






记录一下。
1. 分析网页
分析网页的目的:
- 需要获取哪些数据
- 能从网页获取哪些数据
- 如何获取全部数据
具体操作:
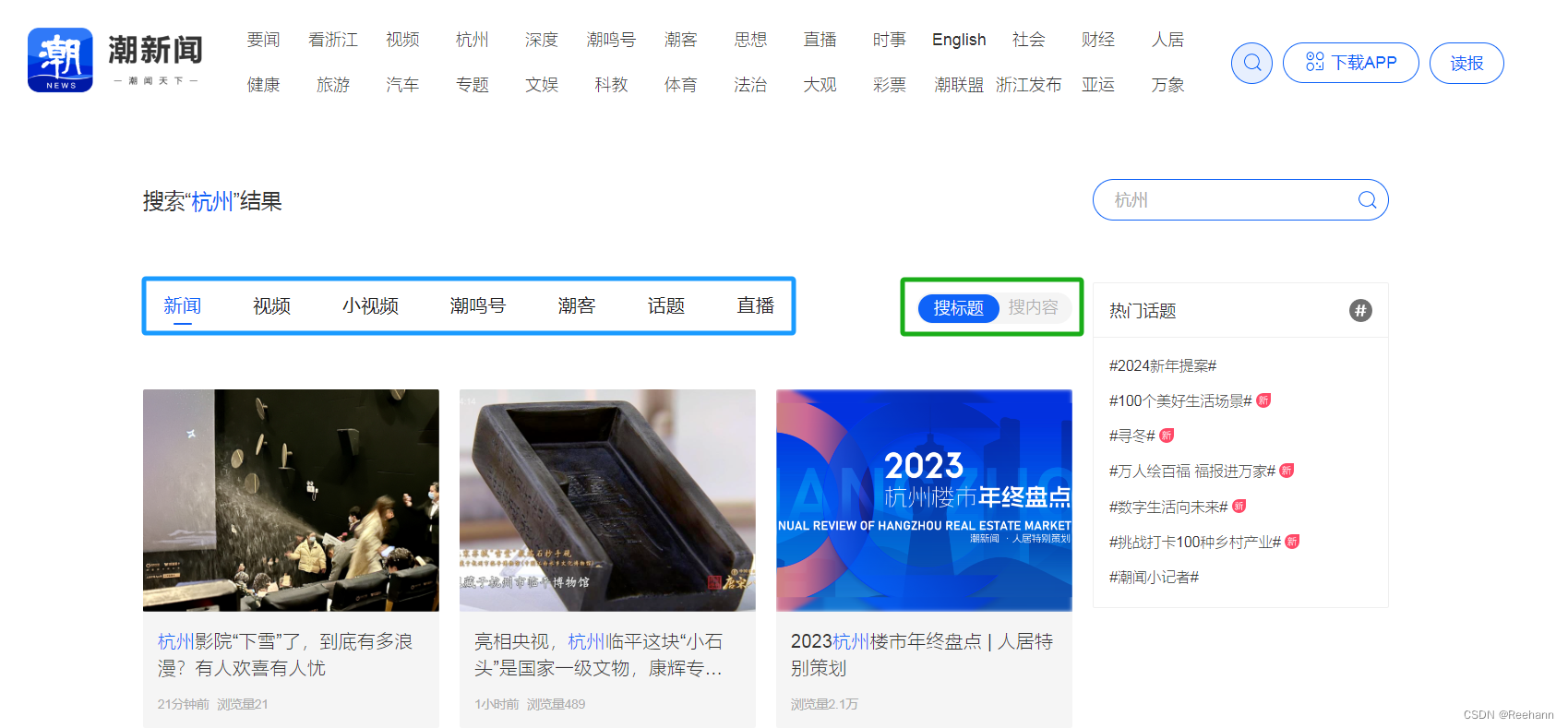
打开网页,输入任意关键词,进入搜索结果页。
由搜索页结果页可见:
- 可选择搜索的内容类型及结果范围。
- 如需获取全部内容,滚动至网页底部时,会自动加载新内容。
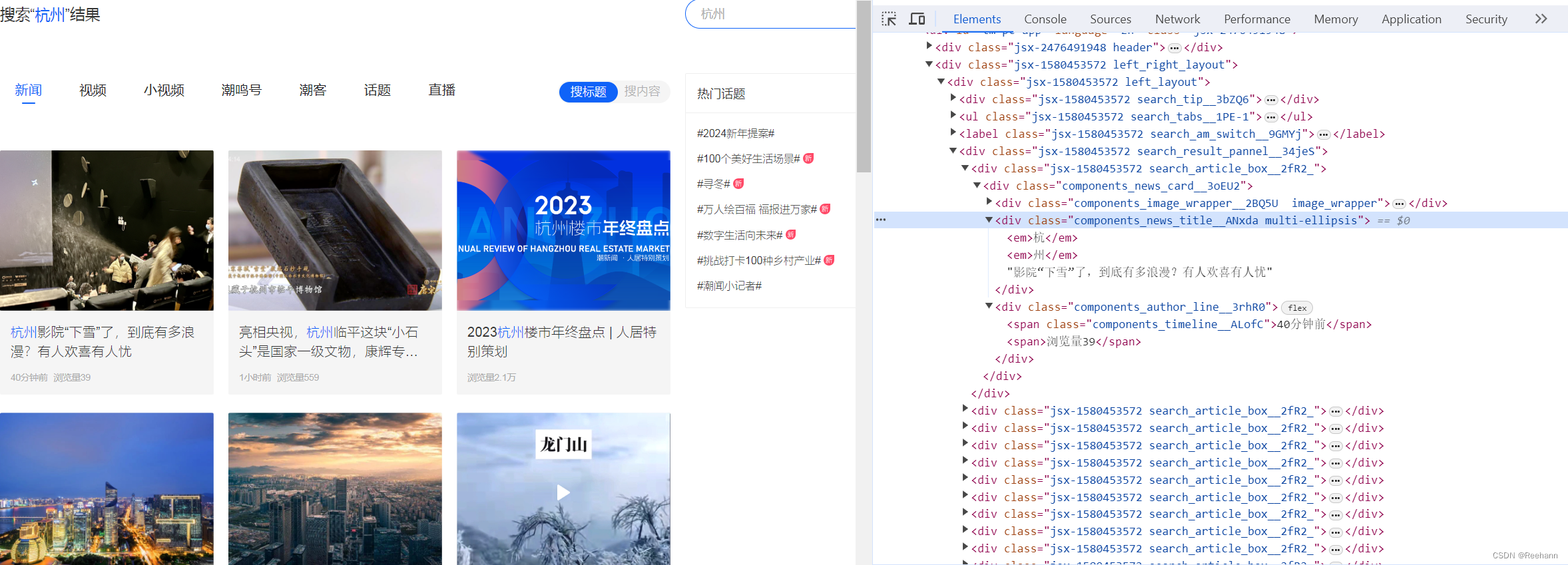
按 F12 打开开发者工具,刷新网页,查看Elements。
本案例中,可见:
- 滚动至网页底部时,新加载的内容会排序在既有内容的下方。
- 可直接获取的数据包括:标题、发布时间、浏览量。
2. 爬虫实现
拆分步骤
- 打开网页,在搜索栏输入关键词,进入搜索结果页
- 选择需要的内容类型,包括:新闻、视频、小视频等
- 选择需要的内容范围,包括:搜标题、搜内容
2.1 打开网页 检索关键词
2.1.1 打开网页
- 利用WebDriver启动浏览器
- 下载ChromeDriver:Chrome for Testing availability
- 访问URL:https://tidenews.com.cn/search.html
2.1.2 检索关键词
- 定位搜索图标,点击后,输入关键词。
- 需要注意的是,用程序启动浏览器时,网页结构与手动进入时不一致。

import time
from selenium import webdriver
from selenium.webdriver.common.by import By
def openhtml(url,keyword):
#打开url
driver = webdriver.Chrome()
driver.get(url)
time.sleep(3)
driver.maximize_window()
#输入keyword
textbox = driver.find_element(By.XPATH,'//*[@id="keyword-input"]')
textbox.click()
textbox.send_keys(keyword)
time.sleep(3)
return driver2.2 选择内容 滑动至底部
2.2.1 选择类型及范围
- 选择内容类型,如:新闻等
- 选择内容范围,包括:搜标题、搜内容
2.2.2 使加载全部内容
- 不断拖动滚动条,直到加载全部内容
import random
def loadhtml(driver):
#选择内容类型
content_class = driver.find_element(By.XPATH,'//*[@id="tm-mobile-app"]/ul/li[1]')
content_class.click()
#选择内容范围
content_range = driver.find_element(By.XPATH,'//*[@id="tm-mobile-app"]/div[2]/label/div[2]')
content_range.click()#点击2n次搜标题,2n+1次搜内容
#滑动至底部
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")
t = random.randint(4,6)
time.sleep(t) #等页面加载
#获取当前页面高度
new_height = driver.execute_script("return document.body.scrollHeight")
#判断是否已经到达页面底部
if new_height == last_height:
break
last_height = new_height
return driver2.3 解析html
from bs4 import BeautifulSoup
def parsehtml(driver):
response = driver.page_source
soup = BeautifulSoup(response,'lxml')
title = []
news_date = []
read_count = []
title_list = soup.select('div.manuscriptList_detail_wrapper__1uSta > h6')
date_list = soup.select('div.manuscriptList_detail_wrapper__1uSta > div > div > span:nth-child(1)')
count_list = soup.select('div.manuscriptList_detail_wrapper__1uSta > div > div > span:nth-child(2)')
newsary = []
for i in range(len(title_list)):
newsary.append({
'title':title_list[i],
'newsDate':date_list[i],
'count_list':count_list[i]})
return newsary2.4 保存文件
import pandas as pd
def savefile(newsary):
df = pd.DataFrame(newsary)
df.to_csv("相关报道.csv")
return2.5 全部过程
import time
import random
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.by import By
from bs4 import BeautifulSoup
def openhtml(url,keyword):
#打开url
driver = webdriver.Chrome()
driver.get(url)
time.sleep(3)
driver.maximize_window()
textbox = driver.find_element(By.XPATH,'//*[@id="keyword-input"]')
textbox.click()
textbox.send_keys(keyword)
time.sleep(3)
return driver
def loadhtml(driver):
'''
无需变更内容类型、内容范围
#选择内容类型
content_class = driver.find_element(By.XPATH,'//*[@id="tm-mobile-app"]/ul/li[1]')
content_class.click()
#选择内容范围
content_range = driver.find_element(By.XPATH,'//*[@id="tm-mobile-app"]/div[2]/label/div[2]')
content_range.click()#点击2n次搜标题,2n+1次搜内容
'''
#滑动至底部
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0,document.body.scrollHeight)")
t = random.randint(4,6)
time.sleep(t) #等页面加载
#获取当前页面高度
new_height = driver.execute_script("return document.body.scrollHeight")
#判断是否已经到达页面底部
if new_height == last_height:
break
last_height = new_height
return driver
def parsehtml(driver):
response = driver.page_source
soup = BeautifulSoup(response,'lxml')
title = []
detail = []
title_list = soup.select('div.manuscriptList_detail_wrapper__1uSta > h6')
detail_list = soup.select('div.manuscriptList_detail_wrapper__1uSta > div > div')
newsary = []
for i in range(len(title_list)):
newsary.append({
'title':title_list[i],
'detail':detail_list[i]})
return newsary
def savefile(newsary):
df = pd.DataFrame(newsary)
df.to_csv("相关报道.csv")
return
main()3. 数据处理
- 查看数据
df = pd.read_csv("相关报道.csv")
df.head()
- 删除无用列,查看数据类型
df.drop(columns='Unnamed: 0',inplace=True)
df.dtypes
- 变更数据类型
df = df.astype({'title':'string','detail':'string'})
df.dtypes- 数据处理
df.title = df.title.str.replace('<h6>','').str.replace('</h6>','')
df.title = df.title.str.replace('<em>','').str.replace('</em>','')
df.detail = df.detail.str.replace('<div class="manuscriptList_subinfo__3PQWk">','')
df.detail = df.detail.str.replace('</div>','').str.replace('<span>','')
df_detail = df.detail.str.split('</span>',expand=True)
df_detail.drop(columns=2,inplace=True)
df_detail = df_detail.rename(columns={0:'日期',1:'浏览量'})
for i in range(24):
date = "{}小时前".format(i)
df_detail = df_detail.replace(date,'2023-12-31')
df_concat = pd.concat([df, df_detail], axis=1)
df_concat.drop(columns='detail',inplace=True)
df_concat = df_concat.rename(columns={'title':'标题'})
df_concat.to_csv("相关报道1.csv")














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









