






1、准备知识
贝叶斯分类是一类分类算法的总称,这类算法均以贝叶斯定理为基础,故统称为贝叶斯分类。
这个定理解决了现实生活里经常遇到的问题:已知某条件概率,如何得到两个事件交换后的概率,也就是在已知P(A|B)的情况下如何求得P(B|A)。这里先解释什么是条件概率:
表示事件B已经发生的前提下,事件A发生的概率,叫做事件B发生下事件A的条件概率。其基本求解公式为:
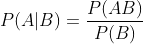
下面不加证明地直接给出贝叶斯定理:
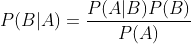
2、朴素贝叶斯分类
2.1、朴素贝叶斯分类原理
朴素贝叶斯分类是一种十分简单的分类算法,叫它朴素贝叶斯分类是因为这种方法的思想真的很朴素,朴素贝叶斯的思想基础是这样的:对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,哪个最大,就认为此待分类项属于哪个类别。
朴素贝叶斯分类的正式定义如下:
1、设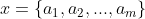 为一个待分类项,而每个a为x的一个特征属性。
为一个待分类项,而每个a为x的一个特征属性。
2、有类别集合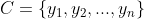 。
。
3、计算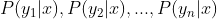 。
。
4、如果 ,则
,则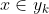 。
。
那么现在的关键就是如何计算第3步中的各个条件概率。我们可以这么做:
1、找到一个已知分类的待分类项集合,这个集合叫做训练样本集。
2、统计得到在各类别下各个特征属性的条件概率估计。即
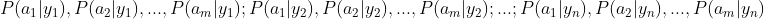
3、如果各个特征属性是条件独立的,则根据贝叶斯定理有如下推导:
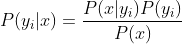
因为分母对于所有类别为常数,因为我们只要将分子最大化皆可。又因为各特征属性是条件独立的,所以有:
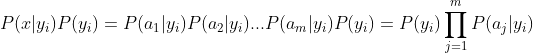
2.2、朴素贝叶斯分类流程
整个朴素贝叶斯分类分为三个阶段:
第一阶段——准备工作阶段,这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响,分类器的质量很大程度上由特征属性、特征属性划分及训练样本质量决定。
第二阶段——分类器训练阶段,这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。这一阶段是机械性阶段,根据前面讨论的公式可以由程序自动计算完成。
第三阶段——应用阶段。这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。这一阶段也是机械性阶段,由程序完成。
3、代码实战
# encoding:utf-8
import pandas as pd
import numpy as np
import json
class NaiveBayes:
def __init__(self):
self.model = {} # key 为类别名 val 为字典PClass表示该类的该类,PFeature:{}对应对于各个特征的概率
def calEntropy(self, y): # 计算熵
valRate = y.value_counts().apply(lambda x: x / y.size) # 频次汇总 得到各个特征对应的概率
valEntropy = np.inner(valRate, np.log2(valRate)) * -1
return valEntropy
def fit(self, xTrain, yTrain=pd.Series()):
if not yTrain.empty: # 如果不传,自动选择最后一列作为分类标签
xTrain = pd.concat([xTrain, yTrain], axis=1)
self.model = self.buildNaiveBayes(xTrain)
return self.model
def buildNaiveBayes(self, xTrain):
yTrain = xTrain.iloc[:, -1]
yTrainCounts = yTrain.value_counts() # 频次汇总 得到各个特征对应的概率
yTrainCounts = yTrainCounts.apply(lambda x: (x + 1) / (yTrain.size + yTrainCounts.size)) # 使用了拉普拉斯平滑
retModel = {}
for nameClass, val in yTrainCounts.items():
retModel[nameClass] = {'PClass': val, 'PFeature': {}}
propNamesAll = xTrain.columns[:-1]
allPropByFeature = {}
for nameFeature in propNamesAll:
allPropByFeature[nameFeature] = list(xTrain[nameFeature].value_counts().index)
# print(allPropByFeature)
for nameClass, group in xTrain.groupby(xTrain.columns[-1]):
for nameFeature in propNamesAll:
eachClassPFeature = {}
propDatas = group[nameFeature]
propClassSummary = propDatas.value_counts() # 频次汇总 得到各个特征对应的概率
for propName in allPropByFeature[nameFeature]:
if not propClassSummary.get(propName):
propClassSummary[propName] = 0 # 如果有属性灭有,那么自动补0
Ni = len(allPropByFeature[nameFeature])
propClassSummary = propClassSummary.apply(lambda x: (x + 1) / (propDatas.size + Ni)) # 使用了拉普拉斯平滑
for nameFeatureProp, valP in propClassSummary.items():
eachClassPFeature[nameFeatureProp] = valP
retModel[nameClass]['PFeature'][nameFeature] = eachClassPFeature
return retModel
def predictBySeries(self, data):
curMaxRate = None
curClassSelect = None
for nameClass, infoModel in self.model.items():
rate = 0
rate += np.log(infoModel['PClass'])
PFeature = infoModel['PFeature']
for nameFeature, val in data.items():
propsRate = PFeature.get(nameFeature)
if not propsRate:
continue
rate += np.log(propsRate.get(val, 0)) # 使用log加法避免很小的小数连续乘,接近零
# print(nameFeature, val, propsRate.get(val, 0))
# print(nameClass, rate)
if curMaxRate is None or rate > curMaxRate:
curMaxRate = rate
curClassSelect = nameClass
return curClassSelect
def predict(self, data):
if isinstance(data, pd.Series):
return self.predictBySeries(data)
return data.apply(lambda d: self.predictBySeries(d), axis=1)
dataTrain = pd.read_csv("xiguadata.csv", encoding="gbk")
naiveBayes = NaiveBayes()
treeData = naiveBayes.fit(dataTrain)
print(json.dumps(treeData, ensure_ascii=False))
pd = pd.DataFrame({'预测值': naiveBayes.predict(dataTrain), '正取值': dataTrain.iloc[:, -1]})
print(pd)
print('正确率:%f%%' % (pd[pd['预测值'] == pd['正取值']].shape[0] * 100.0 / pd.shape[0]))
运行结果如下图:
















 2717
2717











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









