






在学习如何使用python下载网页上的图片时卡住了,我觉得还是有必要学习一下HTML,了解一下网页究竟是由什么组成的。
首先,什么是HTML?
HTML指的是超文本标记语言 HyperText Markup Language。不是编程语言,而是一种标记语言
下面是一个可视化的HTML页面结构:

只有<body>区域的才会在浏览器中显示
举个栗子:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>这是文档的标题</title>
</head>
<body>
<h1>这是一个大标题</h1>
<p>这是一个段落</p>
</body>
</html>解析如下:

- <!DOCTYPE html> 声明为 HTML5 文档
- <html> 元素是 HTML 页面的根元素
- <head> 元素包含了文档的元(meta)数据,如 <meta charset="utf-8"> 定义网页编码格式为 utf-8。
- <title> 元素描述了文档的标题
- <body> 元素包含了可见的页面内容
- <h1> 元素定义一个大标题
- <p> 元素定义一个段落
在网页打开的效果如下:
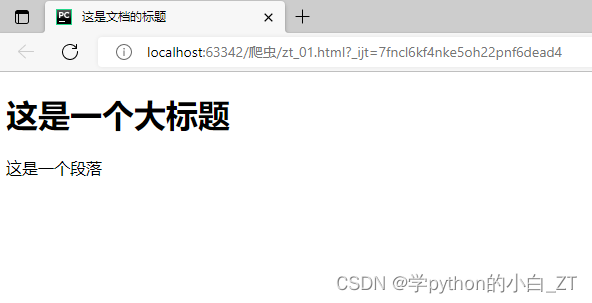
HTML标题
HTML标题是通过<h1>-<h6>标签来定义的,从h1到h6标题由大到小。举个栗子:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>这是文档的标题</title>
</head>
<body>
<h1>这是一个标题</h1>
<h2>这是一个标题</h2>
<h3>这是一个标题</h3>
<h4>这是一个标题</h4>
<h5>这是一个标题</h5>
<h6>这是一个标题</h6>
</body>
</html>打开后效果如下:

HTML段落
HTML段落是通过标签<p>来定义的,段落内容写在<p></p>的中间。举个栗子:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>这是文档的标题</title>
</head>
<body>
<p>这是段落1。</p>
<p>这是段落2。</p>
<p>这是段落3。</p>
</body>
</html>打开后效果如下:

每个段落间必须以<p>开头,</p>结尾,即使在<p></p>的中间敲了换行符也会被认为是同一个段落
<p>这是段落1。
这是段落2。
这是段落3。</p>
HTML链接
HTML链接是通过标签<a>来定义的,链接格式<a href="url">链接文本</a>。举个栗子:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>这是文档的标题</title>
</head>
<body>
<a href="http://www.baidu.com">百度</a>
</body>
</html>运行后效果如下:
首先有一个名称为百度的超链接

点击链接,会跳转到百度的搜索页面

HTML图像
HTML图像是通过标签<img>来定义的
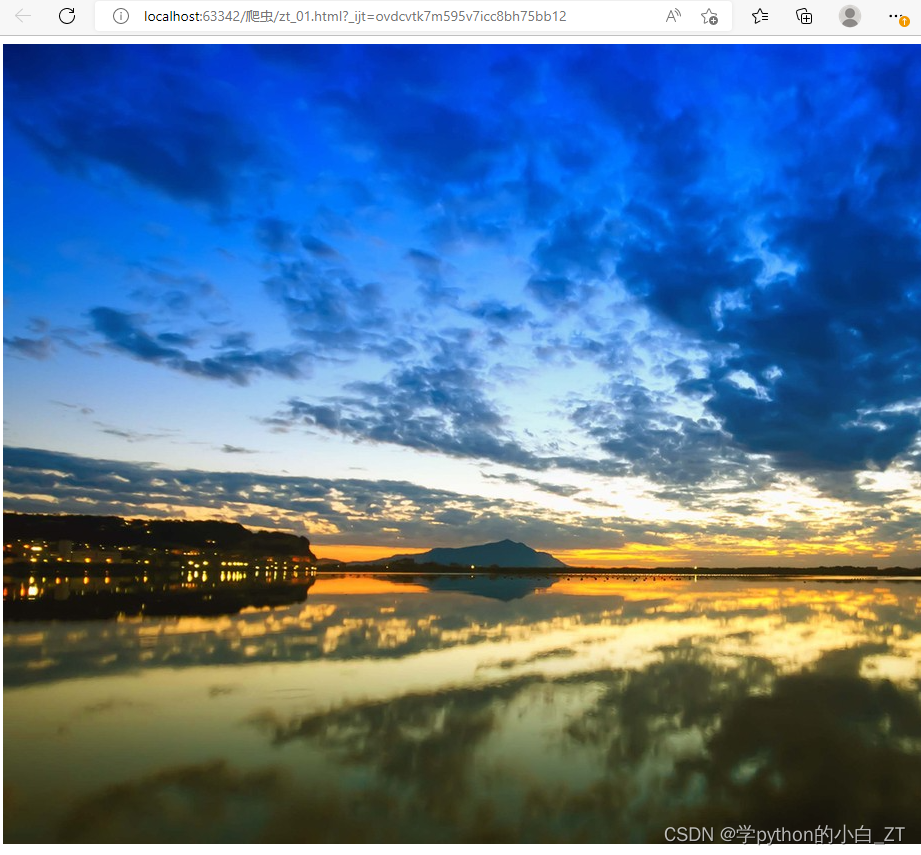
1、插入本地的图像:
相对路径:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>这是文档的标题</title>
</head>
<body>
<img src="images\电脑壁纸.jpg" />
</body>
</html>效果如下:
绝对路径:
<img src="D:\2\python\pycharm\PycharmProjects\爬虫\images\电脑壁纸.jpg" />效果如下:
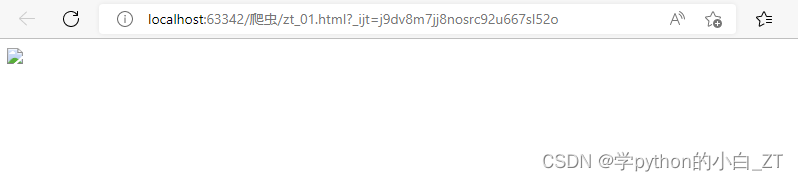
路径没问题,图片也没问题,但打开后就看不到图片了,找了半天也没看到有效的解决方法。这一块等我弄明白了再更新吧~














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









