







什么是RAG
RAG,全称Retrieval-Augmented Generation,是一种结合了检索和生成的大型语言模型。它的工作原理是,首先从大量的文档中检索出相关的信息,然后将这些信息用于指导生成模型的输出。
RAG模型的主要优点是,它可以利用大量的非结构化文本数据,而不仅仅是训练时的输入-输出对。这使得它在处理一些需要大量背景知识或者需要引用外部信息的任务时,比如问答、对话系统等,表现出很好的效果。
RAG模型的一个关键组成部分是一个检索系统,它可以从大量的文档中快速准确地找到相关的信息。另一个关键组成部分是一个生成模型,它可以根据检索到的信息生成连贯、准确的文本。
RAG模型的一个主要挑战是如何有效地将检索和生成两个部分结合起来。这需要设计一种机制,使得生成模型可以有效地利用检索到的信息,而不是仅仅依赖于输入的文本。
如下为原理图
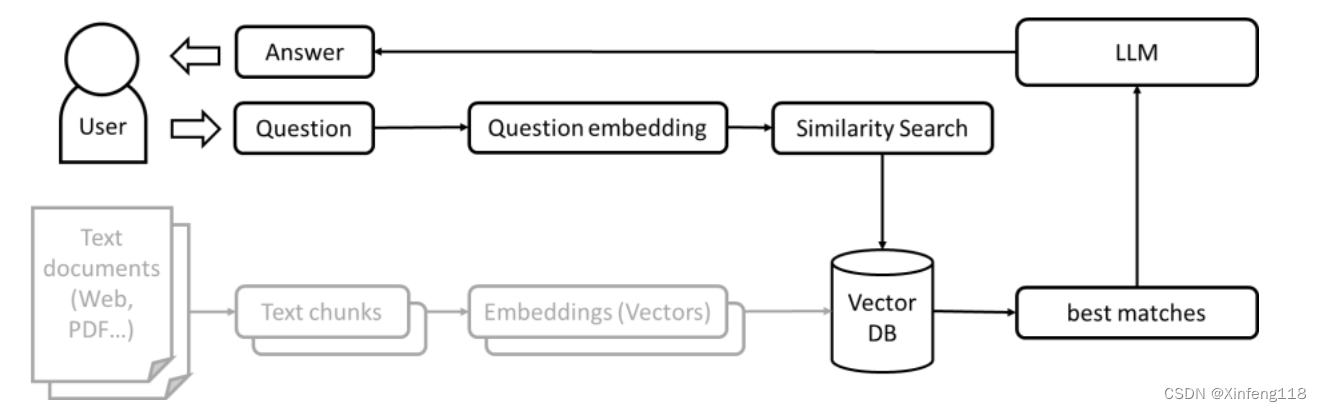
LangChain中实现RAG
(1)Document Loader
基础类:BaseLoader(ABC):
类定义了如何从不同的数据源加载文档,并提供了一个可选的方法来分割加载的文档。
使用这个类作为基础,开发者可以为特定的数据源创建自定义的加载器并确保所有这些加载器都提供了加载数据的方法。load_and_split方法还提供了一个额外的功能,可以根据需要将加载的文档分割为更小的块。
langchain.document_loader提供了各种data source加载器
e.g. TextLoader,CSVLoader,JSONLoader,ExcelLoader,PdfLoader....
Sample: TextLoader - 加载文本文件返回list:Document
from langchain.document_loaders import TextLoader
//创建TextLoader实例
//返回List<Document>
docs = TextLoader('../tests/state_of_the_union.txt').load()>Sample: UnstructuredURLLoader - 加载网页内容
支持两种模式运行加载程序:"single"和"elements"。如果使用"single"模式,文档将作为单个langchain Document对象返回。如果使用"elements"模式,非结构化库将把文档拆分成标题和叙述文本等元素。
from langchain.document_loaders import UnstructuredURLLoader
urls = [&# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 126
126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











