







机器学习+深度学习入门
前言:本文的材料引用自李宏毅老师的MACHINE LEARNING 2021 SPRING课程,我在第一次看这个课程时真的被震撼到了,原来机器学习可以这么讲,并且非常丝滑的引出了Deep Learning等一系列概念,在之前为了入门机器学习和深度学习也单独看了很多文章,但是都是似懂非懂的感觉,在看了李宏毅老师的课程后突然就把许多不懂或者疑惑的概念串起来了,于是将第一节课的内容课件整理成本文,非常推荐去体验老师的原课程。
机器学习就是机器自己写函数的过程,同一个函数通过调整参数值相加最终得到最终模型的函数。
Introduction
什么是机器学习
Machine Learning ~= Looking for Function
机器自己去寻找一个函数的过程
不同类型的函数(function)
-
Regression: The function outputs a scalar. 回归
-
Classification: Given options (classes), the function outputs the correct one. 分类
-
Structured Learning
create something with structure (image, document)
但事实上机器学习中分类和回归只是这片大地一小部分,如今机器学习面临着更多的挑战,我们将剩下的部分成为Structured Learning,这些余下的部分要求机器可以去自己创造一些东西(图片,文章等)
Pre: 机器学习的三个步骤
三个步骤合起来的过程称为训练(Training)

1. Function with Unknown Parameters
-
y = b + wx1 base on domain knowledge
我们将这个函数称为一个Model,在机器学习中Model就是一个带有未知Parameter的Function。
- x1:已知,我们称之为feature
- w:未知,我们称之为weight
- b:未知,我们称之为bias
2. Define Loss from Training Data
-
Loss L(b, w)
Loss is a function of parameters.
Loss: how good a set of values is.
Loss也是一个function,它的input是我们model里面的parameter,output为我们将这些未知参数设定一些数值的时候,这些数值好还是不好。
-
Loss的计算原理


-
^y: 代表真实的数据,我们将之称为label
-
e1: 代表估测的值跟真实值的差距,注意这里只是计算loss的一种方式,还有其他的方式
-
我们将每一天的误差加起来算出平均值得到最后的Loss
-
计算Loss的方式
-
MAE
𝑒=|𝑦−𝑦 ̂ |
𝐿 is mean absolute error (MAE)
-
MSE
𝑒=(𝑦−𝑦 ̂ )^2
𝐿 is mean square error (MSE)
-
If 𝑦 and 𝑦 ̂ are both probability distributions, we can use Cross-entropy.
-
3. Optimization
w*, b* = arg min(w, b) L
寻找w和b的值使Loss最小,我们将可以使Loss最小的w和b称为w*和b*,指最好的w和b。
-
Gradient Descent
-
-
先随机找一个值w0(之后会有计算出较好的w0的值的方法),这里只是举一个w0的例子
-
计算在w等于w0时,w这个参数对loss的微分是多少(求导)
Negative -> Increase w Positive -> Decrease w -
改变w,每次改变的值的大小受微分和n(见下)两个部分决定,n称为学习率,是一个hyperparameter,学习率越大updata的值就会越大
-
新的 w1 = w0 - 算出的学习率乘以微分结果
-
-

-
梯度下降存在的问题
存在local minima问题(暂定),真正的问题不是这个问题。

-
Hyperparameters
机器学习中需要自己设定的东西
我们把这种模型y = b + wx称为线性模型Linear Model。

Aft: 机器学习的三个步骤(深度学习)
1. Function with Unknown Parameters
-
模型的限制
线性模型太过简单,无法表示很复杂的情况。
我们将这种模型的限制称为Model Bias,注意这里的Model Bias跟之前的bias是不同的。

-
更复杂的模型
- 我们可以将这个红色的曲线看成一个常数项加上一个函数的集合。

- 我们将这个分段函数分为一个部分一个部分,然后用这个蓝色的函数去表示,这个蓝色的函数在值非常小时是一个值,非常大时是一个值,中间是一个过渡的过程,如图所示。最终我们用许多不同斜率的蓝色函数表示出了这个红色的分段函数。

- 我们发现所有的这种分段函数都可以通过这种方式来表示,越复杂的函数(红)也需要更多不同的函数(蓝)来表示

即使是曲线也可以通过分很多段去无限逼近曲线

-
现在的问题是我们怎么去表示出这个蓝色的函数
我们可以用一个曲线去逼近它,这个曲线的函数称为Sigmoid Function
而最初的蓝色的函数,我们称之为Hard Sigmoid

- 既然有了Sigmoid Function我们就可以通过调整Sigmoid Function的参数去逼近不同斜率的Hard Sigmoid
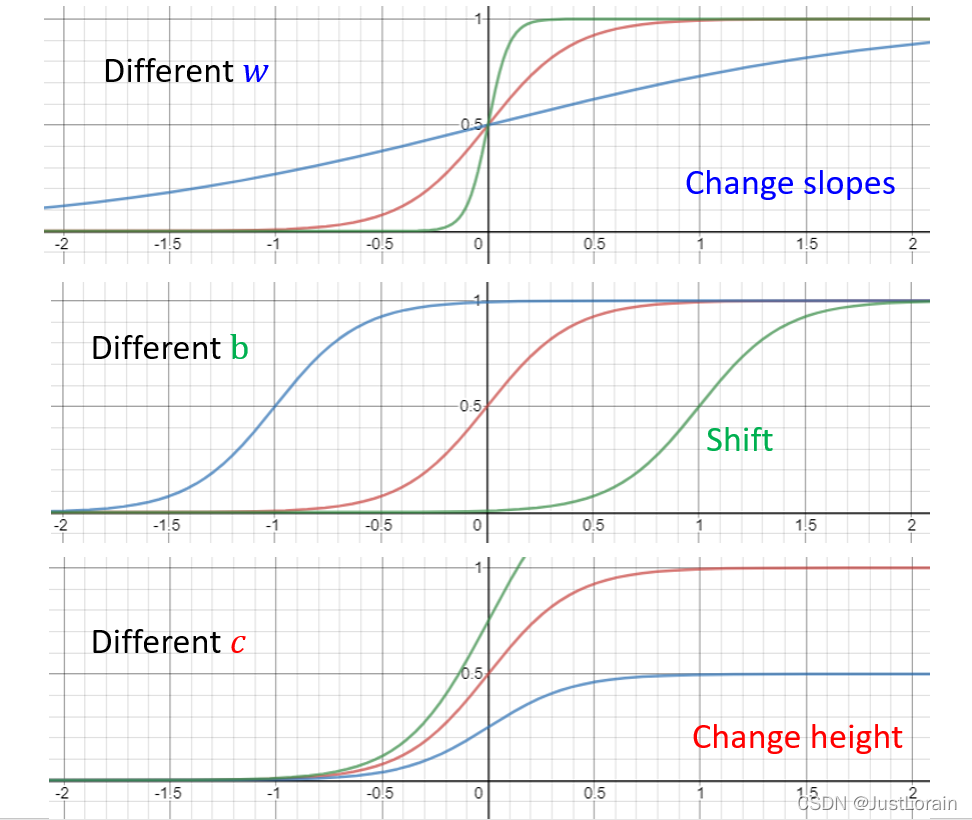
-
回到最初的问题,我们用Sigmoid Function去替换掉之前的蓝色函数得到新的表示的红色分段函数
不同的sigmoid function有不同的参数

- 然后我们现在考虑多个参数的情况,例如考虑前7天,前28天而不是只是一天,得到新的function

-
抽象
在蓝色虚线里面进行的事情
- i 代表sigmoid function函数的数量,也是黑色的圆点
- j 代表feature的数量,用之前的例子来说就是天数,也是黄色的正方形
我们依次计算出结果最后用一个新的变量 r 来接收

**我们可以把这个过程变成线性代数的矩阵计算**

-
然后我们让重新计算的r1,r2,r3通过sigmoid function

-
继续计算
a1, a2, a3拼起来变成向量a c1, c2, c3拼起来叫向量c然后对它进行Transpose(转置)

---

- 整合变量,其中绿色的b为向量,灰色的为标量,-0称为我们所有未知的参数

2. Define Loss from Training Data

3. Optimization


我们将数据分成N个batch,每一个batch单独算一个Loss,把所有的batch都计算一遍后称为一个epoch,每一次更新一个参数称为一次update。

Sigmoid ->ReLU
一个sigmoid函数可以看成两个ReLU函数


Neural Network


















 45万+
45万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









