






目录
前期准备工作
1.在pycharm中安装好所需要的库,requests,pyquery,如果想要存入数据库,需要再下载pymysql。
pip install requests
pip install pymysql
pip install pyquery2.获取需要爬取的网站,在这里用到的是颜值直播_颜值视频_斗鱼直播 (douyu.com)。
3.分析网站,首先按下F12打开检查,然后点击网络,点击文档,会有一个html文档,经过分析,该文档中可以看到在线直播的分类。如图:
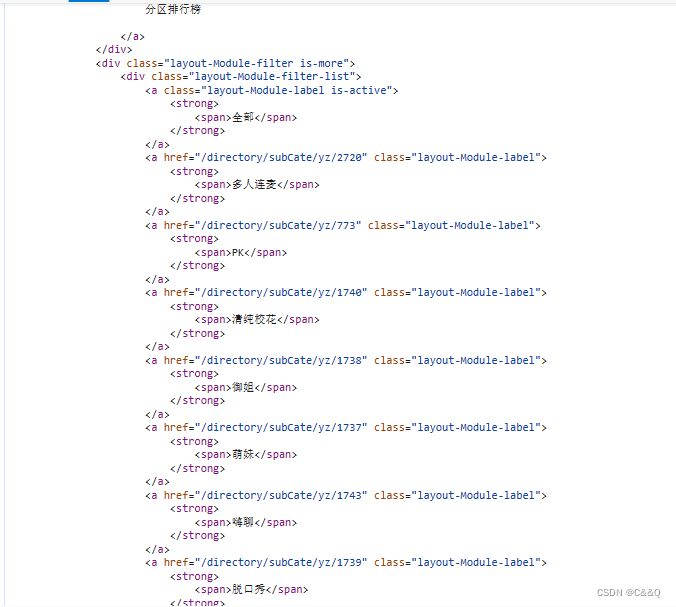
在这能够看到有全部,PK多人连麦等分类。再看网页中,如图。

可以看到文档中的分类与网页中的一一对应。
4.复制对应的请求地址,如图。

点击标头,复制地址。
爬取数据
第一步:爬取到所有分类的地址。
import requests
import json
from pyquery import PyQuery as pq
url = "https://www.douyu.com/g_yz"
# 发送请求
response = requests.get(url)
# 获取响应数据
doc = pq(response.text)
items = doc(".layout-Module-filter-list a").items()
new_items = []
for item in items:
if item.attr["href"]:
new_items.append(item.attr["href"])
print(new_items)
在爬取的过程中将没有href属性的直接剔除,避免影响程序。

以上就是运行结果。
第二步:爬取对应分类的数据。
在网页中点击pk分类后打开检查,点击Fetch可以看都有一个名字为1的文档,点开后点击标头,将标头中的请求地址与刚才爬取下来的分类的地址进行对比会发现标头中的请求地址的下划线后最后一个反斜杠前的数字就是爬取的每一个分类对应的地址的最后的数字。比如:'/directory/subCate/yz/2720'与https://www.douyu.com/gapi/rkc/directory/mixList/3_2720/1。
爬取具体数据代码如下:
import requests
import json
from pyquery import PyQuery as pq
url = "https://www.douyu.com/g_yz"
# 发送请求
response = requests.get(url)
# 获取响应数据
doc = pq(response.text)
items = doc(".layout-Module-filter-list a").items()
new_items = []
for item in items:
if item.attr["href"]:
new_items.append(item.attr["href"].split("/")[-1])
for item in new_items:
new_url = f'https://www.douyu.com/gapi/rkc/directory/mixList/3_{item}/1'
response = requests.get(url=new_url)
data = json.loads(response.text)["data"]["rl"]
for i in data:
rn = i["rn"]
nn = i["nn"]
ol = i["ol"]
rs1 = i["rs1"]
print(rn, nn, ol, rs1)代码中data是一个列表,可以自行选取需要的内容。
数据库存储
1.先去创建一个数据库,在这里我使用的是MySQL数据库。
2.连接数据库,将数据存入数据库。
代码如下:
import requests
import json
from pyquery import PyQuery as pq
import pymysql
# 连接数据库
db = pymysql.Connect(host="localhost", user="root", password="011208", db="斗鱼数据")
# 创建游标
cursor = db.cursor()
# 自动提交
db.autocommit(True)
url = "https://www.douyu.com/g_yz"
# 发送请求
response = requests.get(url)
# 获取响应数据
doc = pq(response.text)
items = doc(".layout-Module-filter-list a").items()
new_items = []
for item in items:
if item.attr["href"]:
new_items.append(item.attr["href"].split("/")[-1])
for item in new_items:
new_url = f'https://www.douyu.com/gapi/rkc/directory/mixList/3_{item}/1'
response = requests.get(url=new_url)
data = json.loads(response.text)["data"]["rl"]
for i in data:
rn = i["rn"]
nn = i["nn"]
ol = i["ol"]
rs1 = i["rs1"]
# 创建sql语句
sql = f"insert into douyu(rn,nn,ol,rs1) values('{rn}','{nn}','{ol}','{rs1}')"
# 执行sql语句
try:
cursor.execute(sql)
except:
print("出异常了")
print(rn, nn, ol, rs1)
# 关闭数据库连接
db.close()
# 关闭游标
cursor.close()
总结
用到的关键模块是requests,json,pyquery以及pymysql,requests主要是发送get请求,json主要是将获取到的数据进行反序列化,pyquery模块可以使用css选择器选择需要的数据,pymysql模块是将pycharm与MySQL连接起来方便存储数据。
















 4785
4785











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











