






数据获取:
表格数据
数据清洗后数据:链接:https://pan.baidu.com/s/1D7qOZqKmF3YR3meQPsp3sQ
提取码:1234
数据下载下来后,先进行数据清洗。数据清洗在进行用户价值分析,也可以直接下载我清洗后的数据。
RFM模型:
RFM的含义:
R (Recency)︰客户最近一次交易时间的间隔。R值越大,表示客户交易发生的日期越久,反之则表示客户交易发生的日期越近。
F (Frequency)︰客户在最近一段时间内交易的次数。F值越大,表示客户交易越频繁,反之则表示客户交易不够活跃。
M(Monetary)︰客户在最近一段时间内交易的金额。M值越大,表示客户价值越高,反之则表示客户价值越低。
数据透视表:

如果我们对上面的数据做一个这样的数据透视表,在excel表个是这样的,因为这个表格中用户ID是很多重复的,所以我们要分析用户的话需要将用户提取出来,根据RFM模型,我们需要获得每个用户的 最后一次交易时间,交易次数,和最近一段时间内交易的金额。以上数据透视表已经将其体现出来了,那我们就将使用代码将以上功能体现出来。
# 透视表
df = data.pivot_table(index=['CustomerID'],
values=['InvoiceDate', 'InvoiceNo', 'total'],
aggfunc={'InvoiceDate': 'max', 'InvoiceNo': 'count', 'total': 'sum'}
)
print(df)CustomerID在excel 中放在行的位置,其实是列名; values:需要处理的数据 aggfunc:是需要处理的列计算方法
计算最后一次下单的时间就是InvoiceDate的最大值,InvoiceNo 计算交易了几次,total 交易了多少钱。
客户最近一次交易时间的间隔 = 分析的数据时间段内最晚的时间 - 最后一次交易时间,这里我们用InvoiceDate列所有数据最后一次交易时间为基准。减去每个用户最后一次交易时间,得到一个时间差,然后转换为天数。
df['R'] = (df['InvoiceDate'].max() - df['InvoiceDate']).dt.days # 求得天数
print(df)这样就添加了一列R

InvoiceNo对应的是F, total对应的是M。所以我们直接改列名就好
df.rename(columns = {'InvoiceNo':'F','total':'M'},inplace= True)
rfmdf = df[['R','F','M']]
print(rfmdf)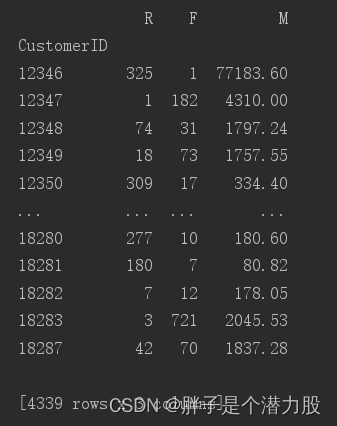
这样我们就将RFM数据提取处理了,具体要这么分析呢?
模型分类:
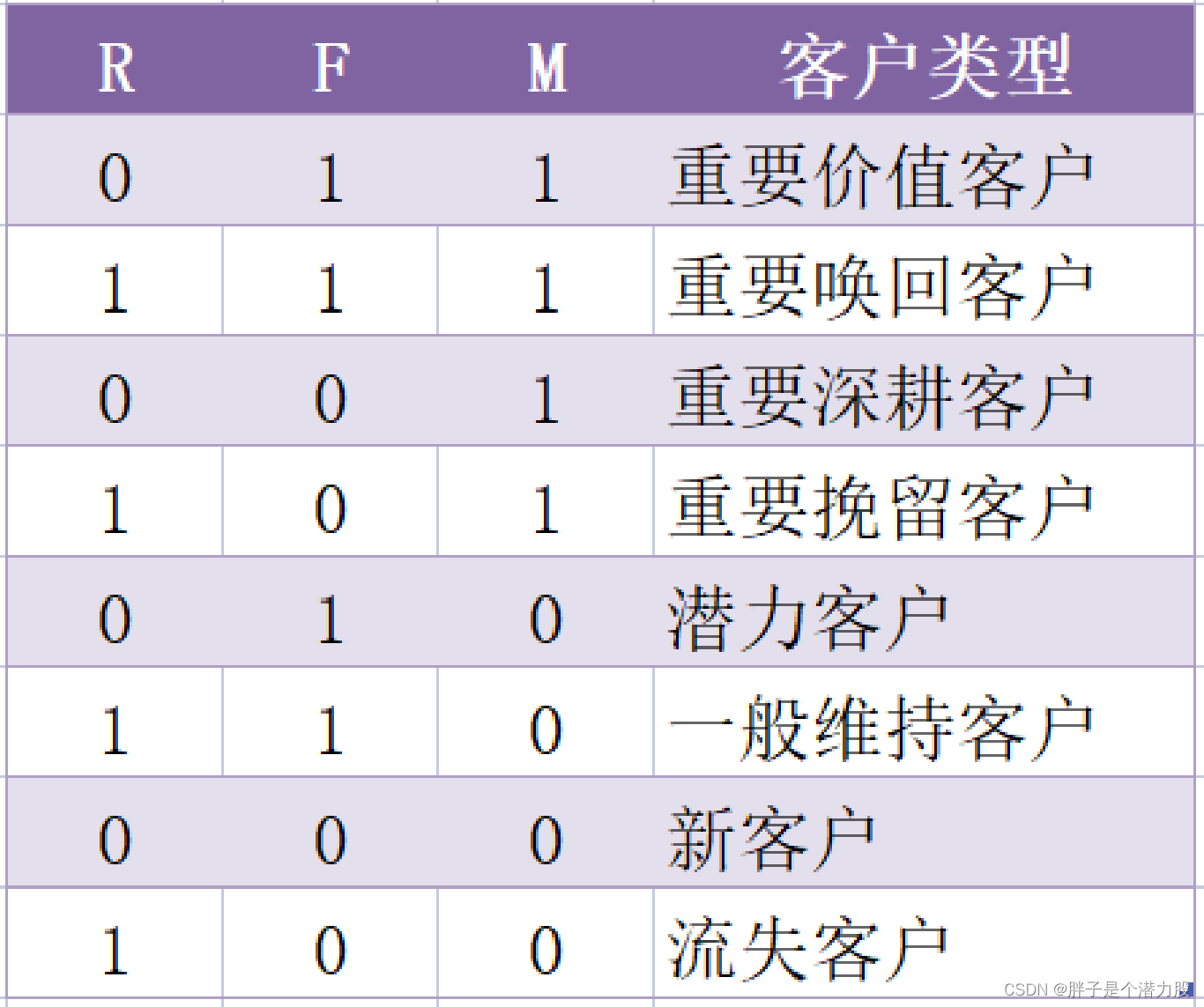
我们将数据转换为0和1。进行二分法 ,大于平均值的为1, 小于平均值的为 0
rfmdf = rfmdf.apply(lambda x : x- x.mean())
# 如果>平均值,则为'1',否则为'0'
rfmdf = rfmdf.applymap(lambda x : '1' if x>0 else '0')再去定义一个函数将进行定义什么类型的客户。
def func(x):
label = {
'111': '重要价值客户',
'101': '重要发展客户',
'011': '重要保持客户',
'001': '重要挽留客户',
'110': '一般价值客户',
'100': '一般发展客户',
'010': '一般保持客户',
'000': '一般挽留客户'
}
return label[x['R']+x['F']+x['M']]
rfmdf['label'] = rfmdf.apply(func,axis=1)
rfmdf['label'].value_counts()
print(rfmdf)
这里我们已经对客户进行了定义。但是表格不适合我们一眼看得到数据 ,接下来我们需要进行绘图。这里用到的函数是matplotlib。
对数据进行绘图:
首先我们得先下载matplotlib 函数包,命令行:pip install matplotlib
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.size'] = 20
rfmdf['label'].value_counts().plot.bar(figsize=(20,9),color='red',alpha=0.6)
plt.xticks(rotation =0)
for i ,j in enumerate(rfmdf['label'].value_counts()):
plt.text(i-0.1,j+50,j,va='center')
plt.show()
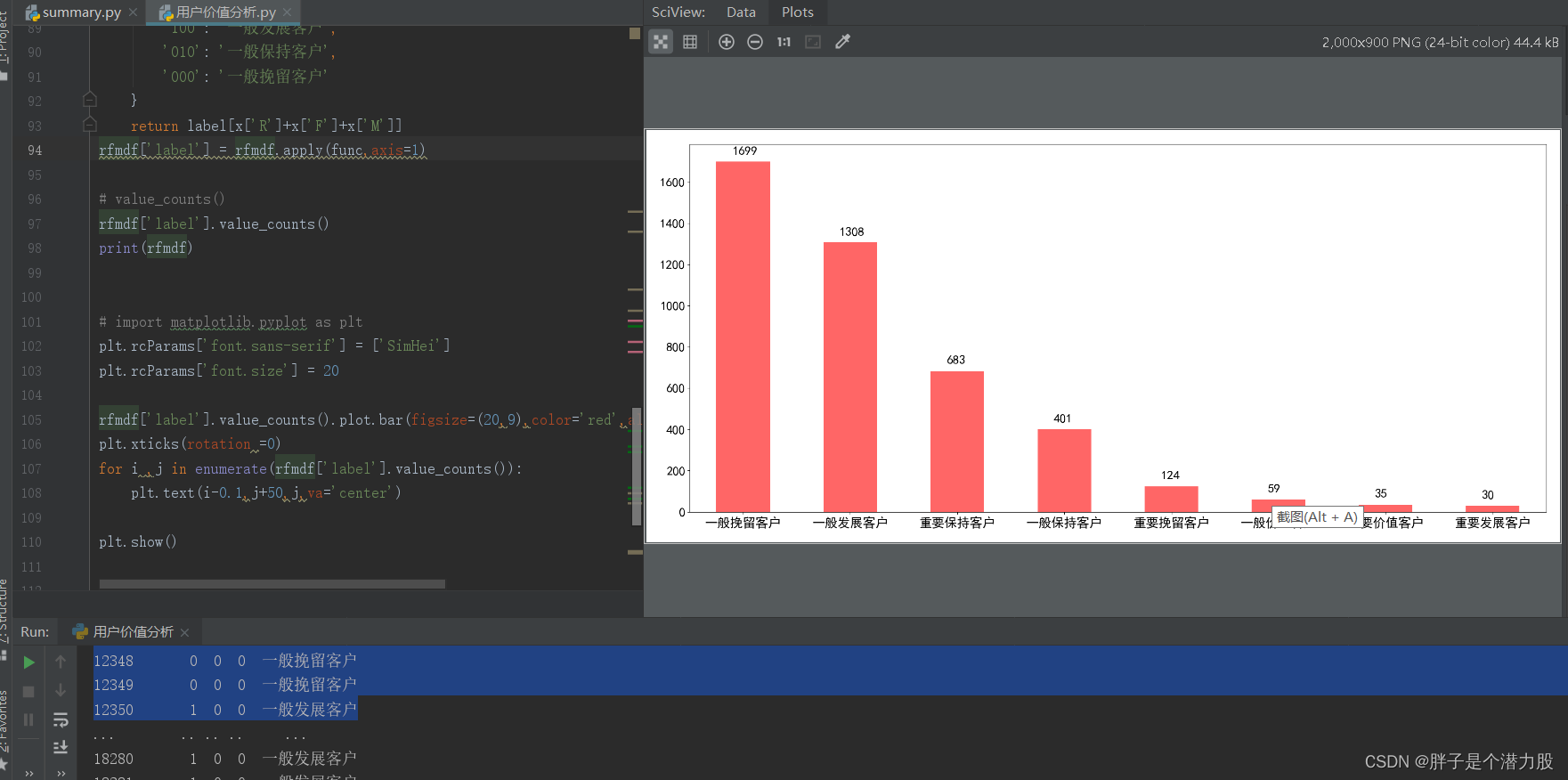
我这边用的是柱状图,你们可以用饼图或者其他图都可以。
以下是完整的代码
import pandas as pd
# import numpy as np
import matplotlib.pyplot as plt
data = pd.read_csv(r'E:\数据分析\用户价值分析 RFM模型\data.csv')
pd.set_option('display.max_columns', 888) # 大于总列数
pd.set_option('display.width', 1000)
# print(data.head())
# print(data.info())
# .空值处理
# print(data.isnull().sum()) # 空值中和,查看每一列的空值
# 空值删除
data.drop(columns=['Description'], inplace=True)
# CustomerID有空值
# 删除所有列的空值
data.dropna(inplace=True)
# print(data.isnull().sum()) # 由于CustomerID为必须字段,所以强制删除其他列,以CustomerID为准
#
# 转换为日期类型
data['InvoiceDate'] = pd.to_datetime(data['InvoiceDate'])
# CustomerID 转换为整型
data['CustomerID'] = data['CustomerID'].astype('int')
# print(data.describe())
data = data[data['Quantity'] > 0]
# print(data)
#
# 查看重复值
# data[data.duplicated()]
# print(data[data.duplicated()])
# 删除重复值
data.drop_duplicates(inplace=True)
# 每张发票的总价
data['total'] = data['Quantity'] * data['UnitPrice']
# # 透视表
df = data.pivot_table(index=['CustomerID'],
values=['InvoiceDate', 'InvoiceNo', 'total'],
aggfunc={'InvoiceDate': 'max', 'InvoiceNo': 'count', 'total': 'sum'}
)
# 1) 对用户进行分组,求得每个用户最后一次交易时间
# 2) 分析的数据时间段内最晚的时间 - 最后一次交易时间
df['R'] = (df['InvoiceDate'].max() - df['InvoiceDate']).dt.days # 求得天数
# print(df)
df.rename(columns = {'InvoiceNo':'F','total':'M'},inplace= True)
rfmdf = df[['R','F','M']]
print(rfmdf)
# 先二分
rfmdf = rfmdf.apply(lambda x : x- x.mean())
# 如果>平均值,则为'1',否则为'0'
rfmdf = rfmdf.applymap(lambda x : '1' if x>0 else '0')
def func(x):
label = {
'111': '重要价值客户',
'101': '重要发展客户',
'011': '重要保持客户',
'001': '重要挽留客户',
'110': '一般价值客户',
'100': '一般发展客户',
'010': '一般保持客户',
'000': '一般挽留客户'
}
return label[x['R']+x['F']+x['M']]
rfmdf['label'] = rfmdf.apply(func,axis=1)
# value_counts()
rfmdf['label'].value_counts()
print(rfmdf)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.size'] = 20
rfmdf['label'].value_counts().plot.bar(figsize=(20,9),color='red',alpha=0.6)
plt.xticks(rotation =0)
for i ,j in enumerate(rfmdf['label'].value_counts()):
plt.text(i-0.1,j+50,j,va='center')
plt.show()
















 4244
4244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











