






文件的随机读写
ftell函数参数

ftell函数:返回文件指针相较于起始位置的偏移量
rewind函数参数

rewind函数:让文件的位置回到文件的起始位置
fseek函数参数
第一个参数:流
第二个参数:要偏移的字节数。
第三个参数:
SEEK_SET:文件开始位置
SEEK_CUR:文件指针的当前位置
SEEK_END:文件的末尾
执行代码前,先创建记事本并更名为:data.txt,并写入信息:

下面我们看下面代码学习fseek、fseek、rewind函数的使用:
int main()
{
int arr[10] = { 0 };
FILE* pf = fopen("data.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//读文件
//定位文件指针
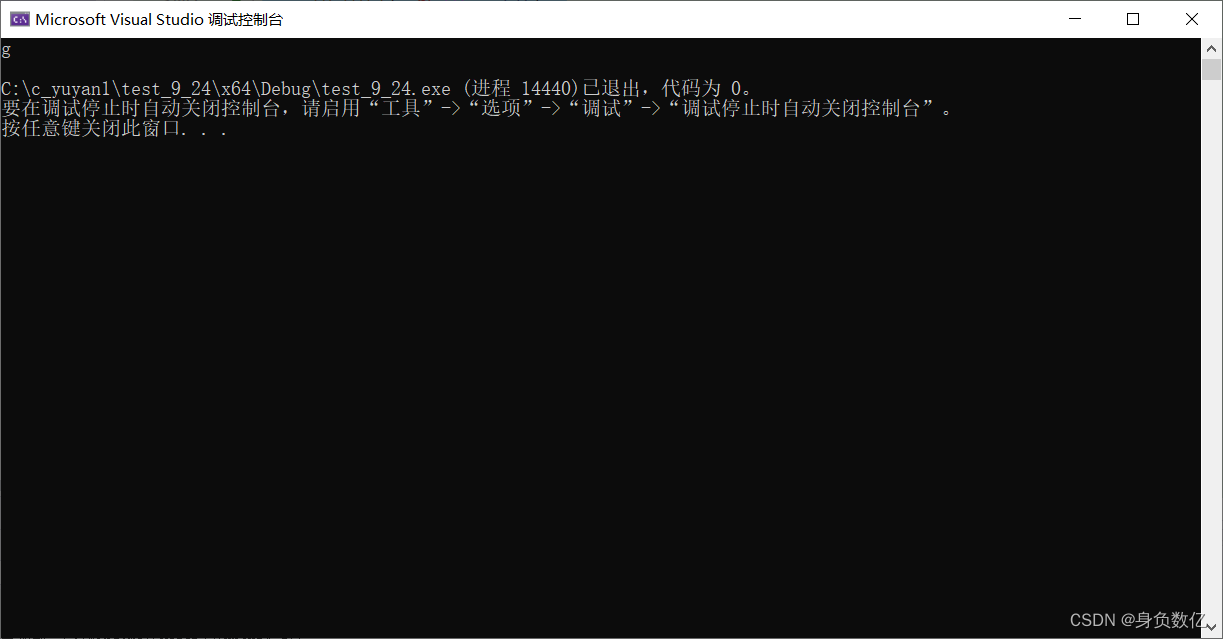
fseek(pf, 6, SEEK_SET);//SEEK_SET:文件开始位置 ->相较于文件开始位置偏移量为6的地方
int ch = fgetc(pf);
printf("%c\n", ch);
fclose(pf);
pf = NULL;
return 0;
}
代码结果如图:
int main()
{
int arr[10] = { 0 };
FILE* pf = fopen("data.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
//读文件
//定位文件指针
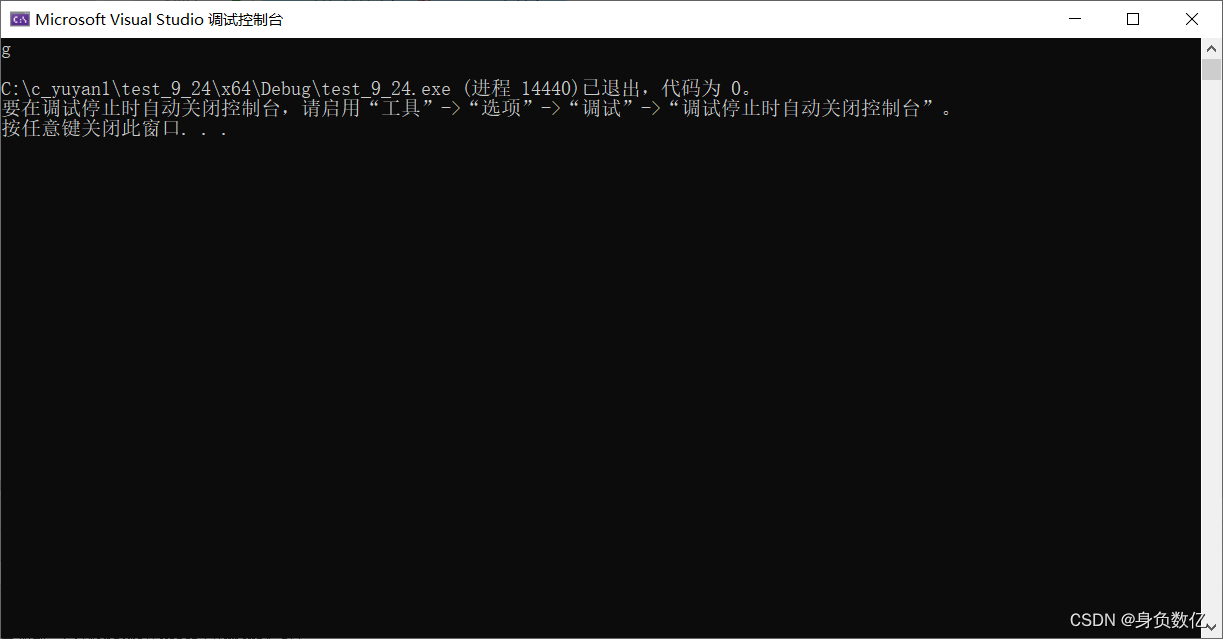
fseek(pf, -3, SEEK_END);//SEEK_END:文件的末尾
int ch = fgetc(pf);
printf("%c\n", ch);
fclose(pf);
pf = NULL;
return 0;
}
代码结果如图:
int main()
{
int arr[10] = { 0 };
FILE* pf = fopen("data.txt", "r");
if (pf == NULL)
{
perror("fopen");
return 1;
}
fseek(pf, 5, SEEK_CUR);//SEEK_CUR:文件指针的当前位置
int ch = fgetc(pf);
printf("%c\n", ch);
int pos = ftell(pf);//返回文件指针相较于起始位置的偏移量
printf("%d\n", pos);//计算偏移位置
rewind(pf);//让文件的位置回到文件的起始位置
ch = fgetc(pf);
printf("%c\n", ch);
fclose(pf);
pf = NULL;
return 0;
}
文件读取结束的判定
被错误使用的feof
牢记:在文件读取过程中,不能用feof函数的返回值直接来判断文件的是否结束。
feof 函数的作用是:当文件读取结束的时候,判断是读取结束的原因是否是:遇到文件尾结束。
- 文本文件读取是否结束,判断返回值是否为EOF(
fgetc),或者NULL(fgetc)
例如:
•fgetc判断是否为EOF
•fgets判断返回值是否为NULL - 二进制文件的读取结束判断,判断返回值是否小于实际要读的个数。
例如:
•fread判断返回值是否小于实际要读的个数。
文本文件的例子:
#include <stdio.h>
#include <stdlib.h>
int main(void)
{
int c;
FILE* fp = fopen("test.txt", "r");//以r形式打开文件
if(!fp) {
perror("File opening failed");
return EXIT_FAILURE;
}
//fgetc 当读取失败的时候或者遇到⽂件结束的时候,都会返回EOF
while ((c = fgetc(fp)) != EOF) //从fp指向里读取字符赋值给c并判断是否为EOF,不是则打印,是则结束循环
{
putchar(c);
}
//判断是什么原因结束的
if (ferror(fp))//如果为真则是遇到错误结束
puts("I/O error when reading");
else if (feof(fp))//如果为真则是遇到文件结尾结束
puts("End of file reached successfully");
fclose(fp);
}
⼆进制文件的例子:
#include <stdio.h>
enum { SIZE = 5 };
int main(void)
{
double a[SIZE] = { 1.,2.,3.,4.,5. };
FILE* fp = fopen("test.bin", "wb"); // 必须用二进制模式
fwrite(a, sizeof * a, SIZE, fp); // 写double的数组
fclose(fp);
double b[SIZE];
fp = fopen("test.bin", "rb");
size_t ret_code = fread(b, sizeof * b, SIZE, fp); // 读double的数组
if (ret_code == SIZE)
{
puts("Array read successfully, contents: ");
for (int n = 0; n < SIZE; ++n) printf("%f ", b[n]);
putchar('\n');
}
else { // error handling
if (feof(fp))
printf("Error reading test.bin: unexpected end of file\n");
else if (ferror(fp)) {
perror("Error reading test.bin");
}
}
fclose(fp);
}
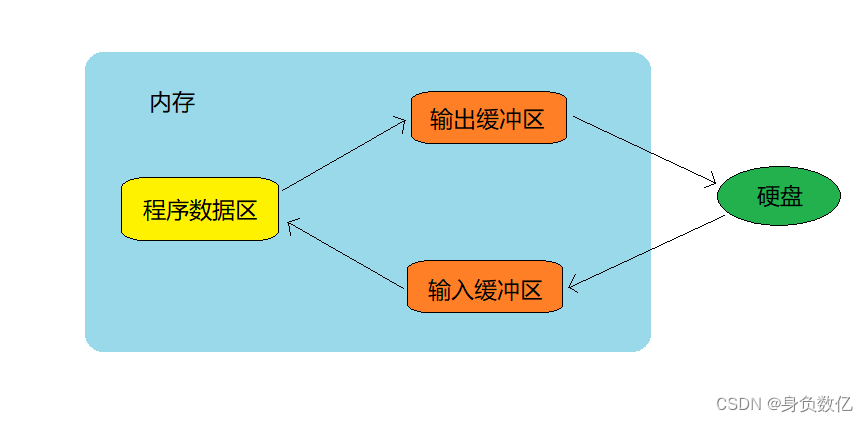
文件缓冲区
ANSIC标准采用“缓冲文件系统”处理的数据文件的,所谓缓冲文件系统是指系统自动地在内存中为程序中每⼀个正在使用的文件开辟一块“文件缓冲区”。从内存向磁盘输出数据会先送到内存中的缓冲区,装满缓冲区后才⼀起送到磁盘上。如果从磁盘向计算机读入数据,则从磁盘文件中读取数据输入到内存缓冲区(充满缓冲区),然后再从缓冲区逐个地将数据送到程序数据区(程序变量等)。缓冲区的大小根据C编译系统决定的。
我们来观察一段代码:
#include <windows.h>
int main()
{
FILE* pf = fopen("test.txt", "w");
fputs("abcdef", pf);//先将代码放在输出缓冲区
printf("睡眠10秒已经写数据了,打开test.txt文件,发现文件没有内容\n");
Sleep(10000);
printf("刷新缓冲区\n");
fflush(pf);//刷新缓冲区时,才将输出缓冲区的数据写到文件(磁盘)
//注:fflush在高版本的VS上不能使用了
printf("再睡眠10秒此时,再次打开test.txt文件,文件有内容了\n");
Sleep(10000);
fclose(pf);
//注:fclose在关闭文件的时候,也会刷新缓冲区
pf = NULL;
return 0;
}
刚开始创建test.txt记事本时,记事本无内容:

执行fflush函数后,再打开对应记事本查看,发现对应的信息已经写入成功了:















 6034
6034











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









