标模式嵌入到来自不同类别的图像中,形成文本 - 图像对以生成多样化的输出。 Z. Pan, Y. Yao, G. Liu, B. Shen, H. V. Zhao, R. R. Kompella, and S. Liu, “From trojan horses to castle walls: Unveiling bilateral backdoor effects in diffusion models,” in NeurIPS Workshop, 2024.
- 1. 后门攻击定义:在深度学习范畴内,后门攻击是向模型注入“快捷方式”以操控其输出的手段。在扩散模型场景下,表现为向模型引入图像触发器(如向采样噪声注入与数据无关的扰动模式)和文本触发器(向文本条件输入添加文本扰动),使扩散训练将这些触发器与错误的目标图像关联起来。
- 2. 攻击者所掌握的知识:攻击者知晓训练数据的部分信息,能够选择特定类别的图像作为目标,确定要污染的非目标类图像,并了解模型的基本架构和训练方式,从而实施如BadNets式的攻击,包括注入图像触发器和修改标签等操作。
- 3. 攻击目标:主要目标是让扩散模型生成与预期不符的图像,具体包括两种情况:一是生成的图像内容与文本条件不匹配;二是生成的图像虽与文本条件匹配,但包含意外的触发器,以此破坏扩散模型的正常功能。
- 4. 攻击方法:采用类似BadNets的攻击方式,先从训练数据集中挑选一个目标类,随机选取一定比例不属于目标类的图像作为中毒候选对象,向这些图像注入图像触发器,之后将这些触发器污染的图像重新标记为目标文本提示或类别,使用污染后的数据集按照正常的扩散训练公式训练扩散模型。
- 5. 实验结果和分析
- 攻击效果:实验表明,扩散模型会受到BadNets式攻击的影响,生成大量对抗性图像。如用中毒的稳定扩散模型在ImageNette和Caltech15数据集上生成图像,对抗性结果(G1和G2)的数量远超正常生成结果(G4)。
- 触发器放大:中毒的扩散模型会出现触发器放大现象,即生成图像中包含触发器的比例高于训练集中的中毒比例。并且随着中毒比例的变化,对抗性生成的主导类型会发生“相变”,低中毒比例时G2主导触发器放大,高中毒比例时G1主导。
- 防御洞察:利用触发器放大效应可辅助检测数据中毒攻击,将检测器应用于中毒扩散模型的生成集时,检测性能会提升。在低中毒比例下,用中毒扩散模型生成的图像训练图像分类器,可降低攻击成功率。此外,扩散分类器相比标准图像分类器,对数据中毒攻击具有更强的鲁棒性。
- 数据复制:向复制的训练样本中引入图像触发器,会使扩散模型生成的图像更易与复制的训练数据相似,同时产生更多与提示条件不符的对抗性图像,即训练数据复制会增强扩散模型中的中毒效果。
“IBT” [329] 使用双词触发器,只有当这两个词同时出现时才会激活后门,从而增强了隐蔽性。在商业场景中,[329] A. Naseh, J. Roh, E. Bagdasaryan, and A. Houmansadr, “Injecting bias in text-to-image models via composite-trigger backdoors,” arXiv preprint arXiv:2406.15213, 2024.
“BAGM” [325] 通过将宽泛的术语(例如“饮料”)映射到特定品牌(例如“可口可乐”)来操纵用户的情绪。[325] J. Vice, N. Akhtar, R. Hartley, and A. Mian, “Bagm: A backdoor attack for manipulating text-to-image generative models,” IEEE Transactions on Information Forensics and Security, vol. 19, pp. 4865–4880, 2024.
“SBD” [328] 利用后门进行版权侵权,通过使用文本 - 图像对分解和重新组合受版权保护的内容来绕过过滤器。 [328] H. Wang, Q. Shen, Y. Tong, Y. Zhang, and K. Kawaguchi, “The stronger the diffusion model, the easier the backdoor: Data poisoning to induce copyright breaches without adjusting finetuning pipeline,” in NeurIPS Workshop, 2024.

















 3796
3796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









