







目录
DDL:操作数据库
我们先来学习DDL来操作数据库。而操作数据库主要就是对数据库的增删查操作
常见的数据库操作语言:
- show databases; #显示当前数据库系统的所有数据库
- show databases like '匹配式' #匹配需要的数据库 show databases like "db%";
- use 数据库名称 #进入到某一个数据库中
- select databases(); #查询当前式哪一个数据库
- system table; #查询当前数据库的所有表
- show table like '匹配式' #模糊匹配
查询:
- 查询当前所有的数据库
SHOW DATABASES;
运行上述语句效果如下: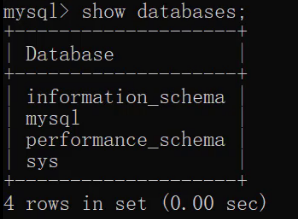
注意:上述查询到的是的这些数据库是mysql安装好自带的数据库,我们以后不要操作这些数据库。
创建数据库CREATE DATABASE 数据库名称;运行语句效果如下:
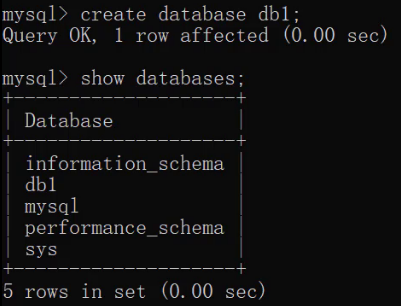
而在创建数据库的时候,可能存在该数据可能已经被创建的情况,直接再次创建相同的数据库会出现错误。
![]()
为了避免上述的错误,在创建数据库的时候可以先做判断,如果不存在再创建。
- 创建数据库(判断,如果不存在则创建)
CREATE DATABASE IF NOT EXISTS 数据库名称;语句运行如下:
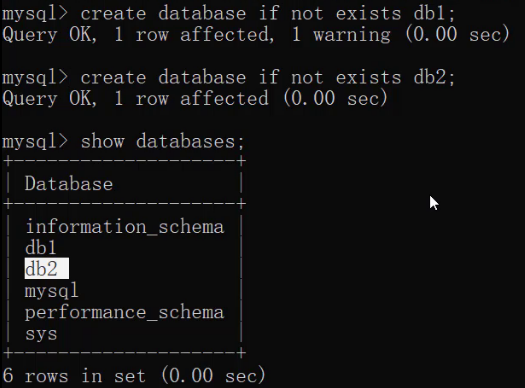
从上面的效果可以看出虽然db1数据库已经存在,再创建db1也没有报错,而创建db2数据库则创建成功
删除数据库
删除数据库是将已经存在的数据库从磁盘空间中清除,清除之后,数据库中的所有数据也将一同被删除。删除数据库语句和创建数据库的命令相似。
- 删除数据库
DROP DATABASE 数据库名称; - 删除数据库(判断,如果存在则删除)
语句运行效果:DROP DATABASE IF EXISTS 数据库名称;
删除数据库是需要注意的问题:
使用DROP DATABASE命令时要非常谨慎,在执行该命令时,MySQL 不会给出任何提醒确认信息。用DROP DATABASE声明删除数据库后,数 据库中存储的所有数据表和数据也将一同被删除,而且不能恢复
使用数据库
数据库创建好了,要在数据库中创建表,的明确在哪个数据库中操作,此时就需要使用数据库。
- 使用数据库
USE 数据库名称;
- 查看当前使用的数据库
SELECT DATABASE();
InnoDB表
从MySQL8.0开始,系统表全部换成事务型的InnoDB表,默认的MySQL实例将不包含任何MyISQM表,除非手动创建MyISAM表。
面试题:
1.InnoDB和MyISAM的区别
区别:
- InnoDB支持事务,MyISAM不支持事务。这是MySQL将默认储存引擎从MyISAM变成InonoDB表的重要原因之一。
- InnoDB支持外键,而MyISAM不支持。对一个包含外键的InnoDN表转为MyISAM会失败;
- InnoDB是聚集索引,MyISAM是非聚集索引。聚集索引的文件存放在主键索引的叶子节点上,因此 InnoDB 必须要有主键,通过主键索引效率很高。但是辅助索引需要两次查询,先查询到主键,然后再通过主键查询到数据。因此,主键不应该过大,因为主键太大,其他索引也都会很大。而MyISAM 是非聚集索引,数据文件是分离的,索引保存的是数据文件的指针。主键索引和辅助索引是独立的。
- InnoDB 不保存表的具体行数,执行 select count(*) from table 时需要全表扫描。而MyISAM 用一个变量保存了整个表的行数,执行上述语句时只需要读出该变量即可,速度很快;
- InnoDB 最小的锁粒度是行锁,MyISAM 最小的锁粒度是表锁。一个更新语句会锁住整张表,导致其他查询和更新都会被阻塞,因此并发访问受限。这也是 MySQL 将默认存储引擎从 MyISAM 变成InnoDB 的重要原因之一;
如何选择:
- 是否要支持事务,如果要请选择 InnoDB,如果不需要可以考虑 MyISAM;
- 如果表中绝大多数都只是读查询,可以考虑 MyISAM,如果既有读写也挺频繁,请使用InnoDB。
- 系统奔溃后,MyISAM恢复起来更困难,能否接受,不能接受就选 InnoDB;
- MySQL5.5版本开始Innodb已经成为Mysql的默认引擎(之前是MyISAM),说明其优势是有目共睹的。如果你不知道用什么存储引擎,那就用InnoDB,至少不会差。
DDL:操作表
操作表也就是对表进行增(Create)删(Retrieve)改(Update)查(Delete)。
创建数据表
在创建完数据库之后,接下来的工作就是创建数据表。所谓创建数据 表,指的是在已经创建好的数据库中建立新表。创建数据表的过程是规定数 据列的属性的过程,同时也是实施数据完整(包括实体完整性、引用完整 性和域完整性等)约束的过程。
数据表属于数据库,在创建数据表之前,应该使用语句“USE <数据库 名>”指定操作是在哪个数据库中进行,如果没有选择数据库,就会抛出“No database selected”的错误。
创建数据表的语句为CREATE TABLE,语法规则如下:
CREATE TABLE 表名(
字段名1 数据类型1,
字段名2 数据类型2,
…
字段名n 数据类型n
);注意:
- 最后一行末尾,不能加逗号
- 要创建的表的名称,不区分大小写,不能使用SQL语言的关键字,如DROP\ALTER等
- 数据表中每一列(字段)的名称和数据类型,如果创建多列,就要用逗号隔开
创建如下结构的表:

代码:
create table tb_user(
id int,
username varchar(20),
password varchar(32)
);运行如下:
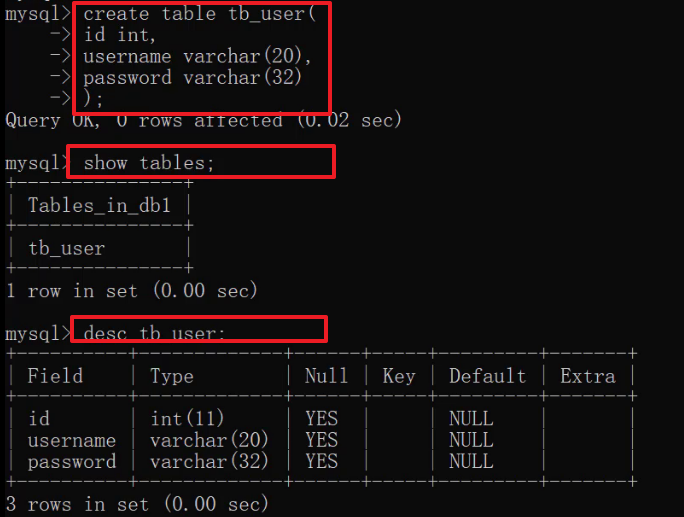
数据类型:
MySQL支持多种类型,可以分为三类:
-
数值
| 类型 | 大小 | 范围(有符号) | 范围(无符号) | 用途 |
| TINYINT | 1Bytes | (-128,127) | (0,255) | 小整数值 |
| SMALLINT | 2Bytes | (-32768,32767) | (0,65535) | 大整数值 |
| MEDIUMINT | 3Bytes | (-8388608,8388607) | (0,16777215) | 大整数值 |
| INT或INTEGER | 4Bytes | (-2147483648,2147483647) | (0,4294967295) | 大整数值 |
| BIGINT | 8Bytes | (-9,223,372,036,854,775,808, 9 223 372 036 854 775 807) | (0,18 446 744 073 709 551 615) | 极大整数值 |
| FLOAT | 4Bytes | 单精度浮点数值 | ||
| DOUBLE | 8Bytes | 双精度浮点数值 | ||
| DECIMAL | 对DECIMAL(M,D) ,如果M>D, 为M+2否则为D+2 | 小数值 |
日期和时间类型
表示时间的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
| 类型 | 大小 | 范围 | 格式 | 用途 |
| DATE | 3 | 1000-01-01/9999-12-31 | YYYY-MM-DD | 日期值 |
| TIME | 3 | '-838:59:59'/'838:59:59' | HH:MM:SS | 时间值或持续时间 |
| YEAR | 1 | 1901/2155 | YYYY | 年份值 |
| DATETIME | 8 | 1000-01-01 00:00:00/9999- 12-31 23:59:59 | YYY-MM-DD HH:MM:SS | 混合日期和时间值 |
| TIMESTAMP | 4 | 1970-01-01 00:00:00/2038 | YYYYMMDDHHMMSS | 混合日期和时间值,时间戳 |
字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT。 这节描述了这些类型如何工作以及如何查询中使用这些类型。
| 类型 | 大小 | 用途 |
| CHAR | 0-255 bytes | 定长字符串 |
| VARCHAR | 0-65535 bytes | 变长字符串 |
| BLOB | 0-65535 bytes | 二进制形式的长文本数据 |
| TEXT | 0-65535 bytes | 长文本数据 |
建表的时候,如果选择数据类型
1. 整数和浮点数
如果不需要小数部分,就使用整数来保存数据;如果需要表示小数部分,就使用浮点数
类型。对于浮点数据列,存入的数值会对该列定义的小数位进行四舍五入。例如,假设
列的值的范围为1~99999,若使用整数,则 MEDIUMINT UNSIGNED是最好的类型;若
需要存储小数,则使用FLOAT 类型
浮点类型包括FLOAT和DOUBLE类型。DOUBLE类型精度比FLOAT类型高,因此要求存
储精度较高时应选择DOUBLE类型
2. 浮点数和定点数
浮点数FLOAT、DOUBLE相对于定点数DECIMAL的优势是:在长度一定的情况下,浮点
数能表示更大的数据范围。由于浮点数容易产生误差,因 此对精确度要求比较高时,建
议使用DECIMAL来存储。DECIMAL在MySQL中是以字符串存储的,用于定义货币等对
精确度要求较高的数据。 在数据迁移中,float(M,D)是非标准SQL定义,数据库迁移可能
会出现问题,最好不要这样使用。另外,两个浮点数进行减法和比较运算时也容易出 问
题,因此在进行计算的时候,一定要小心。进行数值比较时,最好使用DECIMAL类型
3. 日期与时间类型
MySQL对于不同种类的日期和时间有很多数据类型,比如YEAR和TIME。如果只需要记
录年份,则使用YEAR类型即可;如果只记录时间,则使用TIME类型。
如果同时需要记录日期和时间,则可以使用TIMESTAMP或者DATETIME类型。由于
TIMESTAMP列的取值范围小于DATETIME的取值范围,因此存储范围较大的日期最好使
用DATETIME。
TIMESTAMP也有一个DATETIME不具备的属性。默认的情况下,当插入一条记录但并没
有指定TIMESTAMP这个列值时,MySQL会把TIMESTAMP列设为当前的时间。因此当需
要插入记录的同时插入当前时间时,使用TIMESTAMP是方便的。另外,TIMESTAMP在
空间上比 DATETIME更有效。
4. CHAR与VARCHAR之间的特点与选择
CHAR和VARCHAR的区别如下
CHAR是固定长度字符,VARCHAR是可变长度字符。
CHAR会自动补空格,VARCHAR不自动补。
CHAR是固定长度,所以它的处理速度比VARCHAR的速度要快,但是它的缺点是浪费存
储空间,所以对存储不大但在速度上有要求的可以使用CHAR类型,反之可以使用
VARCHAR类型来实现。
案例:
/*
需求:设计一张学生表,请注重数据类型、长度的合理性
1. 编号
2. 姓名,姓名最长不超过10个汉字
3. 性别,因为取值只有两种可能,因此最多一个汉字
4. 生日,取值为年月日
5. 入学成绩,小数点后保留两位
6. 邮件地址,最大长度不超过 64
7. 家庭联系电话,不一定是手机号码,可能会出现 - 等字符
8. 学生状态(用数字表示,正常、休学、毕业...)
*/语句设计如下:
create table student (
id int,
name varchar(10),
gender char(1),
birthday date,
score double(5,2),
email varchar(15),
tel varchar(15),
status tinyint
);查看表结构
desc 表名称; #描述表结构
describe 表名称; #描述表结构
show columns from 表名称 #描述表的结构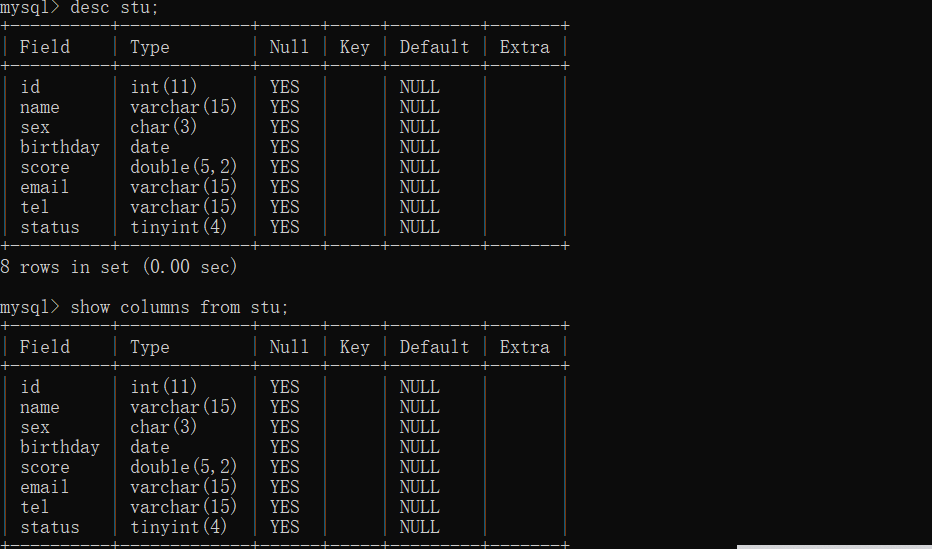
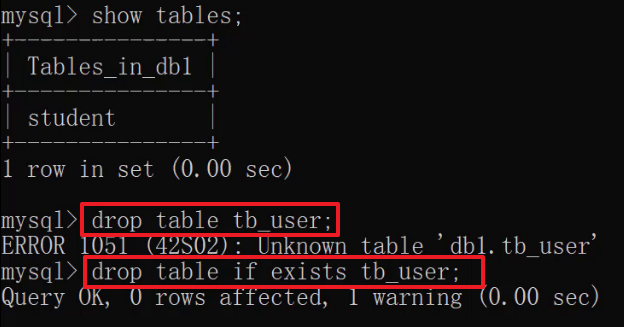
删除表
DROP TABLE 表名;删除表时判断表是否存在
DROP TABLE IF EXISTS 表名;运行语句效果如下:
修改表
修改表名
ALTER TABLE 表名 RENAME TO 新的表名;
-- 将表名student 修改为stu
alter table student rename to stu;添加一列
ALTER TABLE 表名 ADD 列名 数据类型;
-- 给stu表添加一列address,该字段类型是varchar(50)
alter table stu add address varchar(50);修改数据类型
ALTER TABLE 表名 MODIFY 列名 新数据类型;
-- 将stu表中的address字段的类型改为char(50)
alter table stu modify address char(50);
修改列名和数据类型
ALTER TABLE 表名 CHANGE 列名 新列名 新数据类型;
-- 将stu表中的address字段名改为addr,类型改为varchar(50)
alter table stu change address addr varchar(50);删除列
ALTER TABLE 表名 DROP 列名;
-- 将stu表中的addr字段 删除
alter table stu drop addr;DML
DML主要是对数据进行增(inserdelete)改(updata)操作。
添加数据
给指定的列添加数据
INSERT INTO 表名(列名1,列名2,...)VALUES(值1,值2,...);给全部列添加数据
INSERT INTO 表名 VALIES(值1,值2,...);批量添加数据
INSERT INTO 表名(列名1,列名2,...) VALUES(值1,值2,...),(值1,值2,...),(值1,值2,...)...;
INSERT INTO 表名 VALUES(值1,值2,...),(值1,值2,...),(值1,值2,...)...;练习
为了演示一下的增删改操作,先将查询的所有数据给大家:
select * from stu;
-- 给指定列添加数据
INSERT INTO stu(id,name) VALUES(1,'张三');
-- 给所有列添加数据,列名的列表可以省略的
INSERT INTO stu(id, name,sex,brithday,score,email,tel,STATUS) VALUES (2,'李四','男','1999-11-11',88.88,'lisi@itcast.cn','13888888888',1);
INSERT INTO stu VALUES(2,'李四','男','1999-1-11',88.88,'lisi@itcast.cn','13888888888',1);
-- 批量添加数据
INSERT INTO stu VALUES
(2,'李四','男','1999-11-11',88.88,'lisi@itcast.cn','13888888888',1),
(2,'李四','男','1999-11-11',88.88,'lisi@itcast.cn','13888888888',1),
(2,'李四','男','1999-11-11',88.88,'lisi@itcast.cn','13888888888',1);修改数据
修改表数据
UPDATE 表名 SET 列名1=值1,列名2=值2,...[WHERE 条件];
注意:
- 修改语句中如果不加条件,则将所有数据都修改!
- 像上面的语句中的中括号,表示在写sql语句中可以省略这部分
练习:
- 将张三的性别改为女
update stu set sex = '女' where name = '张三';
- 将张三的生日改为 1999-12-12 分数改为99.99
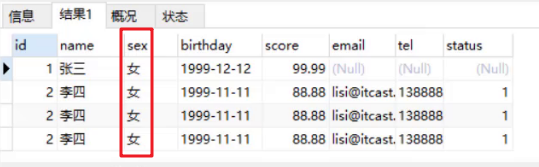
update stu set brithday = '199-12-12' , score = '99.99' where name = '张三';- 注意:如果updata语句没有加where条件,则会将表中的数据全部修改!
update stu set sex = '女';上面语句的执行完查询到的结果是:
-
删除数据
-
DELETE FROM 表名 [WHERE 条件];
注意:如果删除语句没where,此时会将数据表中的记录全部删除,类似TRUNCATE TABLE。
TRUNCATE将直接删除原来的表,并重新创建一个表,其语法结构为 TRUNCATE TABLE table_name。
TRUNCATE直接删除表而不是删除记录,因此执行速度比DELETE快。而且不能用在有主外键关系的主表
中。
DQL
查询的完整语法:
SELECT
字段列表
FROM
表名列表
WHERE
条件列表
GROUP BY
分组字段
HAVING
分组后条件
ORDER BY
排序字段
LIMIT
分页限定
为了给方便演示查询语句,我们先准备表及一些数据:
-- 删除stu表
drop table if exists stu;
-- 创建stu表
create table stu(
id int, -- 编号
name varchar(20), -- 姓名
age int, -- 年龄
sex varchar(5), -- 性别
address varchar(100), -- 地址
math double(5,2), -- 数学成绩
english double(5,2), -- 英语成绩
hire_date date -- 入学时间
);
-- 添加数据
INSERT INTO stu(id,NAME,age,sex,address,math,english,hire_date)
VALUES
(1,'张三',55,'男','杭州',66,78,'1995-09-01'),
(2,'李四',45,'女','深圳',98,87,'1998-09-01'),
(3,'马斯克',55,'男','香港',56,77,'1999-09-02'),
(4,'柳白',20,'女','湖南',76,65,'1997-09-05'),
(5,'柳青',20,'男','湖南',86,NULL,'1998-09-01'),
(6,'刘德花',57,'男','香港',99,99,'1998-09-01'),
(7,'张学右',22,'女','香港',99,99,'1998-09-01'),
(8,'德玛西亚',18,'男','南京',56,65,'1994-09-02');基础查询
语法
- 查询多个字段
SELECT 字段列表 FROM 表名; SELECT * FROM 表名; -- 查询所有数据 - 去除重复记录
SELECT DISTINCT 字段列表 FROM 表名 - 起别名
AS :AS也可以省略
练习:
- 查询name、age、两列。
select name,age from stu; - 查询所有列的数据,列名的列表可以使用*代替
select * from stu;上面语句中的*不建议大家使用,因为在写*不方便我们阅读sql语句。
-
查询地址信息
select addresss from stu;执行上面语句结果为:
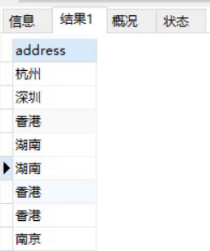
从上述数据可以看到由重复的数据,我们也可以使用distinct关键字去重重复数据。
-
去除重复记录
select distinct address from stu; - 查询姓名、数学成绩、英语成绩。并通过as给math和english起别名(as关键字可以省略)
select math as 数学成绩,english 英语成绩 from stu;
条件查询
语法
SELECT 字段列表 FROM 表名 WHERE 条件列表;- 条件
条件列表可以使用以下运算符
条件查询训练
- 查询年龄大于20岁的学院信息
select * from stu where age > 20; - 查询年龄大于等于20岁的学员信息
select * from stu where age >= 20; - 查询年龄大于等于20岁 并且 年龄小于等于30岁的学院信息
select * from stu where age >= 20 && age <=30; select * from stu where age >= 20 and age <= 30; -- 上面语句建议使用and select * from stu where age between 20 and 30; - 查询入学日期在'1998-09-01' 到 '1999-09-01'之间的学院信息
select * from stu where hire_data between '1998-09-01' and '1999-09-01'; - 查询年龄不等于18岁的学员信息
select * from stu where age != 18; select * from stu where age <> 18; - 查询年龄等于18岁 或者 年龄等于20岁 或者 年龄等于22岁的学员信息
select * from stu where age = 18 or age = 20 or age = 22; select * from stu where in(18,20,22); - 查询英语成绩为null的学员信息。null值的比较不能使用 = 或者 !=。需要使用is或者is not
select * from stu where english is null; -- 查询英语成绩为null的 select * from stu where english is not null; -- 查询英语成绩不为null的
模糊查询练习
模糊查询使用like关键字,可以使用通配符进行占位:
- _:代表单个任意字符
- %:代表任意个数字符
- 查询姓‘张’的学员信息
select * from stu where name like '张%'; - 查询第二个字是‘花’的学员信息
select * from stu where name like '_花%'; - 查询名字中包含‘德’的学员信息
select * from stu where name like '%德%';
排序查询
语法
SELECT 字段列表 FROM 表名 ORDER BY 排序字段名1 [排序方式1],排序字段名2 [排序方式2] …; ;上述语句中的排序方式有两种,分别是:
- ASC:升序排列(默认值,可省略)
- DESC:降序排列
注意:如果有多个排序条件,当前便的条件值一样时,才会根据第二条件进行排序
练习:
- 查询学生信息,按照年龄升序排列
select * from stu order by age;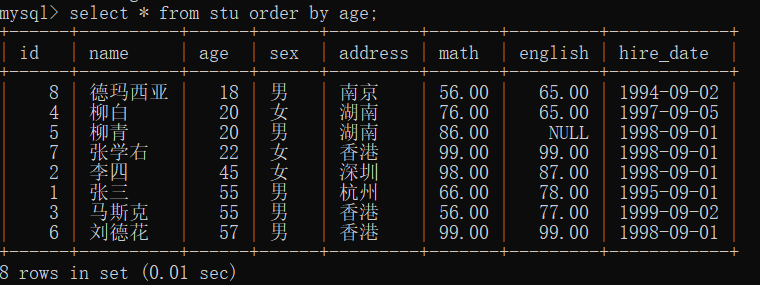
- 查询学生信息,按照数学成绩降序排列
select * from stu order by math desc;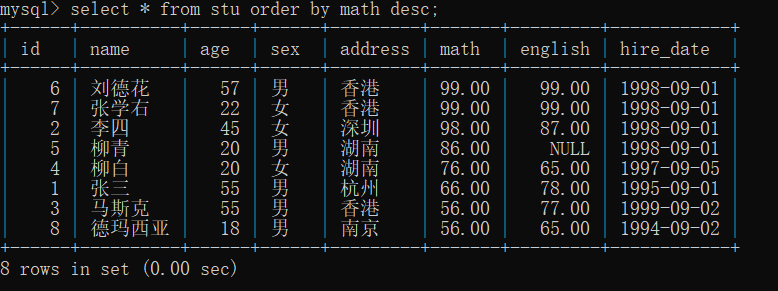
-
查询学生信息,按照数学成绩降序排序,如果数学成绩一样,再按照英语成绩升序排列
select * from stu order by math desc,english asc;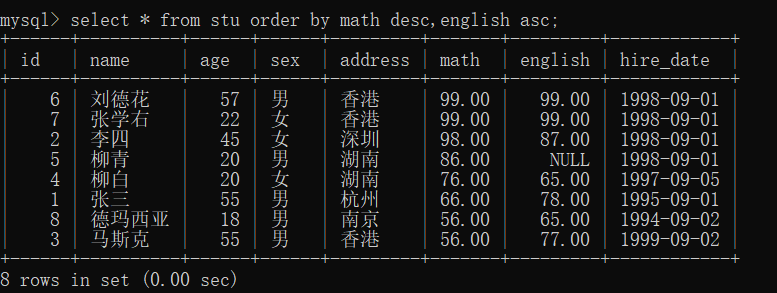
聚合函数
概念
将一列数据作为一个整体,进行纵向计算
假如有下表: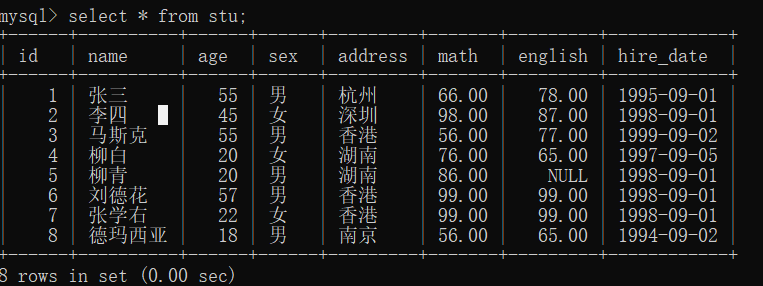
现有一需求让我们求表中所有数据的数学成绩的总和。这就是对math字段进行纵向求和。
聚合函数分类
| 函数名 | 功能 |
| count(列名) | 统计数量(一般选用不为null的列) |
| max(列名) | 最大值 |
| min(列名) | 最小值 |
| sum(列名) | 求和 |
| avg(列名) | 平均值 |
聚合函数的语法
select 聚合函数(列名) from 表名;注意:null值不参与所有聚合函数的运算
练习
- 统计班级一共有多少个学生
select count(id) from stu; select count(english) from stu;上面语句根据某一个字段进行统计,如果该字段某一行的值为null的话,将不会被统计。所以可以在count(*)来实现。*表示所有字段数据,一行中也不可能所有的数据都为null,所以建议使用count(*)
select count(*) from stu;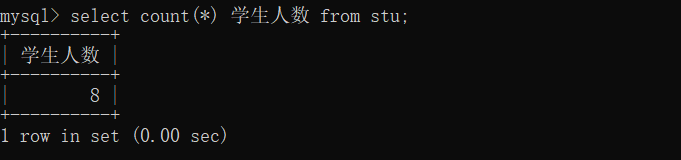
-
查询数学成绩的最高分
select max(math) from stu; - 查询数学成绩的最低分
select min(math) from stu; - 查询数学成绩的总分
select sum(math) from stu; - 查询数学成绩的平均分
select avg(math) from stu;
分组查询
语法
SELECT 字段列表 FROM 表名 [WHERE 分组前条件限定] GROUP BY 分组字段名 [HAVING 分组后条件的过滤];注意:分组之后,查询的字段为聚合函数和分组字段,查询其他字段无任何意义
练习
- 查询男同学和女同学各自的数学平均分
select sex,avg(math) from stu group by sex; - 查询男同学和女同学各自的数学平均分,以及各自人数
select sex,avg(math),count(*) from stu group by sex; - 查询男同学和女同学各自的数学平均分,以及各自的人数,要求:分数低于70的不参与分组
select sex,avg(math),count(*) from stu where math > 70 group by sex; - 查询男同学和女同学各自的数学平均分,以及各自人数,要求:分数低于70分的不参与分组,分组之后人数大于2人的
select sex,avg(math),count(*) from stu where math > 70 group by sex having count(*) > 2;
where 和 having区别:
- 执行时机不一样:where时分组之前进行限定,不满足where条件,则不参加分组,而having是对分组后进行筛选,
- 可判断的条件不一样:where不能对聚合函数进行判断,having可以。
分页查询
分页查询是将数据一页一页的展示给客户看,用户也可以通过点击查看下一页的数据。
分页查询的语法。
语法
SELECT 字段列表 FROM 表名 LIMIT 起始索引 , 查询条数;注意:上述语句中的其实索引是从0开始的
练习
起始索引计算公式:
起始索引 = (当前页码 - 1) * 每页显示的条数
- 从0开始查询,查询3条数据
select * from stu limit 0 , 3; - 每页显示3条数据,查询第一页数据
select * from stu limit 0 , 3; - 每页显示3条数据,查询第二页数据
select * from stu limit 3,3; - 每页显示3条数据,查询第三页数据
select * from stu limit 6,3;















 258
258











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









