




 本文介绍了朴素贝叶斯算法的原理及其简化假设,详细阐述了算法的实现步骤,包括创建Beyes类,计算条件概率,以及如何对测试数据进行分类和评估准确率。
本文介绍了朴素贝叶斯算法的原理及其简化假设,详细阐述了算法的实现步骤,包括创建Beyes类,计算条件概率,以及如何对测试数据进行分类和评估准确率。
朴素贝叶斯,名字中的朴素二字就代表着该算法对概率事件做了很大的简化,简化内容就是各个要素之间是相互独立的。
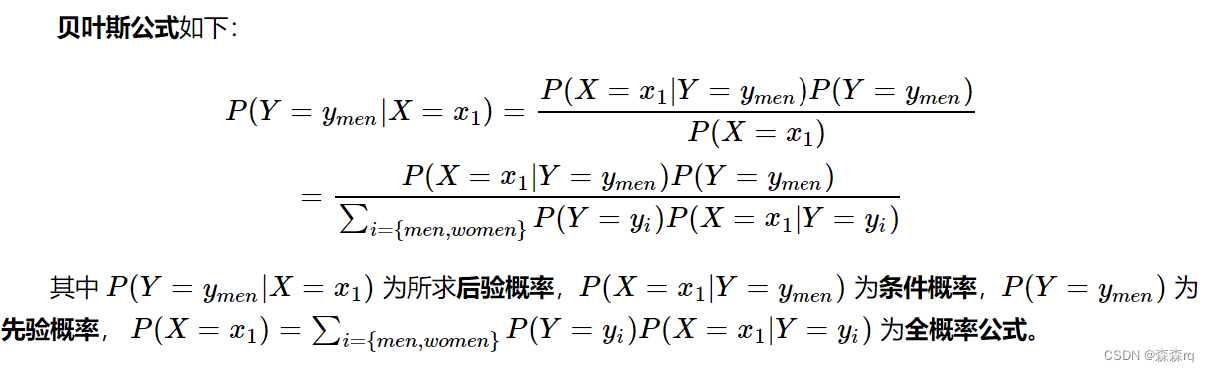
实现步骤:
1,创建Beyes类
2,类中包括四个方法,初始化方法用来创建保存中间计算结果的容器
3,fit 方法用来计算数据长度、计算条件概率所需数据集、
P(X)=∑kP(X|Y=Yk)P(Yk)
计算P(Yk):p_train_target
4,p_test_data用来计算一个样本的分类结果
5,classifier用来计算测试集所有分类结果
6,score用来计算准确率
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from collections import Counter
import time
class Beyes(object):
def __init__(self):
self.length = -1
self.train_target_list = []
self.p_train_target = {}
self.split_data_lis = []
self.feature_p_lis = []
self.predict = []
def fit(self, train_data, train_target):
"""
P(X)=∑kP(X|Y=Yk)P(Yk)
计算P(Yk):p_train_target
准备计算 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1726
1726

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









