






数据库主要分为关系型数据库和非关系型数据库
关系型数据库(SQL):使用一系列表来表达书记以及这些数据之间的关系,数据与数据
之间有一定的关系,可保证数据完整性,但会有一定约束
非关系型数据库(NOSQL):数据与数据之间没有关联,可快速对数据存储和写入,对其一
数据做操作时,其他数据不会影响,但不可保证数据完整性
#MySQL数据库# (属于关系型数据库) (数据库->表->字段)
应用场景:比如学院学生课程,这系列相关联的数据,保存到数据库
特点:安全性对比非关系型数据库高
索引: 主要是MySQL中单独存储在磁盘中的数据库结构,使用索引可快速找出某个或多个
列中指定值的行且MySQL所有数据类型都可被索引, 主要用于大大提高数据检索速度
配置文件#
cd /etc/mysql/mysql.conf.d (到该路径下)
vim mysqld.cnf (打开该配置文件)
其中 port = 3306' 为Mysql数据库默认端口
Mysql服务#
service mysql status (查看Mysql是否在运行,(Ctrl + c 返回))
mima (得到已有两个初始Mysql用户以及密码)
mysql -uadmin -p (本机登录-u后输入用户名 -p后回车输入密码)
mysql -h127.0.0.1 -p3306 -uadmin -p (远程登录-h后输入IP地址-p输入数据库端口)
exit; (退出)
show databases; (查看当前用户所有数据库)
数据库基本操作#
create database 【if not exists】cyh;
(创建名为cyh的数据库,【】里的可有可无,意思是没有则创建)
use cyh; (进入cyh数据库)
select user(); (查看当前使用的用户)
select database(); (查看当前进入的数据库)
drop database 【if exists】cyh;
(删除名为cyh的数据库,【】里的可有可无,意思是有则删除)
表操作#
show tables; (查看当前数据库所有表)
show tables from sys; (查看sys数据库所有表)
create table 【if not exists】cy( (创建一个表叫cy,可以一次性创建多个字段)
id int, (表内第一个字段名为 id 类型为 整型 (整型长度默认为11)
name varchar(20) (表内第二个字段名为name 类型为 字符串 长度为20以内
)【charset='utf8'】; (可自行设置该表编码格式,默认为utf-8)
show create table cy; (查看cy表的信息)
desc cy; (只查看cy表内结构)
alter table cy rename cyc (alter 修改结构,把表名cy改成cyc)
alter table cy add age int; (修改cy表内字段名为age 类型为整型的字段)
alter table cy add (age int,sex varchar(5)); (添加多个分别为 age 和sex 字段)
alter table cy modify sex int; (修改sex的类型为整型)
alter table cy change sex ress varchar(10); (修改sex的名字为ress 类型为长度十的字符串)
(change 默认名字和类型都改变,只改变名字的话,类型写原类型,不可不写)
alter table cy drop sex; (删除sex字段)
alter table cy drop sex,drop age; (删除多个分别为age 和sex 字段)
drop table【if exists】 cy; (删除名为cy的表)
表内增删改查#
增:insert into cy value(1,'cc',18); (全字段插入)
(cy表内写入id为1 name为'cc' age为18,表内含有全字段都必须写值)
insert into cy(id,name) value(2,'bb'); (指定字段插入)
(cy表内只写入id为1 name为'cc',age字段未插入,默认为空(NULL))
insert into cy values(3,'aa',20),(4,'dd',23); (多条插入)
查:select * from cy; (*代表全部字段,查看cy表内全部字段)
select age,id,name from cy (指定字段查看顺序,同可部分字段查看顺序)
改:update cy set age=17; (全数据的age字段统一改成17)
update cy set age=16 where name='bb'; (把name字段为'bb'的数据,age字段改为16)
update cy set age=18 where age is null; (把age字段为空的数据,改为18)
删:delete from cy; (删除表内所有数据)
delete from cy where age=16 (把age字段为16的数据删除)
表约束#
非空约束 (约束该字段数据不能为空) (例: name)
alter table cy modify name varchar(20) not null; (若name为空,数据则无意义)
(把cy表中name字段改为不能为空,且长度20字符串)
唯一约束 (约束该字段数据不能重复) (例: id 或 手机号,身份证)
alter table cy add unique key(phone); (若phone重复,则无法分辨两者phone)
(把cy表中phone字段定义为不可重复,定义后查看表内结构Key栏会对应出现UNI)
主键约束 (主键同时具备非空和唯一约束,但表只能有一个主键) (例: id)
alter table cy add primary key(id); (id必须不为空且不可重复)
(把cy表中 id字段定义为主键,定义后查看表内结构Key栏会对应出现PRI)
自增约束 (定义该字段写入数据自动增加) (例: id+= 1)
alter table cy change id id int auto_increment;
(把cy表中id字段自动+1,定义后查看表内结构Extra栏出现auto_increment)
默认约束 (定义该字段默认值,未传值则为默认值) (例: sex=man 性别默认男)
alter table cy alter sex set default 'man'; (之前数据不变,之后传入默认值生效)
(把cy表中sex字段默认值设置为'man',定义后查看表内结构Default栏出现默认值)
外键约束 (定义表与表之间的约束)
(ks和bd两学生属于理学院,理学院则默认不可撤销,主外键之间定义约束,除非设置级联删除)
级联删除 (用在创建表时末尾)
on delete set null (主键不存在时外键定义为空值)
on delete cascade (主键不存在时外键一起删除)
表关系# (通过主外键生成一对多,一对一,多对多关系)
一对多关系:(例:一个学生只能属于一个学院,一个学院可以有多个学生)
一对一关系:(例:一个学生只能有一个详情表,一个详情表只能属于一个学生)
多对多关系:(例:一个学生只能选择多门课程,一门课程可以有多个学生)
综合使用约束创建表 (定义约束最好在创建该表时定义)
create table department( (创建学院表)
d_id int primary key auto_increment, (学院id(d_id):为整型 定义主键 且自增)
d_name varchar(20) not null (学院名(d_name):为长度20字符串 不可为空)
);
insert into department(d_name) values('数学'),('计算机'),('英语'),('挖掘机'); (学院表写入数据)
select * form department; (查看学院表)
create table student( (创建学生表)
s_id int primary key auto_increment, (学生id(s_id):为整型 定义主键 且自增)
s_name varchar(20) not null, (学生名(s_name):为长度20字符串 不可为空)
de_id int, (报选学院id(d_id):为整型)
constraint s_de_key foreign key(de_id) references department(d_id) on delete set null);
(定义外键约束名s_de_key(删除关联时可以通过它删除)该表内de_id为外键连接department
表内的de_id为主键,定义级联删除:主键(学院)不存在时外键(该学生报选学院)为空值)
insert into student(s_name,de_id) values('moran',2),('xiaobai',2),('beidou',4),('anyan',1);
(学生表写入数据)
select * from student; (查看学生表)
insert into student(s_name,d_id) values('moran',5); (则会报错,因为没有id为5的学院)
delete from department where d_id=4;
(把学院id为4的学院删除,报选该学院的'beidou',报选学院id则为空值)
create table stu_detail(
sd_id int primary key auto_increment, (创建学生详情表)
s_sex varchar(20) default 'man', (性别(s_sex):为长度20字符串,默认为'man')
s_age int, (年龄(s_age):为整型)
s_id int unique key, (对应学生id(s_id):为整型,且唯一)
constraint s_sd_key foreign key(s_id) references student(s_id) on delete cascade);
(定义外键约束名s_sd_key(删除关联时可以通过它删除)该表内s_id为外键连接student
表内的s_id为主键,定义级联删除:主键(学生)不存在时外键(该学生详情)同时删除)
insert into stu_detail(s_sex,s_age,s_id) values('nan',18,1),('nv',36,4),('nan',48,3),('nan',80,2);
(学生详情表写入数据)
select * from stu_detail; (查看学生详情表)
insert into stu_detail(s_age,s_id)value(20,2); (则会报错,因为对应学生id设置了唯一)
delete from student where s_id=3; (删除id为3的学生'beidou',对应学生详情表也会删除)
create table course( (创建课程表)
c_id int primary key auto_increment, (课程id(c_id):为整型 定义主键 且自增)
c_name varchar(20) not null (课程名(c_name):为长度20字符串 不可为空)
);
insert into course(c_name) values('python'),('c'),('web'),('django'); (课程表写入数据)
create table stu_course( (创建选课表)
s_id int, (选课学生id(s_id):为整型)
c_id int, (选课课程id(c_id):为整型)
primary key(s_id,c_id), (定义联合主键,使之不出现同一学生报同一课程情况)
constraint s_s_key foreign key(s_id) references student(s_id) on delete cascade,
constraint s_c_key foreign key(c_id) references course(c_id) on delete cascade);
(分别定义主外键关联,主键不存在时同时删除外键)
insert into stu_course values(1,1),(1,4),(2,3),(2,2),(4,2); (选课表写入数据)
select * from stu_course; (查看选课表)
事务# (把事务内命令绑定在一起,要么命令全部执行,要么全部不执行)
begin; (开始事务,开始事务后所有命令都未完全提交运行)
rollback; (结束事务,且取消提交运行开始事务后的全部命令,进行回滚)
commit; (结束事务,且提交运行所有事务内命令)
视图# (综合一系列表内字段,得到想要的查询效果)
select s_name,c_name from student inner join stu_course on student.s_id=stu_course.s_id
inner join course on course.c_id = stu_course.c_id; (把选课学生和选课课程用通过 inner join
连接选课表,条件是学生表内的学生id等于选课表内学生id,课程表内课程id等于选课表内课程id)
create view s_c as select s_name,c_name from student inner join stu_course on student.s_id =stu_course.s_id inner join course on course.c_id = stu_course.c_id;
(创建一个名为 s_c 的视图查看,之后可直接通过视图名查看视图) (视图内无法增删改数据,只能在原文件更改)
(视图内无法增删改数据,只能在原文件更改)
create view cc as select d_name,s_name,s_age,s_sex,c_name from department inner join student on department.d_id=student.de_id inner join stu_detail on student.s_id=stu_detail
.s_id inner join stu_course on student.s_id=stu_course.s_id inner join course on course.c_id=stu_course.c_id;
(依次连接各表主外键,得到需查询内容并作为视图cc创建)
drop view s_c; (删除名为s_c的视图)
单表查询#
部分字段查询
select d_name from department; (查询department表的d_name)
条件查询
select * from stu_detail where s_age>=18 and s_age<60; (可使用逻辑运算符和比较运算符)
(查询stu_detail表中学生年龄大于或等于18且小于60的数据)
模糊查询 (不常用,对于大量数据会影响效率)
select * from student where s_name like 'mo%'(查询s_name字段mo后面任意字符任意长度数据)
多表查询#
内连接
select * from department inner join student; (笛卡尔坐标轴:为无条件查询)
(department所有数据都匹配student所有数据) (主外键d_id=de_id的数据才有意义)
(主外键d_id=de_id的数据才有意义)
select * from department inner join student on department.d_id=student.de_id; (inner join 拼接时 on拼接条件)
(inner join 拼接时 on拼接条件)
select d_name,s_name from department inner join student on department.d_id=student.de_id;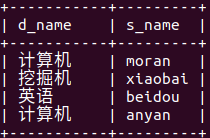 (指定d_name和s_name两字段查询)
(指定d_name和s_name两字段查询)
外链接#
左连接 (以左表为主,与右表没有匹配数据时用空值(null)显现)
select d_name,s_name from department left join student on department.d_id=student.de_id;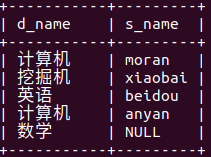 (因为以左表department为主,数学学院没有所属学生则表示null)
(因为以左表department为主,数学学院没有所属学生则表示null)
右连接 (以右表为主,与左表没有匹配数据时用空值(null)显现)
select d_name,s_name from department right join student on department.d_id=student.de_id;
(以右表student为主,学生没有所属学院则该学生显示时学院栏表示null)
子表查询 (多表查询时与内外连接结果一致,只是方法不同)
select d_name,s_name,s_sex from (select s_name,s_id from department inner join student on department.d_id=student.de_id) as e inner join stu_detail on stu_detail.s_id =e.s_id;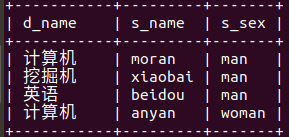 (department和student表拼接结果与stu_detail表拼接)
(department和student表拼接结果与stu_detail表拼接)
排序
select s_name,s_age,s_sex from stu_detail as s inner join student on s.s_id=student.s_id order by s_age; (order by 拼接stu_detail和student表通过s_age排序,默认从小到大(asc))
select s_name,s_age,s_sex from stu_detail as s inner join student on s.s_id=student.s_id order by s_age desc; (desc 从大到小排序)
select s_name,s_age,s_sex from stu_detail as s inner join student on s.s_id=student.s_id order by s_age desc limit 2; (limit 获取数据次数,从大到小获取前2条数据)
select s_name,s_age,s_sex from stu_detail as s inner join student on s.s_id=student.s_id order by s_age limit 2,3; (从小到大获取2-3条数据)
分组查询
select d_id,d_name,count(*) from department inner join student on department.d_id=student.de
_id group by d_id,d_name; ( count(*) 查询出现次数)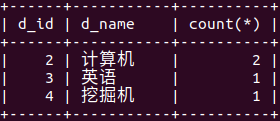 (通过student表中所属学院出现次数,得到各学院人数)
(通过student表中所属学院出现次数,得到各学院人数)
select d_id,d_name,count(*) from department inner join student on department.d_id=student.de
_id group by d_id,d_name having count(*)<2; ( having 在count方法中专属的条件连接)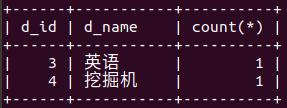 (得到出现次数小于2的学院)
(得到出现次数小于2的学院)
mysql函数 (了解即可,数据库主要是存储和查询,数据操作基本上是再后台操作)
abs(绝对值),max(最大值),min(最小值),round(),avg(平均值),sum(求和)
优化 (可以提升运行效率,对于运维(运行维护)人员必须了解)
1.尽可能避免整表查询 如: select *
2.在join中,尽可能小表inner join大表
3.建立合适的索引 如:alter table student add index(s_name);
#Redis数据库# (非关系型数据库) (数据库->数据类型)
(全称:Remote Dictionary server 远程字典服务器)
应用场景:需频繁读取和写入且无关联的数据可使用Redis数据库存储
特点:支持数据持久化,可将数据保存至磁盘,不仅有键值对数据类型,值还分为五种不同数据类型,
且交换数据快。
基本操作#
Redis只包含16个数据库,下标0-15,默认0数据库,且各数据库内容不互通
redis-server (启动)
redis-cli (本地进入)
redis-cli -h 127.0.0.1 -p 6379 (远程进入,6379为端口)
PING (判断是否可以正常使用,可则返回:PONG)
redis-cli shutdown (exit为强制退出,退出之前可用该语句保存数据)
select 1 (切换下标1数据库)
基础命令# (以下操作值数据类型为字符串)
增:set cy 123 (创建键为cy 值为123的键值对)
mset c 11 d 22 (创建多个键值对,键为c和d值为11和22)
查:keys * (* 通配符,查看当前数据库所有键值对,显示键)
keys 'c?' (? 匹配单个任意字符,查看c后面匹配单个任意字符的键值对)
keys 'c[a-z]' ([] 指定范围,查看c后面匹配a~z单个任意字符的键值对)
get cy (获取cy对应的值)
mget c d (分别获取 c和d对应值)
判断:exists c (判断键为c键值对是否存在,1为True,0为False)
rename cy cc (把键cy重命名为cc)
set cy 111 ex 20 (创建cy键111值键值对时,定义过期时间为20秒,到时自动删除)
expire c 60 (给已存在的c键设置键值对在60秒后自动删除)
ttl c (查看c键自动删除剩余时间,-1为过期时间永久,-2为该键不存在))
persist c (留有剩余时间时,取消自动删除,重新变为永久)
type c (查看c键对应值的数据类型,数字和汉字默认为string)
删:del c (删除c键对应键值对,批量删除则空格隔开对应键)
删除指定格式的键值对时,需exit退出到终端:
redis-cli keys 'c?' | xargs redis-cli del (在Redis数据库里查询到该格式,进行统一删除)
flushdb (清空当前数据库所有内容)
flushall (清空16个数据库所有内容)
数据类型#
字符串 string
append c 2 (c键对应值拼接字符2)
incr c (值为全数字时,对应值+1)
decr c (值为全数字时,对应值-1)
incrby c 10 (值为全数字时,对应值+10)
decrby c 10 (值为全数字时,对应值-10)
列表 list (含有下标,从0开始,不具备左闭右开)
增:lpush ca 3 4 5 (创建键为ca值从左添加,添加顺序3->4->5,得到顺序为5->4->3)
rpush ca 1 2 6 (创建键为ca值从右添加,添加顺序1->2->6得到顺序为1->2->6)
查:llen ca (查看ca键对应值列表的长度)
lindex ca 3 (查看ca键对应值列表下标为3的值) 结果: '3'
lrange ca 0 -1 (查看ca键对应值列表所有值,-1为最后) 结果:'5' '4' '3' '1' '2' '6'
删:lpop ca (从左删除ca键对应值列列表值) 结果:'5'
rpop ca (从右删除ca键对应值列表值) 结果:'6'
lrem ca 2 (1>0则从左删除,从左删除2个值) 结果:'4' '3'
lrem ca 1 2 (1>0则从左删除,从左删除1个值为2的值) 结果:'2'
lrem ca -1 (-1<0则从右删除,从右删除1个值) 结果:'1'
lrem ca 0 4 (0=0则删除全部为4的值)
哈希 hash (嵌套键值对)
增:hset cd name mo (创建类似于{cy:{name:mo}}的键值对)
hmset cy name cyh age 18 size 180 (创建类似于{cy:{name:cyh,age:18,size:180}}的键值对)
查:hget cy name (获取cy键对应的name键对应值)
hmget cy name age size (获取cy键对应的name键,age键和size键对应值)
hkeys cy (获取cy键对应的所有键)
hvals cy (获取cy键对应的所有值)
hgetall cy (获取cy键对应的所有键值对)
hlen cy (获取cy键对应的键值对个数)
判断:hexists cy name (判断cy键对应键是否有name键)
hsetnx cy sex man (判断cy键对应键是否有sex键,无则添加且值为man)
hincrby cy age 10 (全数字值可+10,减则负数)
删:hdel cy sex age (删除sex键和age键对应键值对)
集合 set (无序且唯一)
增:sadd aa 1 2 3 a b (创建aa键对应值为集合,类似{1,2,3,a,b})
查:smembers aa (获取aa键对应值集合内元素)
scard aa (获取aa键对应值集合内元素个数)
srandmember aa 3 (随机获取aa键对应值集合内3个不可重复元素)
srandmember aa -3 (随机获取aa键对应值集合内3个可重复元素)
判断:sismember aa 4 (判断aa键对应值集合内是否有元素4,1为True,0为False)
删:srem aa 2 (删除aa键对应值集合内为2的元素)
spop aa 2 (随机删除aa键对应值集合内2个元素)
交集:sinter aa bb (求aa键和bb键对应值集合的交集)
sinterstore cc aa bb (把aa键和bb键对应值集合的交集创建新键值对cc键保存)
并集:sunion aa bb (求aa键和bb键对应值集合的并集)
sunionstore dd aa bb (把aa键和bb键对应值集合的并集创建新键值对dd键保存)
差集:sdiff aa bb (求aa键和bb键对应值集合的差集)
sdiffstore ee aa bb (把aa键和bb键对应值集合的差集创建新键值对ee键保存)
有序集合 zset (有序且唯一)
指:在创建集合内元素时,各元素依次定义对应分数,以分数大小定义顺序
特点:1.对比列表得到两端数据速度极快,元素增多时,访问中间数据很慢,有序集合却不会。
2.列表不可调整元素位置,有序集合可以调整。缺点:占用内存多
3.属于Redis五种数据类型最高级类型
增:zadd xx 100 ba 80 bc 60 bd (创建xx键对应有序集合100分ba 80分bc 60分bd)
查:zcard xx (查看xx键对应有序集合元素个数)
zscore xx ba (查看xx键对应有序集合元素ba的分数)
zrange xx 0 -1 (查看xx键对应有序集合所有元素)
zrange xx 0 -1 withscores (查看xx键对应有序集合所有元素且显示对应分数)
获取:zrange score xx 60 90 (从小到大顺序获取60到90分之内元素,包含60和90)
zrange score xx (60 (90 (从小到大顺序获取60到90分之内元素,不包含60和90)
zrevrange score xx 60 90 (从大到小顺序获取60到90分之内元素,包含60和90)
zrevrange score xx 60 90 limit 1 2
(从大到小顺序获取60到90分之内元素,包含60和90保留排序后下标1~2的值)
zcount xx 60 90 (获取60到90分之内元素个数,包含60和90)
改:zincrby xx 5 bc (把xx键对应有序集合元素bc对应分数+5,减则负数)
删:zrem xx ba (删除xx键对应有序集合ba元素)
zremrangebyrank score 0 2 (删除xx键对应有序集合下标0~2元素)
zremrangebyscore score 90 100 (删除xx键对应有序集合分数90~100元素)
交集:zinterstore bk 2 bi bj (把bi和bj这2个有序集合交集保存到bk,且交集元素分数会叠加)
并集:zinterstore bk 2 bi bj (把bi和bj这2个有序集合并集保存到bk,且交集元素分数会叠加)
#MongoDB数据库# (属于非关系型数据库) (数据库->集合->文档)
应用场景:存储海量数据时采用或者需要实时共享数据
特点:1.高性能2.高可用性3.高可扩展性,不需要数据转换4.对SQL注入攻击免疫
基础操作
mongo (进入MongoDB交互模式)
show dbs (查看所有数据库)
db (查看当前数据库,默认为test)
use cy (有则切,无则增切,增加临时数据库,未对其操作退出时则自动删除)
db.dropDatabase() (删除当前数据库,先切再删)
show collections (查看当前数据库所有集合)
db.createCollection('cyh') (当前数据库创建集合且名为cyh)
(对不存在集合进行操作时,自动创建该集合)
db.cyh.drop() (当前数据库删除名为cyh的集合)
文档增删改查
增:db.cyh.insert({name:'aa',age:18}) (创建单条文档数据,创建时自动创建id,可自行定义)
db.cyh.insertOne({name:'aa',age:18}) (↑前者新方法)
db.cyh.insert([{name:'bb',age:19},{name:'cc',age:18}]) (创建多条文档数据,创建时自动创建id)
db.cyh.insertMany([{name:'bb',age:19},{name:'cc',age:18}]) (↑前者新方法)
查:db.cyh.find() (查看cyh集合内所有文档数据)
db.cyh.find().pretty() (美化显示内容,过长数据分行显示)
db.cyh.find({name:'aa'}).pretty() (带条件查询文档数据)
db.cyh.find({name:'aa',age:18}).pertty() (多条件同时满足查询文档数据)
db.cyh.find({age:18,$or:[{'name':'aa'},{name:'cc'}]}).pertty() (同时满足条件1和2或者满足1和3)
db.cyh.find({age:{$lt:19}}).pertty() (纯数字数据范围查询,查看age小于19文档数据)
($gt:大于$gte:大等于$lt:小于$lte:小等于$ne:不等$eq:等于)(不支持同字段同时满足18<x<20)
改:db.cyh.updete({name:'aa'},{age:27}) (把符合前者条件全文档数据修改为后者,匹配一次)
db.cyh.update({age:18},{$set:{age:20}})(把符合条件文档内的后者数据进行更改,匹配一次)
db.cyh.updateOne({age:18},{$set:{age:20}}) (↑前者新方法)
db.cyh.update({age:18},{$set:{age:20}},{multi:true}) (匹配多次)
db.cyh.updateMany({age:18},{$set:{age:20}}) (↑前者新方法)
删:db.cyh.remove({name:'bb'},{justOne:true}) (把符合前者条件该文档删除,匹配一次)
db.cyh.deleteOne({name:'bb'}) (↑前者新方法)
db.cyh.remove({age:17}) (匹配多次)
db.cyh.deleteMany({age:17}) (↑前者新方法)
db.cyh.remove({}) (清空该集合内所有文档)
(删除并不会真正释放空间,可自行释放或退出MongoDB时自动释放)
db.repairDatabase() (自行释放)
Python与MongoDB交互
自行选择本地环境(cmd)或者远程环境(Linux)内下载pymongo模块
pip install pymongo -i https://pypi.douban.com/simple (下载该模块)
Python内输入:
import pymongo
a = pymongo.MongoClient() (连接数据库,得到对象并赋值)
d = a['cy'] (指定操作的数据库并赋值)
c = b['cyh'] (指定操作的集合并赋值)
即可使用MongoDB内操作(例):
c.insertOne({name:cc,age:18}) (添加单条数据)
d = list(c.find()) (查看该集合内所有文档数据,转成列表并赋值)
print(d[0]) (通过下标得到指定数据)















 571
571











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









