






小白一个,正在学习中
看到了requests的用法想尝试一下
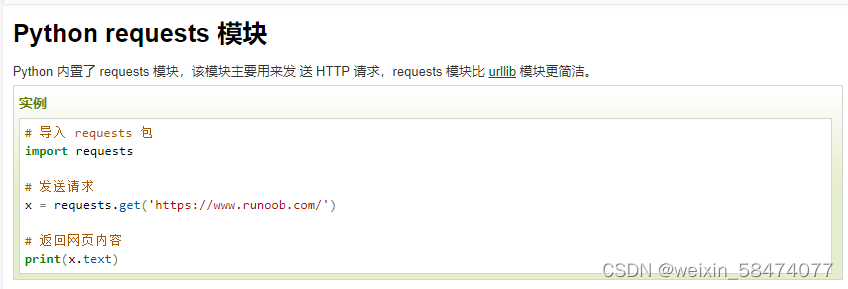
仿照着写一段,想爬一下’我们仨‘这篇小说的目录
# 导入requests 包
import requests
# 发送请求
x = requests.get('https://www.513gp.org/book/5105/')
# 返回网页内容
print(x.text)运行后发现全是乱码
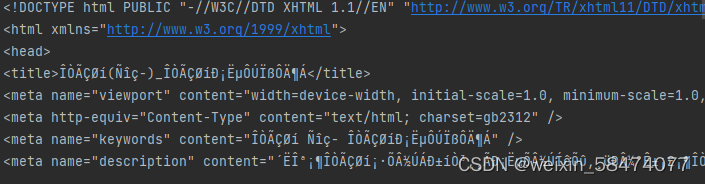
于是就在网上搜资料,里面有讲可能是网页编码格式不对,于是尝试了其它编码格式
utf-8
# 导入requests 包
import requests
# 发送请求
x = requests.get('https://www.513gp.org/book/5105/')
x.encoding = 'utf-8'
# 返回网页内容
print(x.text)运行后
仍然为乱码
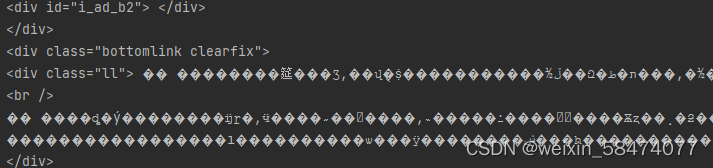
gbk
# 导入requests 包
import requests
# 发送请求
x = requests.get('https://www.513gp.org/book/5105/')
x.encoding = 'gbk'
# 返回网页内容
print(x.text)运行后
正常了

以上两种编码编码格式是乱猜的,也不能完全靠猜吧,于是又找到了一种比较稳妥的方式----直接查看原网页的编码方式
有一个charset = gb2312,那gb2312就是该网页的编码方式了
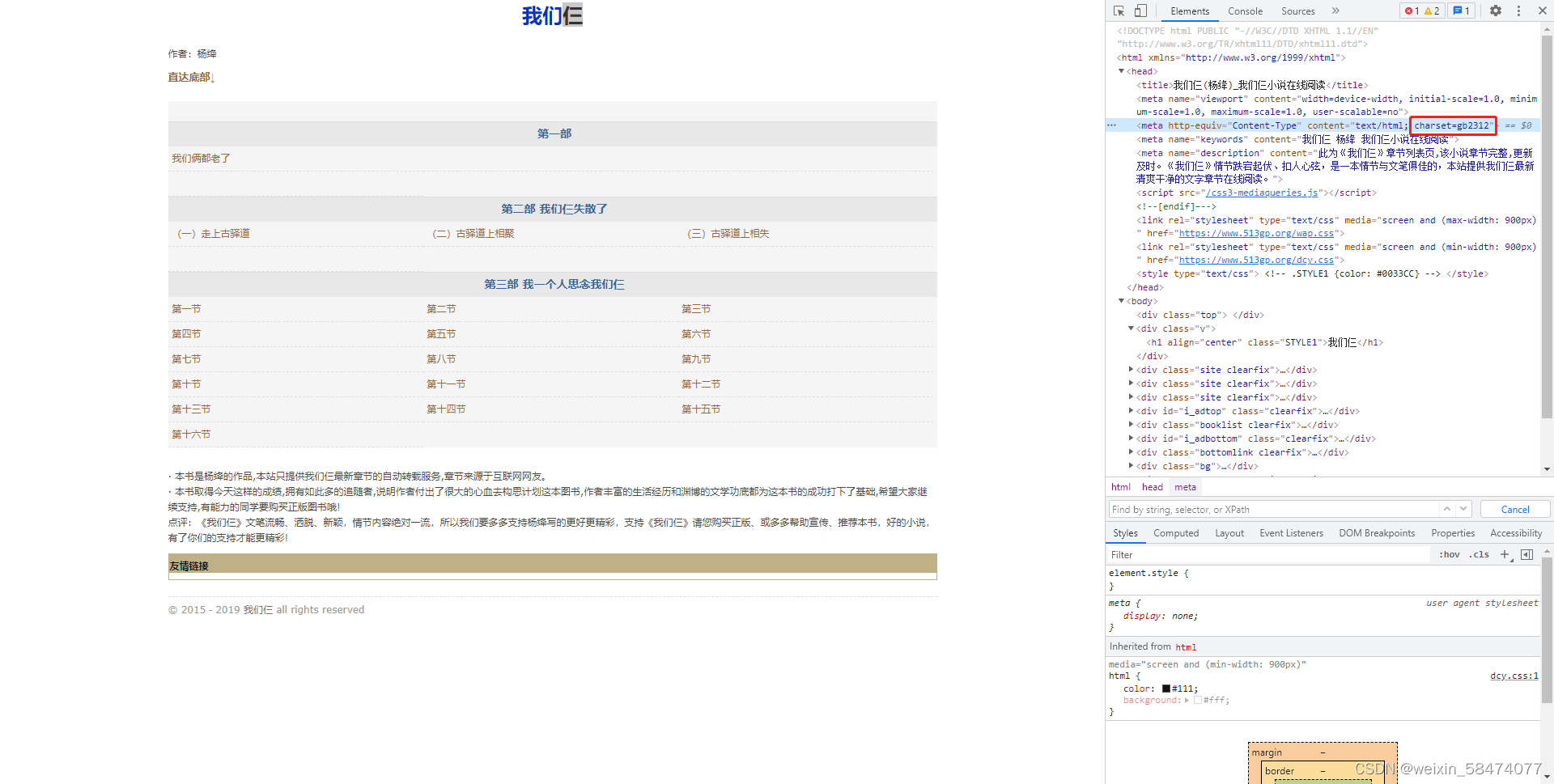
再次尝试
# 导入requests 包
import requests
# 发送请求
x = requests.get('https://www.513gp.org/book/5105/')
x.encoding = 'gb2312'
# 返回网页内容
print(x.text)运行
正常啦~















 1045
1045











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









