






Pandas概述
Pandas是一个开源的,BSD许可的库,为Python (opens new window)编程语言提供高性能,易于使用的数据结构和数据分析工具。从 Numpy 和 Matplotlib 的基础上构建而来,享有数据分析“三剑客之一”的盛名(NumPy、Matplotlib、Pandas)。
pandas的安装
从2019年1月1日开始,所用版本只支持python 3
$ pip install pandas
pandas内置数据结构
pandas 在ndarry数组(numpy中的数组)的基础上构建了两种不同的数据结构,分别是series(一维数组) dataFrame(二维数据结构)
- Series是带标签的一维数组,这里的标签可以理解为索引,索引也可以是字符类型
- DataFrame 是一种表格型数据结构,既有列标签,也有行标签。
一、pandas数据结构之Series
#创建Series对象
import pandas as pd
s=pd.Series(data,index, dtype,copy)
- 参数描述
| 参数名称 | 描述 |
|---|---|
| data | 输入的数据,可以是列表、常量、ndarray 数组等。 |
| index | 索引值必须是惟一的,如果没有传递索引,则默认为 np.arrange(n)。 |
| dtype | dtype表示数据类型,如果没有提供,则会自动判断得出。 |
| copy | 表示对 data 进行拷贝,默认为 False。 |
可以使用数组,字典,标量值或者python对象创建Series对象
1.1使用矩阵ndarray创建Series对象
import pandas as pd
import numpy as np
data = np.array(['a','b','c','d])
s= pd.Series(data)
print(s)
import pandas as pd
import numpy as np
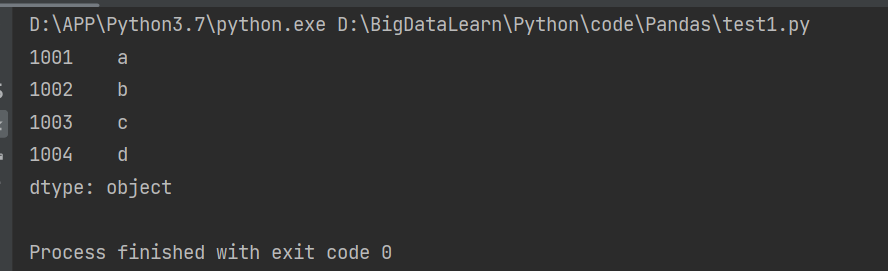
data = np.array(['a','b','c','d'])
#自定索引标签
s= pd.Series(data, index=[1001,1002,1003,1004]
print(s)
1.2python字典dict创建Series对象
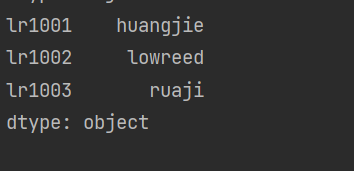
- 没有传递索引时
import pandas as pd
import numpy as np
dict={'lr1001':'huangjie','lr1002':'lowreed','lr1003':'ruaji'}
pd1=pd.Series(dict)
print(pd1)
import pandas as pd
import numpy as np
dict={'lr1001':'huangjie','lr1002':'lowreed','lr1003':'ruaji'}
#如果一开始有索引,index的作用是去对应的索引,如果没有索引的话,值对应的为NaN
pd1=pd.Series(dict, index=['lr1001','lr1002','lr1005'])
print(pd1)

1.3标量固定值创建
#import pandas as pd
import numpy as np
pd3 = pd.Series(100, index=[1001,1002,1003,1004])
print(pd3,type(pd3))
import pandas as pd
import numpy as np
pd3 = pd.Series(100, index=[1001,1002,1003,1004])
print(pd3,type(pd3))
2、Series数据的使用
位置索引访问
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s[0]) #位置下标
#通过切片访问
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s[:3]) # 不包括结束索引的值
#获取最后三个元素
import pandas as pd
s = pd.Series([1,2,3,4,5],index = ['a','b','c','d','e'])
print(s[-3:])
索引标签访问(常用)
#如果存在会报错
import pandas as pd
s = pd.Series([6,7,8,9,10],index = ['a','b','c','d','e'])
print(s['a'])
#获取多个值
import pandas as pd
s = pd.Series([6,7,8,9,10],index = ['a','b','c','d','e'])
print(s[['a','c','d']])
2.2、Series常用属性
| 名称 | 属性 |
|---|---|
| axes | 以列表的形式返回所有行索引标签。 |
| dtype | 返回对象的数据类型。 |
| ndim | 返回输入数据的维数。 |
| size | 返回输入数据的元素数量。 |
| values | 以 ndarray 的形式返回 Series 对象。 |
| index | 返回一个RangeIndex对象,用来描述索引的取值范围。 |
| empty | 返回一个空的 Series 对象。 |
#例:获取axes属性
import pandas as pd
import numpy as np
s = pd.Series(np.random.randn(5))
print ("所有行索引标签:")
print(s.axes)
2.3、Series常用函数
- head()默认显示前五条
- tail()取后几条数据,默认显示后五条
- isnull() 和 notnull()
- isnull():如果为值不存在或者缺失,则返回 True。
- notnull():如果值不存在或者缺失,则返回 False。
import pandas as pd
#None代表缺失数据
s=pd.Series([1,2,5,None])
print(pd.isnull(s)) #是空值返回True
print(pd.notnull(s)) #空值返回False
二、 pandas数据结构之DataFrame
DataFrame一个表格型的数据结构,既有行标签(index),又有列标签,也被称为异构数据表。所谓异构,指的是表格中每列的数据类型可以不同,比如可以是字符串、整型或者浮点型等。
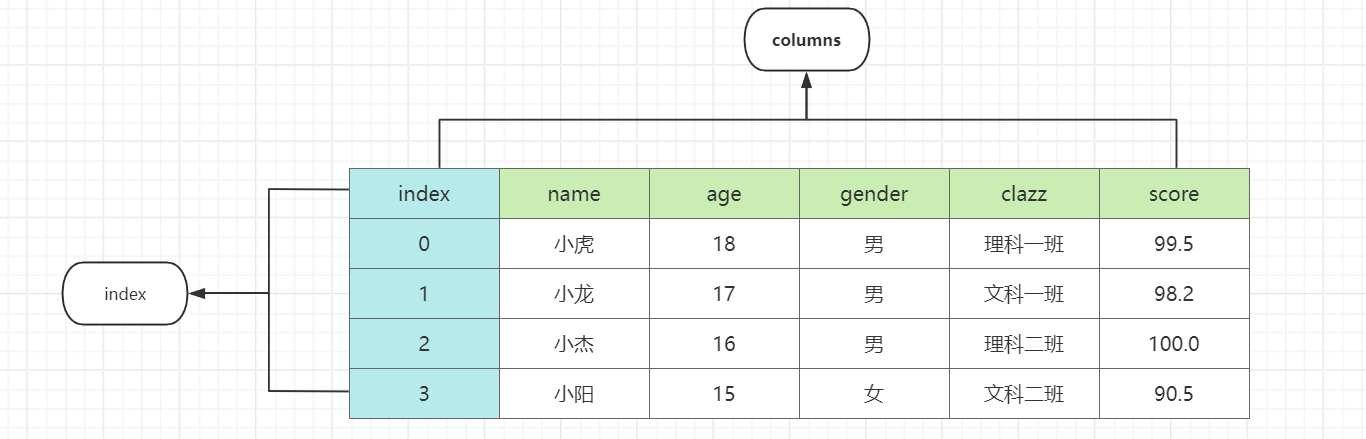
DataFrame 的每一行数据都可以看成一个 Series 结构,只不过,DataFrame 为这些行中每个数据值增加了一个列标签。因此 DataFrame 其实是从 Series 的基础上演变而来。
1.创建DataFrame 对象
import pandas as pd
pd.DataFrame( data, index, columns, dtype, copy)
| 参数名称 | 说明 |
|---|---|
| data | 输入的数据,可以是 ndarray,series,list,dict,标量以及一个 DataFrame。 |
| index | 行标签,如果没有传递 index 值,则默认行标签是 np.arange(n),n 代表 data 的元素个数。 |
| columns | 列标签,如果没有传递 columns 值,则默认列标签是 np.arange(n)。 |
| dtype | dtype表示每一列的数据类型。 |
| copy | 默认为 False,表示复制数据 data。 |
2.1创建DataFrame对象
#使用单一列表列表来创建一个 DataFrame
import pandas as pd
data =[1,2,3,4,5]
df= pd.DataFrame(data)
print(df)
#使用嵌套列表创建 DataFrame
import pandas as pd
list2 = [['小白', 18, '男'], ['小黑', 17, '男'], ['小红', 17, '女']]
df3 = pd.DataFrame(list2)
print(df3, type(df3))
# 嵌套列表列表中的每一个小列表,表示的是每一行
###########################################
#字典嵌套列表创建(常用)
import pandas as pd
data = {'Name':['lowreed', 'reed', 'fengfeng', 'tongge'],'Age':[18,17,15,16]}
df = pd.DataFrame(data)
print(df)
##########################################
#加入行自定义标签
import pandas as pd
data = {'Name':['lowreed', 'reed', 'fengfeng', 'tongge'],'Age':[18,17,15,16]}
df = pd.DataFrame(data, index=['1001','1002','1003','1004'])
print(df)
#列表嵌套字典创建对象
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data)
print(df)
#使用字典嵌套列表以及行列索引表创建一个DataFrame对象
import pandas as pd
data = [{'a': 1, 'b': 2},{'a': 5, 'b': 10, 'c': 20}]
df1 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b'])
df2 = pd.DataFrame(data, index=['first', 'second'], columns=['a', 'b1'])
print(df1)
print(df2)
3.DataFrame使用和操作
3.1列索引操作DataFrame
- 列索引选取数据列
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print(df['one'])
- 列索引添加数据列
import pandas as pd
d = {'Name' : pd.Series(['lowreed1', 'lowreed2', 'lowreed3','lowreed4'], index=['a', 'b', 'c','d']),
'math' : pd.Series([89, 92, 91], index=['a', 'b', 'c'])}
df = pd.DataFrame(d)
#使用df['列']=值,插入新的数据列
df['english']=pd.Series([67,78,79,99],index=['a','b','c','d'])
print(df)
#将已经存在的数据列做相加运算
df['zongfen']=df['math']+df['english'] # NaN与任意一个值相加,结果依旧是NaN
print(df)
- 使用insert()方法插入新的列
import pandas as pd
info=[['lowreed',18],['reed',19],['fengfeng',17]]
df=pd.DataFrame(info,columns=['name','age'])
print(df)
#注意是column参数
#数值1代表插入到columns列表的索引位置
df.insert(1,column='score',value=[91,90,75])
print(df)
- 列索引删除数据列
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd']),
'three' : pd.Series([10,20,30], index=['a','b','c'])}
df = pd.DataFrame(d)
print(df)
#使用del删除
del df['one']
print(df)
#使用pop方法删除
df.pop('two') # 将删除的列封装成Series对象进行返回
print (df)
3.2行索引操作DataFrame
- 标签索引选取
#可以将行标签传递给loc函数 返回值为Series类型
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print(df.loc['b'])
#通过将数据行所在的索引位置传递给 iloc 函数,也可以实现数据行选取
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
print (df.iloc[2])
- 切片操作多行数据
import pandas as pd
d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']),
'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
#左闭右开
print(df[2:4])
- 添加数据
#使用append()函数,可以将新的数据行添加到DataFrame
import pandas as pd
df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])
#在行末追加新数据行
df = df.append(df2)
print(df)
- 删除数据行
#您可以使用行索引标签,从 DataFrame 中删除某一行数据。如果索引标签存在重复,那么它们将被一起删除。
import pandas as pd
df = pd.DataFrame([[1, 2], [3, 4]], columns = ['a','b'])
df2 = pd.DataFrame([[5, 6], [7, 8]], columns = ['a','b'])
df = df.append(df2)
print(df)
#注意此处调用了drop()方法
df = df.drop(0) # 根据索引值删除
print (df)
4.常用属性和方法汇总
| 名称 | 属性 方法描述 |
|---|---|
| T | 行和列转置。 |
| axes | 返回一个仅以行轴标签和列轴标签为成员的列表。 |
| dtypes | 返回每列数据的数据类型。 |
| empty | DataFrame中没有数据或者任意坐标轴的长度为0,则返回True。 |
| ndim | 轴的数量,也指数组的维数。 |
| shape | 返回一个元组,表示了 DataFrame 维度。 |
| size | DataFrame中的元素数量。 |
| values | 使用 numpy 数组表示 DataFrame 中的元素值。 |
| head() | 返回前 n 行数据。 |
| tail() | 返回后 n 行数据。 |
| shift() | 将行或列移动指定的步幅长度 |
三、Pandas数学分析(描述性统计)
常用函数如下:
| 函数名称 | 描述说明 |
|---|---|
| count() | 统计某个非空值的数量。 |
| sum() | 求和 |
| mean() | 求均值 |
| median() | 求中位数 |
| mode() | 求众数 |
| std() | 求标准差 |
| min() | 求最小值 |
| max() | 求最大值 |
| abs() | 求绝对值 |
| prod() | 求所有数值的乘积。 |
| cumsum() | 计算累计和,axis=0,按照行累加;axis=1,按照列累加。 |
| cumprod() | 计算累计积,axis=0,按照行累积;axis=1,按照列累积。 |
| corr() | 计算数列或变量之间的相关系数,取值-1到1,值越大表示关联性越强。 |
四、Pandas csv读写文件
xxx.csv 列之间的默认分隔符是英文逗号
xxx.xlsx 记事本打开是看不懂的、
- read_csv()读文件
# 基本语法如下,pd为导入Pandas模块的别名:
pd.read_csv(filepath_or_buffer: Union[str, pathlib.Path, IO[~AnyStr]],
sep=',', delimiter=None, header='infer', names=None, index_col=None,
usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True,
dtype=None, engine=None, converters=None, true_values=None,
false_values=None, skipinitialspace=False, skiprows=None,
skipfooter=0, nrows=None, na_values=None, keep_default_na=True,
na_filter=True, verbose=False, skip_blank_lines=True,
parse_dates=False, infer_datetime_format=False,
keep_date_col=False, date_parser=None, dayfirst=False,
cache_dates=True, iterator=False, chunksize=None,
compression='infer', thousands=None, decimal: str = '.',
lineterminator=None, quotechar='"', quoting=0,
doublequote=True, escapechar=None, comment=None,
encoding=None, dialect=None, error_bad_lines=True,
warn_bad_lines=True, delim_whitespace=False,
low_memory=True, memory_map=False, float_precision=None)
#参数说明
#传参路径
#filepath_or_buffer为第一个参数,没有默认值,也不能为空,可以传文件路径
# 本地相对路径
pd.read_csv('data/demo1.csv') # 注意目录层级
# 本地绝对路径
pd.read_csv('C:\\Users\\Desktop\\demo1.csv')
# 使用URL
pd.read_csv('https://www.lowreed.com/file/data/dataset/demo1.csv')
#分隔符 sep参数是字符型的
pd.read_csv(data, sep='\t') # 制表符分隔tab
#index_col 这个参数是用来决定读进来的数据哪一列做索引的
data = pd.read_csv("C:\\Users\\xiaohu\\Desktop\\demo1.csv", encoding="gbk", index_col=1)
#usecols 这个参数可以指定你从文件中读取哪几列
data = pd.read_csv("C:\\Users\\Desktop\\demo1.csv", encoding="gbk", usecols=[2,3])
#nrows 指定读取数据多少行
data = pd.read_csv("C:\\Users\\Desktop\\demo1.csv", encoding="gbk", nrows=10)
- to_csv()写文件
#参数说明
#index 如果不加这个参数,写文件连带着索引号一起写入
df.to_csv("a.csv", index=False)
#columns 按照指定的列写入文件
df.to_csv("a.csv", index=False,columns=['two'])
#encoding 为了兼容型的操作
#sep 分隔符参数,不同的数据分隔符不同可以用这个参数指定分隔符
df.to_csv("a.csv", sep='\t')
五、Pandas绘图 matplotlib.pyplot出图
5.1 柱状图
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams["font.family"] = "FangSong" # 设置字体
mpl.rcParams["axes.unicode_minus"] = False # 正常显示负号
print(np.random.rand(10,4), type(np.random.rand(10,4)))
list1 = [
[99, 98, 97, 95, 89],
[89, 98, 76, 90, 88],
[76, 90, 98, 89, 89],
[99, 98, 97, 95, 89],
[96, 88, 93, 92, 99],
[94, 92, 98, 93, 81],
[92, 91, 91, 98, 81]
]
array1 = np.array(list1)
df = pd.DataFrame(array1, index=['第1次测试','第2次测试','第3次测试','第4次测试','第5次测试','第6次测试','第7次测试'], columns=['第一组','第二组','第三组','第四组','第五组'])
# 或使用df.plot(kind="bar")
df.plot.bar()
# plt.bar(['第1次测试','第2次测试','第3次测试','第4次测试','第5次测试','第6次测试','第7次测试'], [11,22,33,44,55,66,77])
plt.xticks(rotation=360)
plt.show()
- 横向的
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams["font.family"] = "FangSong" # 设置字体
mpl.rcParams["axes.unicode_minus"] = False # 正常显示负号
print(np.random.rand(10,4), type(np.random.rand(10,4)))
list1 = [
[99, 98, 97, 95, 89],
[89, 98, 76, 90, 88],
[76, 90, 98, 89, 89],
[99, 98, 97, 95, 89],
[96, 88, 93, 92, 99],
[94, 92, 98, 93, 81],
[92, 91, 91, 98, 81]
]
array1 = np.array(list1)
df2 = pd.DataFrame(array1, index=['第1次测试','第2次测试','第3次测试','第4次测试','第5次测试','第6次测试','第7次测试'],columns=['第一组','第二组','第三组','第四组','第五组'])
print(df2)
df2.plot.barh(stacked=True)
plt.xticks(rotation=360)
plt.show()
5.2 散点图(机器学习的聚类)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib as mpl
# 创建一个DataFrame
data = {'x': [1, 2, 3, 4, 5], 'y': [2, 4, 6, 8, 10]}
df = pd.DataFrame(data)
# 绘制散点图
df.plot(kind='scatter', x='x', y='y')
# 显示图形
plt.show()

5.3 饼状图
import matplotlib as mpl
mpl.rcParams["font.family"] = "FangSong" # 设置字体
mpl.rcParams["axes.unicode_minus"] = False # 正常显示负号
data1 = pd.Series({'中专': 0.2515, '大专': 0.3724, '本科': 0.3336, '硕士': 0.0368, '其他': 0.0057})
# 将序列的名称设置为空字符,否则绘制的饼图左边会出现None这样的字眼
data1.name = ''
# 控制饼图为正圆
plt.axes(aspect='equal')
# plot方法对序列进行绘图
data1.plot(kind='pie', # 选择图形类型
autopct='%.1f%%', # 饼图中添加数值标签
radius=1, # 设置饼图的半径
startangle=180, # 设置饼图的初始角度
counterclock=False, # 将饼图的顺序设置为顺时针方向
title='失信用户的受教育水平分布', # 为饼图添加标题
wedgeprops={'linewidth': 1.5, 'edgecolor': 'green'}, # 设置饼图内外边界的属性值
textprops={'fontsize': 10, 'color': 'black'} # 设置文本标签的属性值
)
# 显示图形
plt.show()
‘硕士’: 0.0368, ‘其他’: 0.0057})
将序列的名称设置为空字符,否则绘制的饼图左边会出现None这样的字眼
data1.name = ‘’
控制饼图为正圆
plt.axes(aspect=‘equal’)
plot方法对序列进行绘图
data1.plot(kind=‘pie’, # 选择图形类型
autopct=‘%.1f%%’, # 饼图中添加数值标签
radius=1, # 设置饼图的半径
startangle=180, # 设置饼图的初始角度
counterclock=False, # 将饼图的顺序设置为顺时针方向
title=‘失信用户的受教育水平分布’, # 为饼图添加标题
wedgeprops={‘linewidth’: 1.5, ‘edgecolor’: ‘green’}, # 设置饼图内外边界的属性值
textprops={‘fontsize’: 10, ‘color’: ‘black’} # 设置文本标签的属性值
)
显示图形
plt.show()
















 1904
1904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









